







Hadoop的两大核心原理:MapReduce和HDFS,在安装Hadoop之前一定要深入的理解这些原理,才有助于安装过程中的故障排查以及以后使用中的问题分析。
HDFS:就是分布式的一群存储拼接成一个大存储,集群内数据做分片、备份、元数据管理、消息通信等,这些对于使用者来说是透明的。
Block(数据块):最基本的存储单元,一个文件可以存为多个block,每个block可以在多个datanode上保留副本,默认为3份。
Datanode(数据节点-需要重点掌握):真正负责存储的节点。
Namenode(元数据节点-需要重点掌握):负责管理文件目录、文件与block的对应关系,以及block与datanode的关系。Namenode的元数据是在内存中管理的,相关的有2个文件,fsimage - 它是在NameNode启动时对整个文件系统的快照;edit logs -它是在NameNode启动后,对文件系统的改动序列。显然edit logs将会随运行越久不断增长直到下次重启。
SecondaryNameNode:就是来帮助解决上述问题的,它的职责是合并NameNode的edit logs到fsimage文件中。
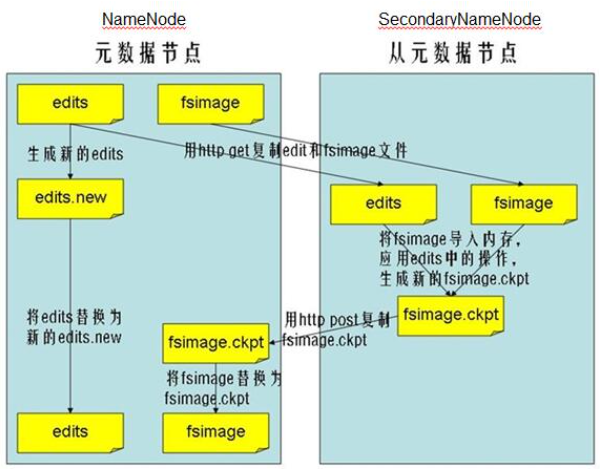
以上是HDFS相关的定义,下面再来看下运行时Hadoop各个节点间是如何协作的。对HDFS的操作主要是读和写。
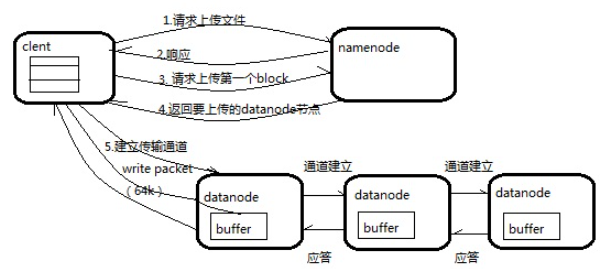
HDFS的写:Client负责拆分block
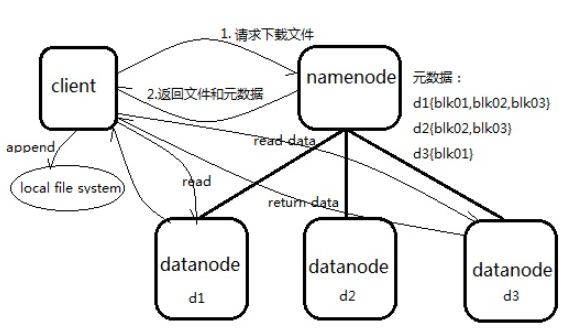
HDFS的读:Client负责append block
HDFS优点:高可用性、高扩展性、低成本
缺点:延时性、不支持多用户写入、无法高效管理海量小文件
MapReduce经历了1.0时代和2.0时代,2.0又叫YARN。
Mapreduce1.0原理
JobClient:门户,代理,拉皮条的,提交job给jobTracker
JobTracker负责管理job的失败、重启等
TaskTracker,真正干活的节点
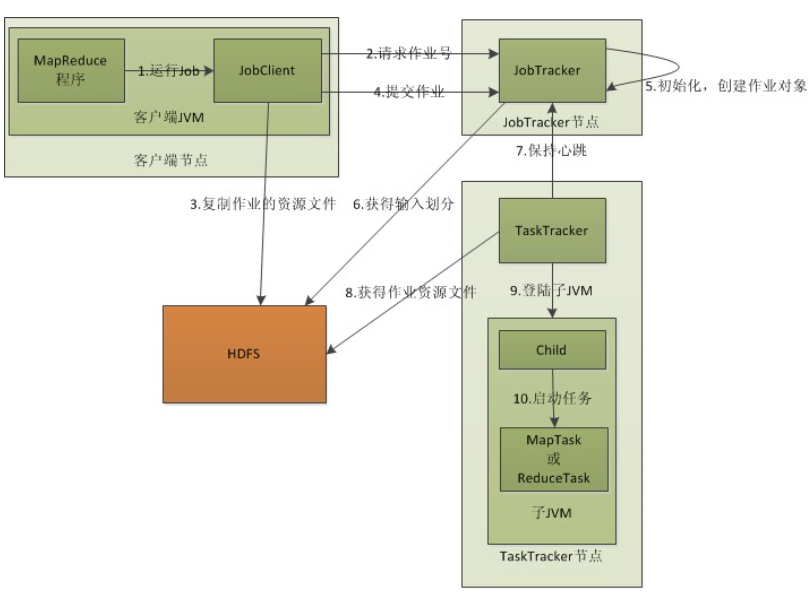
MapReduce存在的缺陷:
1 Job Tracker 存在单点故障
2 Job Tracker 完成太多任务,当MR任务非常多时,造成很大的内存开销
3 Task Tracker 端,如果两个大内存消耗的任务一起调度,容易出现OOM,如果只有Map任务或Reduce任务时会造成资源浪费
MapReduce2.0-YARN原理
ResourceManager:YARN资源框架控制中心,负责集群资源管理调度
NodeManager:是resourceManager在每台机器上的代理,负责容器管理,监控资源使用情况(CPU、内存、磁盘、网络等)
container:真正干活的容器,容器里运行task和applicationMaster,可以是任何命令(例如java、python、C++)
applicationMaster:任务大总管,负责向resourceManager申请资源,请求nodeManager启动container并告知container要做什么事情
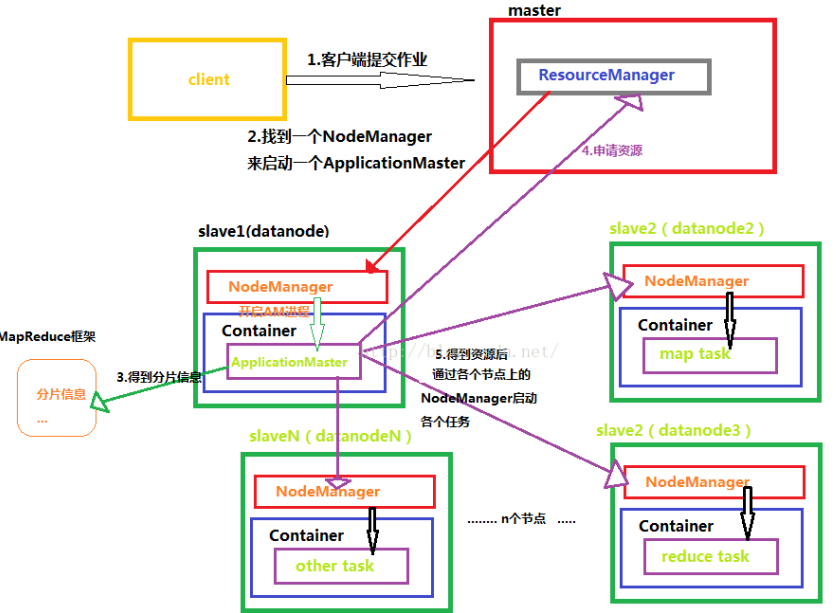
与老的MapReduce相比,YARN把资源管理与任务调度的工作分离开来(交给ApplicationMaster去做),减少了MapReduce中Job Tracker的压力
我准备搭建3节点的Hadoop集群:
192.168.226.135 master
192.168.226.133 slaver1
192.168.226.136 slaver2
1规划集群
我准备搭建一个3节点的hadoop集群,master、slaver1、slaver2,我现在有3台虚拟机(centos7.0),先配置好操作系统的hostname和hosts
机器1:192.168.226.135à mastr
修改/etc/hostname,机器名修改为master
修改/etc/hosts,添加其它两个节点的映射:
192.168.226.133 slaver1
192.168.226.136 slaver2
机器2:192.168.226.133à slaver1
修改/etc/hostname,机器名修改为slaver1
修改/etc/hosts,添加其它两个节点的映射:
192.168.226.135 master
192.168.226.136 slaver2
机器3:192.168.226.136à slaver2
修改/etc/hostname,机器名修改为slaver2
修改/etc/hosts,添加其它两个节点的映射:
192.168.226.135 master
192.168.226.133 slaver1
2设置SSH免登录
hadoop的进程之间通信使用ssh方式,需要每次都要输入密码。为了实现自动化操作,需要配置ssh免密码登陆方式。
2.1 /etc/ssh/sshd_config去掉2行注解
#RSAAuthentication yes
#PubkeyAuthentication yes
2.2 ssh-keygen-t rsa,生成key,使用默认的一直回车,/root下就会生成.ssh文件夹
2.3 合并所有节点的/root/.ssh/id_rsa.pub文件到一起
cat id_rsa.pub>> authorized_keys
ssh root@slaver1 cat/root/.ssh/id_rsa.pub>> authorized_keys
2.4 把Master服务器的authorized_keys复制到Slave服务器的/root/.ssh目录
在slaver节点上scproot@master:/root/.ssh/authorized_keys.
执行完毕后hadoop集群间可以直接ssh不需要密码了。
3安装Hadoop
下载地址:http://archive.apache.org/dist/hadoop/core/hadoop-2.9.0/
Wget方式下载,gunzip,tar
4安装配套的JDK
下载地址:http://download.oracle.com/otn-pub/java/jdk/8u161-b12/2f38c3b165be4555a1fa6e98c45e0808/jre-8u161-linux-i586.tar.gz
我的目录/home/hadoop/java/jdk1.8.0_162
5修改Hadoop的etc配置
Hadoop的配置都在/hadoop_home/etc/hadoop下
修改core-site.xml:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131702</value>
</property>
</configuration>
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
修改yarn-site.xml:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<description>The address of the applications manager interface in the RM.</description>
<name>yarn.resourcemanager.address</name>
<value>${yarn.resourcemanager.hostname}:8032</value>
</property>
<property>
<description>The address of the scheduler interface.</description>
<name>yarn.resourcemanager.scheduler.address</name>
<value>${yarn.resourcemanager.hostname}:8030</value>
</property>
<property>
<description>The http address of the RM web application.</description>
<name>yarn.resourcemanager.webapp.address</name>
<value>${yarn.resourcemanager.hostname}:8088</value>
</property>
<property>
<description>The https adddress of the RM web application.</description>
<name>yarn.resourcemanager.webapp.https.address</name>
<value>${yarn.resourcemanager.hostname}:8090</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>${yarn.resourcemanager.hostname}:8031</value>
</property>
<property>
<description>The address of the RM admin interface.</description>
<name>yarn.resourcemanager.admin.address</name>
<value>${yarn.resourcemanager.hostname}:8033</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
<discription>每个节点可用内存,单位MB,默认8182MB</discription>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
<discription>每个节点可用内存,单位MB,默认8182MB</discription>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
Slaves中把内容清空,添加slaves节点的hostname
slaver1
slaver2
6创建目录,在/home/hadoop目录下创建tmp、dfs、dfs/data、dfs/name(根据自己etc里的配置创建)
7设置环境变量
Hadoop_home和java_home先配置好,虽然hadoop_home不是必须的,但是后面命令行操作hdfs会非常麻烦,所以建议一起配置好
Vi /etc/profile
exportHADOOP_HOME=/home/hadoop/hadoop-2.9.0
export JAVA_HOME=/home/hadoop/java/jdk1.8.0_162
exportPATH=.:$HADOOP_HOME/bin:$JAVA_HOME/bin:$PATH
立刻生效:
source /etc/profile
机器之间如果无法通信,需要关闭防火墙。
systemctl stop firewalld.service
但是关了防火墙还不够,下次重启还会打开
设置开机禁止启动防火墙
systemctl disable firewalld.service
OK,网络通信问题到目前为止都搞定了
8启动Hadoop
先初始化以下hdfs“硬盘”:bin/hdfs namenode -format
全部启动sbin/start-all.sh,也可以分开用sbin/start-dfs.sh、sbin/start-yarn.sh启动hdfs和yarn(不用关心mapreduce1.0了,已经out了)
我建议第一次先启动dfs再启动yarn,一个个排查下,因为第一次直接成功的概率不大,start-all不方便排查问题。
9检查
DFS启动之后,master机器上2个服务nameNode和secondaryNameNode,两台slaver机器上都是dataNode。
ps–ef | grep hadoop
但是这并不代表启动是成功的,需要去确认下日志里有没有报错。
YARN启动之后master机器会多个ResourceManager,slaver节点会多个NodeManager
10操作:
hadoop dfs -mkdir /input
在hdfs上创建个目录先,如果能成功并不代表服务是好的,只能代表nameNode是好的。
hadoop dfs –put yourfile /input/newfilename
如果这一步成功说明master能将文档分段后存储到slaver上了,证明dataNode是好的。
到目前为止只能说Hdfs成功了,还需要继续验证yarn
用hadoop自带的wordcount程序验证:
hadoop jar/home/hadoop/hadoop-2.9.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.0.jarwordcount /input /output
如果成功并且output里有你要的part开头的结果文件,说明安装已经验证完成了,如果失败了通过yarn logs -applicationId application_1518156964431_0001来跟踪下失败原因。
PS:输出文件不能重复,如果/output已经存在了那就删掉或者换一个文件名。
安装时的小技巧:
所有的hadoop节点上的内容,无论是master还是slaver,jdk+hadoop_home的内容都是一模一样的,所以可以先把mater装好,然后虚拟机复制或者scp文件夹拷贝,这样可以减少很多没必要的操作。
Ps:也正是hadoop这种完全相同的特性,使得docker容器+hadoop也是比较便利的。
Hadoop所有启动命令列表:
start-all.sh启动所有的Hadoop守护进程。包括NameNode、 SecondaryNameNode、DataNode、JobTracker、 TaskTrack
stop-all.sh 停止所有的Hadoop守护进程。包括NameNode、 Secondary NameNode、DataNode、JobTracker、 TaskTrack
start-dfs.sh 启动Hadoop HDFS守护进程NameNode、SecondaryNameNode和DataNode
stop-dfs.sh 停止Hadoop HDFS守护进程NameNode、SecondaryNameNode和DataNode
hadoop-daemons.sh start namenode 单独启动NameNode守护进程
hadoop-daemons.sh stop namenode 单独停止NameNode守护进程
hadoop-daemons.sh start datanode 单独启动DataNode守护进程
hadoop-daemons.sh stop datanode 单独停止DataNode守护进程
hadoop-daemons.sh start secondarynamenode 单独启动SecondaryNameNode守护进程
hadoop-daemons.sh stop secondarynamenode 单独停止SecondaryNameNode守护进程
start-mapred.sh 启动Hadoop MapReduce守护进程JobTracker和TaskTracker
stop-mapred.sh 停止Hadoop MapReduce守护进程JobTracker和TaskTracker
hadoop-daemons.sh start jobtracker 单独启动JobTracker守护进程
hadoop-daemons.sh stop jobtracker 单独停止JobTracker守护进程
hadoop-daemons.sh start tasktracker 单独启动TaskTracker守护进程
hadoop-daemons.sh stop tasktracker 单独启动TaskTracker守护进程
WordCount代码解析:
public class WordCountMap extends Mapper<LongWritable, Text, Text, IntWritable>{
//map输出的value类型,常量1
private final IntWritable one = new IntWritable(1);
//map输出的key类型
private Text word = new Text();
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
StringTokenizer parse = new StringTokenizer(line);
while(parse.hasMoreTokens()) {
word.set(parse.nextToken());
context.write(word, one);
}
}
}
public class WordCountReduce extends Reducer<Text, IntWritable, Text, IntWritable>{
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException{
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
}public class WordCount {
public static void main(String[] args) throws Exception{
//先设置job的整体配置
Configuration conf = new Configuration();
Job job = new Job(conf);
job.setJarByClass(WordCount.class);
job.setJobName("yejingtao-wordcount");
//在设置job的入参和出参类型和参数
/**
* TextInputFormat是Hadoop默认的输入方法,在TextInputFormat中,每个文件(或其一部分)都会单独作为Map的输入,之后,
* 每一行数据都会产生一个<key,value>形式:其中key值是每个数据的记录在数据分片中的字节偏移量,而value值是每行的内容
*/
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//设置map-reducer的处理类
job.setMapperClass(WordCountMap.class);
job.setReducerClass(WordCountReduce.class);
//详细给出出参的键值对格式
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.waitForCompletion(true);
}
}
WordCount数据流图示:
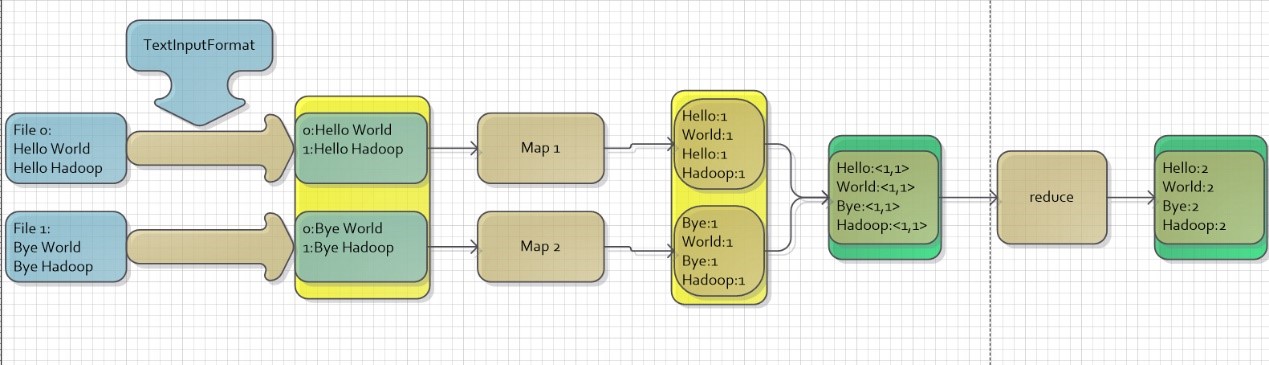
运行中遇到个很妖的错误:
卡在Map 0% Reduce 0%,无法正常执行map-reduce的运算
这是个巨头疼的问题,我在这个问题上卡了很久。
追踪到application的日志卡在了
Going to preempt 1 due to lack of space formaps
查了网络的资料,怀疑是内存不足,于是修改了yarn的配置并扩展了内存,但是仍没有解决问题,后来无意中看到了yarn有这么一项配置:

再linux命令查看了一下自己的磁盘df –hl 已经占用了90%(由于企业没有坏境,我是在自己PC上搭建的VM集群,所以磁盘比较紧张),已经超过了配置说明中75%的界限。于是扩展了VM的磁盘后,问题解决!
PS:linux磁盘空间扩展请参考Linux需要掌握的常用命令和配置















 749
749

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









