







[YARN] 一个JDK的bug导致RM无法分配Container
- 一月 20, 2017
- 0 条评论
最近集群因为NM的OOM,然后决定把ContainerMetric给关闭了,然后采取了批量重启NM的方式,采取的步骤是先批量下线,然后在上线,后来发现集群任务越来越慢,集群的利用率越来越低
以下是集群可用内存,一直在增加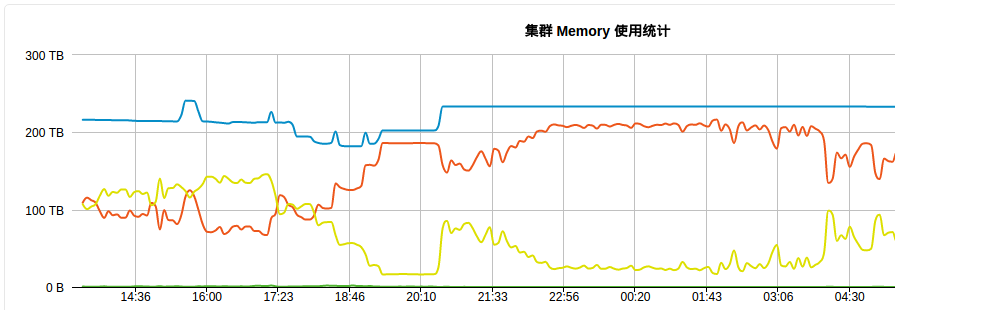
其中出现的现象是:
- 1.事件队列队列堆积非常严重,最高500W+
- 2.Container每秒的分配速率从原来的k级别到变成几十每秒
- 3.发现NM注册之后有些节点从NEW->RUNNING状态需要花费20+s的是状态转化时间,从而导致FINISHED_CONTAINERS_PULLED_BY_AM事件不在状态机的处理范围当中抛出了异常
然后发现社区也有类似的错误问题YARN-4741,但是看他们讨论的结果,并不能解释为什么调度事件下来的时候,NM还是分配不到container
节点每次进行addNode就不进行分配了
[2017-01-17T18:29:31.769+08:00] [INFO] resourcemanager.rmnode.RMNodeImpl.handle(RMNodeImpl.java 424) [AsyncDispatcher event handler] : xxx:50086 Node Transitioned from NEW to RUNNING
[2017-01-17T18:29:44.191+08:00] [INFO] scheduler.fair.FairScheduler.addNode(FairScheduler.java 899) [ResourceManager Event Processor] : Added node xxx:50086 cluster capacity: <memory:226007040, vCores:67872>
[2017-01-17T18:31:43.538+08:00] [INFO] hadoop.util.HostsFileReader.readFileToSetWithFileInputStream(HostsFileReader.java 88) [IPC Server handler 0 on 8033] : Adding xxx to the list of included hosts from xxx/hosts/mapred_hosts而且NodeUpdate的平均时间很低
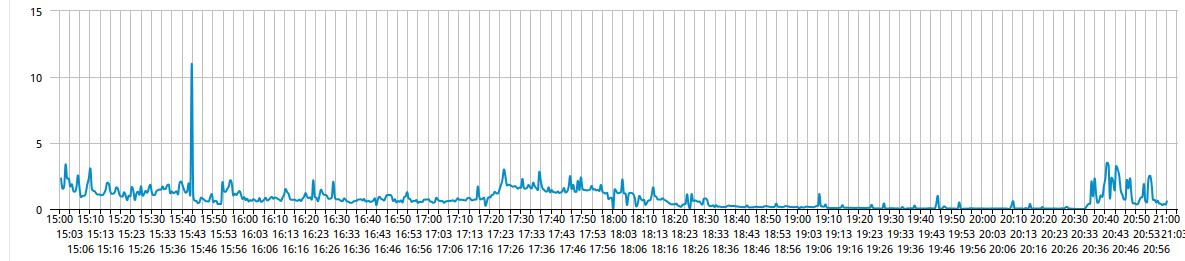
然后做出假设,假设NM没分配上
- 1.NM因为状态错误,RM认为他满了,资源不满足,所以跳过分配
- 2.NM因为被别的应用预留,状态错误,导致没分配
- 3.队列状态错误,导致RM认为队列资源满了,所以没分配
经过反复排查之后,都不能解释上面的问题,后来通过不断上线和下线节点在测试集群重现了改问题
后来发现了连续调度的操作次数一直没有增加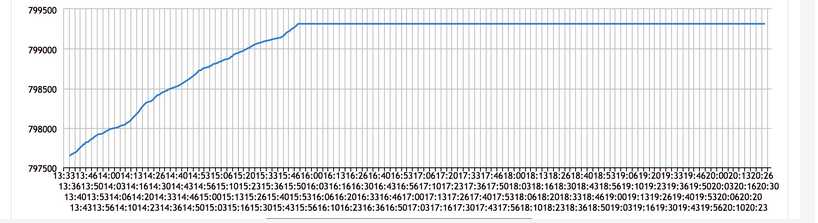
然后追踪该节点的日志,FairSchedulerContinuousScheduling线程因为timsort的bug导致线程退出了
[2017-01-17T15:52:12.791+08:00] [ERROR] hadoop.yarn.YarnUncaughtExceptionHandler.uncaughtException(YarnUncaughtExceptionHandler.java 68) [FairSchedulerContinuousScheduling] : Thread Thread[FairSchedulerContinuousScheduling,5,main] threw an Exception.
java.lang.IllegalArgumentException: Comparison method violates its general contract!
at java.util.TimSort.mergeLo(TimSort.java:747)
at java.util.TimSort.mergeAt(TimSort.java:483)
at java.util.TimSort.mergeCollapse(TimSort.java:410)
at java.util.TimSort.sort(TimSort.java:214)
at java.util.TimSort.sort(TimSort.java:173)
at java.util.Arrays.sort(Arrays.java:659)
at java.util.Collections.sort(Collections.java:217)
at org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler.continuousSchedulingAttempt(FairScheduler.java:1058)
at org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler$ContinuousSchedulingThread.run(FairScheduler.java:292)原因是我们开启了continuousSchedulingEnabled,当下线的节点重新注册时,completedContainers.isEmpty()肯定是true,新加入的节点无法加入调度,导致集群使用率越来越低
if (continuousSchedulingEnabled) {
if (!completedContainers.isEmpty()) {
attemptScheduling(node);
}
} else {
attemptScheduling(node);
}因为TimSort的compare函数不够严谨,然后引发这个bug,所以为了解决这个问题,可以在启动时加上一下参数
-Djava.util.Arrays.useLegacyMergeSort=true以下是提供的参考资料TimSort in Java 7
总 结
- 以后遇到集群慢的时候优先检查队列资源的使用率,如果对比两天的使用有明显差异应该出现了问题
- 关注每秒分配container的数据对比是否处于正常值
- 平均nodeupdate时间和连续调度的次数
[YARN] 基于ZKRMStateStore的Yarn的HA机制分析
- 十二月 12, 2016
- 0 条评论
前面已经说过HDFS的HA的相关机制简单了解NameNode的ZKFC机制,所以我们接着上面的说,YARN的HA切换由EmbeddedElectorService类控制,和ZKFailoverController的ElectorCallbacks一样,实现了ActiveStandbyElectorCallback接口,他们的区别是fenceOldActive方法的实现
private Stat fenceOldActive() throws InterruptedException, KeeperException {
.......
if (Arrays.equals(data, appData)) {
LOG.info("But old node has our own data, so don't need to fence it.");
} else {
appClient.fenceOldActive(data);
}
return stat;
}ZKFailoverController为,先GracefulFence,不行则进行真正的fence
private synchronized void fenceOldActive(byte[] data) {
HAServiceTarget target = dataToTarget(data);
try {
doFence(target);
} catch (Throwable t) {
recordActiveAttempt(new ActiveAttemptRecord(false, "Unable to fence old active: " + StringUtils.stringifyException(t)));
Throwables.propagate(t);
}
}而Yarn的HA则为
@Override
public void fenceOldActive(byte[] oldActiveData) {
if (LOG.isDebugEnabled()) {
LOG.debug("Request to fence old active being ignored, " +
"as embedded leader election doesn't support fencing");
}
}NameNode通过rpc或ssh kill的防止脑裂,而ZKRMStateStore是怎么在防止脑裂的呢?
在ZKRMStateStore中,大部分的操作都会在实际操作之前创建RM_ZK_FENCING_LOCK的文件,操作完成之后则删除对应的文件,这些操作是事务性的,这样意味着同时只有一个client去写rmstore目录,当有两个rm同时写,创建RM_ZK_FENCING_LOCK时则会抛出异常,同时rm则会捕获异常,并将自己的状态转化为standby的状态。
private synchronized void doDeleteMultiWithRetries( final List<Op> opList) throws Exception {
final List<Op> execOpList = new ArrayList<Op>(opList.size() + 2);
execOpList.add(createFencingNodePathOp); execOpList.addAll(opList);
execOpList.add(deleteFencingNodePathOp);
new ZKAction<Void>() {
@Override
public Void run() throws KeeperException, InterruptedException {
setHasDeleteNodeOp(true);
zkClient.multi(execOpList);
return null;
} }.runWithRetries(); }举一个例子,异常会被store.notifyStoreOperationFailed(e)处理
public void transition(RMStateStore store, RMStateStoreEvent event) {
......
try {
LOG.info("Storing RMDelegationToken and SequenceNumber");
store.storeRMDelegationTokenState(
dtEvent.getRmDTIdentifier(), dtEvent.getRenewDate());
} catch (Exception e) {
LOG.error("Error While Storing RMDelegationToken and SequenceNumber ",
e);
store.notifyStoreOperationFailed(e);
}
}这里就进行context相关的关闭,转化为standby的状态
/**
* This method is called to notify the ResourceManager that the store
* operation has failed.
* @param failureCause the exception due to which the operation failed
*/
protected void notifyStoreOperationFailed(Exception failureCause) {
if (failureCause instanceof StoreFencedException) {
updateFencedState();
Thread standByTransitionThread =
new Thread(new StandByTransitionThread());
standByTransitionThread.setName("StandByTransitionThread Handler");
standByTransitionThread.start();
} else {
rmDispatcher.getEventHandler().handle(
new RMFatalEvent(RMFatalEventType.STATE_STORE_OP_FAILED, failureCause));
}
}除了防止同时写的情况发生,ZKRMStateStore还在切换的时候对ZKRMStateStore的存储目录进行权限的设置,只允许自己读写,其他用户只有读的权限,我们可以通过zk命令去看到这样的权限设置
[zk: localhost:2181(CONNECTED) 27] ls /yarn-test/rmstore/ZKRMStateRoot
[AMRMTokenSecretManagerRoot, RMAppRoot, EpochNode, RMVersionNode, RMDTSecretManagerRoot]
[zk: localhost:2181(CONNECTED) 28] getAcl /yarn-test/rmstore/ZKRMStateRoot
'world,'anyone
: rwa
'digest,'xxx-xxxx-xxx15.hadoop.xxx.com:0vfG9l2cyt85oF5/H01oip5KEGU=
: cd参考资料
[YARN] FairScheduler的资源分配机制分析(一)
- 十一月 11, 2016
- 0 条评论
以下是队列资源分配的简单架构

调度器的container资源分配
通过简图可以看出,container是分配是随着每一次nodeupdate而进行资源分配的,在每一次尝试调度container之前,首先会检查改节点是否曾经有预留的app(预留指的是该node曾经因为资源不足,为了提高本地性原因,当节点有资源更新时,优先的把这个节点的资源分配给这个app的策略)
// 类名FairScheduler.java
// Assign new containers...
// 1. Check for reserved applications
// 2. Schedule if there are no reservations
FSAppAttempt reservedAppSchedulable = node.getReservedAppSchedulable();
if (reservedAppSchedulable != null) {
Priority reservedPriority = node.getReservedContainer().getReservedPriority();
FSQueue queue = reservedAppSchedulable.getQueue();
// 之前有预留,不满足条件则释放
if (!reservedAppSchedulable.hasContainerForNode(reservedPriority, node)
|| !fitsInMaxShare(queue,
node.getReservedContainer().getReservedResource())) {
// Don't hold the reservation if app can no longer use it
LOG.info("Releasing reservation that cannot be satisfied for application "
+ reservedAppSchedulable.getApplicationAttemptId()
+ " on node " + node);
reservedAppSchedulable.unreserve(reservedPriority, node);
reservedAppSchedulable = null;
} else {
// Reservation exists; try to fulfill the reservation
if (LOG.isDebugEnabled()) {
LOG.debug("Trying to fulfill reservation for application "
+ reservedAppSchedulable.getApplicationAttemptId()
+ " on node: " + node);
}
// 满足条件,则分配
node.getReservedAppSchedulable().assignReservedContainer(node);
}
}总的来说:
- 1、如果该app在该节点没有container的需求,则释放预留container
- 2、如果该app在该节点还有container的需求,但队列的MaxShare无法满足,则释放该节点预留的container
- 3、如果该app这个优先级的资源的请求已经为0,释放预留的container
否则检查这个node的可用资源和需求的资源是否满足,如果不满足,则预留,满足则分配
如果该节点没有app预留,则把该node从RootQueue进行分配下去,其中还有分配参数assignMultiple和maxAssign限制该node分配的container数量。
因为我们通过图可以知道,其实资源分配可以看成三层结构,ParetnQueue到LeafQueue,再到FSAppAttempt
那我们提出一个问题,当资源分配,如何选取最适合的队列?如何选取最适合的App?
在每次进行资源分配,都会采取排序的操作
Collections.sort(childQueues, policy.getComparator());app进行排序
Collections.sort(runnableApps, comparator);找出最适合的子队列和最适合的app, 对于采取fair算法策略的队列来说,其比较实现在FairShareComparator的compare方法中,对于每个可排序的Schedulable,包括叶子队列,FSAppAttempt,第一步都会计算两个Schedulable的minShare,即通过配置的最小资源要求和每个Schedulable的demand进行比较的最小值
Resource minShare1 = Resources.min(RESOURCE_CALCULATOR, null,
s1.getMinShare(), s1.getDemand());
Resource minShare2 = Resources.min(RESOURCE_CALCULATOR, null,
s2.getMinShare(), s2.getDemand());然后通过当前的资源使用和minshare进行比较等等,详细可以自行查看源码
boolean s1Needy = Resources.lessThan(RESOURCE_CALCULATOR, null,
s1.getResourceUsage(), minShare1);
boolean s2Needy = Resources.lessThan(RESOURCE_CALCULATOR, null,
s2.getResourceUsage(), minShare2);以上可以总结为,如果Schedulable都低于他们的minShare,则通过他们低于minShare的比例的多少来比较,例如,如果一个job A拥有8个task(minShare 10即比例为80%),job B拥有50个task(minShare 100即比例为50%),则job B将会有更高的优先级在下次资源分配时获取资源。
如果Schedulable在他们的minShare之上,则通过比较他们的(runningTasks/weight),如果所有的权重都相等,则slot资源需求少的job优先获得资源,另外,如果一个job拥有更高的权重则拥有机会获得多slot。
解决完选取子队列和app之后,接下来FSAppAttempt自身处理资源的问题了,也就是主要考虑这个FSAppAttempt的计算时的本地性问题
为了提升本地性,对于每个优先级,都会尝试的优先分配本地节点,然后再是机架,off-switch的请求通常会被延迟调度。
分配的策略简要为
从appSchedulingInfo中获取该节点或机架,该优先级对应的资源请求
ResourceRequest rackLocalRequest = getResourceRequest(priority,
node.getRackName());
ResourceRequest localRequest = getResourceRequest(priority,
node.getNodeName());然后满足条件的情况下尝试分配node local的节点,如果满足分配条件则分配成功,如果container的请求满足队列最大的MaxShare,则预留该节点给这个FSAppAttempt
if (rackLocalRequest != null && rackLocalRequest.getNumContainers() != 0
&& localRequest != null && localRequest.getNumContainers() != 0) {
return assignContainer(node, localRequest,
NodeType.NODE_LOCAL, reserved);
} 因为我们经常想优先的调度node-local的container, 其次再为rack-local和off-switch的container去保证最大可能的本地性,为了达到这个目标,我们首先对给定的优先级分配node-local,如果我们在很长的一段时间内没有成功调度,则放松本地性的阀值。
如上所述,通过判断上一次的NodeType类型去判断使用nodeLocalityThreshold( yarn.scheduler.fair.locality.threshold.node默认-1.0f ) 或 rackLocalityThreshold( yarn.scheduler.fair.locality.threshold.rack默认-1.0f ),从而去决定是否改变本地性级别。
if (getSchedulingOpportunities(priority) > (numNodes * threshold)) {
// 满足调度机会条件,则将NODE_LOCAL级别降为RACK_LOCAL级别
if (allowed.equals(NodeType.NODE_LOCAL)) {
allowedLocalityLevel.put(priority, NodeType.RACK_LOCAL);
resetSchedulingOpportunities(priority);
}
// 满足调度机会条件,则将RACK_LOCAL级别降为OFF_SWITCH级别
else if (allowed.equals(NodeType.RACK_LOCAL)) {
allowedLocalityLevel.put(priority, NodeType.OFF_SWITCH);
resetSchedulingOpportunities(priority);
}
}
// 否则本地性等级不变
return allowedLocalityLevel.get(priority);Application所需要的demand如何计算?
在FSAppAttempt中,其维护着每一个Application在Fair Scheduler的相关调度信息,包括Application所需要的demand,它的fairShare和allowedLocalityLevel等其他相关信息
然而在上文也有提到,每个FSAppAttempt或queue都会用它的minshare和demand比较,而demand是怎么来的呢?
在FSAppAttempt中,每一次AppMaster申请资源都会更新appSchedulingInfo里面的requests对象

在FairScheduler中则有线程定时的去调度UpdateThread线程,去重新更新每个队列,FSAppAttempt所需demand和重新计算FairShare等

每一层的demand等于min(下一层demand,最大资源分配),FSAppAttempt的demand则为当前使用的资源大小+未分配的资源大小
@Override
public void updateDemand() {
demand = Resources.createResource(0);
// Demand is current consumption plus outstanding requests
Resources.addTo(demand, getCurrentConsumption());
// Add up outstanding resource requests
synchronized (this) {
for (Priority p : getPriorities()) {
for (ResourceRequest r : getResourceRequests(p).values()) {
Resource total = Resources.multiply(r.getCapability(), r.getNumContainers());
Resources.addTo(demand, total);
}
}
}
}[YARN] FairScheduler设置AM的vcore无法生效
- 十月 27, 2016
- 0 条评论
在集群上了Linux Container之后,如果我们想增加AM在NM上获取时间片的能力,我们可以在配置文件中找到以下参数
<property>
<name>yarn.app.mapreduce.am.resource.cpu-vcores</name>
<value>15</value>
</property>该参数描述的是给AM多少个虚拟核,但是查看RM日志确发现,不管怎么设置AM的核数量都无法生效
[2016-10-27T16:36:37.280 08:00] [INFO] resourcemanager.scheduler.SchedulerNode.allocateContainer(SchedulerNode.java 153) [ResourceManager Event Processor] : Assigned container container_1477059529836_336635_01_000001 of capacity <memory:2048, vCores:1>原因是对于FairScheduler默认的策略说,每次都会对AM的提交请求进行规整,而且只会考虑mem的情况
SchedulerUtils.normalizeRequest(amReq, scheduler.getResourceCalculator(), scheduler.getClusterResource(), scheduler.getMinimumResourceCapability(), scheduler.getMaximumResourceCapability(), scheduler.getMinimumResourceCapability());在DefaultResourceCalculator类中,只对内存进行规整,createResource(memory, (memory > 0) ? 1 : 0),如果内存大于0,则默认变为1
@Override
public Resource normalize(Resource r, Resource minimumResource,
Resource maximumResource, Resource stepFactor) {
int normalizedMemory = Math.min(
roundUp(
Math.max(r.getMemory(), minimumResource.getMemory()),
stepFactor.getMemory()),
maximumResource.getMemory());
return Resources.createResource(normalizedMemory);
}所以在默认的DefaultResourceCalculator当中,当你不管怎么设置AM的核数都无法生效
[YARN] YARN的HA是如何工作的
- 九月 2, 2016
- 0 条评论
YARN的HA已经实现了Active和Standby的架构,即一个ResourceManager是Active,另一个ResourceManager处于Standby模式,如果Active出现问题,随时接管Active

在下面你将会了解到如何配置重启ResourceManager不会丢失任务的状态,如何对ResourceManager进行切换等相关信息。
ResourceManager状态存储
RM会把其内部的状态(applications和他们的attempts,delegation token和version信息)存储到指定的ResourceManagerStateStore中,NM的节点资源状态则通过心跳定期的汇报给RM.
对于状态存储的实现现有三种:
- 基于内存(主要用来测试)
- 基于文件系统(Hdfs或本地)
- 基于Zookeeper实现
对于ZKStore来说,RM的状态会不断的同步到外部的存储实现当中,其存储的目录结构如下:

RMState主要保存三个状态的数据:appState,rmSecretManagerState,amrmTokenSecretManagerState,其中appState由一个ApplicationId作为Key和ApplicationStateData做为value的TreeMap组成,每个ApplicationStateData包含了对应的apptemps的详细信息,当RM进行状态恢复时,会从zk的存储中,读取这些信息,恢复RMState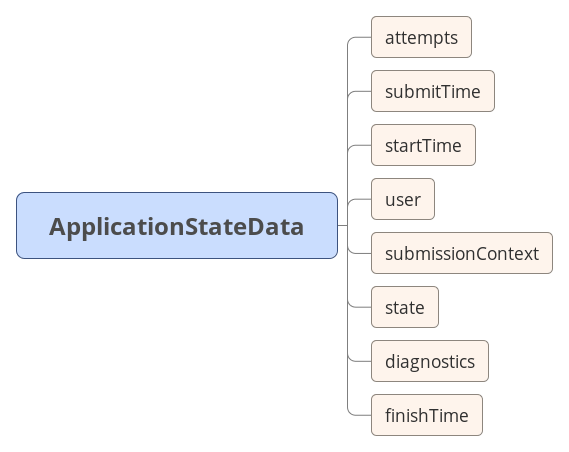
在
[YARN] NodeManager因为ContainerMetric导致OOM
- 八月 24, 2016
- 0 条评论
现象描述
之前hadoop2.7.1的集群,经常运行一段时间后会触发OOM,导致上面的map需要重跑,能想到的一种方案是调整GC参数,利用GC回收器对内存进行回收,另外一种情况则感觉代码可能处理有问题。
关键日志:
2016-07-05 09:35:40,907 WARN org.apache.hadoop.ipc.Client: Unexpected error reading responses on connection Thread[IPC Client (2069725879) connection to rmhost:8031 from yarn,5,main]
java.lang.OutOfMemoryError: Java heap space
at sun.nio.ch.EPollArrayWrapper.<init>(EPollArrayWrapper.java:120)
at sun.nio.ch.EPollSelectorImpl.<init>(EPollSelectorImpl.java:68)后来调整GC参数,追踪到底哪里出了问题,以下是参数参考
YARN_NODEMANAGER_OPTS="-Xmx2g -Xms2g -Xmn1g -XX:PermSize=128M -XX:MaxPermSize=128M -XX:+DisableExplicitGC -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/data1/yarn-logs/nm_dump.log -Dcom.sun.management.jmxremote -Xloggc:/data1/yarn-logs/nm_gc.log -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCApplicationStoppedTime -XX:+PrintGCApplicationConcurrentTime -XX:+PrintTenuringDistribution -XX:ErrorFile=/data1/yarn-logs/nm_err_pid"后来经过分析,确实是代码处理有问题 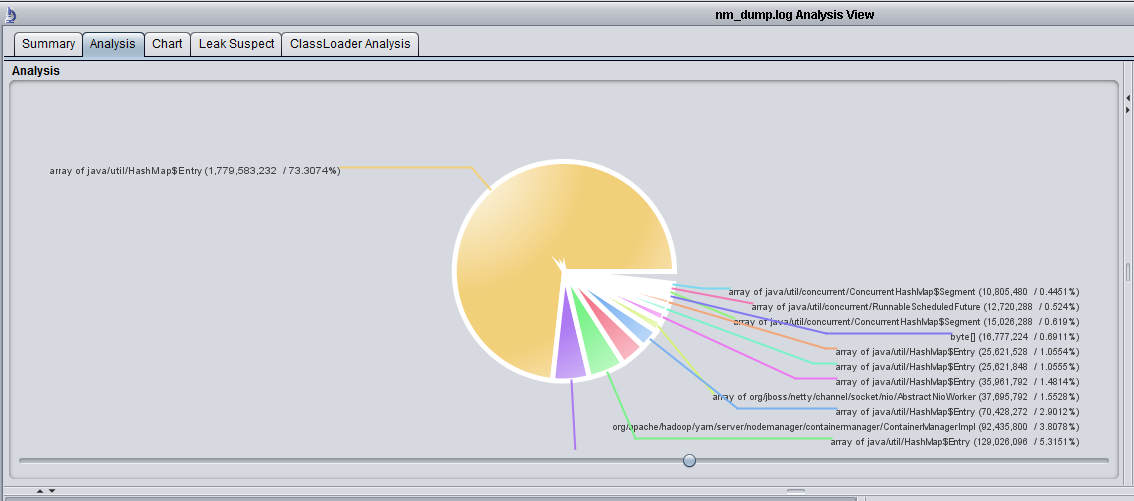
containerMetric占用了大部分内存 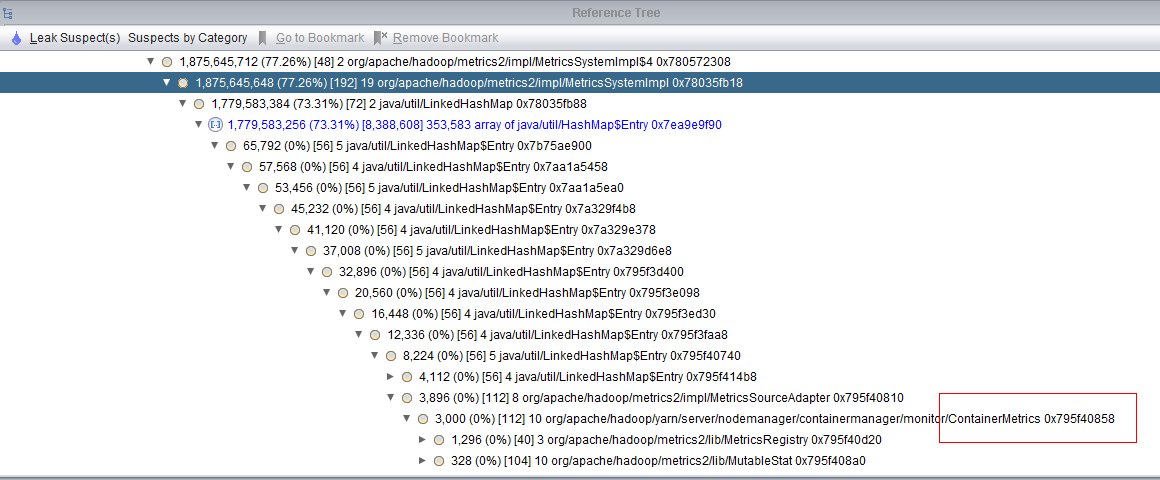
后来社区有patch可以修复HADOOP-13362
解决方案
- 1.关掉ContainerMetric,默认是开启的(yarn.nodemanager.container-metrics.enable默认true
改为false) - 2.打patch
参考工具
[YARN] Reduce一直被kill分析
- 七月 27, 2016
- 2 条评论
现象描述:
之前遇到有些任务在队列满时,reduce一直被kill,任务运行了很久,导致进入了死循环的状态,以下是原因分析
我们先看任务:
2016-05-31 19:29:46,382 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.TaskAttemptImpl: attempt_1464351197737_140388_m_000836_0 TaskAttempt Transitioned from NEW to UNASSIGNED到分配
2016-05-31 19:39:50,999 INFO [RMCommunicator Allocator] org.apache.hadoop.mapreduce.v2.app.rm.RMContainerAllocator: Assigned container container_e08_1464351197737_140388_01_001657 to attempt_1464351197737_140388_m_000836_0
2016-05-31 19:39:51,002 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.TaskAttemptImpl: attempt_1464351197737_140388_m_000836_0 TaskAttempt Transitioned from UNASSIGNED to ASSIGNED启动:
2016-05-31 19:39:51,002 INFO [ContainerLauncher #216] org.apache.hadoop.mapreduce.v2.app.launcher.ContainerLauncherImpl: Processing the event EventType: CONTAINER_REMOTE_LAUNCH for container container_e08_1464351197737_140388_01_001657 taskAttempt attempt_1464351197737_140388_m_000836_0开始跑:
2016-05-31 19:39:51,014 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.TaskAttemptImpl: attempt_1464351197737_140388_m_000836_0 TaskAttempt Transitioned from ASSIGNED to RUNNING完成清理相关信息,此时container已经退出,只是AM保存这个Task在这个机器的状态是success的:
2016-05-31 19:40:00,511 INFO [IPC Server handler 20 on 34613] org.apache.hadoop.mapred.TaskAttemptListenerImpl: Done acknowledgement from attempt_1464351197737_140388_m_000836_0
2016-05-31 19:40:00,512 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.TaskAttemptImpl: attempt_1464351197737_140388_m_000836_0 TaskAttempt Transitioned from RUNNING to SUCCESS_CONTAINER_CLEANUP
2016-05-31 19:40:00,518 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.TaskAttemptImpl: attempt_1464351197737_140388_m_000836_0 TaskAttempt Transitioned from SUCCESS_CONTAINER_CLEANUP to SUCCEED因为该节点是不可用的状态,打印了日志,原理是,如果该节点不可用则把该节点的TaskAttemp给kill了
2016-05-31 21:09:35,528 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.JobImpl: TaskAttempt killed because it ran on unusable node BJM6-Decare-14057.hadoop.jd.local:50086. AttemptId:attempt_1464351197737_140388_m_000836_0但是该Task是SUCCESS状态:
2016-05-31 21:09:35,529 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.TaskAttemptImpl: attempt_1464351197737_140388_m_000836_0 TaskAttempt Transitioned from SUCCEEDED to KILLED总的来说这个task完成了他自身的所有流程,程序也跑完了,就是因为NM汇报它自身为不健康节点导致AM把这个节点的所有Task给KILL了所以有SUCCEEDED to KILLED
每个Task完成都会触发AttemptSucceededTransition,会发送事件到AM中,触发TaskCompletedTransition,然后job.completedTaskCount++就进行相加了,也就是说每一个task完成都会被相加,直到所有的map跑完才执行reduce
private static class TaskCompletedTransition implements
MultipleArcTransition<JobImpl, JobEvent, JobStateInternal> {
@Override
public JobStateInternal transition(JobImpl job, JobEvent event) {
job.completedTaskCount++;
LOG.info("Num completed Tasks: " + job.completedTaskCount);
JobTaskEvent taskEvent = (JobTaskEvent) event;
Task task = job.tasks.get(taskEvent.getTaskID());
if (taskEvent.getState() == TaskState.SUCCEEDED) {
taskSucceeded(job, task);
} else if (taskEvent.getState() == TaskState.FAILED) {
taskFailed(job, task);
} else if (taskEvent.getState() == TaskState.KILLED) {
taskKilled(job, task);
}
return checkJobAfterTaskCompletion(job);
}所有有了以下日志:
2016-05-31 19:45:09,275 INFO [RMCommunicator Allocator] org.apache.hadoop.mapreduce.v2.app.rm.RMContainerAllocator: Before Scheduling: PendingReds:100 ScheduledMaps:0 ScheduledReds:0 AssignedMaps:2 AssignedReds:0 CompletedMaps:1885 CompletedReds:0 ContAlloc:1899 ContRel:9 HostLocal:1572 RackLocal:291
2016-05-31 19:45:09,279 INFO [RMCommunicator Allocator] org.apache.hadoop.mapreduce.v2.app.rm.RMContainerAllocator: Recalculating schedule, headroom=<memory:-4096, vCores:763>
2016-05-31 19:45:09,279 INFO [RMCommunicator Allocator] org.apache.hadoop.mapreduce.v2.app.rm.RMContainerAllocator: Reduce slow start threshold reached. Scheduling reduces.因为在Reduce跑着的过程中,发现map所在的机器的节点出现了不健康,所以AM把Task的状态SUCCESS转换为KILLED事件,进行Task的重新调度:
private static class MapTaskRescheduledTransition implements
SingleArcTransition<JobImpl, JobEvent> {
@Override
public void transition(JobImpl job, JobEvent event) {
//succeeded map task is restarted back
job.completedTaskCount--;
job.succeededMapTaskCount--;
}
}对应的数值开始减1,然后在心跳线程中重新申请资源preemptReducesIfNeeded:
if (recalculateReduceSchedule) {
preemptReducesIfNeeded();
scheduleReduces(
getJob().getTotalMaps(), completedMaps,
scheduledRequests.maps.size(), scheduledRequests.reduces.size(),
assignedRequests.maps.size(), assignedRequests.reduces.size(),
mapResourceRequest, reduceResourceRequest,
pendingReduces.size(),
maxReduceRampupLimit, reduceSlowStart);
recalculateReduceSchedule = false;
}如果map的数量大于0,集群资源不满足则kill reduce
@Private
@VisibleForTesting
void preemptReducesIfNeeded() {
if (reduceResourceRequest.equals(Resources.none())) {
return; // no reduces
}
//check if reduces have taken over the whole cluster and there are
//unassigned maps
if (scheduledRequests.maps.size() > 0) {
Resource resourceLimit = getResourceLimit();
Resource availableResourceForMap =日志都打印出来没什么好说的了:
2016-05-31 21:12:35,401 INFO [RMCommunicator Allocator] org.apache.hadoop.mapreduce.v2.app.rm.RMContainerAllocator: Going to preempt 1 due to lack of space for maps然后抢到资源:
2016-05-31 21:12:37,408 INFO [RMCommunicator Allocator] org.apache.hadoop.mapreduce.v2.app.rm.RMContainerAllocator: Assigned container container_e08_1464351197737_140388_01_002139 to attempt_1464351197737_140388_m_000836_1开始跑了
总结:
设置slow start阀值为1,map跑完后就开始跑Reduce了,但是过程中有些节点变成了不可用,所以相应的task就会从SUCCESS状态变为KILLED状态进行重新调度,因为所有的Reduce都开始跑队列资源沾满的情况下,开始尝试kill自己的Reduce看能不能抢到资源,抢不到继续KILL,直到抢到运行完map为止,Reduce才能继续执行。
[YARN] 简单了解FairShare是如何进行计算的?
- 十一月 13, 2015
- 2 条评论
这个我一直处于看了忘,忘了看的过程,所以决定把总结写下。
在此之前,先提两个问题
- 队列配置的Max Resources加起来超过集群资源的总量时,会有什么影响?
- 队列使用的资源量不会超过我们设置的Max Resources?
我使用的版本是Apache hadoop 2.2.0,所以下都是基于该版本进行分析的。
在YARN中,我们都是通过队列的方式进行资源管理的,队列中可以建立子队列,队列可以通过配置不同的属性,包括提交权限,资源大小,权重等,对于FS来说,每个队列都被抽象成一个Schedulable,其计算过程就是给定一系列的Schedulable和一系列的slot,计算出他们的加权fairshare(weighted fair share)。
资源公平性计算
如果我们不设置minumum share和maximum share,加权fairshare的R = soltAssigned / weight(默认1),可以看出每个Schedulable都可以获得相同的资源量
在实际中,有些Schedulable可能会出现minShare高于他们设置的maxShare或者maxShare低于他们分配的share值,为了处理这些类似的问题,资源分配需要满足:
- 如果S.minShare > R*S.weight,则分配S.minShare
- 如果S.maxShare < R*S.weirht,则分配S.maxShare
- 其他则分配R*S.weight
主要计算实现:ComputeFairShares
基本原理:
- 0.首先计算每个schedulable的maxShare的值的和与totalResource比较,取最小值
- 1、rMax=1
- 2、计算当前的使用量U
- 3、如果U < TotalResource,则rMax = rMax*2,跳转2
- 定义left=0,right=rMax
- 4、mid =(left + right)/ 2
- 5、计算当前的使用量U
- 6、如果U<TotalResource,left = mid
- 7、否则right = mid
- 8、当前迭代次数<规定迭代次数,跳转4,否则退出
- 9、通过right值计算每个schedulable的FairShare
如何计算当前资源的使用量U,通过尝试w2rRatio的值,计算出每个schedulable资源的使用量之和,使之接近于资源总量
private static int resourceUsedWithWeightToResourceRatio(double w2rRatio, Collection<? extends Schedulable> schedulables) {
int resourceTaken = 0;
for (Schedulable sched : schedulables) {
int share = computeShare(sched, w2rRatio);
resourceTaken += share;
}
return resourceTaken;
}上述所说的主要方法
private static int computeShare(Schedulable schedulable, double w2rRatio) {
double share = schedulable.getWeight() * w2rRatio;
share = Math.max(share, schedulable.getMinShare());
share = Math.min(share, schedulable.getMaxShare());
return (int) share;
}说完如何计算fairshare的基本流程,下面来讨论FairSharePolicy是如何对slot进行分配的
对于FairScheduler的FairSharePolicy机制,它采用的是DefaultResourceCalculator,即只对内存做资源计算,规则为通过比较两个Schedulable的加权fairShare(weighted fair sharing),那些低于minShare的Schedulable将会比那些高于minShare的拥有更高的优先级获取资源。
如果Schedulable都低于他们的minShare,则通过他们低于minShare的比例的多少来比较,例如,如果一个job A拥有8个task(minShare 10即比例为80%),job B拥有50个task(minShare 100即比例为50%),则job B将会有更高的优先级在下次资源分配时获取资源。
如果Schedulable在他们的minShare之上,则通过比较他们的(runningTasks/weight),如果所有的权重都相等,则slot资源需求少的job优先获得资源,另外,如果一个job拥有更高的权重则拥有机会获得多slot。
另外还有一张图:

总结
这篇文档,断断续续写了很久,温故知新,能有让自己能有对FS调度有个较为全面的认识。
[YARN] Hadoop2.7.1 Linux Container和CGroup配置笔记
- 十月 29, 2015
- 0 条评论
在新版本的hadoop中,配置linux container已经不需要在每台机器上新建用户了,让使用变得更加灵活,之前我用的是2.2版本,详细的看官网,2.7.1的配置在这里,具体配置就不多说了
secure container
对于配置的权限,还是会有要求,container-executor.cfg文件需要root权限,和其父目录等向上拥有者为root,所以,可以把改文件放置到/etc/目录下满足其要求,同时方便配置同步管理,然而,container-executor的默认读取路径是$HADOOP_HOME/etc/hadoop/目录下,所以我们需要传入指定路径去重新编译container-executor,该文件权限可以设置为6050。
mvn package -Pdist,native -DskipTests -Dtar -Dcontainer-executor.conf.dir=/etc编译完成后,就可以检查是否成功了
strings container-executor | grep etc关于Cgroup
要开启该功能,在新机器中要确保安装开启和内核支持该功能
在yarn配置了CGroup的模式下,它是通过cpu.cfs_period_us,cpu.cfs_quota_us,cpu.shares来对container进行CPU的资源控制。
举个例子:
假设我们设置yarn.nodemanager.resource.percentage-physical-cpu-limit参数为80和yarn.nodemanager.linux-container-executor.cgroups.strict-resource-usage参数为true(假设测试虚拟机的核数为4),在该模式下所有container能使用的核数为
yarnProcessors = nodeCpuPercentage * numProcessors = 0.8 * 4 = 3.2CPU shares为
cpuShares = CPU_DEFAULT_WEIGHT * containerVCores = 1024 * 1其中CPU_DEFAULT_WEIGHT=1024代表一个CPU时间
即containers能使用的核数量为3.2个,然后通过公式:
containerCPU = (containerVCores * yarnProcessors) / nodeVCores注: nodeVCore为配置NM的核数为4,containerVCores为应用为每个container申请的核数
即按照上面的公式得到containerCPU为1*3.2除以4=0.8,然后根据quotaUS = periodUS * containerCPU,即1000*1000*0.8得到800000,即cpu.cfs_quota_us的值,即该进程使用的CPU不会超过80%,当应用申请的container核数为2时,得到shares为2048,意味着其将会获得比1024多2倍的CPU时间,由此类推。
参考资料
[YARN] Yarn下Mapreduce的内存参数理解
- 九月 20, 2015
- 2 条评论
这篇文章算是给自己重新缕清MR下内存参数的含义
Container是什么?
Container就是一个yarn的java进程,在Mapreduce中的AM,MapTask,ReduceTask都作为Container在Yarn的框架上执行,你可以在RM的网页上看到Container的状态
基础
Yarn的ResourceManger(简称RM)通过逻辑上的队列分配内存,CPU等资源给application,默认情况下RM允许最大AM申请Container资源为8192MB(“yarn.scheduler.maximum-allocation-mb“),默认情况下的最小分配资源为1024M(“yarn.scheduler.minimum-allocation-mb“),AM只能以增量(”yarn.scheduler.minimum-allocation-mb“)和不会超过(“yarn.scheduler.maximum-allocation-mb“)的值去向RM申请资源,AM负责将(“mapreduce.map.memory.mb“)和(“mapreduce.reduce.memory.mb“)的值规整到能被(“yarn.scheduler.minimum-allocation-mb“)整除,RM会拒绝申请内存超过8192MB和不能被1024MB整除的资源请求。
相关参数
YARN
- yarn.scheduler.minimum-allocation-mb
- yarn.scheduler.maximum-allocation-mb
- yarn.nodemanager.vmem-pmem-ratio
- yarn.nodemanager.resource.memory.mb
MapReduce
Map Memory
- mapreduce.map.java.opts
- mapreduce.map.memory.mb
Reduce Memory
- mapreduce.reduce.java.opts
- mapreduce.reduce.memory.mb

从上面的图可以看出map,reduce,AM container的JVM,“JVM”矩形代表服务进程,“Max heap”,“Max virtual”矩形代表NodeManager对JVM进程的最大内存和虚拟内存的限制。
以map container内存分配(“mapreduce.map.memory.mb“)设置为1536为例,AM将会为container向RM请求2048mb的内存资源,因为最小分配单位(“yarn.scheduler.minimum-allocation-mb“)被设置为1024,这是一种逻辑上的分配,这个值被NodeManager用来监控改进程内存资源的使用率,如果map Task堆的使用率超过了2048MB,NM将会把这个task给杀掉,JVM进程堆的大小被设置为1024(“mapreduce.map.java.opts=-Xmx1024m“)适合在逻辑分配为2048MB中,同样reduce container(“mapreduce.reduce.memory.mb“)设置为3072也是.
当一个mapreduce job完成时,你将会看到一系列的计数器被打印出来,下面的三个计数器展示了多少物理内存和虚拟内存被分配
Physical memory (bytes) snapshot=21850116096
Virtual memory (bytes) snapshot=40047247360
Total committed heap usage (bytes)=22630105088虚拟内存
默认的(“yarn.nodemanager.vmem-pmem-ratio“)设置为2.1,意味则map container或者reduce container分配的虚拟内存超过2.1倍的(“mapreduce.reduce.memory.mb“)或(“mapreduce.map.memory.mb“)就会被NM给KILL掉,如果 (“mapreduce.map.memory.mb”) 被设置为1536那么总的虚拟内存为2.1*1536=3225.6MB
当container的内存超出要求的,log将会打印一下信息
Current usage: 2.1gb of 2.0gb physical memory used; 1.6gb of 3.15gb virtual memory used. Killing container.mapreduce.map.java.opts和mapreduce.map.memory.mb
大概了解完以上的参数之后,mapreduce.map.java.opts和mapreduce.map.memory.mb参数之间,有什么联系呢?
通过上面的分析,我们知道如果一个yarn的container超除了heap设置的大小,这个task将会失败,我们可以根据哪种类型的container失败去相应增大mapreduce.{map|reduce}.memory.mb去解决问题。 但同时带来的问题是集群并行跑的container的数量少了,所以适当的调整内存参数对集群的利用率的提升尤为重要。
因为在yarn container这种模式下,JVM进程跑在container中,mapreduce.{map|reduce}.java.opts能够通过Xmx设置JVM最大的heap的使用,一般设置为0.75倍的memory.mb,因为需要为java code,非JVM内存使用等预留些空间
补充一下
对于FairScheduler来说(其他我也没看),存在着一个增量参数
/** Increment request grant-able by the RM scheduler.
* These properties are looked up in the yarn-site.xml */
public static final String RM_SCHEDULER_INCREMENT_ALLOCATION_MB =
YarnConfiguration.YARN_PREFIX + "scheduler.increment-allocation-mb";
public static final int DEFAULT_RM_SCHEDULER_INCREMENT_ALLOCATION_MB = 1024;对于线上2560MB最小分配内存,客户端的内存为2048,incrementMemory为1024,通过其计算算法得出值,demo如下
/**
* Created by shangwen on 15-9-14.
*/
public class TestCeil {
public static void main(String[] args) {
int clientMemoryReq = 2048;
int minAllowMermory = 2560;
int incrementResource = 1024;
System.out.println(roundUp(Math.max(clientMemoryReq,minAllowMermory),incrementResource));
// output 3072
}
public static int divideAndCeil(int a, int b) {
if (b == 0) {
return 0;
}
return (a + (b - 1)) / b;
}
public static int roundUp(int a, int b) {
System.out.println("divideAndCeil:" + divideAndCeil(a, b));
return divideAndCeil(a, b) * b;
}
}得出的结果为3072MB,即对于map来说,则会分配3G内存,即使你在客户端写的是2G,所以你可以看到以下日志:
Container [pid=35691,containerID=container_1441194300243_383809_01_000181] is running beyond physical memory limits. Current usage: 3.0 GB of 3 GB physical memory used; 5.4 GB of 9.3 GB virtual memory used.对于56G内存的NM来说,如果全部跑map则56/3大约跑18个container
假设修改最小分配为默认的1024,则分配的内存为2G,即大约可以跑56/2约28个container。
通过上述的描述,大概就对其参数有个比较综合的了解了。
参考资料















 2091
2091

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









