










最近在复习期末考,就顺便把这些笔记保存下来,也方便以后查看,涉及的都是一些基础知识,大牛勿喷啊,有错误之处欢迎指教~~~~
首先,当然得记住一些常用的词汇啊!!!下面就把会出现的词汇都大概的总结出来,方便查看,省得满文章的去找(英语好的就自行跳过吧!)。当然,不是纯纯的单词翻译,后面跟的文字可能是翻译也可能是他用到的地方。
-DBCC ShrinkDataBase :收缩数据库
- Constraint :约束 (数据完整性约束条件定义时用到)
- Primary Key :主键约束
- Unique :唯一性约束
- Clustered | Nonclustered :聚集索引或非聚集索引
- Check: 检查约束
- Default :默认约束
- Foreign Key:外键约束
- On update Cascade On deleteCascade :外键约束中的级联更新和删除
- SQL: Structured Query Language 结构化查询语言
- Having :筛选组
- Exists:存在
- Union:联合
- Truncate Table :清空表(不记录日志操作,无法恢复)
- Begin Transaction :事务开始
- Commit Transaction :事务结束,执行过程成功
- Rollback Transaction: 事务回滚,执行过程出错
- Set Implicit_Transactions On:隐式事务开始
- Set Implicit_Transactions Off:隐式事务关闭
- @@Trancount:检测连接事务处理嵌套的层数
- Sysobjects:主要记录新表的基本信息
- Syscolumns :主要记录新表的列信息
- Sysindexes:主要记录指向新表锁使用的存储空间和主键等信息。
- excute:执行
- @@fetch_status:取得最后一次游标数据提取操作结果状态,0表示成功,-1表示失败,-2表示要取得行不在记录集内,已从集合中删除。
- PROCEDURE:存储过程
数据库基础和设计
- 数据库系统包括数据库、数据库管理系统、数据库的用户和支撑数据库管理系统运行的软硬件。
- 数据库五个常用的对象是:表、存储、视图、触发器、索引。
- 数据库对象的三种关系:一对一、一对多、多对多。
- 信息是有用的数据,数据是信息的表现形式。信息的特点是:无限性、共享性、创造性。
- 模式是数据库中全体数据的逻辑结构和特征的描述。数据库的三级模式:内模式(物理层)、概念模式(逻辑层)、外模式(用户层)。
- 数据库系统的用户结构:单用户结构、主从式结构、客户-服务器模式结构和分布式结构。
- 第一范式:在一个关系中消除重复的字段,且每个字段都是最小的逻辑存储单位。
- 第二范式:所有非主键字段完全依赖于主键,不存在非主键字段部分依赖主键。
- 第三范式:去除传递依赖(不要包含可以通过计算得到或推导得到的字段)。
数据库结构和管理
- 主数据文件(.mdf):数据库的起点,可以指向数据库中文件的其他部分。
- 次数据库文件(.ndf)
- 事务日志文件(.ldf):包含恢复数据库所需的所有日志信息。
- 收缩数据库 DBCC SHRINKDATABASE(数据库名称,收缩后的大小)
表的存储原理及完整性创建管理
- 数据类型:
- 数值型:BIGINT , INT , SMALLINT , TINYINT , DECIMAL和NUMERIC , FLOAT 和 REAL
- 货币型:MONEY , SMALLMONEY
- 字符型:CHAR , VARCHAR , TEXT
- 日期时间类型:DATETIME , SMALLDATETIME
- 完整性约束条件
- 空值约束 : null | not null
- 主键约束:Constraint PK_课程表_课号 PRIMARY KEY (课号)
- 唯一性约束:Constraint 约束名 unique [ clustered | nonclustered] (列名)
- 检查约束:Constraint CK_课程表_课号 check(课号 like ‘s[0-9][0-9][0-9][0-9]’)
- 默认约束:性别 char(2) Default ‘男’
- 外部键约束:Constraint FK_开课表_课号 Foreign Key (课号) References 课程表(课号) on update cascade on delete cascade(包含了级联删除和修改)
- 修改表结构:ALETR 跟属性列有关的约束和索引删除后,指定的属性才能删除。
- 使用DROP Table 语句不能删除系统表和被Foreign Key 约束所参照的用户表,必须先删除引用的外键约束或引用的表。
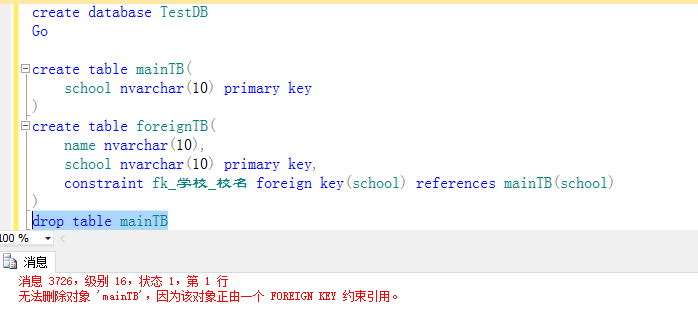
~~~感觉分不清哪张表可以删除,哪张不可以了????下面就用例子说明吧,如下所示:创建了两张表,mainTB和foreignTB,foreignTB中的学校字段受外键约束,此时我们不能删除mainTB,而foreignTB是可以直接删除的,当然,如果删除了foreignTB则mainTB也就可以删除了!
查询处理和表数据编辑
- 起别名:当别名有空格时要加上”,eg: ‘new name’。
- Distinct关键字作用的范围是整个查询列表,而不是单个的列,因此distinct要放在select后面。
- 涉及空值的查询,要用exp is [not] null,而不能用”=“ 或者 ”!=“ 或者 ” <>“代替。
- 如果在select中用了计算列,并且要求按这个计算列进行排序,则在order by子句中有三种方式表示:
1.计算列的顺序编号 2.计算列的表达式 3.计算列的别名
select 学号,成绩,成绩+10 as 新成绩
from 学生表
order by 3 --第二种方式:计算列的顺序编号
order by 成绩 +10 --第二种方式:计算列的表达式
order by 新成绩 --第三种方式:计算列的别名- 分组查询
Group by 子句可以将查询结果集按一列或多列取值相等的原则进行分组。
--查询个门课程的课程名级相应的选课人数
select 开课号,count(学号) From 选课表 group by 开课号group by 子句中的列名只能是From子句所列表的列名,而不能是别名。
select目标列表达式所涉及的列必须满足,要么在group by 子句中,要么在某个统计函数中。
--查询学号前5位为"s0601"且选修了两门以上课程的学生的学号
select 学号 from 选课表 where 学号 like 's0606%' group by 学号 having count(*) >=2
where 和 having的区别:
1.作用对象不同(where -> 表;having -> 组);
2.选择条件的构成有差异,where 条件不能直接包含统计函数,而having条件所涉及的列必须要么在group by子句中,要么在某个统计函数中。
- 连接查询
普通连接
join on 连接 (Inner join)
外连接(左连接left outer join,右连接 right outer join,全连接 full outer join) - 子查询
对子查询结果集的检查包括:
检查给定值是否在结果集中(用in连接子查询和父查询);
检查给定值和结果值中元素的大小比较(单值比较;多值比较);
检查结果集是否为空。
--查询选修了开课计划编号为010101的课程的学生姓名
select 姓名
from 学生表 as s
where exists (
select * from 选课表 as s
where e.学号=s.学号 and 开课号='010101'
)
--***** 这类查询的特点:
--***** 1.子查询的条件往往用到父查询所涉及的表;
--***** 2.子查询的select 子句一般写成select * 即可,无需给出具体列名;//获取前8条记录 desc降序 asc升序
select top 8 * from newsTab where type='通知通告' order by zhiding desc,id desc;插入子查询结果
1.使用insert select 子句 要自己创建表
2.使用select into 子句 系统自己创建表(当目标列是计算列时必须取别名)删除数据
可以使用delete from 表名 或者 Truncate Table 语句来清空目标表(比delete快 不记录日志操作,他的删除无法恢复)
索引
- 索引是对数据库中一个或多个列的值进行排序的结构。
作用:
通过创建唯一索引,可以保证数据记录的唯一性。
可以大大加快数据检索的速度。
可以加速表与表之间的连接。
使用order by子句和group by子句进行检索数据时,可以显著减少查询中分组和排序的时间。
索引可以在检索的过程中使用查询优化器,提高系统性能。索引分类
聚集索引:逻辑有序,物理也有序,一个表只能有1个;
非聚集索引:逻辑有序,物理无序,一个表只能有249个;索引的创建和删除
--索引的创建
create [unique] [clustered|nonclustered]
index 索引名
on 数据表|视图(字段 asc|desc)
--索引的删除
drop index 表名.索引名事务
- 事务的特性:原子性、一致性、隔离性、永久性。
- 事务时恢复和并发的基本单位。
- 事务并发的数据问题:丢失修改或被覆盖、读脏数据、不能重复读、幻影读。
- 事务分类:显示事务、隐式事务、自动事务模式(SQL SERVER默认的)。
- 显示事务:
begin transaction --语句开始
commit transaction / commit work --事务结束 执行成功
rollback transaction / rollback work --事务结束 执行失败- 隐式事务
所有的create语句,alert table ,所有的drop语句,Truncate table,grant,revork,insert,delete,update,select,open,fetch都会重新启动一个事务。
set Implicit_Transactions on --隐式事务打开
set Implicit_Transactions off --隐式事务关闭@@Trancount检测连接事务处理嵌套的层数。
- 基本锁
共享锁(S锁):用于只读操作,它允许多个事务对资源锁定进行读取,但禁止其他事务对锁定资源进行修改。
排它锁(X锁) :它锁定的资源不能再被其他事务锁定,所以其他事务不能读取和修改。
Transact-SQL程序结构
批是一组sql语句的集合,一个批以GO结束,使用批的基本规则:
1.所有create语句应该单独做成一个批,不能再批中和其他sql语句一起使用。
2.使用alter table修改表结构以后, 不能再同一个批中使用新定义的列。
3.excute语句为批中的第一个语句时,可以省略excute关键字。
4.批命令GO与其他sql语句不能再用一行上。转换函数
cast (<表达式> as <目标数据类型> [(<长度>)])
convert(<目标数据类型> [(<长度>)],<表达式>[,style])Case语句用法
CASE <输入表达式>
When <当表达式1> Then <结果表达式1>
When <当表达式2> Then <结果表达式2>
................
When <当表达式n> Then <结果表达式n>
{Else <结果表达式n+1>}
END
CASE
WHEN <条件表达式1> Then <结果表达式1>
WHEN <条件表达式2> Then <结果表达式2>
................
WHEN <条件表达式n> Then <结果表达式n>
{Else <结果表达式n+1>}
END视图规划和操作
视图对应三级模式中的外模式,视图中存储着视图的定义及其关联的基本表的信息,而不存放视图对应的数据,这些数据仍然存放在导出视图的基本表中,因此视图有称为虚拟表。
数据库中使用视图的主要优点:
- 视图能简化用户的操作;
- 视图是用户能以多角度看待同一数据;
- 视图为数据库重构提供了一定程度的逻辑独立性;
- 视图能够对机密数据提供安全保护。
--创建视图的语法格式
create view view_name
as
select_statement --定义视图的select子句
[with check option] --强制视图上执行的所有数据修改语句都必须符合由select_statement设置的准则
with encryption --表示sql server加密包含create view 语句的文本系统表列,可防止将视图作为sql server复制的一部分发布。
--创建视图时,视图的名字存在sysobjects表中,有关视图所定义的列信息添加到syscolumns表中,而有关视图相关性的信息存储在
--sysdepends表中,另外,create view 语句的文本添加到syscomments表中。
eg:
USE 教学管理
IF exists (select table_name from information_schema.views where table_name='V_视图名')
drop view V_视图名
GO
CREATE view V_视图名
WITH ENCPYPTION
AS
SELECT 课号,课名,教材
FROM 课程表
WHERE 所在院系='信息学院'
WITH CHECK OPTION
GO--修改视图
alert view view_name
as
select_statement
[with check option]
--使用alert view 更改当前正在使用的视图,sql server将为他提供一个排他架构锁。
--视图重命名
exec sp_rename 'V_oldname','V_newname'--删除视图
drop view view_name当视图引用多个表时,无法用delete删除数据,若使用update,则应当与insert一样,被更新的列必须属于同一个表。
select_statement在选择列表中没有聚合函数,也不包括top,group by,union或distinct子句。
select_statement列表中没有派生列。
一个update或insert语句只能修改引用的一个基表中的数据。
当视图在from子句中只引用一个表时,delete语句才能引用可更新的视图。
游标
游标提供了一种对从表中检索出数据进行操作的灵活手段,就本质而言,有标识实际上是一种包括多条数据记录的记过集中每次提取一条记录的机制。
sql server支持三种类型的游标:Transact-SQL 游标、API服务器游标、客户游标。
--游标的申明
DECLARE <游标名> cursor
[local|global]
[forward_only|scroll] --forward_only只进游标,
[static|keyset|dynamic|fast_forwar] --static静态游标,不能随时反应用户的更改结果 dynamic动态游标,能随时反应用户的更改结果
[read_only|scroll_locks|optimistic]
FOR <select 查询>
eg:
declare 学生表_cur1 cursor
for select 学号,姓名
from 学生表 where 专业='计算机'
--打开游标
open 游标名
--读取游标数据
fetch [next | prior | first | last |absolute{n|@nvar} | relative {n|@nvar} from ] --next 返回结果集的第一行
--prior | first | last |absolute{n|@nvar} | relative {n|@nvar}只有定义了scroll选项才可以使用
游标名
into @变量1,@变量2--关闭游标
close 游标名
--close语句关闭游标,但不释放游标占用的数据结构,应用程序可以再次执行open打开和填充游标eg:
declare 学生表_cur1 cursor
for select 学号,姓名,所在院系
from 学生表
group by 学号
declare @snum char(5),
@sname char(10),
@sdepa char(10)
--打开游标
open 学生表_cur1
--取游标第一行数据
fetch next from 学生表_cur1 into @snum,@sname,@sdepa
--逐行显示教师信息,并取下一行数据
while @@fetch_status = 0
BEGIN
select @snum,@sname,@sdepa
fetch next from 学生表_cur1
into @snum,@sname,@sdepa
END
--关闭游标,此时还可以重新打开
close 学生表_cur1
--释放游标
deallocate 学生表_cur1
go游标定位修改和删除操作
--游标定位修改和删除操作
--语法格式:
--游标定位修改update语句:
update 表名
set 子句
where current of 游标名
--游标定位删除delete语句:
delete from 表名
set 子句
where current of 游标名
--利用where current of进行的修改或删除只影响当前行
--eg:首先查看学生表中的每一行,将学号="s060109"的记录的移动电话改为13888320247,并将城市改为天津
declare @学号 char(6) ,@姓名 char(10),@电话 char(11),@籍贯 char(10)
declare stu_up_cur cursor
for
select 学号,姓名,电话,籍贯
from 学生表
for update of 电话,籍贯
open stu_up_cur cursor
fetch next from stu_up_cur cursor into @学号,@姓名,@电话,@籍贯
while @@fetch_status=0
begin
select @学号,@姓名,@电话,@籍贯
if @学号='s060109'
update 学生表 set 电话='13888320247',籍贯='天津'
where current of stu_up_cur cursor --利用where current of进行的修改或删除只影响当前行
fetch next from stu_up_cur cursor into @学号,@姓名,@电话,@籍贯
end
close stu_up_cur cursor
deallocate stu_up_cur cursor
用户自定义函数设计
用户自定义函数分为三种类型:标量类型函数(返回在returns子句中定义的类型的单个数据),内嵌表值型函数(以表的类型返回一个返回值),多语句表值型函数(返回一个表)
不能在函数中进行的操作有:对数据库表的修改,对不在函数上的局部游标进行操作,发送电子邮件,尝试修改目录,以及生成返回至用户的结果集。
--创建标量值用户自定义函数
--语法格式
create function function_name
return scalar_return_data_type
begin
function body
return scalar_expression
end
--eg:创建成绩转换标量值函数,实现百分制与优 良 中 及格 不及格的转化
use 教学管理
go
create function F_分数等级(@成绩 float)
return char(16)
as
begin
declare @等级 char(16)
select @等级= case
when @成绩 is null then '还没有参加考试'
when @成绩<60 then '不及格'
................
end
return @等级
END
--调用方式
select 学号,DBO.F_分数等级(成绩) as '成绩等级' from 学生表 where 学号='s060606'
--创建内联型用户自定义函数
--语法格式
create function function_name
return table
begin
return select_stmt
end
--eg:创建内联型函数,返回指定学院的学生信息
use 教学管理
go
create function F_学生信息(@院系 char(20))
return table
as
return(select 学号,性别 from 学生表 where 所在院系=@院系)
--调用方式
select * from DBO.F_学生信息('信息学院')--创建多语句表值型函数
--语法格式
create function function_name
return @return_variable table
as
begin
function body
return
end
--eg:创建多语句表值型函数,返回执行教师某年的开课信息
use 教学管理
go
create function F_教师课表(@教师姓名 char(20),@开课学年 char(9))
return @教师课表 table(
课名 varchar(30),
开课地点 char(6),
已选人数 int
)
as
begin
insert @教师课表
select 课名,开课地点,已选人数
from 教师表 T,开课表 O
where T.工号=O.工号
AND 开课学年=@开课学年
return
end
调用方式
select * from DBO.F_教师课表('张三','2015-2016')使用alert Function 命令相当于重建一个同名的函数
不能用alert Function更改函数的类型,也就是:标量值函数、表值型函数、多语句函数不能相互转化
删除函数:drop function function_name
存储过程和用户存储过程的设计
存储过程是一组完成特定功能的sql语句集,经编译后存储在数据库中。
在sql server中存储过程分为两类:系统提供的存储过程和用户自定义的存储过程。
系统过程主要存储在master数据库中并以sp_为前缀,系统存储过程主要是从系统表中获取信息,从而为系统管理员管理sql server提供支持。
用户自定义存储过程是由用户创建并能完成某一个特定功能的存储过程。
存储过程的优点:
- 存储过程允许标准组建式编程。
- 存储过程能实现较快的执行速度。
- 存储过程能减少网络流量。
- 存储过程可作为一种安全机制来充分利用。
- 自动完成需要预先执行的任务。
存储过程虽然既有参数又有返回值,但他与函数不同,存储过程的返回值只是指明执行是否成功,并且他不能像函数那样直接被调用,在调用存储过程名字前一定要有exec保留字。
存储过程由三部分组成:
- 所有的输入参数及传给调用者的输出参数。
- 执行的针对数据库的操作语句,包括调用其它存储过程的语句。
- 返回给调用者的状态值,以指明调用是成功还是失败。
--创建一个带参数的存储过程,实现对指定的某一专业某门课程学生选课及成绩的查询。
use 教学管理
go
if exists (select * from sysobjects where name='p_学生选课信息' and type='p')
BEGIN
DROP PROCEDURE P_学生选课信息
END
GO
CREATE PROCEDURE P_学生选课信息(@专业 char(20),@课名 char(20))
as
if @专业 is null
begin
print '必须指定专业'
end
else
begin
select s.学号,姓名,专业,所在院系,o.课号,o.课名,o.成绩
from 学生表 as s,选课表 as E,开课表 as o,课程表 c
where 专业=@专业 and 课名=@课名 and s.学号=e.学号 and e.开课号=o.开课号 and o.课号=c.课号
end
--执行存储过程
exec P_学生选课信息 '计算机','数据结构'修改存储过程 alter
删除存储过程 drop procedure 存储过程名
触发器原理及使用
触发器可以看成一类特殊的存储过程,他在满足某个特定条件时自动触发执行,触发器是为表上的更新、插入、删除操作定义的,也就是说,当表上发生更新、插入和删除操作时触发器将执行。
触发器的主要作用就是能够实现主键和外键所不能保证的复杂的参照完整性和数据一致性。触发器还有很多功能:
- 强化约束。
- 级联运行。
存储过程的调用。
触发器的种类:
AFTER触发器:该类型触发器要求只有执行完某一操作[INSERT | UPDATE | DELETE ],并处理过所有约束后,触发器才能被触发,且只能在表上定义。
INSTEAD OF 触发器:该类触发器表示并不执行所定义的操作[INSERT | UPDATE | DELETE ],而仅执行触发器本身。既可以在表上也可以在视图上。
触发器原理:
每个触发器有两个特殊的表:插入表和删除表,分别为inserted 和 delete,有下列几个特点:这两个表是逻辑表,并且这两个表都是由系统管理的,存储在内存,不是存储在数据库中,因此不允许用户直接对其修改。
- 这两个表的结构总是与被该触发器作用的表有相同的表结构。
- 这两个表是动态驻留在内存中,当触发器工作完成时,这两个表也被删除。
这两个表是只读的,且只在触发器内部可读,即用户不能向这两个表写入内容,但可以在触发器中引用表的数据。
插入表的功能:
一旦对该表执行了插入操作,那么对该表插入的所有行来说,都有一个相应的副本存放到插入表(inserted )中,即插入表存储原表插入的新数据行。
删除表的功能:
一旦对该表执行了删除操作,则将所有被删除的行存放到删除表(delete)中。
--insert触发器
--在大学数据库中,当新的学生选课注册信息添加到选课表中时,要对开课表中的人数进行更新,且当人数超过最多能容纳的人数时,要提示选课人数已满
USE 教学管理
GO
CREATE trigger T_选课表插入触发
ON 选课表
FOR insert
AS
Begin
DECLARE @已选人数 int,@限选人数 int
select @已选人数=已选人数+1,@限选人数=限选人数
from 开课表 o,inserted i
where o.开课号=i.开课号
if(@已选人数 > @限选人数)
begin
print '选修人数已满'
rollback transaction
end
update 开课表
set 已选人数=@已选人数
from 开课表 o,inserted i
where o.开课号=i.开课号
End--update触发器
--教师表里的工号和负责人必须有外键关联,当负责人工号修改了,负责人内容也要更着修改,使用触发器实现当某个负责人工号修改了,级联修改负责人
use 教学管理
go
create trigger T_负责人工号变化
on 教师表
for update
AS
Begin
declare @old_工号 char(6),@new_工号 char(6)
select @old_工号=工号
from deleted
select @new_工号=i.工号
from inserted i
update 教师表
set 负责人=@new_工号
where 负责人=@old_工号
end--delete触发器
--当某个学生退学时,须删除该学生的基本数据,并级联删除该学生的选课记录。
use 教学管理
go
create trigger T_学生数据删除
on 学生表
for delete
AS
Begin
delete from 选课表 from 选课表 e,deleted d
where e.学号=d.学号
end--insert of触发器
--当删除教师表的某个教师时,需要先查看开课表是否有该教师的代课情况,有则不能删除,否则可以删除。
use 教学管理
go
create trigger T_教师数据删除
on 教师表
instead of delete
as
begin
declare @姓名 char(20)
select @姓名=姓名 from deleted
if exIsts(select * from 开课表 o,deleted d where o.工号=d.工号) print @姓名+'不能删除'
else
begin
delete from 教师表 from 教师表 T ,deleted d where T.工号=d.工号
print @姓名+'删除成功'
end
end














 353
353

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









