







本系列文章由 @YhL_Leo 出品,转载请注明出处。
文章链接: http://blog.csdn.net/yhl_leo/article/details/50311869
尽管大多数人认为手机是传统有线电话服务的延伸,事实上,手机技术是极其复杂而且堪称神奇的技术。很少有人意识到这些小型设备为了维持一个电话谈话需要每秒执行数百万次的计算,如果我们细看将语音电子信号转换为比特序列的模块,就会发现每20毫秒的输入语音就会被计算出一组语音参数然后传输到接收端,之后接收端再将这组参数转换为语音。本文将介绍手机语音传输中的核心——线性预测分析合成技术 (linear predictive (LP) analysis-synthesis)。

世界首款商用移动手机 Motorola DynaTAC 8000x
1 语音的线性预测处理背景
语音是由我们喉咙产生的一种激励信号,通过声带、鼻、咽部等共振调整出每个人所具有的不同的形式。这种激励信号,可以通过我们周期性地开启和关闭声带产生(例如语音中的元音),也可以仅仅是一些肺部推动的连续气流(例如语音中末尾的语气音),或者是两种结合在一起的方式等。
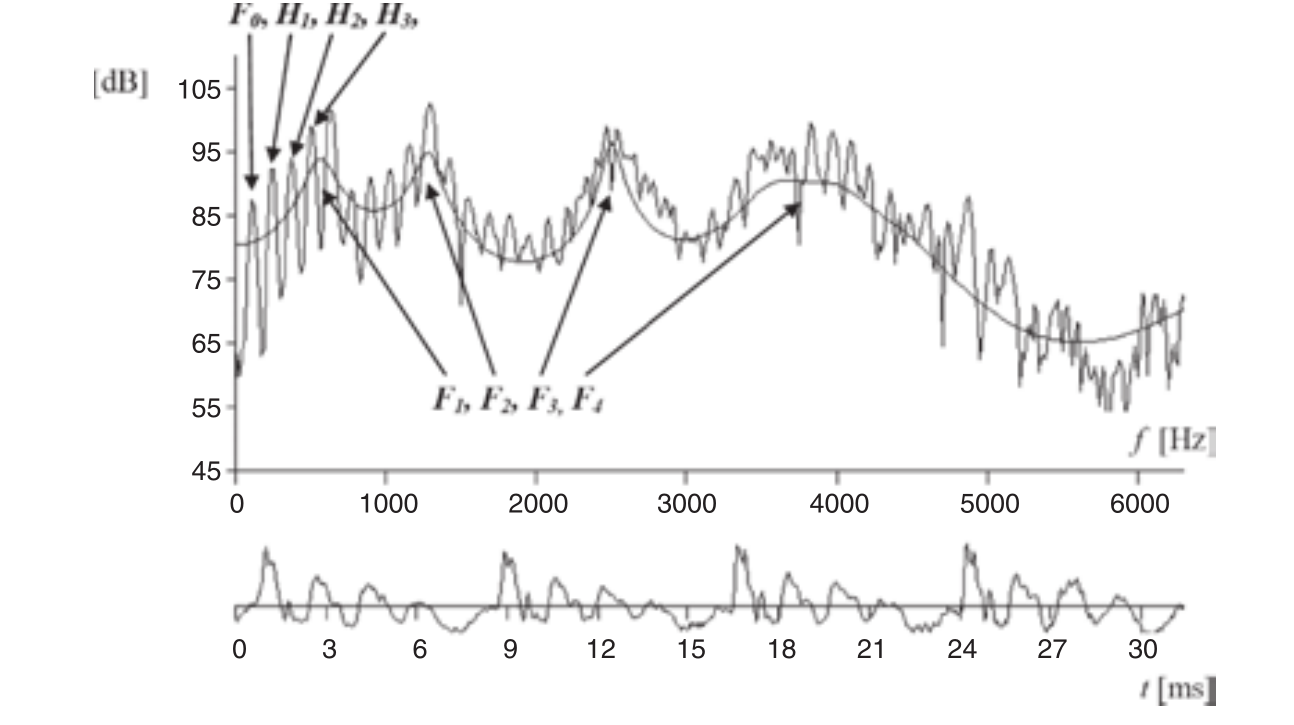
图 1 一段30毫秒的声音信号
如图 1所示,一段30毫秒的声音信号(底部)和它对应的波谱(这里显示的是其FFT的大小)。其中 F0 是基频,我们可以称之为音高(Pitch)(严格来讲,音高是指感知到的基频)。谐波或者谐频(Harmonics)是指像 H1,H2,H3 等峰值处对应的频率声波。共振峰(Formants)是指像 F1,F2,F3 等出现在频谱包络宽峰处。
1.1 语音的线性预测处理模型
早在1960年,Fant就提出一种语音的线性处理模型,称之为source-filter模型。它基于这样的假设:声门和声道是完全分离的。这个模型最终由Rabiner and Shafer(1978)发展成为有名的线性预测模型(linear predictive,LP)或者称为自我回归模型(autoregressive,AR),后来又被逐渐被广泛应用在语音编码中,所以也被称为语音线性预测编码模型(linear predictive coding,LPC):
其中, S~(z) 和 E~(z) 是Z-变换后的语音信号和激励信号(Z-变换,将时域信号(即:离散时间序列)变换为在复频域的表达式), p 是prediction order。整个过程如图 2所示:
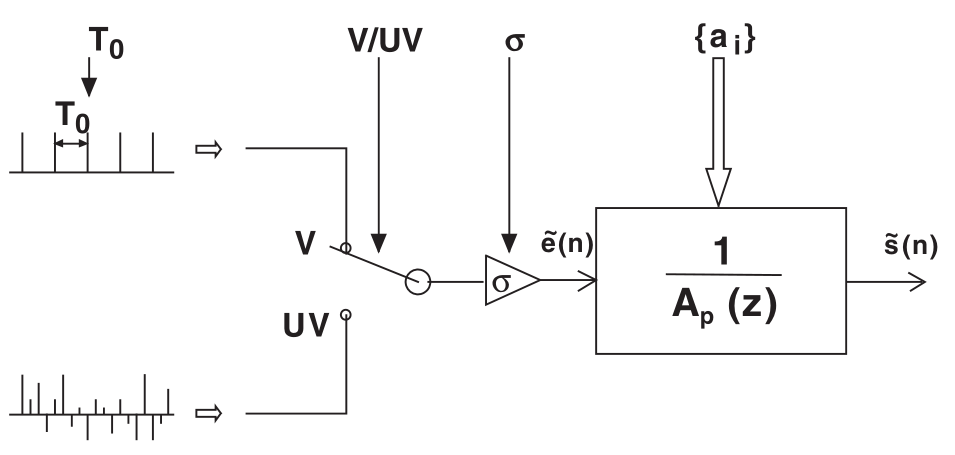
图 2 语音生成的LP模型
在这一模型中,LP模型的激励被认为是一串定期间隔的脉冲(其周期
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 8307
8307











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









