










 本文介绍了一种基于线性预测编码(LPC)的语音合成方法,通过调整激励信号提高合成语音质量,并提供了MATLAB代码实现。
本文介绍了一种基于线性预测编码(LPC)的语音合成方法,通过调整激励信号提高合成语音质量,并提供了MATLAB代码实现。
本系列文章由 @YhL_Leo 出品,转载请注明出处。
文章链接: http://blog.csdn.net/yhl_leo/article/details/50359613
根据前面的博客,我们如果将之前的语音帧的处理通过循环,作用在整段语音上,当然就可以得到合成整段语音~
同样我们还是讲语音帧设为30毫秒,相邻帧之间的重叠度为20毫秒,仍然使用Hamming加权窗。在合成的时候,每次合成10毫秒的语音,然后连接后面的语音。另外,我们这里固定合成语音的基频 F0 为200Hz,为了省事,每10毫秒的语音对应的激励脉冲只包含两个脉冲信号,请看下面的代码实现:
clc; clear;
[speech,fs,bits] = wavread('h_orig.wav');
figure(1);
plot(speech);
synt_speech_HF = [];
for i=1:(length(speech)-160)/80; % number of frames
% Extracting the analysis frame
input_frame=speech((i-1)*80+1:(i-1)*80+240);
% Hamming window weighting and LPC analysis
[ai, sigma_square]=lpc(input_frame.*hamming(240),10);
sigma=sqrt(sigma_square);
% Generating 10 ms of excitation = 2 pitch periods at 200 Hz
excitation=[1;zeros(39,1);1;zeros(39,1)];
gain=sigma/sqrt(1/40);
% Applying the synthesis filter
synt_frame=filter(gain, ai,excitation);
% Concatenating synthesis frames
synt_speech_HF=[synt_speech_HF;synt_frame];
end
figure(2);
plot(synt_speech_HF);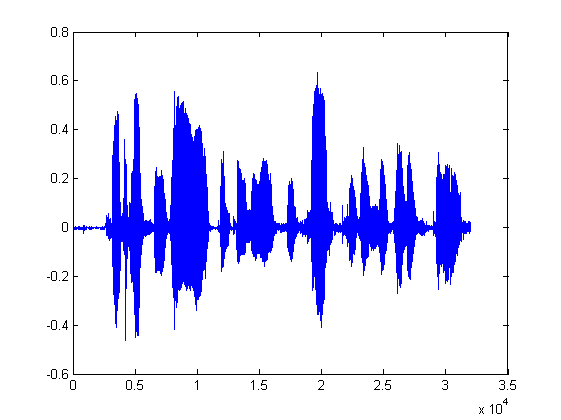
图 1 原始语音波形
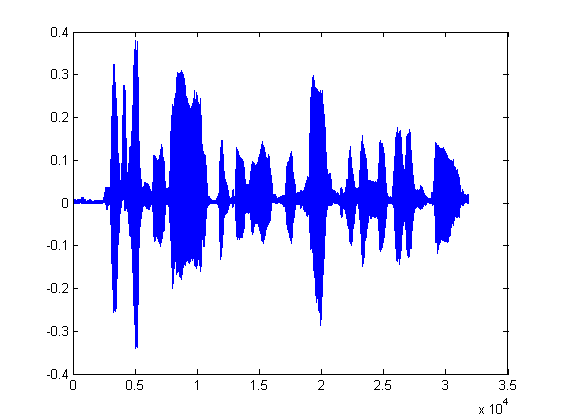
图 2 LP合成语音波形
从整体上看,两者的波形比较相似,但是还是可以看出两者还是有点差距的,原语音中前半部分的振幅跟中间部分的一个片段是相似的,但合成语音中前半部分明显高于后半部分,这是由于采用的激励信号过于简单,现在我们调整一下:
for i=1:(length(speech)-160)/80; % number of frames
% Extracting the analysis frame
input_frame=speech((i-1)*80+1:(i-1)*80+240);
% Hamming window weighting and LPC analysis
[ai, sigma_square]=lpc(input_frame.*hamming(240),10);
sigma=sqrt(sigma_square);
% Generating 10 ms of excitation taking a possible offset into account
% if pitch period length > excitation frame length
if offset>=80
excitation=zeros(80,1);
offset=offset-80;
else
% complete the previously unfinished pitch period
excitation=zeros(offset,1);
% for all pitch periods in the remaining of the frame
for j=1:floor((80-offset)/N0)
% add one excitation period
excitation=[excitation;1;zeros(N0-1,1)];
end;
% number of samples left in the excitation frame
flush=80-length(excitation);
if flush~=0
% fill the frame with a partial pitch period
excitation=[excitation;1;zeros(flush-1,1)];
% remember to fill the remaining of the period in next frame
offset=N0-flush;
else offset=0;
end
end
gain=sigma/sqrt(1/N0);
% Applying the synthesis filter
synt_frame=filter(gain, ai,excitation);
% Concatenating synthesis frames
synt_speech_HF=[synt_speech_HF;synt_frame];
end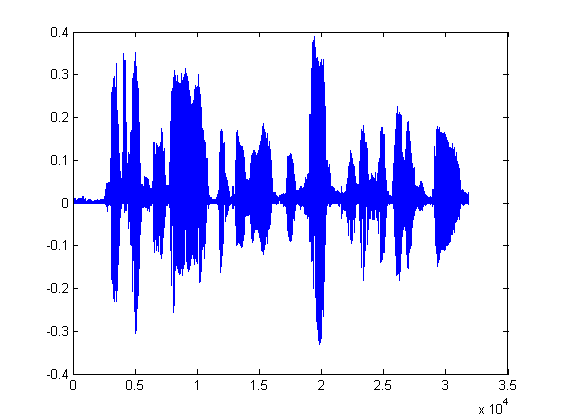
图 3 LP合成语音波形
这样是不是跟原信号更加接近了?

















 8836
8836

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









