







 本文介绍了如何采用SDN方法管理FCoE存储网络流量,通过结合传统方法与SDN,解决了OpenFlow协议在存储流控制上的不足。通过主动与反应式控制策略,优化了流量瓶颈,增强了存储流量的控制能力。
本文介绍了如何采用SDN方法管理FCoE存储网络流量,通过结合传统方法与SDN,解决了OpenFlow协议在存储流控制上的不足。通过主动与反应式控制策略,优化了流量瓶颈,增强了存储流量的控制能力。
note:本文基本思想来自论文 ,介绍了一种类似于SDN openflow的方法,并将它应用于fcoe网络中。这种控制流的方法可以和openflow为协议的sdn流控制方法共存,但是又不完全一样,算是扩展了OpenFlow协议的数据平面和控制平面:)
problem
存储网络到虚拟网络中的融合
因为数据中心的资源需要按需控制,网络虚拟化和sdn都已经积极地推动了数据中心的网络。然而,用软件完全控制网络还存在一些问题。要达到细粒度的控制存在一个问题。而且,软件控制对于高速度的反应(高速流量)可能不是那么有效果。更进一步来说,即使openflow近来作为控制流层次的交换机非常流行,也没有足够的特性来控制存储流;它缺乏特性去深入处理存储的包。
FCOE的几个问题
存在流量瓶颈问题,如下图所示:
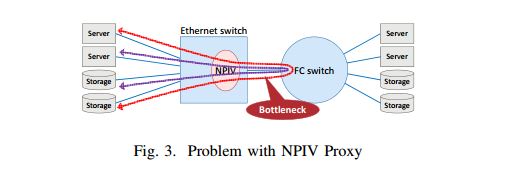
对于NPIV代理方式的FCoE拓扑可能会存在一个网络的瓶颈,但但经过这个瓶颈的很多流量其实却是可以避免的。
设计思想
使用sdn方法来控制存储流量
基本思想是传统方法和sdn方法的结合;
考虑控制粒度的问题,物理交换机应该提供细粒度和高速的控制;
如果我们将以太网交换机部署为reactive当时的openflow交互,所有来自未知地址的包都会被送到控制器,导致很高的控制平面的开销。这个问题可以使用proactive方式解决,如果我们有节点位置的信息。另外一方面,sdn并不适合故障控制,我们可以使用reactive方式(利用fip处理)来控制fcoe流,fip的频率并不是很高,并不会导致控制器过高的开销。
增强的存储流量控制方法
比起LAN,FCoE基本上没有被OpenFlow控制。openflow可以看到ip源地址和目的地址,协议,tcp端口号等信息,然而,却无法识别fip的字段,比如D_ID(目的 fc id)。所以对于交换机来说能够处理存储流的包信息是非常重要的。
原型和评价
原型
平台:融合光纤网,我们使用了融合的光纤交换机(自产的)。CFABRIC由一个交换机Blade和ToR交换机和管理软件组成。
包括一个交换机固件和一个控制器。
交换机固件:
除了基本的交换机功能之外,还有两个功能,一个是抓住FIP包把他们转发给控制器,第二个是检测FCoE流。如果控制器告诉它要怎么转发FCoE包,那就乖乖听从控制器的指令,修改转发表。

额外的交换机配置命令被使用(自研发),来达到上述的这些功能。使得外部的控制器可以控制流(就像OpenFlow一样)。就是需要加入FCoE处理的部分。
控制器
包括主要四个功能:分析fip包(要能够抓出l3的内容来),能够确定终端位置,能够计算合适的路由,能够发送指令给交换机。我们主要用下图来描述控制器的操作。
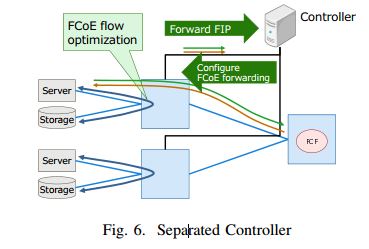
总结:原型的中心思想就是要在数据平面能够实现识别fcoe的功能,然后在控制器端可以实现根据fcoe的l3(D_ID)来进行转发。他让这个交换机真正变成了一个fcoe交换机(和 ip路由器进行对比)。
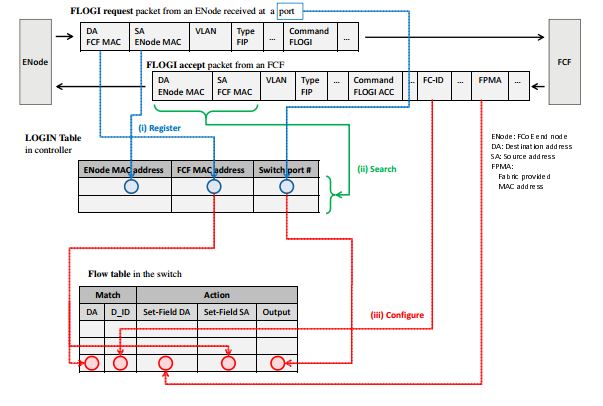
首先,交换机将FIP包发送给控制器(匹配以太网类型的动作)。然后,控制器分析这个FIP包,然后将FCoE流转发的指令发送给交换机。总体结构如下图所示:
参考文献:
[1]Shiraki O, Nakagawa Y, Hyoudou K, et al. Managing storage flows with SDN approach in I/O converged networks[C]//Globecom Workshops (GC Wkshps), 2013 IEEE. IEEE, 2013: 890-895.

















 950
950

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









