







 本文介绍了SparkSQL的使用,包括环境配置、Spark shell启动、SQLContext和hiveContext的演示。重点讲解了如何通过Case Class和applySchema创建SchemaRDD,以及读取parquet和json文件。还展示了如何在sqlContext和hiveContext中使用SQL查询,并讨论了cache和DSL的使用。此外,文章还探讨了SparkSQL在Spark生态系统中的综合应用,如店铺分类和PageRank算法的实现。
本文介绍了SparkSQL的使用,包括环境配置、Spark shell启动、SQLContext和hiveContext的演示。重点讲解了如何通过Case Class和applySchema创建SchemaRDD,以及读取parquet和json文件。还展示了如何在sqlContext和hiveContext中使用SQL查询,并讨论了cache和DSL的使用。此外,文章还探讨了SparkSQL在Spark生态系统中的综合应用,如店铺分类和PageRank算法的实现。
【注】该系列文章以及使用到安装包/测试数据 可以在《倾情大奉送–Spark入门实战系列》获取
1 运行环境说明
1.1 硬软件环境
- 主机操作系统:Windows 64位,双核4线程,主频2.2G,10G内存
- 虚拟软件:VMware® Workstation 9.0.0 build-812388
- 虚拟机操作系统:CentOS 64位,单核
- 虚拟机运行环境:
- JDK:1.7.0_55 64位
- Hadoop:2.2.0(需要编译为64位)
- Scala:2.10.4
- Spark:1.1.0(需要编译)
- Hive:0.13.1
1.2 机器网络环境
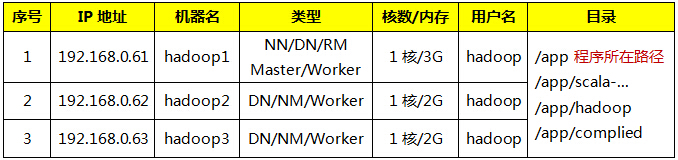
集群包含三个节点,节点之间可以免密码SSH访问,节点IP地址和主机名分布如下:
2 Spark基础应用
SparkSQL引入了一种新的RDD——SchemaRDD,SchemaRDD由行对象(Row)以及描述行对象中每列数据类型的Schema组成;SchemaRDD很象传统数据库中的表。SchemaRDD可以通过RDD、Parquet文件、JSON文件、或者通过使用hiveql查询hive数据来建立。SchemaRDD除了可以和RDD一样操作外,还可以通过registerTempTable注册成临时表,然后通过SQL语句进行操作。
值得注意的是:
- Spark1.1使用registerTempTable代替1.0版本的registerAsTable
- Spark1.1在hiveContext中,hql()将被弃用,sql()将代替hql()来提交查询语句,统一了接口。
- 使用registerTempTable注册表是一个临时表,生命周期只在所定义的sqlContext或hiveContext实例之中。换而言之,在一个sqlontext(或hiveContext)中registerTempTable的表不能在另一个sqlContext(或hiveContext)中使用。
另外,Spark1.1提供了语法解析器选项spark.sql.dialect,就目前而言,Spark1.1提供了两种语法解析器:sql语法解析器和hiveql语法解析器。
- sqlContext现在只支持sql语法解析器(SQL-92语法)
- hiveContext现在支持sql语法解析器和hivesql语法解析器,默认为hivesql语法解析器,用户可以通过配置切换成sql语法解析器,来运行hiveql不支持的语法,如select 1。
- 切换可以通过下列方式完成:
- 在sqlContexet中使用setconf配置spark.sql.dialect
- 在hiveContexet中使用setconf配置spark.sql.dialect
- 在sql命令中使用 set spark.sql.dialect=value
SparkSQL1.1对数据的查询分成了2个分支:sqlContext 和 hiveContext。至于两者之间的关系,hiveSQL继承了sqlContext,所以拥有sqlontext的特性之外,还拥有自身的特性(最大的特性就是支持hive)。
2.1 启动Spark shell
2.1.1 环境设置
使用如下命令打开/etc/profile文件:
sudo vi /etc/profile
设置如下参数:
export SPARK_HOME=/app/hadoop/spark-1.1.0
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
export HIVE_HOME=/app/hadoop/hive-0.13.1
export PATH=$PATH:$HIVE_HOME/bin
export CLASSPATH=$CLASSPATH:$HIVE_HOME/bin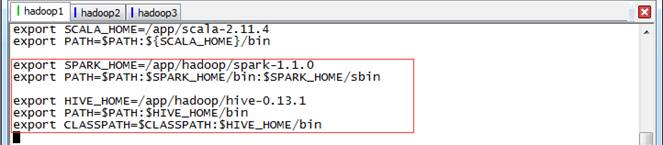
2.1.2 启动HDFS
$cd /app/hadoop/hadoop-2.2.0/sbin
$./start-dfs.sh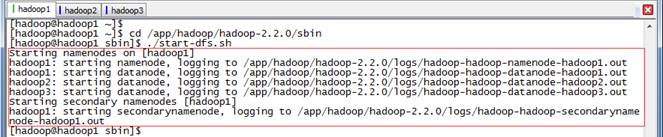
2.1.3 启动Spark集群
$cd /app/hadoop/spark-1.1.0/sbin
$./start-all.sh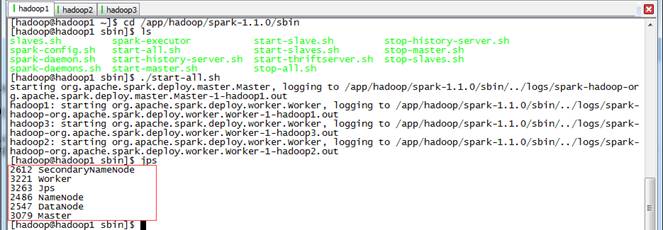
2.1.4 启动Spark-Shell
在spark客户端(在hadoop1节点),使用spark-shell连接集群
$cd /app/hadoop/spark-1.1.0/bin
$./spark-shell --master spark://hadoop1:7077 --executor-memory 1g 
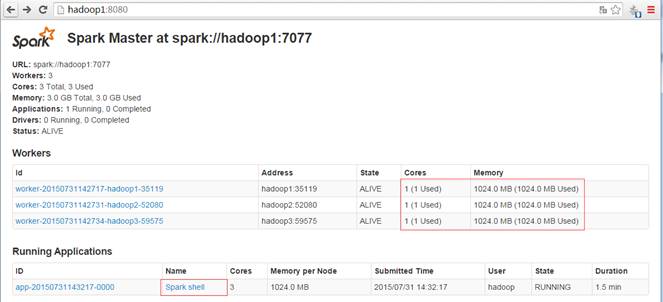
启动后查看启动情况,如下图所示:
2.2 sqlContext演示
Spark1.1.0开始提供了两种方式将RDD转换成SchemaRDD:
- 通过定义Case Class,使用反射推断Schema(case class方式)
- 通过可编程接口,定义Schema,并应用到RDD上(applySchema 方式)
前者使用简单、代码简洁,适用于已知Schema的源数据上;后者使用较为复杂,但可以在程序运行过程中实行,适用于未知Schema的RDD上。
2.2.1 使用Case Class定义RDD演示
对于Case Class方式,首先要定义Case Class,在RDD的Transform过程中使用Case Class可以隐式转化成SchemaRDD,然后再使用registerTempTable注册成表。注册成表后就可以在sqlContext对表进行操作,如select 、insert、join等。注意,case class可以是嵌套的,也可以使用类似Sequences 或 Arrays之类复杂的数据类型。
下面的例子是定义一个符合数据文件/sparksql/people.txt类型的case clase(Person),然后将数据文件读入后隐式转换成SchemaRDD:people,并将people在sqlContext中注册成表rddTable,最后对表进行查询,找出年纪在13-19岁之间的人名。
第一步 上传测试数据
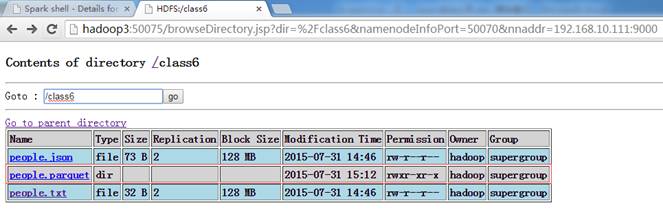
在HDFS中创建/class6目录,把配套资源/data/class5/ people.txt上传到该目录上
$hadoop fs -mkdir /class6
$hadoop fs -copyFromLocal /home/hadoop/upload/class6/people.* /class6
$hadoop fs -ls /
第二步 定义sqlContext并引入包
//sqlContext演示
scala>val sqlContext=new org.apache.spark.sql.SQLContext(sc)
scala>import sqlContext.createSchemaRDD
第三步 定义Person类,读入数据并注册为临时表
//RDD1演示
scala>case class Person(name:String,age:Int)
scala>val rddpeople=sc.textFile("hdfs://hadoop1:9000/class6/people.txt").map(_.split(",")).map(p=>Person(p(0),p(1).trim.toInt))
scala>rddpeople.registerTempTable("rddTable")
第四步 在查询年纪在13-19岁之间的人员
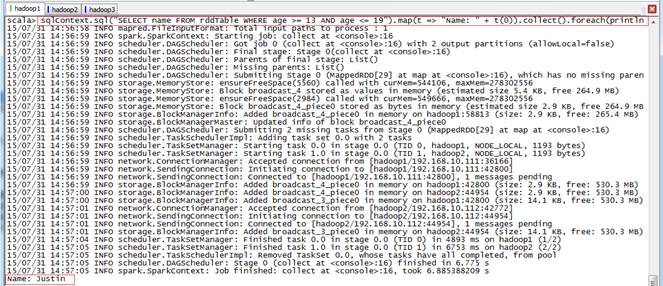
scala>sqlContext.sql("SELECT name FROM rddTable WHERE age >= 13 AND age <= 19").map(t => "Name: " + t(0)).collect().foreach(println)上面步骤均为trnsform未触发action动作,在该步骤中查询数据并打印触发了action动作,如下图所示:
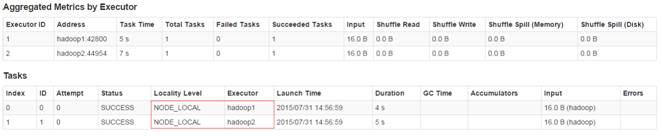
通过监控页面,查看任务运行情况:

2.2.2 使用applySchema定义RDD演示
applySchema 方式比较复杂,通常有3步过程:
- 从源RDD创建rowRDD
- 创建与rowRDD匹配的Schema
- 将Schema通过applySchema应用到rowRDD
第一步 导入包创建Schema
//导入SparkSQL的数据类型和Row
scala>import org.apache.spark.sql._
//创建于数据结构匹配的schema
scala>val schemaString = "name age"
scala>val schema =
StructType(
schemaString.split(" ").map(fieldName => StructField(fieldName, StringType, true)))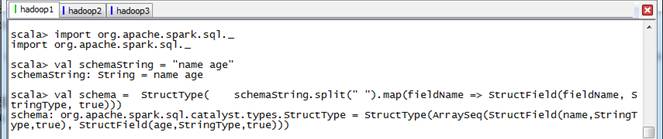
第二步 创建rowRDD并读入数据
//创建rowRDD
scala>val rowRDD = sc.textFile("hdfs://hadoop1:9000/class6/people.txt").map(_.split(",")).map(p => Row(p(0), p(1).trim))
//用applySchema将schema应用到rowRDD
scala>val rddpeople2 = sqlContext.applySchema(rowRDD, schema)
scala>rddpeople2.registerTempTable("rddTable2")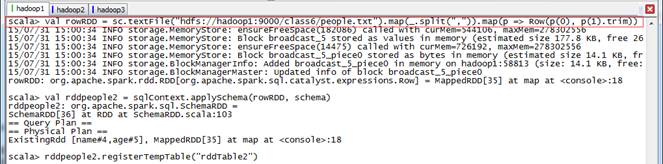
第三步 查询获取数据
scala>sqlContext.sql("SELECT name FROM rddTable2 WHERE age >= 13 AND age <= 19").map(t => "Name: " + t(0)).collect().foreach(println)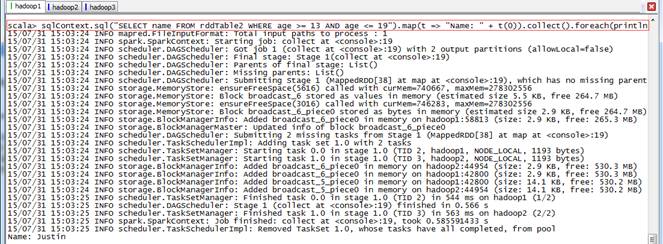
通过监控页面,查看任务运行情况:

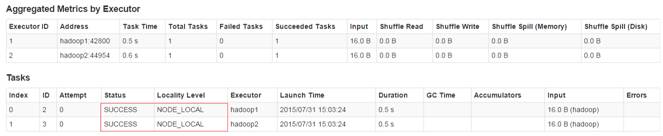
2.2.3 parquet演示
同样得,sqlContext可以读取parquet文件,由于parquet文件中保留了schema的信息,所以不需要使用case class来隐式转换。sqlContext读入parquet文件后直接转换成SchemaRDD,也可以将SchemaRDD保存成parquet文件格式。
第一步 保存成parquest格式文件
// 把上面步骤中的rddpeople保存为parquet格式文件到hdfs中
scala>rddpeople.saveAsParquetFile("hdfs://hadoop1:9000/class6/people.parquet")
第二步 读入parquest格式文件,注册表parquetTable
//parquet演示
scala>val parquetpeople = sqlContext.parquetFile("hdfs://hadoop1:9000/class6/people.parquet")
scala>parquetpeople.registerTempTable("parquetTable")
第三步 查询年龄大于等于25岁的人名
scala>sqlContext.sql( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 389
389

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









