




 本文深入讲解了归并排序算法的工作原理及其应用场景。介绍了归并排序的基本步骤,包括分割和排序阶段,并探讨了其在数据库中的应用及优势。
本文深入讲解了归并排序算法的工作原理及其应用场景。介绍了归并排序的基本步骤,包括分割和排序阶段,并探讨了其在数据库中的应用及优势。
本文翻译自Coding-Geek文章:《 How does a relational database work》。
原文链接:http://coding-geek.com/how-databases-work/#Buffer-Replacement_strategies
本文翻译了如下章节:

一、Merge Sort – 归并排序
当你需要对集合排序时,你怎么做? 什么? 你直接调用Sort()函数,…好,这是一个不错的方案。但是,对于数据库,你必须理解Sort()函数内部是如何工作的。
有很多好的排序算法,我们聚焦到最重要的一种:the merge sort。
你当前可能不理解排序的重要性,但是后面在读到查询优化章节时会理解这一点。此外,理解归并排序,也将有助于理解后面将讲到的一种数据库常用连接操作—归并连接。
二、Merge
就像许多其它有用的算法,归并排序是基于这样一种假设:将2组已经排序,大小是N/2的数据合并成在一起, 形成大小为N, 排序好的数组, 需要执行N步操作。 这些操作被称为merge。
让我们用一个简单的样例演示一下merge的过程:
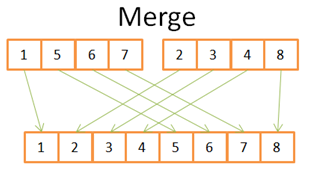
从图中可以看到,构建出最终排好序有8个元素的数组,只需要遍历一次2组有4个元素的数组。因为,这两组元素都是已排好序的:
- 比较两个数组中的数据。从第一个元素开始比较。
- 将较小的数据放到排序结果数组中。
- 比较刚拿走数据的数组中的下一个元素。
- 重复1~3步,直到某个数组中的数据已拿完。
- 将另一个数组中剩余的元素放到排序结果数组中。
以上排序流程能正常执行,是因为参与排序的两个数组是有序的。在遍历数组的时候不需要往前“go back”。
现在,大家已经理解 Merge Sort的原理了。下面是它的伪代码:
array mergeSort(array a)
if(length(a)==1)
return a[0];
end if
//recursive calls
[left_array right_array] := split_into_2_equally_sized_arrays(a);
array new_left_array := mergeSort(left_array);
array new_right_array := mergeSort(right_array);
//merging the 2 small ordered arrays into a big one
array result := merge(new_left_array,new_right_array);
return result;归并排序将一个大的问题分解为小的问题,通过找小问题的解决方法,把结果汇总起来解决最初的大问题。(备注:这类算法被称为分治法)。如果你不理解这个算法,不用担心。我第一次看到它时也不理解。我经验也许可以帮助你,我将该算法分成两个阶段:
- 分割阶段:将数组分割成更小的数组。
- 排序阶段:使用合并的方法将小的数组合并成更大的数组。
(一)Division phase – 分割阶段
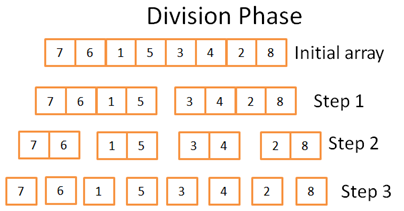
在分割阶段,数组将通过3个步骤分割为更小的数组单元。用数学公式表示操作步骤数量是 log(N), N是数组中的元素数量。例如N=8,那么 log(N) = 3。
我是怎么知道的呢?
我是一个天才!哦,不…。 一句话:算法决定。其思路是每一步分割操作将原始的数组拆分为两份,操作步骤的数量就是你能将数组分割为两组数据的次数。这也是这个算法的准确定义。
(二)Sorting phase – 排序阶段
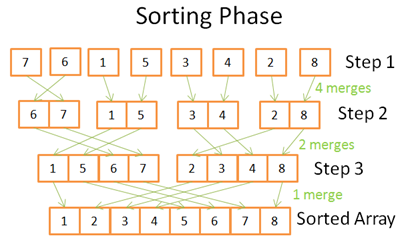
在排序阶段,你先从最小的单个数组开始排序合并。每一步,你将使用多次合并操作,总共合并次数为N=8:
- 第一步合并,先得到4组合并后的数组。每组合并使用2次操作。
- 第二步合并,得到2组合并后的数组。每组合并使用4次操作。
- 第三步合并将得到一组合并后的数组,使用8次操作。
由于执行了log(N)步,所以总的操作数是 N*log(N)。
(三)The power of merge sort – 归并排序的威力
为什么该算法如此有用?因为:
你能对算法做修改以减少内存空间的占用。换句话说,你不需要创建新的数组,直接修改原数组就可以实现排序。
备注:这种算法叫原地排序,通过调整数组中元素的位置,通过元素位置交换实现排序)。你能对算法做修改以使用磁盘空间做数据排序,只使用很少量的内存,也不会给I/O带来大的负担。其思路是每次只加载正在排序比较的数据到内存,排序后的数据写到磁盘保存。这点非常重要,当你需要对1G数据的表做排序,而你的内存只有100M时。
备注:这种算法叫外部排序。借助磁盘和内存数据交换,用有限的内存实现大数据的排序)。你可以把算法修改为支持多线程、多进程、多服务器。
例如:分布式的 merge sort是hadoop的关键组件(hadoop是一个大数据框架)。这个算法能产生真金白银(绝对的实话)。
Merge sort在大多数数据库中使用(不是所有数据库),但还有一些其它的排序算法也在使用。 如果你想了解更多,可以阅读一下相关的研究论文,它们分析了不同数据库排序算法的优劣势。
已翻译的《How does a relational database work》其它章节链接:
1. 关系型数据库工作原理-时间复杂度:http://blog.csdn.net/ylforever/article/details/51205332
2. 关系型数据库工作原理-归并排序:http://blog.csdn.net/ylforever/article/details/51216916
3. 关系型数据库工作原理-数据结构:http://blog.csdn.net/ylforever/article/details/51278954
4. 关系型数据库工作原理-高速缓存:http://blog.csdn.net/ylforever/article/details/50990121
5. 关系型数据库工作原理-事务管理(一):http://blog.csdn.net/ylforever/article/details/51048945
6. 关系型数据库工作原理-事务管理(二):http://blog.csdn.net/ylforever/article/details/51082294


















 1510
1510


 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言








