







一,准备工作:
1,添加mysql的驱动jar包。
将mysql-connector-java-5.0.6-bin.jar 添加到 SPARK_HOME/lib/目录下.
2, 曾加SPARK_HOME/conf目录下的文件:
hive的hive-site.xml, hadoop的core-site.xml(为安全起见),hdfs-site.xml(为HDFS配置)。
二,启动:
将hadoop,hive,mysql都启动好,然后再指定驱动将spark启动:
bin/spark-shell –driver-class-path /mysoftware/spark-1.6.1-bin-hadoop2.6/lib/mysql-connector-java-5.0.6-bin.jar。
与hive的连接:
1,输入sc 观察它是否有效:

2,定义sqlcontext:

3,创建表:
sqlContext.sql(“CREATE TABLE IF NOT EXISTS sparkhivetest001 (key INT, value STRING)”);

4,向表中添加数据导入本地存在的数据:
sqlContext.sql(“LOAD DATA LOCAL INPATH ‘examples/src/main/resources/kv1.txt’ INTO TABLE sparkhivetest001”);

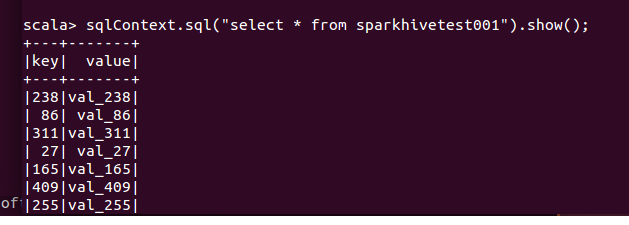
5,查看数据也可以在hive里面查看:
与mysql的连接:
注意:dbtable是已经在mysql存在的表。
输入语句:
val jdbcDF = sqlContext.read.format("jdbc").options( Map("url" -> "jdbc:mysql://192.168.61.128:3306/hive?user=hive&password=hive",
"dbtable" -> "hive.TBLS","driver" -> "com.mysql.jdbc.Driver")).load()
显示信息:
jdbcDF.show()















 2944
2944

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









