




 slab分配器是Linux内核用于高效管理小内存区域的机制,它解决了内部碎片问题并提供缓存功能。slab由kmem_cache_t结构描述,包含对象、构造/析构函数、高速缓存链表等。slab分配器通过kmem_cache_create()创建,使用kmem_cache_alloc()和kmem_cache_free()分配和释放对象。slab着色确保对象在内存中均匀分布以优化高速缓存性能。内存布局包括数据结构、slab分配、颜色管理和对象分配/释放策略。
slab分配器是Linux内核用于高效管理小内存区域的机制,它解决了内部碎片问题并提供缓存功能。slab由kmem_cache_t结构描述,包含对象、构造/析构函数、高速缓存链表等。slab分配器通过kmem_cache_create()创建,使用kmem_cache_alloc()和kmem_cache_free()分配和释放对象。slab着色确保对象在内存中均匀分布以优化高速缓存性能。内存布局包括数据结构、slab分配、颜色管理和对象分配/释放策略。
前面详细讨论了伙伴系统算法,以及基于该算法的页框管理细节。这些内容都是采用页框作为基本内存区,这适合于对大块内存的请求。但是,内核如何处理对一些数据结构分配内存空间,大多数数据结构根本占用不到一个页框。我们如何处理对小内存区的请求呢,比如说几十或几百个字节?
显然,如果为了存放很少的字节而给它分配一个整页框,这显然是一种浪费。取而代之的正确方法就是引入一种新的数据结构来描述在同一页框中如何分配小内存区。但这样也引出了一个新的问题,即传说中的内部碎片(internal fragmentation)。内部碎片的产生主要是由于请求内存的大小与分配给它的大小不匹配而造成的,例如为某一数据结构分配一个页,该数据结构只有几个字节,那么有上千字节的空间被当做碎片给浪费掉;即使多个此数据结构通过一定规则挤进一个页面,那么也还有若干字节的空间被浪费。
下面,我们引出本故事的主角 —— slab分配器
这里先给出slab分配器的一些特性,下面的文字可能晦涩难懂,大家可以先把后面的数据结构和相关算法掌握了再回过头来浏览:
(1)所存放数据的类型可以影响内存区的分配方式。例如,当给用户态进程分配一个页框时,内核调用get_zeroed_page()函数用0 填充这个页。slab 分配器概念扩充了这种思想,并把内存区看作对象(object),这些对象由一组数据结构和几个叫做构造(constructor)或析构(destructor)的函数(或方法)组成。前者初始化内存区,而后者回收内存区。为了避免重复初始化对象,slab分配器并不丢弃已分配的对象,而是释放但把它们保存在内存中。于是,slab分配器具有了想当一部分缓存的功能,当以后又要请求新的对象时,就可以从内存获取而不用重新初始化。
(2)内核函数倾向于反复请求同一类型的内存区。例如,只要内核创建一个新进程,它就要为一些固定大小的数据结构分配内存区。当进程结束时,包含这些数据结构的内存区还可以被重新使用。因为进程的创建和撤消非常频繁,在没有slab分配器时,内核把时间浪费在反复分配和回收那些包含同一内存区的页框上;slab分配器把那些页框保存在高速缓存中并很快地重新使用它们。
(3)对内存区的请求可以根据它们发生的频率来分类。对于预期频繁请求一个特定大小的内存区而言,可以通过创建一组具有适当大小的专用对象来高效地处理,由此以避免内碎片的产生。另一种情况,对于很少遇到的内存区大小,可以通过基于一系列几何分布大小(如早期Linux 版本所使用的2的幂次方大小)的对象的分配模式来处理,即使这种方法会导致内碎片的产生。
(4)在引入的对象大小不是几何分布的情况下,也就是说,数据结构的起始地址不是物理地址值的2 的幂次方,事情反倒好办。这可以借助处理器硬件高速缓存而导致较好的性能。
(5)硬件高速缓存的高性能又是尽可能地限制对伙伴系统分配器调用的另一个理由,因为对伙伴系统函数的每次调用都“弄脏”硬件高速缓存,所以增加了对内存的平均访问时间。内核函数对硬件高速缓存的影响就是所谓的函数“足迹(footprint)”,其定义为函数结束时重写高速缓存的百分比。显而易见,大的“足迹”导致内核函数刚执行之后较慢的代码执行,因为硬件高速缓存此时填满了无用的信息。
slab 分配器把对象分组放进高速缓存。每个高速缓存都是同种类型对象的一种“储备”。例如,当一个文件被打开时,存放相应“打开文件”对象所需的内存区是从一个叫做filp(“文件指针”)的slab 分配器的高速缓存中得到的。
包含高速缓存的主内存区被划分为多个slab,每个slab 由一个或多个连续的页框组成,这些页框中既包含已分配的对象,也包含空闲的对象。我们将在以后有关回收页框的博文中看到,内核周期性地扫描高速缓存并释放空slab 对应的页框。
1 数据结构
每个高速缓存都是由kmem_cache_t(等价于struct kmem_cache_s类型)类型的数据结构来描述的;kmem_cache_t 描述符的lists 字段又是一个kmem_list3结构体,而kmem_list3中的slabs_partial、slabs_full、slabs_free分别包含空闲和非空闲对象的slab 描述符双向循环链表;不包含空闲对象的slab 描述符双向循环链表;只包含空闲对象的slab 描述符双向循环链表;高速缓存中的每个slab 都有自己的类型为slab 的描述符, 其中的colouroff字段表示slab中第一个对象的偏移;s_mem字段表示slab中第一个对象(或者已被分配, 或者空闲)的地址;inuse字段表示当前正在使用的(非空闲)slab 中的对象个数;最后free字段表示slab中下一个空闲对象的下标,如果没有剩下空闲对象则为BUFCTL_END。
数据结构全图如下所示:
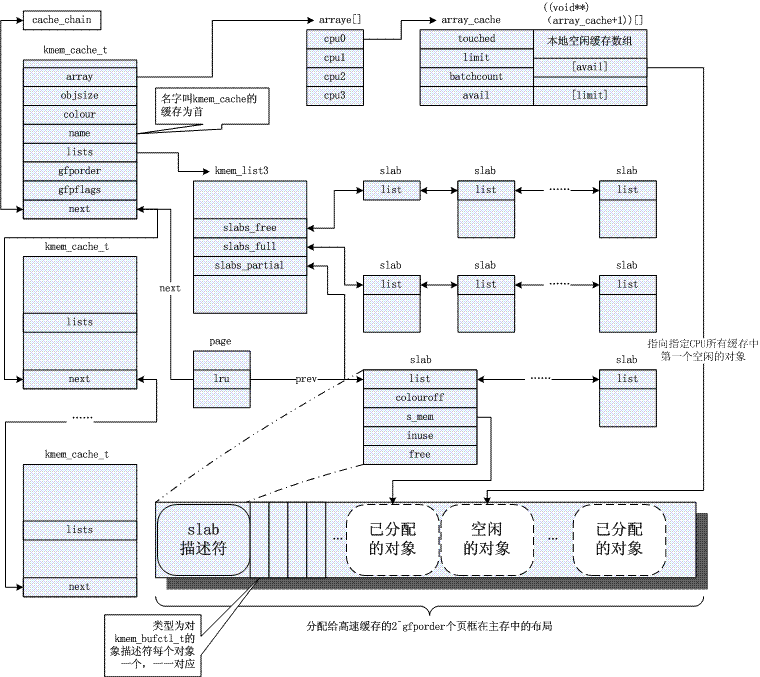
在系统初始化期间内核调用kmem_cache_init()和kmem_cache_sizes_init()来建立搭建一个高速缓存平台,我们只是简单地提一提相关的流程。首先,初始化一个kmem_cache_t类型的cache_cache缓存,取名叫做kmem_cache:
static kmem_cache_t cache_cache = {
.lists = LIST3_INIT(cache_cache.lists),
.batchcount = 1,
.limit = BOOT_CPUCACHE_ENTRIES,
.objsize = sizeof(kmem_cache_t),
.flags = SLAB_NO_REAP,
.spinlock = SPIN_LOCK_UNLOCKED,
.name = "kmem_cache",
#if DEBUG
.reallen = sizeof(kmem_cache_t),
#endif
};
这个缓存用来分配kmem_cache_t类型的slab对象,也就是给缓存自身分配缓存的,所以叫做cache_cache,缓存中的缓存。初始化好cache_cache以后,将它作为第一个元素插到cache_chain循环链表中。
随后,初始化另外一些高速缓存包含用作通用用途的类型的slab对象。内存区大小的范围一般包括13个几何分布的内存区。一个叫做malloc_sizes的表(其元素类型为cache_sizes)分别指向26个高速缓存描述符,与其相关的内存区大小为32, 64, 128, 256, 512,1024, 2048, 4096, 8192, 16384, 32768, 65536 和131072 字节。对于每种大小,都有两个高速缓存:一个适用于ISA DMA 分配,另一个适用于常规分配。其kmem_cache_t.name取名类似size-64或size-64(DMA)。
以上操作完成后,整个slab高速缓存平台就搭建好了,我们就可以用kmem_cache_create()函数来创建各个专用对象的缓存了。这个函数首先根据参数确定处理新高速缓存的最佳方法(例如,是在slab 的内部还是外部包含slab 描述符)。然后它从cache_cache普通高速缓存中为新的高速缓存分配一个高速缓存描述符kmem_cache_t:
(kmem_cache_t *) kmem_cache_alloc(&cache_cache, SLAB_KERNEL);
并把这个描述符插入到高速缓存描述符的cache_chain链表中(当获得了用于保护链表避免被同时访问的cache_chain_sem 信号量后,插入操作完成)。
还可以调用kmem_cache_destroy()撤销一个高速缓存并将它从cache_chain链表上删除。这个函数主要用于模块中,即模块装入时创建自己的高速缓存,卸载时撤销高速缓存。为了避免浪费内存空间,内核必须在撤销高速缓存本身之前就撤销其所有的slab。kmem_cache_shrink()函数通过反复调用slab_destroy()撤销高速缓存中所有的slab。
所有
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1259
1259







 到【灌水乐园】发言
到【灌水乐园】发言







