







analyzer
Analyzer是分析器,它的作用是把一个字符串按某种规则划分成一个个词语,并去除其中的无效词语,这里说的无效词语是指英文中的“of”、 “the”,中文中的“的”、“地”等词语,这些词语在文章中大量出现,但是本身不包含什么关键信息,去掉有利于缩小索引文件、提高效率、提高命中率。
分词的规则千变万化,但目的只有一个:按语义划分。这点在英文中比较容易实现,因为英文本身就是以单词为单位的,已经用空格分开;而中文则必须以某种方法将连成一片的句子划分成一个个词语。常用的分析器有mmseg,IKAnalyzer,Lucene 也自带了简单的二元分析器,比如把”北京天安门”划分成”北京”,”京天”、”天安、”安门”document
用户提供的源是一条条记录,它们可以是文本文件、字符串或者数据库表的一条记录等等。一条记录经过索引之后,就是以一个Document的形式存储在索引文件中的。用户进行搜索,也是以Document列表的形式返回。field
一个Document可以包含多个信息域,例如一篇文章可以包含“标题”、“正文”、“最后修改时间”等信息域,这些信息域就是通过Field在Document中存储的。
Field有两个属性可选:存储和索引。通过存储属性你可以控制是否对这个Field进行存储;通过索引属性你可以控制是否对该Field进行索引。这看起来似乎有些废话,事实上对这两个属性的正确组合很重要,下面举例说明:
还是以刚才的文章为例子,我们需要对标题和正文进行全文搜索,所以我们要把索引属性设置为真,同时我们希望能直接从搜索结果中提取文章标题,所以我们把标题域的存储属性设置为真,但是由于正文域太大了,我们为了缩小索引文件大小,将正文域的存储属性设置为假,当需要时再直接读取文件;我们只是希望能从搜索结果中提取最后修改时间,不需要对它进行搜索,所以我们把最后修改时间域的存储属性设置为真,索引属性设置为假。上面的三个域涵盖了两个属性的三种组合,还有一种全为假的没有用到,事实上Field不允许你那么设置,因为既不存储又不索引的域是没有意义的。term
term是搜索的最小单位,它表示文档的一个词语,term由两部分组成:它表示的词语和这个词语所在的field。Token
Token是term的一次出现,它包含term文本和相应的起止偏移,以及一个类型字符串。一句话中可以出现多次相同的词语,它们都用同一个term表示,但是是不同的Token,每个Token标记该词语出现的地方。segment
添加索引时并不是每个document都马上添加到同一个索引文件,它们首先被写入到不同的小文件,然后再合并成一个大索引文件,这里每个小文件都是一个segment。Posting Table
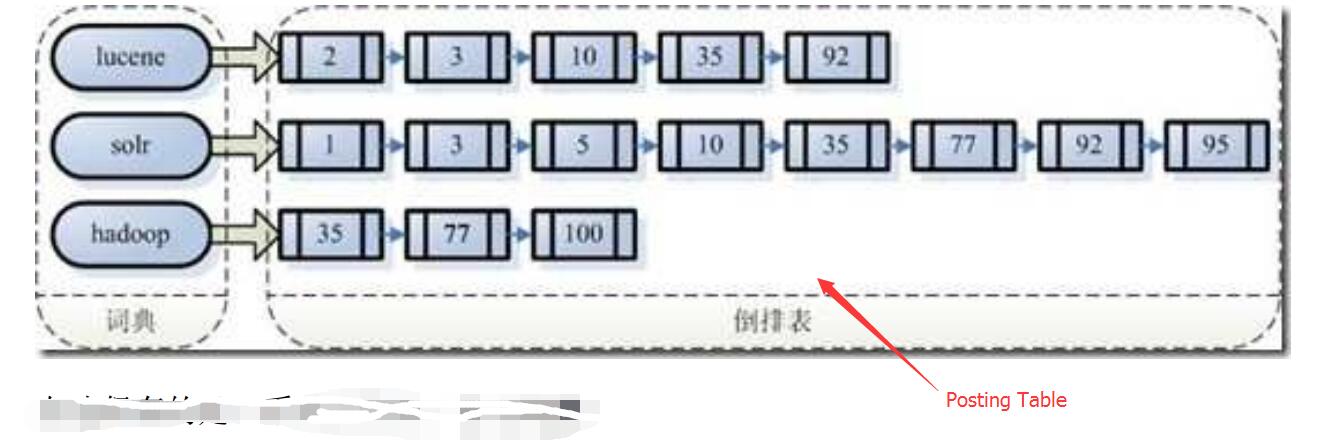
一般情况下,将一个词条所索引的文档(一般用文档编号表示)称之为 Posting,那么一个词条索引的多个文档就称之为 Posting-list。
多个Posting-list构成一个Postingtable
**总的来说,一篇文章可以看成就是一个document,含有多个field和相应的内容content,field可以理解成标题,正文,作者等信息域,我们可以控制那些field可以索引,那些可以存储。当然索引是肯定需要分词的。不同的分词规则需要不同analyzer,一篇文章经过加工处理后,lucene会为每个doc分配一个名字,在构建索引时,每个document就是一个segment,随着构建索引的document 的增加,多个segment就会合并成一个新的segment里。
可以认为倒排索引是一个map<term,list<Token>>,key是term,value是一系列term出现的位置。**














07-29
 1万+
1万+
1万+
05-16
6834
6834
08-11
2796
2796
08-11
1441
1441
08-29
4522
4522
08-19
1533
1533
05-09
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









