









之前做比赛用了下scikit-learn,用着异常方便。现在记录下使用的过程,以免以后忘记。由于主要使用了SVM,所以文章大部分都是以SVM为例。后期可能对每一部分做不定期更新。
文章内容组织如下:
1.scikit-learn读取数据
2.训练分类器
3.特征选择
4.cross validation
5.寻参(grid search)
1.scikit-learn读取数据
scikit-learn可以读取libsvm格式数据(用过台湾大学的libsvm应该都有了解)
from sklearn import datasets as ds
def load_data():
#读取libsvm格式数据
x_train,y_train=ds.load_svmlight_file("D:/traindata/12trainset")
x_test,y_test=ds.load_svmlight_file("D:/traindata/12testset")
x_train.todense()
x_test.todense()</span>type(x_train)
<class 'scipy.sparse.csr.csr_matrix'>
type(y_train)
<class 'numpy.ndarray'> #这是训练数据的类型y_train为label函数参数:
load_svmlight_file(f, n_features=None, dtype=<type 'numpy.float64'>, multilabel=False,zero_based='auto', query_id=False)
参数介绍:
'f'为文件路径
'n_features'为feature的个数,默认None自动识别feature个数
'dtype'为数据集的数据类型(不是很了解),默认是np.float64
'multilable'为多标签,多标签数据的具体格式可以参照(这里)
'zero_based'不是很了解
'query_id'不是很了解。
load_svmlight_file文档(文档链接)
#official example
from sklearn.externals.joblib import Memory
from sklearn.datasets import load_svmlight_file
mem = Memory("./mycache")
@mem.cache
def get_data():
data = load_svmlight_file("mysvmlightfile")
return data[0], data[1]
X, y = get_data()ps.以下所有文档链接为0.17版本
读取数据后就可以训练一个简单的分类器了
2.训练分类器
训练分类器以SVM为例,我们用SVC做一个最简单的分类器
from sklearn.svm import SVC
clf=SVC(kernel='rbf')
clf.fit(x_train,y_train)
clf.predict(x_test)下面介绍一下SVC的参数以及返回的数据
函数参数:
SVC(C=1.0, kernel='rbf', degree=3, gamma=0.0, coef0=0.0, shrinking=True, probability=False,tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=-1, random_state=None)
参数介绍:
C 为惩罚系数,设置的越大表示对于分类错误越不能容忍
kernel 选择核函数
degree 貌似是多项式核函数用的
gamma rbf’, ‘poly’ 和 ‘sigmoid’核函数的系数
coef0 不是很清楚,文档上说在‘poly’ 和 ‘sigmoid’核函数上有效果
shrinking 不是很清楚
probability 是否以概率形式预测
tol 貌似是训练停止的一个阈值
cache_size 指定核函数的缓存
class_weight 设置每个类的权重,这个对不平衡的数据应该有用,如果不设置的话,函数会自动为你设置,设置的原则是和数据集中每个类出现的次数成反比,比如'a'类出现10次,'b'类出现50次,那么a类的权重应该大
verbose 设置为true的话显示中间训练的结果,如下图:

当你clf.fit(x_train,y_train)后SVC的attribute也就生成了,SVC attribute如下图:

比如你想看看支持向量,直接 print(clf.support_vectors_),ps.我的Python版本是3.4, 2点几的print貌似不带括号。不过要是数据很多的话控制台也显示不过来,真想看的话可以存到文件里。
SVC是个类,它还有自己的方法,如下图:

像fit(X,Y) predict(X) get_params() set_params()基本每个分类器都有,fit用来训练数据,predict预测,get_params 获得分类器的参数,也就是上面的SVC的参数,set_params是设置参数,具体的应用场景不清楚。它们返回数据的类型在下面的文档中都有介绍。(SVC文档链接)
SVC默认是支持多分类的,支持的方式是oneVSone(对于二分类变多分类不理解的,可以看看这里),如果想用oneVSrest看下面:
# SVC classifier
clf=SVC(verbose=True)
# oneVSrest classifier
ovr_clf=OneVsRestClassifier(clf,-1)
# 训练分类器
ovr_clf.fit(x_train, y_train)
# 打印第一个类的支持向量
print(ovr_clf.estimators_[0].support_)
ovr_clf.predict(x_test)OneVsRestClassifier(estimator, n_jobs=1)
参数介绍:
estimator 一个初始化的分类器,比如SVC
n_jobs 貌似是多线程,-1的话所有cpu资源都用上
同样在fit(x_train,y_train)后,OneVsRestClassifier的属性也就生成了,如下图:

estimators_是每个类的分类器,假如你的数据分5类,那么这个列表里就有5个分类器,比如我有四个类,
print(ovr_clf.estimators_)如下图:

可以看到这里有4个SVC
OneVsRestClassifier的方法:

这个方法和SVC 差不多,用法也类似。
问题:
如果我用了OneVsRestClassifier,我怎么看每个类的支持向量呢,从上面可以看到我们可以打印出每个类的SVC,
假如想看第1个类的支持向量我们就可以print(ovr_clf.estimators_[0].support_),这里support_是SVC的属性,
就是上面SVC介绍的。
分类器也训练出来的,效果不理想怎么办呢,接下来看看特征选择。
3.特征选择
scikit-learn的特征选择主要有下面几种
(1) removing features with low vaiance
(2) univariate feature selection
(3) recursive feature elimation
(4) L1-based feature selection
(5) tree-based featue selection
第一个是移除低方差的特征,什么是低方差的特征,比如说有一个数据集是这样的,
第一维特征的数据是:0,0,1,0,0,0 大家都知道方差等于“平方的均值减去均值的平方”,第一维的方差等于
1/6-1/36
第二维特征的数据是:0,1,0,1,1,1,第二维的方差等于4/6-16/36
第二维的方差比第一维的要大,因为第二维的数据波动较大,对于分类而言数据的波动越大可能越有助于我们分类。
直观的理解:假设极端的例子是某一维度的值全为0或全为1(方差为0),那么对于分类的问题就会导致每个类里的这个特征的值都一样,这样的话这个维度的特征值对于分类一点用都没有,因为都一样。就好比为了区分男女,用了“是否长有头发”这个特征一样。
下面看一下官方的例子:
from sklearn.feature_selection import VarianceThreshold
X = [[0, 0, 1], [0, 1, 0], [1, 0, 0], [0, 1, 1], [0, 1, 0], [0, 1, 1]]
sel = VarianceThreshold(threshold=(.8 * (1 - .8)))
sel.fit_transform(X)
array([[0, 1],
[1, 0],
[0, 0],
[1, 1],
[1, 0],
[1, 1]])可以看到把第一维的特征去掉了。
函数参数:
VarianceThreshold(threshold)
threshold 方差阈值,方差小于这个阈值的特征被去掉
VarianceThreshold的方法
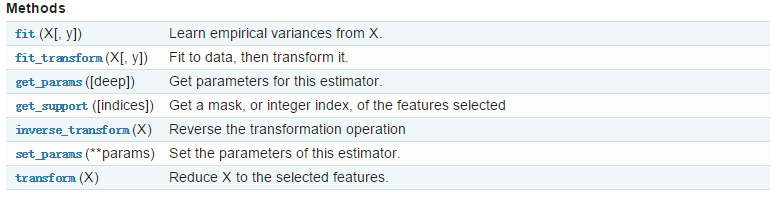
fit()从训练数据计算每一维方差,返回的是varianceThreshold对象,然后用这个对象就可以做get_support()和transform(X)了
fit_transform()和fit差不多,只是它在计算方差后直接返回那些符合threshold的特征
get_params和set_params()和上面介绍的一样都是用来获得和设置varianceThreshold参数用的
inverse_transform()正好和fit_transform相反,它是把fit_transform转化好的X再转化成原来的,但是以前去掉的特征都补上了0
get_suport()符合条件的特征为true 不符合为false ,看下面例子
transform(X)是用训练好的varianceThreshold(也就是fit后的varianceThreshold)来转换其他的数据集
下面是例子:
def test_variancethreshod ():
X_rest=[[0, 2, 0, 3], [0, 2, 4, 3], [0, 2, 1, 3]]
X = [[0, 2, 0, 3], [0, 1, 4, 3], [0, 3, 1, 3]]
vari=VarianceThreshold()
vari.fit(X)
print("variances_: \n",vari.variances_)
print("transform(): \n",vari.transform(X_rest))
print("get_support(): \n",vari.get_support())
print("inverse_transform(): \n",vari.inverse_transform(vari.transform(X)))
第二个是单变量特征选择
待续。。。
先贴一下代码
from sklearn.metrics import precision_recall_curve, roc_curve, auc
from sklearn.metrics import classification_report<span style="white-space:pre"> </span>imfrom sklearn.linear_model import LogisticRegression
from sklearn.metrics import make_scorer
from sklearn import cross_validation as c_v
from sklearn import grid_search as g_s
from sklearn.multiclass import OneVsRestClassifier
from sklearn.feature_selection import chi2,f_classif,SelectKBest,SelectPercentile
import time<span style="white-space:pre"> st</span>st<span style="white-space:pre">art_time = time.time()</span><span style="white-space:pre"> </span>
def test():
#数据是libsvm格式
x_train,y_train=load_svmlight_file("D:/traindata/12trainset")
x_train.todense()
x_test,y_test=load_svmlight_file("D:/traindata/12testset")
x_test.todense()
print(x_train.shape)
#classifier,初始化一个SVM
clf=SVC(kernel='rbf')
#用1VS多来解决多分类问题
ovrclf=OneVsRestClassifier(clf,-1)
#parameter,需要寻的参数,之所以写成'estimator__C'是因为 ovrclf是下面的 gsclf的参数
parameters=[{'estimator__C':[2**-5,2**-4,2**-3,2**-2,2**-1,1,2**1,2**2,2**3,2**4,2**5],
'estimator__kernel':['rbf'],
'estimator__gamma':[2**-5,2**-4,2**-3,2**-2,2**-1,1,2**1,2**2,2**3,2**4,2**5]},
{'estimator__C':[2**-5,2**-4,2**-3,2**-2,2**-1,1,2**1,2**2,2**3,2**4,2**5],
'estimator__kernel':['linear']}]
para={'estimator__C':[2**-5,2**-4],
'estimator__kernel':['rbf'],
'estimator__gamma':[2**-1,1]}
#scoring,自己定义的评价函数,这个是用来确定哪一个参数更好,根据自己的问题确定
sougou_score=make_scorer(score_func,greater_is_better=False)
#cross_validation iterator
sfk=c_v.StratifiedKFold(y_train,shuffle=True,n_folds=5,random_state=0)
#grid search,初始化一个寻参estimator
gsclf=g_s.GridSearchCV(ovrclf,param_grid=para,cv=sfk,scoring=sougou_score)
#开始寻参
gsclf.fit(x_train,y_train)
#打印寻参过程中最优的score
print("best score: ",gsclf.best_score_)
print("best parameters: ",gsclf.best_params_)
y_pred=gsclf.predict(x_test)
#result,一共 0 1 2 3四个类
target_names=['0','1','2','3']
sum_y = np.sum((np.array(y_pred)-np.array(y_test))**2)
print(classification_report(y_test,y_pred,target_names=target_names))
print("sougouVal: ",float(sum_y)/y_pred.shape[0])
print(time.time()-start_time)
#scores=c_v.cross_val_score(ovrclf,x_train,y_train,cv=sfk,scoring='accuracy')
#print(scores)
#自定义的评价函数
def score_func(y_pred,y_test):
sum_y = np.sum((np.array(y_pred)-np.array(y_test))**2)
sougouVal=float(sum_y)/y_pred.shape[0]
return sougouVal















 7339
7339

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









