







1.先区分一下概念:
头结点:
在单链表第一个元素结点之前设置的一个结点, 数据域可以不存任何信息,指针域指向单链表第一个元素的结点。对于单链表来说, 头结点可有可无,但为了操作方便,一般情况下单链表都具有头结点,后面的分析将会区别一下有头结点和没有头结点的区别。
优点:
减少了单链表添加删除时特殊情况的判断,减少了程序的复杂性,主要是添加和删除在第一个有元素的结点(首元结点)上有区别,如果链表没有头结点,则删除或添加时都得需要判断一次首元结点,有了头结点以后,首元结点实际为链表的第二个结点,使得所有的元素结点的添加删除更具有统一性,举例如下:
没有头结点的情况
有头结点的情况
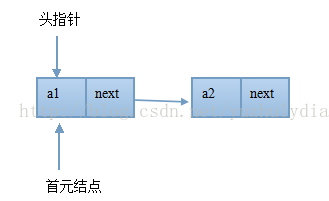
头指针:
指向单链表的第一个结点的指针, 如果单链表有头结点,则头指针指向头结点 ,如果单链表没有头结点,则头指针指向第一个首元结点。
首元结点:
单链表中第一个有数据元素的结点。如果单链表有头结点,则首元结点为头结点的下一个结点,如果单链表没有头结点,则首元结点就是单链表的第一个结点。
三个概念的图模型如下:
1.有头结点
头结点:
在单链表第一个元素结点之前设置的一个结点, 数据域可以不存任何信息,指针域指向单链表第一个元素的结点。对于单链表来说, 头结点可有可无,但为了操作方便,一般情况下单链表都具有头结点,后面的分析将会区别一下有头结点和没有头结点的区别。
优点:
减少了单链表添加删除时特殊情况的判断,减少了程序的复杂性,主要是添加和删除在第一个有元素的结点(首元结点)上有区别,如果链表没有头结点,则删除或添加时都得需要判断一次首元结点,有了头结点以后,首元结点实际为链表的第二个结点,使得所有的元素结点的添加删除更具有统一性,举例如下:
以删除结点举例:
typedef struct stu
{
int num;
struct stu *next;
}TYPE;没有头结点的情况
TYPE * delete(TYPE * head,int num)
{
TYPE *pf,*pb;
if(head==NULL)
{
printf("\nempty list!\n");
return NULL;
}
pb=head;
while ((pb->num!=num) && (pb->next!=NULL))
{
pf=pb;
pb=pb->next;
}
if(pb->num==num)
{
/* 注意此处需要对头指针进行特殊处理 */
if(pb==head)
{
head=pb->next;
}
else
{
pf->next=pb->next;
}
free(pb);
printf("The node is deleted\n");
}
else
{
printf("The node not been found!\n");
}
return head;
}有头结点的情况
TYPE * delete(TYPE * head,int num)
{
TYPE *pf,*pb;
if(head->next==NULL)
{
printf("\nempty list!\n");
return NULL;
}
pf = head;
pb=head->next;
while (pb->num!=num && pb->next!=NULL)
{
pf=pb;
pb=pb->next;
}
if(pb->num==num)
{
pf->next=pb->next;
free(pb);
printf("The node is deleted\n");
}
else
{
printf("The node not been found!\n");
}
return head;
}头指针:
指向单链表的第一个结点的指针, 如果单链表有头结点,则头指针指向头结点 ,如果单链表没有头结点,则头指针指向第一个首元结点。
首元结点:
单链表中第一个有数据元素的结点。如果单链表有头结点,则首元结点为头结点的下一个结点,如果单链表没有头结点,则首元结点就是单链表的第一个结点。
三个概念的图模型如下:
1.有头结点

无头结点















 926
926











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









