






**
Getting Started With TensorFlow
**
谷歌的深度学习框架Tensorflow最近发布了1.0版本,于是开始自己边学习边翻译,希望能实现从0到1的突破。因翻译水平有限,文中附有原文,为于译文分开,以代码框形式展现
This guide gets you started programming in TensorFlow. Before using this guide, install TensorFlow. To get the most out of this guide, you should know the following:
• How to program in Python.
• At least a little bit about arrays.
• Ideally, something about machine learning. However, if you know little or nothing about machine learning, then this is still the first guide you should read.本指南可以助力您开始tensorflow编程。在使用之前请先安装tensorflow。为了从本指南获得更多信息,您应该对以下有所了解
1.怎样在python里编程
2.至少少一点点数组相关
3.最理想的情况下是对机器学习有些许认知,不过,如果您对机器学习一无所知或只知一二,仍然可以首先阅读本指南。
TensorFlow provides multiple APIs. The lowest level API--TensorFlow Core-- provides you with complete programming control. We recommend TensorFlow Core for machine learning researchers and others who require fine levels of control over their models. The higher level APIs are built on top of TensorFlow Core. These higher level APIs are typically easier to learn and use than TensorFlow Core. In addition, the higher level APIs make repetitive tasks easier and more consistent between different users. A high-level API like tf.contrib.learn helps you manage data sets, estimators, training and inference. Note that a few of the high-level TensorFlow APIs--those whose method names contain contrib-- are still in development. It is possible that some contrib methods will change or become obsolete in subsequent TensorFlow releases.
This guide begins with a tutorial on TensorFlow Core. Later, we demonstrate how to implement the same model in tf.contrib.learn. Knowing TensorFlow Core principles will give you a great mental model of how things are working internally when you use the more compact higher level API.tensorflow提供多样的API,提供了最低等级的api——TensorFlow Core 用以完成程序控制。我们建议将TensorFlow core作为机器学习研究人员和其他需要良好水平的人的控制模型。 高等级的API构建在TensorFlow Core的最上层。这些更高层次的api通常比TensorFlow核心更容易学习和使用。 此外,更高层次的api简化重复的任务和不同用户之间更加一致。一个高级tf.contrib之类的API。学习可以帮助你管理数据集,评估人员、培训和推理。注意的一些高层TensorFlow api——那些方法名称包含contrib仍在发展。可能是一些普通发布版方法将在后续TensorFlow变化或者作废的版本。 本指南以教程开始TensorFlow核心。之后,我们将演示如何在tf.contrib.learn实现相同的模型。熟知TensorFlow core的运行原理在你使用更高级API的时候对了解内部运作方式有很大作用。
Tensors
The central unit of data in TensorFlow is the tensor. A tensor consists of a set of primitive values shaped into an array of any number of dimensions. A tensor's rank is its number of dimensions. Here are some examples of tensors:张量
TensorFlow中数据的中心单元是张量。一个张量由一组任何维数的原始值数组组成。张量的秩是维度数。这里有一些张量的例子:
3 # a rank 0 tensor; this is a scalar标量 with shape []
[1. ,2., 3.] # a rank 1 tensor; this is a vector向量 with shape [3]
[[1., 2., 3.], [4., 5., 6.]] # a rank 2 tensor; a matrix矩阵 with shape [2, 3]
[[[1., 2., 3.]], [[7., 8., 9.]]] # a rank 3 tensor张量 with shape [2, 1, 3]TensorFlow Core tutorial
Importing TensorFlow
The canonical import statement for TensorFlow programs is as follows:Tensorflow Core教程
导入Tensorflow
规范的TensorFlow项目导入语句如下:
import tensorflow as tfThis gives Python access to all of TensorFlow's classes, methods, and symbols. Most of the documentation assumes you have already done this.提供了Python 中访问TensorFlow所有类,方法和符号的方式。大部分的文档假定您已经完成了引入。
The Computational Graph
You might think of TensorFlow Core programs as consisting of two discrete sections:
1. Building the computational graph.
2. Running the computational graph.计算图
你可以考虑一下组成TensorFlow Core的两个离散部分:
1. 构建计算图。
2. 运行计算图。
A computational graph is a series of TensorFlow operations arranged into a graph of nodes. Let's build a simple computational graph. Each node takes zero or more tensors as inputs and produces a tensor as an output. One type of node is a constant. Like all TensorFlow constants, it takes no inputs, and it outputs a value it stores internally. We can create two floating point Tensors node1 and node2 as follows:计算图(computational graph)是一系列通过TensorFlow操作安排进图的节点。我们来构建一个简单的计算图。 每个节点需要零个或多个张量作为输入并产生一个张量作为输出。一种类型的节点是一个常数(constant)。 像所有TensorFlow常数一样,它不需要输入值,它输出存储在内部的输出值。我们可以创建两个浮点型张量node1和node2如下:
node1 = tf.constant(3.0, tf.float32)
node2 = tf.constant(4.0) # also tf.float32 implicitly也是隐式的tf.float32
print(node1, node2)The final print statement produces最后输出
Tensor("Const:0", shape=(), dtype=float32) Tensor("Const_1:0", shape=(), dtype=float32)Notice that printing the nodes does not output the values 3.0 and 4.0 as you might expect. Instead, they are nodes that, when evaluated, would produce 3.0 and 4.0, respectively. To actually evaluate the nodes, we must run the computational graph within a session. A session encapsulates the control and state of the TensorFlow runtime.注意,单纯打印节点并不会像您预期的一样输出值3.0和4.0。相反,它们是节点,只当赋值的时候,才会分别输出3.0和4.0。要真正的给节点赋值,我们必须在会话(session)里运行该计算图。 会话封装了控制和TensorFlow运行的状态。
The following code creates a Session object and then invokes its run method to run enough of the computational graph to evaluate node1 and node2. By running the computational graph in a session as follows:下面的代码会创建一个会话对象,然后调用方法充分运行计算图来给node1和node2赋值。像下面这样,在会话中运行计算图:
sess = tf.Session()
print(sess.run([node1, node2]))we see the expected values of 3.0 and 4.0:我们可以看到期望的值了 3.0 和 4.0:
[3.0, 4.0]We can build more complicated computations by combining Tensor nodes with operations (Operations are also nodes.). For example, we can add our two constant nodes and produce a new graph as follows:我们可以通过结合张量与操作(操作也是一个节点)构建更复杂的计算节点。例如,我们可以添加两个常数节点,产生一个新的图如下:
node3 = tf.add(node1, node2)
print("node3: ", node3)
print("sess.run(node3): ",sess.run(node3))
The last two print statements produce
node3: Tensor("Add_2:0", shape=(), dtype=float32)
sess.run(node3): 7.0
TensorFlow provides a utility called TensorBoard that can display a picture of the computational graph. Here is a screenshot showing how TensorBoard visualizes the graph:TensorFlow提供了一个叫做TensorBoard的实用程序,可以展示一个计算图的图像。这里是一个展示TensorBoard可视化的截图:
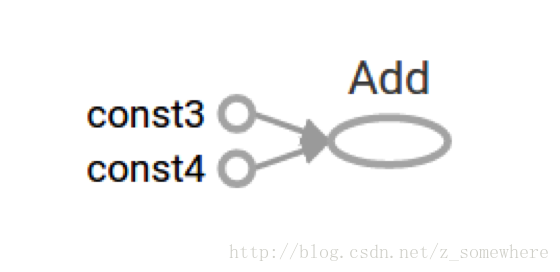
As it stands, this graph is not especially interesting because it always produces a constant result. A graph can be paramaterized to accept external inputs, known as placeholders. A placeholder is a promise to provide a value later.目前,这个图不是特别有趣,因为它总是产生一个恒定的结果。一个图表可以相应接受外部输入,称为占位符(placeholders)。一个占位符是以后会提供一个输入值的承诺。
a = tf.placeholder(tf.float32)
b = tf.placeholder(tf.float32)
adder_node = a + b # + provides a shortcut for tf.add(a, b)The preceding three lines are a bit like a function or a lambda in which we define two input parameters (a and b) and then an operation on them. We can evaluate this graph with multiple inputs by using the feed_dict parameter to specify Tensors that provide concrete values to these placeholders:前三行有点像一个函数或一个lambda(匿名函数)-我们定义了两个输入参数(a和b),然后对他们进行操作。我们可以使用feed_dict参数指定给这些占位符提供具体值的张量来给这个图表赋多个输入值
print(sess.run(adder_node, {a: 3, b:4.5}))
print(sess.run(adder_node, {a: [1,3], b: [2, 4]}))resulting in the output7.5
[ 3. 7.]*注:查询了一下feed_dict
Session’s feed_dict*
x = tf.placeholder(tf.string) with tf.Session() as sess: output = sess.run(x, feed_dict={x: 'Hello World'}) 如上面这段代码所示,在tf.Session.run()中使用feed_dict来传入tensor.上面这个例子传入的是一个字符串”Hello, world”,feed_dict也可以同时传入多个tensor,如下所示。
x = tf.placeholder(tf.string)
y = tf.placeholder(tf.int32)
z = tf.placeholder(tf.float32) with tf.Session() as sess: output = sess.run(x, feed_dict={x: ‘Test String’, y: 123, z: 45.67})
注意:你应该已经注意到所有tensor都已经被预先定义类型,如果在feed_dict中传入的类型与预先定义的不符合,则TF会报“ValueError: invalid literal for…”错误。
一个思考:
那么,什么时候该用tf.placeholder,什么时候该使用tf.Variable之类直接定义参数呢?
答案是,tf.Variable适合一些需要初始化或被训练而变化的权重或参数,而tf.placeholder适合通常不会改变的被训练的数据集。
参考:https://zhuanlan.zhihu.com/p/25307881
In TensorBoard, the graph looks like this:在TensorBoard里,图是这样的
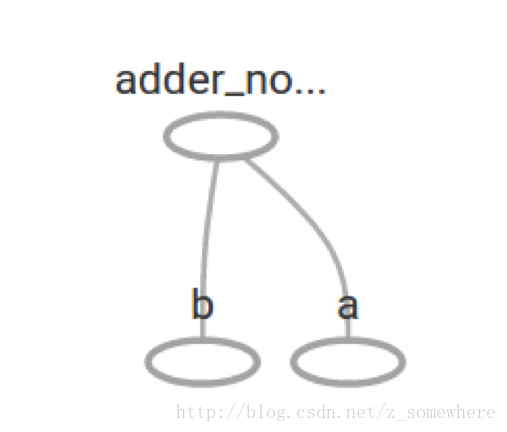
We can make the computational graph more complex by adding another operation. For example,我们可以给计算图添加另一个更复杂的操作。例如,
add_and_triple = adder_node * 3.
print(sess.run(add_and_triple, {a: 3, b:4.5}))produces the output22.5The preceding computational graph would look as follows in TensorBoard: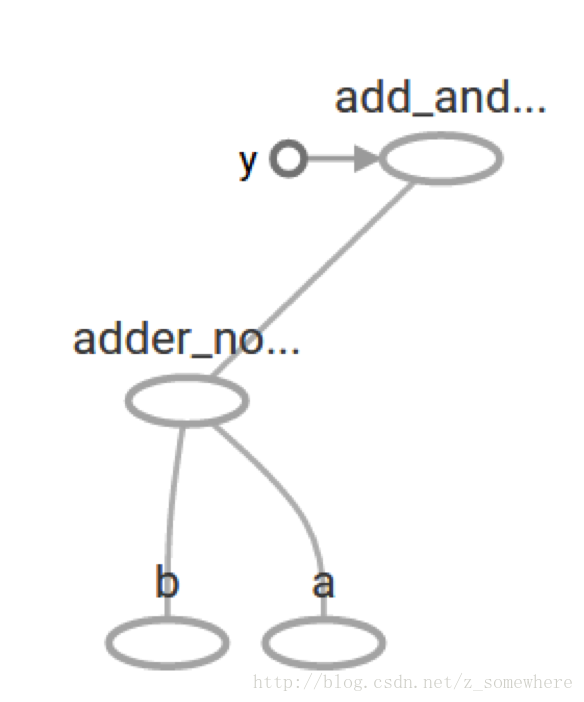
In machine learning we will typically want a model that can take arbitrary inputs, such as the one above. To make the model trainable, we need to be able to modify the graph to get new outputs with the same input. Variables allow us to add trainable parameters to a graph. They are constructed with a type and initial value:在机器学习中,我们通常会想得到一个可以任意输入的模型,例如下面这个。为了使模型更易于训练,我们需要能够修改这个图来得到和输入相同的新的输出。 变量(Variables)允许我们为图添加可训练的参数。他们是由一个类型和初始值所构造:
W = tf.Variable([.3], tf.float32)
b = tf.Variable([-.3], tf.float32)
x = tf.placeholder(tf.float32)
linear_model = W * x + bConstants are initialized when you call tf.constant, and their value can never change. By contrast, variables are not initialized when you call tf.Variable. To initialize all the variables in a TensorFlow program, you must explicitly call a special operation as follows:当你初始化了常数(tf.constant)。它们的值将永远不会改变。 相比之下,调用变量(tf.Variable)时variable是未被初始化的。想要在TensorFlow程序初始化所有变量,必须显式地调用一个特殊操作,如下
init = tf.global_variables_initializer()
sess.run(init)注:我的版本测试了一下global_variables_initializer不能用,旧版本initialize_all_variables可以用,但查了一下说旧版本三月会废弃
It is important to realize init is a handle to the TensorFlow sub-graph that initializes all the global variables. Until we call sess.run, the variables are uninitialized.
Since x is a placeholder, we can evaluate linear_model for several values of x simultaneously as follows:重要的是要意识到初始化对于初始化所有全局变量的tensorflow子图来说是一个handle。直到我们调用sess.run前,变量都是未初始化的。
因为x是一个占位符,我们可以同时给linear_model(前面定义的模型)的x赋几个值,如下:
print(sess.run(linear_model, {x:[1,2,3,4]}))to produce the output
[ 0. 0.30000001 0.60000002 0.90000004]We've created a model, but we don't know how good it is yet. To evaluate the model on training data, we need a yplaceholder to provide the desired values, and we need to write a loss function.
A loss function measures how far apart the current model is from the provided data. We'll use a standard loss model for linear regression, which sums the squares of the deltas between the current model and the provided data. linear_model - y creates a vector where each element is the corresponding example's error delta. We call tf.square to square that error. Then, we sum all the squared errors to create a single scalar that abstracts the error of all examples using tf.reduce_sum:我们已经创建了一个模型,但我们不知道它效果如何。要在训练数据上评估模型,我们需要一个y占位符来提供所需的值,我们需要编写一个损失(loss)函数。 损失函数(loss function)是记录目前提供的数据模型的差距有多远的措施。我们将使用一个标准的线性回归模型(linear regression),总结了目前模型和提供数据之间的方差之和。 linear_model - y创建一个向量,其中每个元素都是误差相应的delta。我们调用tf.square来给误差做平方计算。然后,我们使用tf.reduce_sum来创建一个标量用来计算所有的平方差之和来将所有error实例抽象出来:
y = tf.placeholder(tf.float32)
squared_deltas = tf.square(linear_model - y)
loss = tf.reduce_sum(squared_deltas)
print(sess.run(loss, {x:[1,2,3,4], y:[0,-1,-2,-3]}))producing the loss value23.66We could improve this manually by reassigning the values of W and b to the perfect values of -1 and 1. A variable is initialized to the value provided to tf.Variable but can be changed using operations like tf.assign. For example,W=-1 and b=1 are the optimal parameters for our model. We can change W and b accordingly:我们可以通过将W和b的值重新分配为完美值1和-1来进行手动改善。变量被初始化为提供给tf.Variable的值。但使用操作比如tf.assign这样的操作可以改变这个值。例如,W = -1,b = 1是我们的模型的最优参数。我们可以相应的改变W和b:
fixW = tf.assign(W, [-1.])
fixb = tf.assign(b, [1.])
sess.run([fixW, fixb])
print(sess.run(loss, {x:[1,2,3,4], y:[0,-1,-2,-3]}))The final print shows the loss now is zero.0.0We guessed the "perfect" values of W and b, but the whole point of machine learning is to find the correct model parameters automatically. We will show how to accomplish this in the next section.我们猜测“完美”的W和b值,但机器学习的目的正是自动找到正确的模型参数。我们将在下一节展示了如何做到这一点。
tf.train API
A complete discussion of machine learning is out of the scope of this tutorial. However, TensorFlow provides optimizers that slowly change each variable in order to minimize the loss function. The simplest optimizer is gradient descent. It modifies each variable according to the magnitude of the derivative of loss with respect to that variable. In general, computing symbolic derivatives manually is tedious and error-prone. Consequently, TensorFlow can automatically produce derivatives given only a description of the model using the function tf.gradients. For simplicity, optimizers typically do this for you. For example,机器学习的完整讨论超出了本教程的范围。 然而,TensorFlow提供了优化器(optimizers),慢慢改变每个变量以最小化损失函数。最简单的优化器是梯度下降(gradient descent)。 他根据loss导数的大小和变量的权重来改变该变量。一般来说,人工计算符号化导数繁琐且易出错。 因此,TensorFlow可以仅靠模型描述使用函数tf.gradients自动产生导数。为简单起见,优化器通常为你这样做。例如,
optimizer = tf.train.GradientDescentOptimizer(0.01)
train = optimizer.minimize(loss)
sess.run(init) # reset values to incorrect defaults.
for i in range(1000):
sess.run(train, {x:[1,2,3,4], y:[0,-1,-2,-3]})
print(sess.run([W, b]))which results in the final model parameters[array([-0.9999969], dtype=float32), array([ 0.99999082],
dtype=float32)]Now we have done actual machine learning! Although doing this simple linear regression doesn't require much TensorFlow core code, more complicated models and methods to feed data into your model necessitate more code. Thus TensorFlow provides higher level abstractions for common patterns, structures, and functionality. We will learn how to use some of these abstractions in the next section.现在我们已经完成了实际上的机器学习!虽然这样的简单线性回归不需要太多TensorFlow core代码,但使用更复杂的模型和方法给你的模型喂数据需要更多的代码。 因此TensorFlow为常见的模式,结构和功能(patterns,structures,and functionality)提供了更高级别的抽象(abstractions)。在下一节我们将学习如何使用一些抽象
Complete program
The completed trainable linear regression model is shown here:完整的可训练的线性回归模型如下:
import numpy as np
import tensorflow as tf# Model parameters模型参数
W = tf.Variable([.3], tf.float32)
b = tf.Variable([-.3], tf.float32)
# Model input and output模型的输入值和输出值
x = tf.placeholder(tf.float32)
linear_model = W * x + b
y = tf.placeholder(tf.float32)
# loss
loss = tf.reduce_sum(tf.square(linear_model - y)) # sum of the squares方差
# optimizer优化器
optimizer = tf.train.GradientDescentOptimizer(0.01)
train = optimizer.minimize(loss)
# training data训练数据
x_train = [1,2,3,4]
y_train = [0,-1,-2,-3]
# training loop训练循环
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init) # reset values to wrong
for i in range(1000):
sess.run(train, {x:x_train, y:y_train})
# evaluate training accuracy
curr_W, curr_b, curr_loss = sess.run([W, b, loss], {x:x_train, y:y_train})
print("W: %s b: %s loss: %s"%(curr_W, curr_b, curr_loss))When run, it producesW: [-0.9999969] b: [ 0.99999082] loss: 5.69997e-11This more complicated program can still be visualized in TensorBoard 这个更复杂的程序仍然可以在TensorBoard可视化
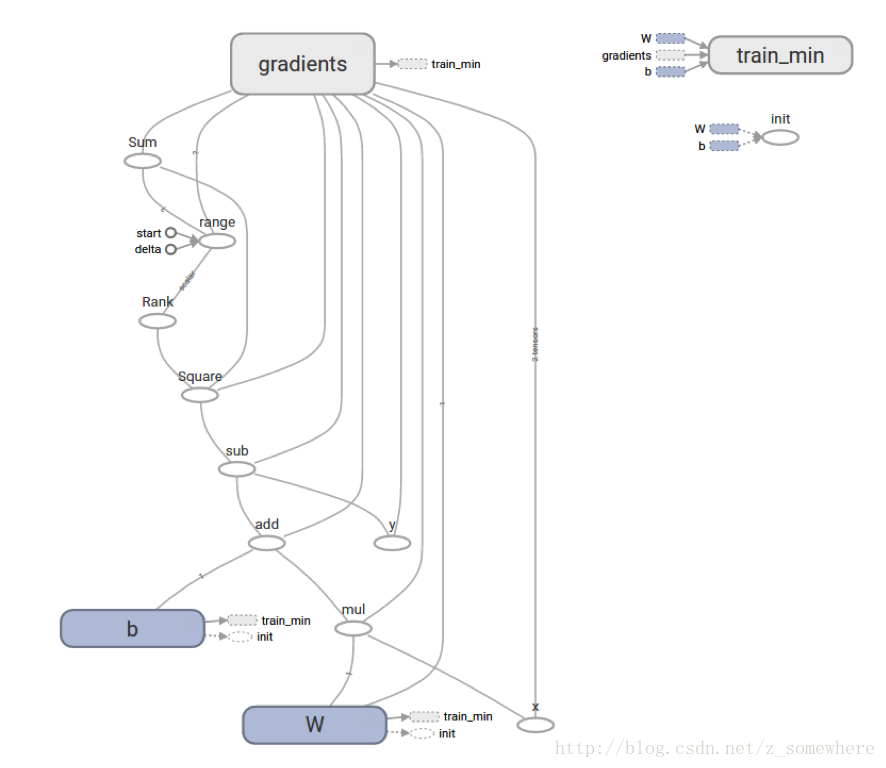
tf.contrib.learn
tf.contrib.learn is a high-level TensorFlow library that simplifies the mechanics of machine learning, including the following:
• running training loops
• running evaluation loops
• managing data sets
• managing feeding
tf.contrib.learn defines many common models.tf.contrib.learn是一个高级TensorFlow库,简化了机器学习的机制,包括:
• 训练循环
• 赋值循环
• 管理数据集
• 管理喂数
tf.contrib.learn 定义了很多通用模型
Basic usage
Notice how much simpler the linear regression program becomes with tf.contrib.learn:请注意使用tf.contrib.learn使得线性回归变得多么简单
import tensorflow as tf
# NumPy is often used to load, manipulate and preprocess data.
#操作和预处理时,我们经常使用NumPy(一个科学计算包)
import numpy as np
# Declare list of features. We only have one real-valued feature. There are many other types of columns that are more complicated and useful.
#声明特征列表。我们只有一个有实值的特征。还有许多其他更复杂的和有用的列的类型。
features = [tf.contrib.layers.real_valued_column("x", dimension=1)]
# An estimator is the front end to invoke training (fitting) and evaluation
# (inference). There are many predefined types like linear regression,
# logistic regression, linear classification, logistic classification, and
# many neural network classifiers and regressors. The following code
# provides an estimator that does linear regression.
estimator = tf.contrib.learn.LinearRegressor(feature_columns=features)
# TensorFlow provides many helper methods to read and set up data sets.
# Here we use `numpy_input_fn`. We have to tell the function how many batches of data (num_epochs) we want and how big each batch should be.
#tensorflow提供了很多帮助方法来阅读和设置数据集。我们必须告诉函数有多少批次的数据(num_epochs)和每一批应该多大。
x = np.array([1., 2., 3., 4.])
y = np.array([0., -1., -2., -3.])
input_fn = tf.contrib.learn.io.numpy_input_fn({"x":x}, y, batch_size=4,
num_epochs=1000)
# We can invoke 1000 training steps by invoking the `fit` method and passing the
# training data set.
estimator.fit(input_fn=input_fn, steps=1000)
# Here we evaluate how well our model did. In a real example, we would want
# to use a separate validation and testing data set to avoid overfitting.
estimator.evaluate(input_fn=input_fn)When run, it produces{'global_step': 1000, 'loss': 1.9650059e-11}
A custom model
tf.contrib.learn does not lock you into its predefined models. Suppose we wanted to create a custom model that is not built into TensorFlow. We can still retain the high level abstraction of data set, feeding, training, etc. oftf.contrib.learn. For illustration, we will show how to implement our own equivalent model to LinearRegressorusing our knowledge of the lower level TensorFlow API.tf.contrib.learn不会将你禁锢在它预设的模型中。假设我们想要创建一个自定义模型。我们仍然可以通过tf.contrib.learn保持高度抽象的数据集,喂养,训练等。为了说明,我们将展示如何用低级TensorFlow API实现自己的等效线性回归模型。
To define a custom model that works with tf.contrib.learn, we need to use tf.contrib.learn.Estimator. tf.contrib.learn.LinearRegressor is actually a sub-class of tf.contrib.learn.Estimator. Instead of sub-classing Estimator, we simply provide Estimator a function model_fn that tells tf.contrib.learn how it can evaluate predictions, training steps, and loss. The code is as follows:要使用tf.contrib.learn定义一个自定义模型。我们需要使用tf.contrib.learn.Estimator。tf.contrib.learn.LinearRegressor实际上是tf.contrib.learn.Estimator的一个子类。我们只是给 Estimator提供一个函数model_fn来告诉tf.contrib怎样定义预测,训练步骤,和损失,而不是生成子类Estimator。代码如下:
import numpy as np
import tensorflow as tf
# Declare list of features, we only have one real-valued feature
def model(features, labels, mode):
# Build a linear model and predict values
#创建一个线性模型并预测值
W = tf.get_variable("W", [1], dtype=tf.float64)
b = tf.get_variable("b", [1], dtype=tf.float64)
y = W*features['x'] + b
# Loss sub-graph
loss = tf.reduce_sum(tf.square(y - labels))
# Training sub-graph
global_step = tf.train.get_global_step()
optimizer = tf.train.GradientDescentOptimizer(0.01)
train = tf.group(optimizer.minimize(loss),
tf.assign_add(global_step, 1))
# ModelFnOps connects subgraphs we built to the
# appropriate functionality.
return tf.contrib.learn.ModelFnOps(
mode=mode, predictions=y,
loss= loss,
train_op=train)
estimator = tf.contrib.learn.Estimator(model_fn=model)
# define our data set
x=np.array([1., 2., 3., 4.])
y=np.array([0., -1., -2., -3.])
input_fn = tf.contrib.learn.io.numpy_input_fn({"x": x}, y, 4, num_epochs=1000)
# train
estimator.fit(input_fn=input_fn, steps=1000)
# evaluate our model
print(estimator.evaluate(input_fn=input_fn, steps=10))When run, it produces{'loss': 5.9819476e-11, 'global_step': 1000}Notice how the contents of the custom model() function are very similar to our manual model training loop from the lower level API.注意,自定义model()函数的内容和低级API的手动循环训练模型十分相似。
Next steps
Now you have a working knowledge of the basics of TensorFlow. We have several more tutorials that you can look at to learn more. If you are a beginner in machine learning see MNIST for beginners, otherwise see Deep MNIST for experts.下一步 现在您有了TensorFlow的基础知识。我们有几个教程,您可以看看了解更多信息。如果您是初学者的话,请看MNIST for beginners, 否则看Deep MNIST for experts.














 1250
1250











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









