







 本文通过Python的urllib2和BeautifulSoup爬取链家网的房产数据,进行数据清洗,利用高德地图API清洗地理位置信息。数据分析结果显示,市中心新房和二手房销售价格高于郊县,二手房价格分化不明显,成都市天府新区有较高的交易热度。
本文通过Python的urllib2和BeautifulSoup爬取链家网的房产数据,进行数据清洗,利用高德地图API清洗地理位置信息。数据分析结果显示,市中心新房和二手房销售价格高于郊县,二手房价格分化不明显,成都市天府新区有较高的交易热度。
随着互联网的发展,可供分析的信息越来越多,利用互联网上的信息来对生活中的问题做一些简单的研究分析,变得越来越便利了。本文就从数据采集、数据清洗、数据分析与可视化三部分来看看新的一年里房市的一些问题。
数据采集:
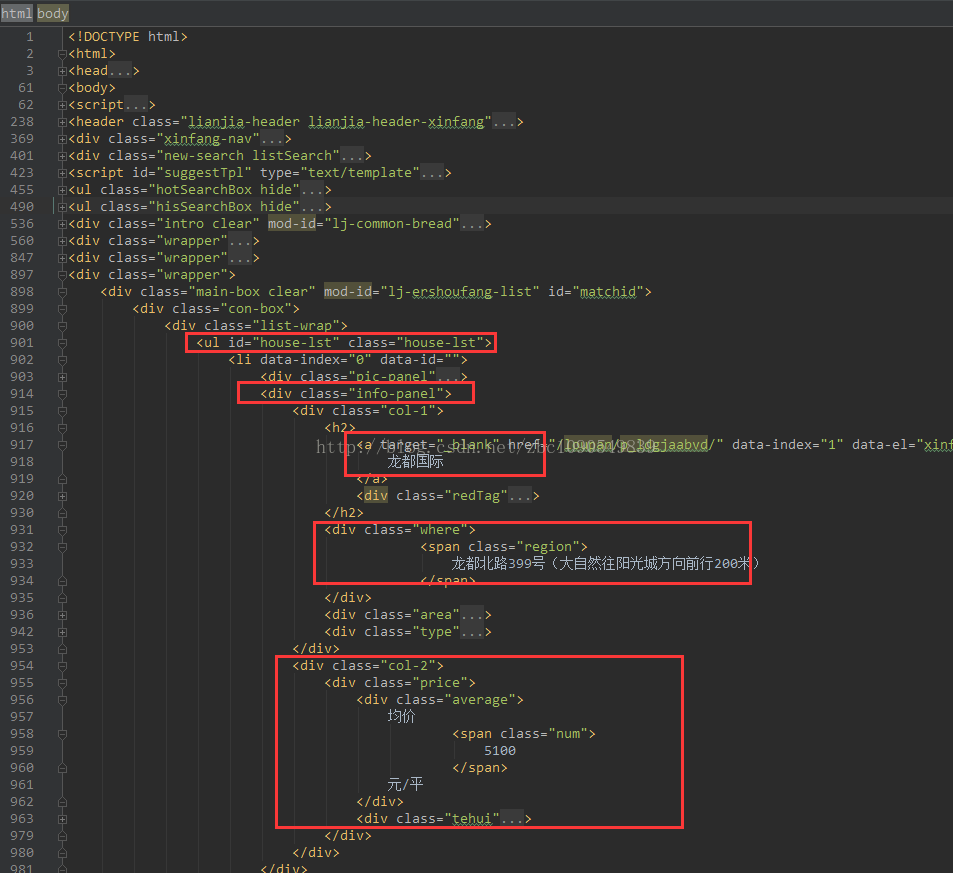
数据采集即从网页上采集我们需要的指定信息,一般使用爬虫实现。当前开源的爬虫非常多,处于简便及学习的目的,在此使用python的urllib2库模拟http访问网页,并BeautifulSoup解析网页获取指定的字段信息。本人获取的链家网上的新房和二手房数据,先来看看原始网页的结构:
首先是URL,不管是新房还是二手房,链家网的房产数据都是以列表的方式存在,比较容易获取,如下图:

其中包含的信息有楼盘名称、地址、价格等信息,回到原始网页,看看在html中,这些信息都在什么地方,如下图:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 683
683

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









