







实验环境
操作系统:ubuntu 14.04 64位
| 主机名 | IP |
|---|---|
| namenode | 10.107.12.10 |
| datanode1 | 10.107.12.20 |
| datanode2 | 10.107.12.50 |
| datanode3 | 10.107.12.60 |
jdk 安装
实验安装的是jdk1.7.0_71版本,具体安装步骤及环境变量设置参考这里。
SSH 无密登录
下面是我写的一个自动化SSH 无密登录脚本,运行脚本前需要安装expect包,ubuntu 系统下直接执行:sudo apt-get install expect就可以了。该脚本运行在namenode上,运行时只需要将IP_1改成对应的datanode地址,PWD_1是对应datanode密码。
# NO_PWD_SSH
#!/bin/sh
IP_1=10.107.12.20,10.107.12.50,10.107.12.60
PWD_1=111111
key_generate() {
expect -c "set timeout -1;
spawn ssh-keygen -t dsa;
expect {
{Enter file in which to save the key*} {send -- \r;exp_continue}
{Enter passphrase*} {send -- \r;exp_continue}
{Enter same passphrase again:} {send -- \r;exp_continue}
{Overwrite (y/n)*} {send -- n\r;exp_continue}
eof {exit 0;}
};"
}
auto_ssh_copy_id () {
expect -c "set timeout -1;
spawn ssh-copy-id -i $HOME/.ssh/id_dsa.pub root@$1;
expect {
{Are you sure you want to continue connecting *} {send -- yes\r;exp_continue;}
{*password:} {send -- $2\r;exp_continue;}
eof {exit 0;}
};"
}
rm -rf ~/.ssh
key_generate
ips_1=$(echo $IP_1 | tr ',' ' ')
for ip in $ips_1
do
auto_ssh_copy_id $ip $PWD_1
done
eval &(ssh-agent)
ssh-add安装Hadoop2.7.1
1. 下载Hadoop2.7.1
下载地址点这里。
2. 解压安装
tar zxvf hadoop-2.7.1.tar.gz解压,解压后放在了/root/spark_sdk/目录下,并在hadoop-2.7.1目录下建立tmp、hdfs/namenode、hdfs/datanode目录,命令如下:
mkdir ./hadoop-2.7.1/tmp
mkdir ./hadoop-2.7.1/hdfs
mkdir ./hadoop-2.7.1/hdfs/datanode
mkdir ./hadoop-2.7.1/hdfs/namenode3. 设置环境变量
在~/.bashrc文件中加入如下两条命令:
export HADOOP_HOME=/root/spark_sdk/hadoop-2.7.1
PATH=$PATH:$HADOOP_HOME/bin使环境变量生效:source ~/.bashrc
4. 设置主机名 && hosts文件
主机名
将/etc/hostname中主机名依次修改为namenode,datanode1,datanode2,datanode3。
hosts文件
将/etc/hosts文件中加入如下命令:
10.107.12.10 namenode
10.107.12.20 datanode1
10.107.12.50 datanode2
10.107.12.60 datanode3注意主机名必须和hosts文件中名称保持一致!!
5. 修改Hadoop 配置文件
hadoop-env.sh 文件
export JAVA_HOME=/root/spark_sdk/jdk1.7.0_71yarn-env.sh 文件
export JAVA_HOME=/root/spark_sdk/jdk1.7.0_71core-site.xml 文件
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://namenode:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131702</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/root/spark_sdk/hadoop-2.7.1/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>这里有一个地方需要注意,最后设置hadoop.proxyuser时,后面跟的是用户名,我是用root用户登录的,所以填的是root。
hdfs-site.xml 文件
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/root/spark_sdk/hadoop-2.7.1/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/root/spark_sdk/hadoop-2.7.1/hdfs/datanode</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>namenode:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>mapred-site.xml 文件
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>yarn-site.xml 文件
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>namenode:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>namenode:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>namenode:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>namenode:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>namenode:8088</value>
</property>
</configuration>
slaves 文件
datanode1
datanode2
datanode36. 启动Hadoop
先格式化namenode,然后依次启动hdfs和yarn。
bin/hadoop namenode -format
sbin/start-dfs.sh
sbin/start-yarn.sh7. 集群启动验证
namenode上执行jps命令,可以查询到有如下进程:
15746 SecondaryNameNode
15508 NameNode
15969 ResourceManager
16377 Jpsdatanode上执行jps命令,可以查询到有如下进程:
14731 Jps
14421 NodeManager
14182 DataNode8. 查询集群信息 && 关闭集群
可以在浏览器中输入:10.107.12.10:50070查询HDFS相关信息,这里10.107.12.10是namenode的IP地址。浏览器输入:10.107.12.10:8088查看yarn的启动情况。
关闭集群可以执行sbin/stop-all.sh。
9. 运行应用程序
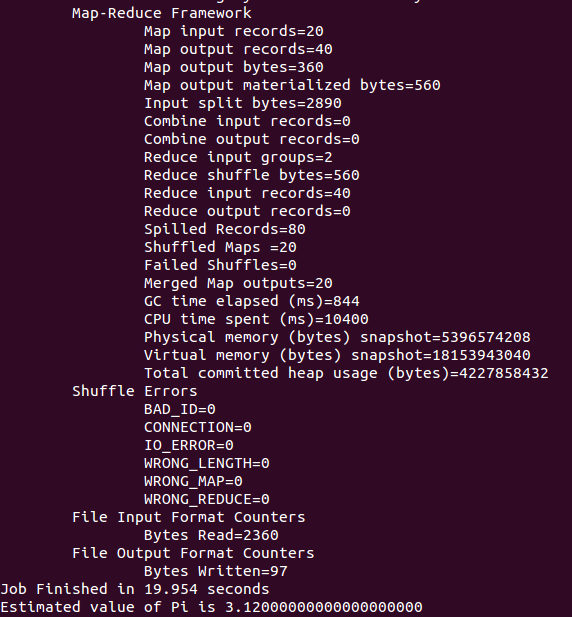
启动集群后,切换到hadoop 主目录,执行 ./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar pi 20 10,运行成功后会输出Pi的值,结果如下:
【完】















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









