







 本文介绍了Word2Vec的背景知识,包括词向量、分类和逻辑回归、Huffman编码。接着详细讨论了Spark MLlib中的Word2Vec模型,如CBOW和Skip-gram模型,以及使用Hierarchical Softmax的求解方法。最后提到了Word2Vec的应用。
本文介绍了Word2Vec的背景知识,包括词向量、分类和逻辑回归、Huffman编码。接着详细讨论了Spark MLlib中的Word2Vec模型,如CBOW和Skip-gram模型,以及使用Hierarchical Softmax的求解方法。最后提到了Word2Vec的应用。
Word2vec 是 Google 在 2013 年开源的一款将词表征为实数值向量的高效工具。能够将单词映射到K维向量空间,同时由于算法考虑了每个单词的上下文环境,因此词向量表示同时具有语义特性。本文对Word2Vec的算法原理以及其在spark MLlib中的实现进行了对应分析。(PS:第一次用latex打这么多公式,真是心累~)
1.背景知识
1.1 词向量
NLP中词向量通常有两种表示方式:
- One-hot Representaion
把每个单词按顺序编号,每个词就是一个很长的向量,向量的长度等于词表的大小,只有对应位置上的数字编号为1,其余位置为0.在实际应用中一般采用稀疏矩阵的表示方式。例如:
假设词表为{I, am, study, spark, machine, learning}
则若用稠密矩阵来表示单词spark,则为[0,0,0,1,0,0,0], 在Scala语法中就是Vectors.dense(0,0,0,1,0,0,0);
若用稀疏矩阵来表示单词spark,则为(6, 3, 1),这是一个三元组,6表示向量维度,3,1表示矩阵在3这个位置上的元素为1,其余位置元素均为0。在Scala语法中就是Vectors.sparse(6,(3),(1)) - Distributed Representaion
其基本思想是通过训练将每个词映射为K维实数向量,通过词之间的距离(例如cosine相似度、欧氏距离)来判断它们之间的语义相似度。Word2Vec就是使用这种Distributed Representaion的词向量表示方式。Word2Vec算法的一个附加输出就是输入语料文本中每个单词的Distributed Representaion词向量。
1.2 分类和逻辑回归
(1) 一般来说,回归不用再分类问题上,因为回归是连续模型,如果非要引入,可以使用logistic回归。logistic回归本质上仍是线性回归,只是在特征 X X 到结果
的映射中加入了一层函数映射,先做线性求和再使用 σ(z) σ ( z ) 作为假设函数来映射,将连续值映射到{0,1}上。logistic回归只能用于二分类,对于任意样本 x={
x1,x2,...xn}T x = { x 1 , x 2 , . . . x n } T ,其评估函数为:
其中 σ(z)=11+e−z σ ( z ) = 1 1 + e − z 就是sigmoid函数
(2) 选用sigmoid函数来做logistic回归的理由有:
平滑映射:能将 x∈(−∞,∞) x ∈ ( − ∞ , ∞ ) 平滑映射到(0,1)区间
其导数具有如下特点:
σ′(z)=ddz(11+e−z)=e−z(1+e−z)2=11+e−z(1−11+e−z)=σ(z)(1−σ(z))(1.2) (1.2) σ ′ ( z ) = d d z ( 1 1 + e − z ) = e − z ( 1 + e − z ) 2 = 1 1 + e − z ( 1 − 1 1 + e − z ) = σ ( z ) ( 1 − σ ( z ) )
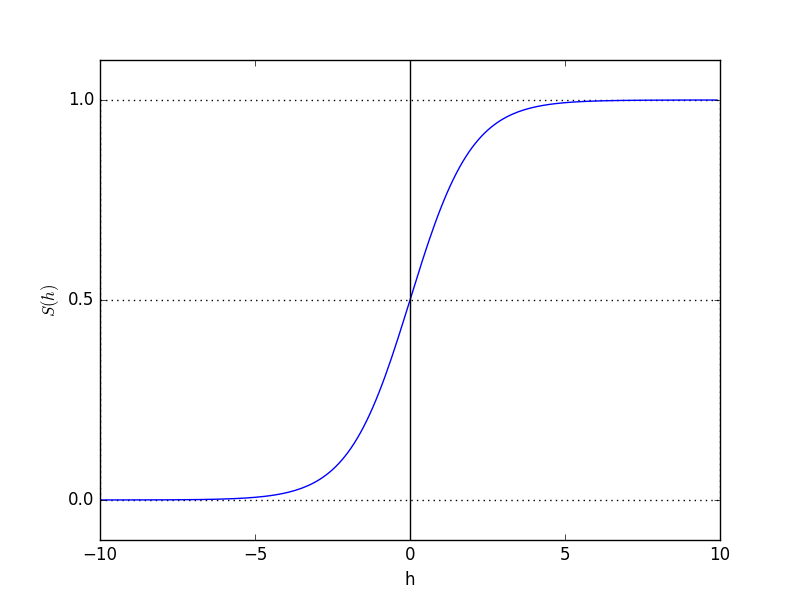
(3) 使用logistic回归进行二分类,实际上是取阈值T=0.5,即使用如下判别公式:
y(x)={
10hθ(x)≥0.5hθ(x)<0.5(1.3) (1.3) y ( x ) = { 1 h θ ( x ) ≥ 0.5 0 h θ ( x ) < 0.5
假设这里的二分类满足伯努利分布,也即
p(y=1|x;θ)p(y=0|x;θ)=hθ(x)=1−hθ(x)(1)(2) (1) p ( y = 1 | x ; θ ) = h θ ( x ) (2) p ( y = 0 | x ; θ ) = 1 − h θ ( x )
也即:
p(y|x;θ)=(hθ(x))y(1−hθ(x))1−y(1.4) (1.4) p ( y | x ; θ ) = ( h θ ( x ) ) y ( 1 − h θ ( x ) ) 1 − y
(4)参数 θ θ 向量的求取方法通常为:假设训练集是独立同分布的,期待模型能在全部训练数据上预测最准,也就是求使其概率积最大 θ θ ,使用最大似然估计,其对数似然函数表示为:
L(θ)l(θ)=p(Y|X;θ)=∏i=1mp(y(i)|x(i);θ)=∏i=1m(hθ(x(i)))y(i)(1−hθ(x(i)))1−y(i)=logL(θ)=∑i=1my(i)loghθ(x(i))+(1−y(i))log(1−hθ(x(i)))(3)(1.5) (3) L ( θ ) = p ( Y | X ; θ ) = ∏ i = 1 m p ( y ( i ) | x ( i ) ; θ ) = ∏ i = 1 m ( h θ ( x ( i ) ) ) y ( i ) ( 1 − h θ ( x ( i ) ) ) 1 − y ( i ) (1.5) l ( θ ) = l o g L ( θ ) = ∑ i = 1 m y ( i ) l o g h θ ( x ( i ) ) + ( 1 − y ( i ) ) l o g ( 1 − h θ ( x ( i ) ) )
(5)要求得使上面的似然函数 l(θ) l ( θ ) 最大的 θ θ ,可使用牛顿上升法,即使用 θ:=θ+α∇θl(θ) θ := θ + α ∇ θ l ( θ ) 迭代公式来不断迭代直到收敛,其中
∇θjl(θ)=∑i=1m(y(i)×1hθ(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 638
638

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









