




 本文介绍了皮尔逊相关系数的定义及其计算方法,并提供了一段Python代码来演示如何计算两列数据之间的皮尔逊相关系数。适用于线性关系且符合正态分布的连续型数据。
本文介绍了皮尔逊相关系数的定义及其计算方法,并提供了一段Python代码来演示如何计算两列数据之间的皮尔逊相关系数。适用于线性关系且符合正态分布的连续型数据。
两个变量之间的皮尔逊相关系数定义为两个变量之间的协方差和标准差的商。
第一种形式(也就是定义的形式):
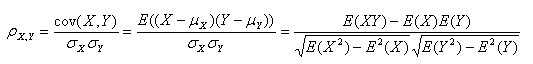
第二种形式:
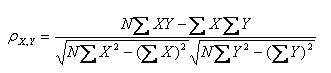
第三种形式:
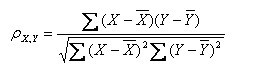
第四种形式:
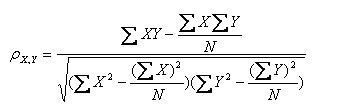
(其中,E为数学期望或均值,N为数据的数目,E{ [X-E(X)] [Y-E(Y)]}称为随机变量X与Y的协方差,记为Cov(X,Y))
根据第四种形式的公式,使用python实现计算两列数据的pearson相关系数的代码:
from math import sqrt
def multiply(a,b):
#a,b两个列表的数据一一对应相乘之后求和
sum_ab=0.0
for i in range(len(a)):
temp=a[i]*b[i]
sum_ab+=temp
return sum_ab
def cal_pearson(x,y):
n=len(x)
#求x_list、y_list元素之和
sum_x=sum(x)
sum_y=sum(y)
#求x_list、y_list元素乘积之和
sum_xy=multiply(x,y)
#求x_list、y_list的平方和
sum_x2 = sum([pow(i,2) for i in x])
sum_y2 = sum([pow(j,2) for j in y])
molecular=sum_xy-(float(sum_x)*float(sum_y)/n)
#计算Pearson相关系数,molecular为分子,denominator为分母
denominator=sqrt((sum_x2-float(sum_x**2)/n)*(sum_y2-float(sum_y**2)/n))
return molecular/denominator
f=open('filename','r')
data={}
lines=f.readlines()
for line in lines:
#strip用于去掉换行符,split()通过指定分隔符对字符串进行切片,返回子字符串
cols=line.strip('\n').split(',')
for i in range(len(cols)):
#float将字符串转成浮点数
data.setdefault(i,[]).append(float(cols[i]))
x=data[0]
y=data[1]
if __name__=='__main__':
print ("x_list,y_list的Pearson相关系数为:"+str(cal_pearson(x,y)))皮尔逊相关系数的适用范围:
当两个变量的标准差都不为零时,相关系数才有定义,皮尔逊相关系数适用于:
1. 两个变量之间是线性关系,都是连续数据。
2. 两个变量的总体是正态分布,或接近正态的单峰分布。
3. 两个变量的观测值是成对的,每对观测值之间相互独立。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









