







(本题数据来源于23年数学建模国赛C题,所看的主教程是b站清风数模)
相关性分析:指对两个或多个具有相关性的变量元素进行分析
区别:pearson是衡量线性关联性的程度,spearman和kendall属于等级相关系数亦称为“秩相关系数”,是反映等级相关程度的统计分析指标。
注意:区分样本和总体——样本标准差是除以n-1,总体标准差是除以n。
pearson
1.定义:
协方差cov(X,Y)除以它们各自标准差的乘积(σX,σY)
系数的取值总是在-1.0到1.0之间,接近0的变量被成为无相关性,接近1或者-1被称为具有强相关性。
特别注意:线性无关,但有可能非线性相关
2.使用条件:
2.1画出散点图
观察数据的趋势,是否是线性相关,在线性相关的条件下,进行皮尔逊相关系数的计算,看其线性相关的程度。
2.2去除异常值
皮尔森相关性系数受异常值的影响比较大
2.3判断是否是正态分布
因为在求皮尔森相关性系数后,通常会用t检验的方法来进行皮尔森相关性系数检验,而 t检验是基于数据呈正态分布的假设的。
且是独立抽样,一般满足条件。
3.假设检验:
原假设: : r = 0
备择假设: : r ≠ 0
设定显著水平:0.05
选择检验方法:
![]()
计算p值:
将r值带入统计量计算可得,后续将采用python代码。
3.实操:
画散点图
import seaborn as sns
sns.pairplot(pivot_data)
plt.show()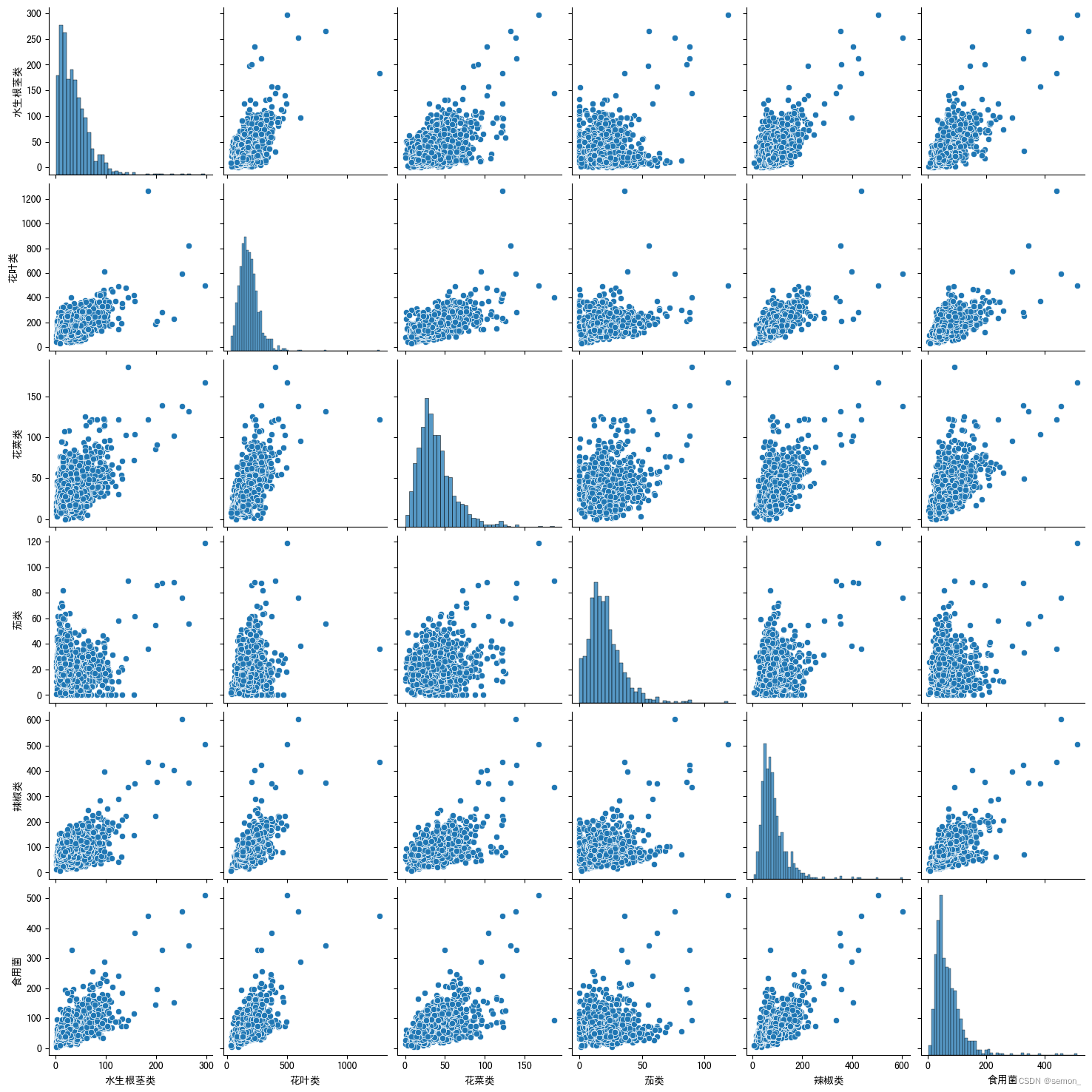
利用python中的pandas处理数据,也可以用excel,不过我选择python,嘿嘿。
#下面这个pivot_data是2023年c题数据变换后得到,总之下面这串代码画出来的热力图观赏性极强,存一下
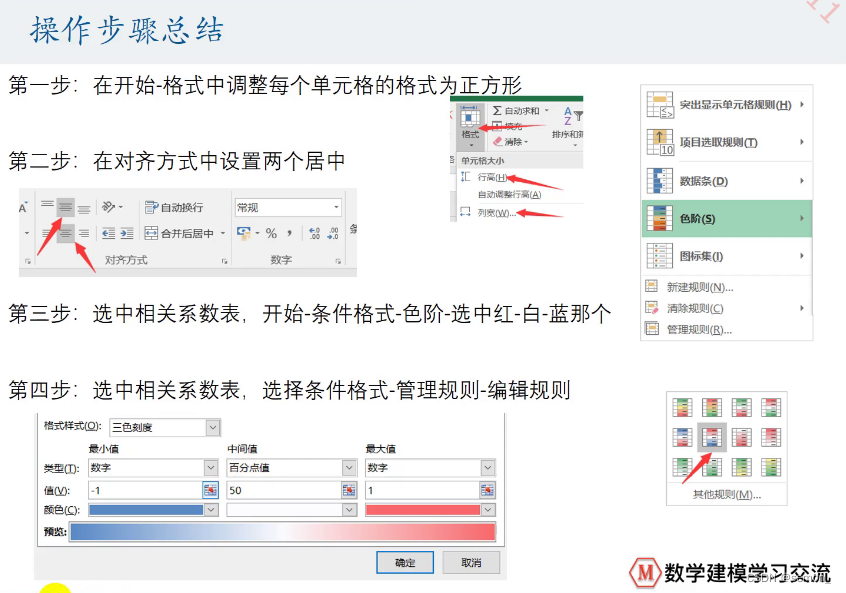
#当然像这样数据量少,也可以利用excel——色阶——管理规则——编辑规则来制作热力图
correlation_matrix = pivot_data.corr(method='spearman')
mask = np.zeros_like(correlation_matrix)
index = np.triu_indices_from(correlation_matrix)
mask[index] = True
cmap = sns.diverging_palette(220,8,as_cmap = True)
kw = {'width_ratios':[1,0.05],'wspace':0.2}
f,(ax1,ax2) = plt.subplots(1,2,gridspec_kw=kw,figsize = (10,9))
sns.heatmap(correlation_matrix,vmin = -1,vmax= 1,cmap = cmap,ax = ax1,
square=False,linewidths=0.5,mask = mask,yticklabels=True,cbar_ax=ax2,
cbar_kws={'orientation':'vertical','ticks':[-1,-0.5,0,0.5,1]},annot=True)
ax1.set_title('Normal')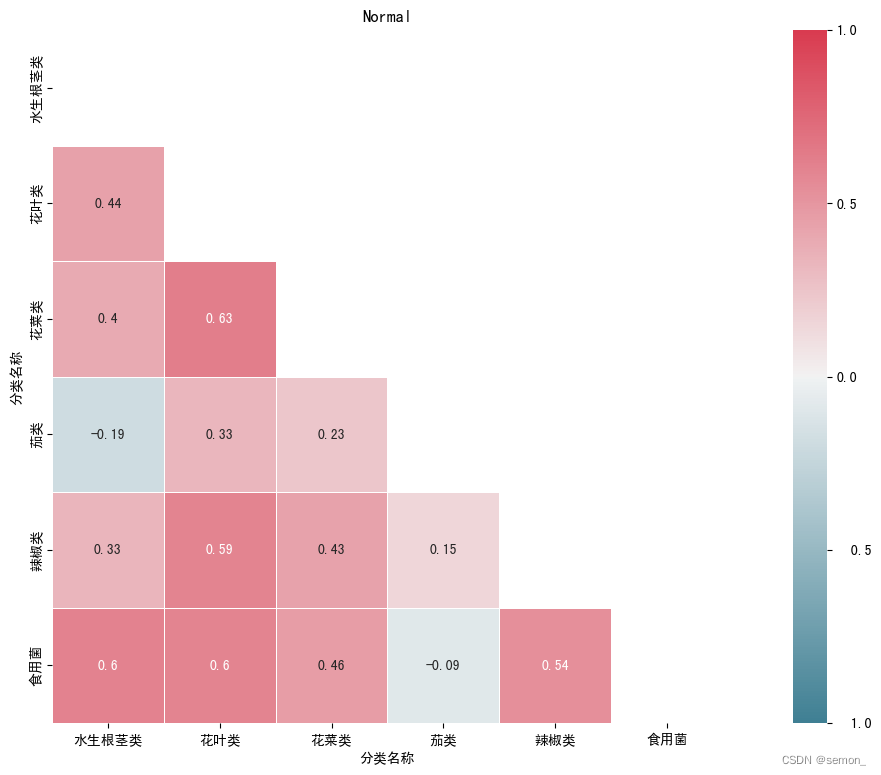
利用pandas.corr()可以直接求得r值,但是无法计算p值,这个时候我们使用 statsmodels 进行皮尔逊相关系数假设检验的示例代码:
r, p_value = pearsonr(X, Y)
但是对于datafram格式的数据无法直接处理,必须借助循环语句。(记得不能有缺失值哦)
import pandas as pd
from scipy.stats import pearsonr
# 创建一个空的 DataFrame 用来存储相关性和 p 值
correlation_results = pd.DataFrame(index=pivot_data.columns, columns=pivot_data.columns)
p_values = pd.DataFrame(index=pivot_data.columns, columns=pivot_data.columns)
# 遍历每一对列,并计算它们之间的相关性和 p 值
for i in pivot_data.columns:
for j in pivot_data.columns:
r, p_value = pearsonr(pivot_data[i], pivot_data[j])
correlation_results.loc[i, j] = r
p_values.loc[i, j] = p_value
print("Correlation Matrix:")
print(correlation_results)
print("\nP-values:")
print(p_values)看到这里是不是忘记了检验p值之前要进行正态分布检验,别担心请移步——第3讲 t检验/卡方检验等_哔哩哔哩_bilibili
S-W检验和JB检验:小样本(小于50)时建议使用S-W检验,大样本(大于50)时建议使用JB检验。
import numpy as np
from scipy.stats import jarque_bera #from scipy.stats import shapiro
#求shapiro时,只需将jarque_bera改为shapiro
nc = pivot_data.shape[1] # 获取数据的列数
H = np.zeros(nc) # 初始化存储结果的数组
P = np.zeros(nc) # 初始化存储 p 值的数组
T = np.zeros(nc)
for i in pivot_data.columns:
n=0
h, p = jarque_bera(pivot_data[i])
H[n] = h
P[n] = p
if p > 0.05:
T[n] = 0
else:
T[n] = 1
n+=1
print("假设检验结果:")
print(H) # 显示假设检验结果
print("p 值:")
print(P) # 显示 p 值
print(T)附带一个正态分布可视化图
import numpy as np
import matplotlib.pyplot as plt
from scipy.interpolate import make_interp_spline
# Sample data for the histogram
bin_edges = np.array([3, 4, 5, 6, 7, 8, 9, 10, 11])
values = np.array([0.5, 1.5, 2.5, 3.0, 3.5, 3.5, 3.0, 2.5, 0.5])
# Create a smoother line for the red curve
x_smooth = np.linspace(bin_edges.min(), bin_edges.max(), 300)
spline = make_interp_spline(bin_edges, values, k=3) # B-spline with cubic interpolation
y_smooth = spline(x_smooth)
fig, ax1 = plt.subplots()
# Plotting the histogram
ax1.bar(bin_edges, values, width=0.9, color='lightblue', edgecolor='black', alpha=0.7)
ax1.set_xlabel('总磷含量 (mg/L)')
ax1.set_ylabel('频率')
ax1.set_ylim(0, 4)
# Overlaying the red line
ax1.plot(x_smooth, y_smooth, color='red', linewidth=2)
plt.show()

附带一个QQ图代码
import statsmodels.api as sm
import matplotlib.pyplot as plt
# 遍历每一列,并绘制对应的 QQ 图
for column_name in pivot_data.columns:
sm.qqplot(pivot_data[column_name], fit=True, line='45')
plt.title(f'QQ Plot for {column_name}')
plt.show()
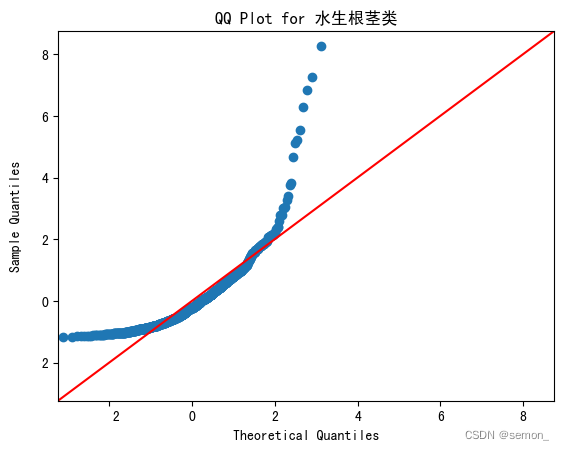
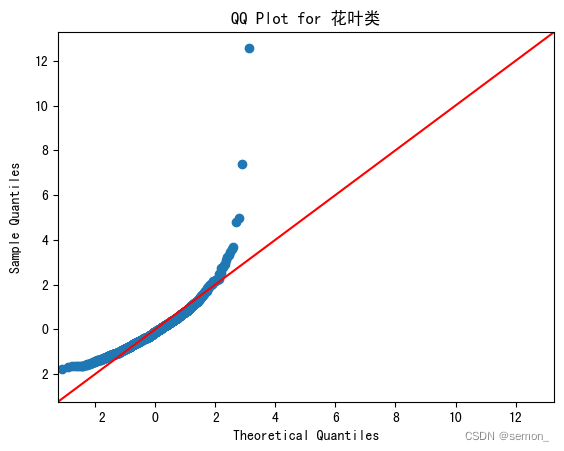
诶呀,数据居然不服从正态分布,其实在散点图的时候我们就该发现此数据不适合用于皮尔逊相关系数,这就引出我们接下来的斯皮尔曼。
spearman
1.定义
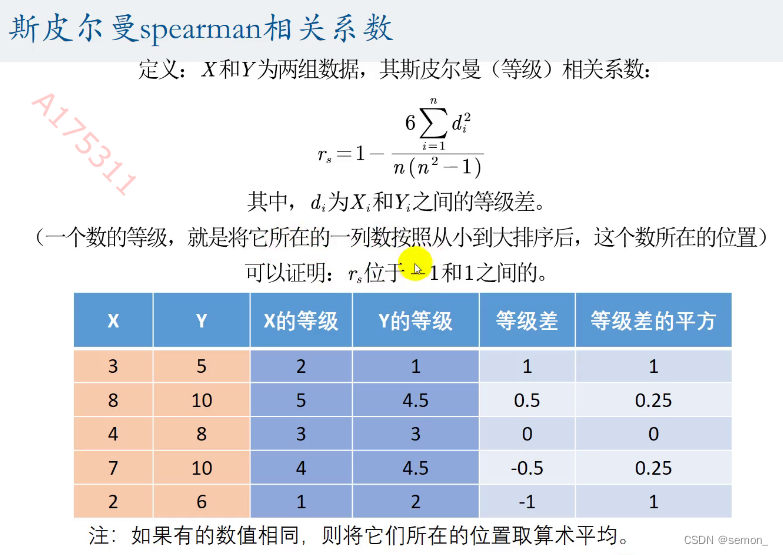
2.假设检验
对于小样本,我们直接查表,比较r,大样本我们需要构建统计量进行检验![]()
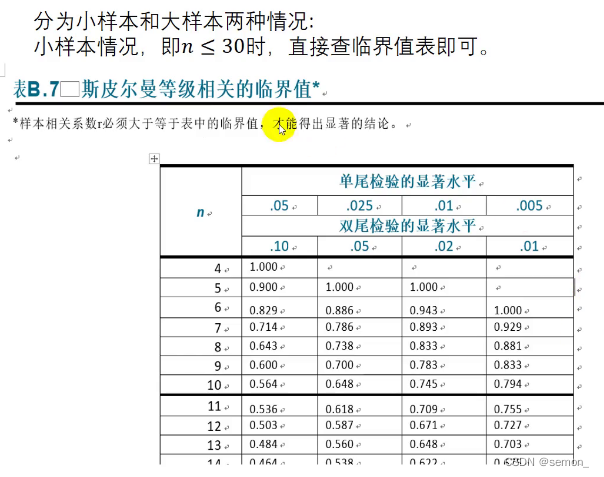
3.区分比较:

4.代码
代码部分只需要改一下methor即可,对于第三种方法kendalltau并没有相关介绍,一般spearman便可以解决90%以上问题,所以我们的文章到这里就结束了。
corr= data.corr(method='spearman')
corr= data.corr(method='kendalltau')
rho, p_value = spearmanr(X, Y)
tau, p_value = kendalltau(X, Y)
清风老师课程b站链接 1.1 层次分析法模型部分_哔哩哔哩_bilibili
优秀论文:
file:///C:/Users/86156/Desktop/清风数学建模课件和代码/正课视频配套的课件和代码/第5讲. 相关系数/扩展资料/皮尔逊相关系数:常州大学一等奖淡水养殖池塘水华发生及池水自净化研究.pdf
file:///C:/Users/86156/Desktop/hh/数学建模/2023C/C050-20240327-202502.pdf















 2096
2096

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









