







引言
字符串的模式匹配是一种常用的操作。模式匹配(pattern matching),简单讲就是在文本(text,或者说母串str)中寻找一给定的模式(pattern)。通常文本都很大,而模式则比较短小。典型的例子如文本编辑和DNA分析。在进行文本编辑时,文本通常是一段话或一篇文章,而模式则常常是一个单词。若是对某个指定单词进行替换操作,则要在整篇文章中进行匹配,效率要求肯定是很高的。
模式匹配的朴素算法
最简单也最容易想到的是朴素匹配。何为朴素匹配,简单讲就是把模式串跟母串从左向右或从右向左一点一点比较:先把模式串的第一个字符同母串的第一个字符比较,若相等则接着比较后面的对应字符;若不等,把模式串后移一个位置,再次从模式串的头部比较……
这如同枚举法:把母串中与模式串相同长度的子串挨个比较。则这种匹配方式显然无任何启发性或智能性。如下图:
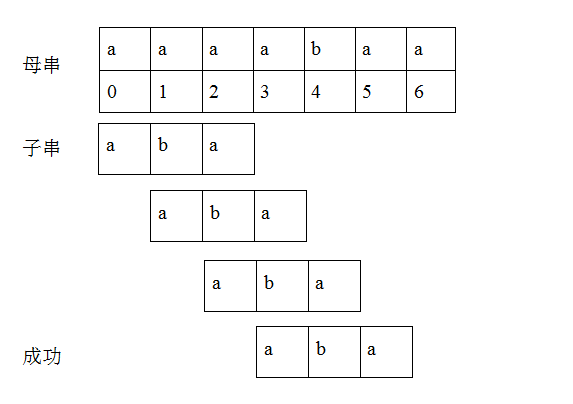
以上步骤很容易看懂,它的代码也各种各样,下面是其中一种:
/*
朴素的模式匹配算法,匹配方向:从前往后
匹配成功,则返回匹配成功时主串的下标位置(只返回第一次匹配成功的位置)
否则,返回-1
母串或子串有一个为空也返回-1
*/
int naiveStringMatching(const char* T, const char* P)
{
if (T && P)
{
int i, j, lenT, lenP;
lenT = strlen(T);
lenP = strlen(P);
//模式串的长度比主串还长,显然无法匹配
if (lenP > lenT)
return -1;
i = 0;
while (i <= lenT-lenP)
{
j = 0;
if (T[i] == P[j])
{
j++;
//指针的写法是这样的:while(j < lenP && *(T + i + j) == *P(j))j++;
while (j < lenP && T[i + j] == P[j])
j++;
//顺利匹配到了模式串的结尾,则匹配成功
if (j == lenP)
return i;
}
i++;
}
//如果程序运行到这里,仍然没有结束,说明没有匹配上
return -1;
}
return -1;
}考虑到有时需要使用c++中的string类型,这时它的代码是这样的:
int naiveStringMatching(const string T, const string P)
{
int i, j, lenT, lenP;
lenT = T.length();
lenP = P.length();
//串空或模式串的长度比主串还长,显然无法匹配
if (lenT == 0 || lenP == 0 || lenP > lenT)
return -1;
i = 0;
while (i <= lenT - lenP)
{
j = 0;
if (T[i] == P[j])
{
j++;
while (j < lenP && T[i + j] == P[j])
j++;
if (j == lenP)
return i;
}
i++;
}
return -1;
}不要小看上面的代码,虽然效率不高,但仍有掌握的必要。代码和算法总是在不断优化的,而这一切的优化都是从简单的情形开始的。
朴素匹配的时间复杂度是很容易分析的。若是成功匹配,最好的情况下,第一次比较就匹配上了,此时只需strlen(P)次(模式串的长度次)比较。最坏的情况下,一直需要比较到母串最后一个长度与模式串相同的子串,共(strlen(T)-strlen(P)+1)*strlen(P)次比较。平均下是O(strlen(T)*strlen(P))。
KMP算法
KMP算法是一种用于字符串匹配的算法,这个算法的高效之处在于当在某个位置匹配不成功的时候可以根据之前的匹配结果从模式字符串的另一个合适的位置开始,而不必每次都从头开始匹配。该算法由Knuth、Morris和Pratt三人设计,故取名为KMP。
KMP的改进之处
回顾一下上文讲的的朴素匹配算法,每次失配的时候,都是 i++;j=0; 从画面上看,就是把模式串相对于主串向后移动一个位置,再次从模式串的首字符开始新的一轮比较。用数学的形式讲,这是 i++;j=0; 的几何意义。
失配时,记主串的下标为i,此时模式串的下标是j。则可以肯定已有j个字符成功匹配。如下图:
Ti-j Ti-j+1
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2886
2886











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









