







定义:
分类就是得到一个函数或分类模型(即分类器),通过分类器将未知类别的数据对象映射到某个给定的类别。
1. 数据分类可以分为两步
第一步建立模型,通过分析由属性描述的数据集,来建立反映其特性的模型。该步骤也称为是有监督的学习,基于训练集而到处模型,训练集合是已知类别标签的数据对象。第二步使用模型对数据对象inxing分类。首先评估对象分类的准确度或者其他指标,如果可以接受,才使用它来对未知类别标签的对象进行分类。
2. 预测的目的
预测的目的主要是从历史数据记录中自动推导出对给定数据的推广描述,从而能够对实现未知类别的数据进行预测。分类和回归是两类主要的预测问题,分类是预测离散的值,回归是预测连续值。
3.分类器的使用和输出
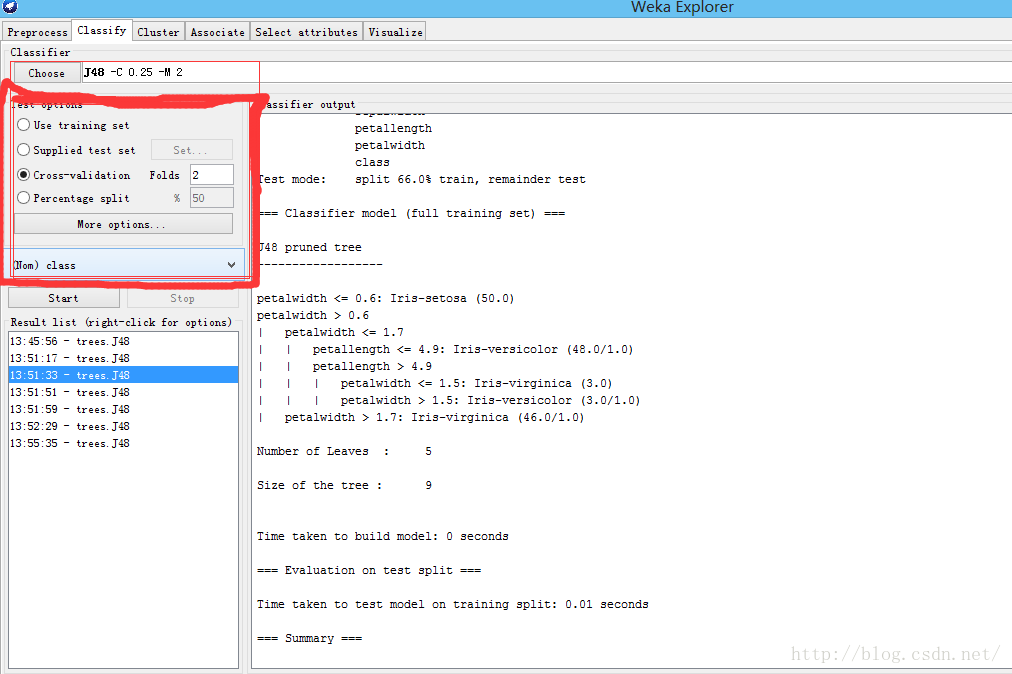
3.1 测试选项
- 使用训练集
- 提供测试集
- 交叉验证
- 按照比例分割
3.2 输出结果
运行信息:
=== Run information ===
//学习方案以及选项
Scheme: weka.classifiers.trees.J48 -C 0.25 -M 2
//关系名称
Relation: iris
//实例数目
Instances: 150
//属性数目
Attributes: 5
sepallength
sepalwidth
petallength
petalwidth
class
//测试模式
Test mode: evaluate on training data
///分类器模型 (完整的训练集合)
=== Classifier model (full training set) ===
J48 pruned tree
------------------
petalwidth <= 0.6: Iris-setosa (50.0)
petalwidth > 0.6
| petalwidth <= 1.7
| | petallength <= 4.9: Iris-versicolor (48.0/1.0)
| | petallength > 4.9
| | | petalwidth <= 1.5: Iris-virginica (3.0)
| | | petalwidth > 1.5: Iris-versicolor (3.0/1.0)
| petalwidth > 1.7: Iris-virginica (46.0/1.0)
Number of Leaves : 5
Size of the tree : 9
Time taken to build model: 0.05 seconds
=== Evaluation on training set ===
Time taken to test model on training data: 0.01 seconds
总结
=== Summary ===
//正确分类的实例
Correctly Classified Instances 147 98 %
//错误分类的实例
Incorrectly Classified Instances 3 2 %
//Kappa统计: 用于评判分类器的分类结果和随机分类的差异度。K=1表明和分类器和随机分类完全不同;K=0表明二者之间相同;K=-1表明分类器比随机分类效果还差。 值 越接近1 越好。
Kappa statistic 0.97
//平均绝对误差【0,1】
Mean absolute error 0.0233
//均方根误差[0,1]
Root mean squared error 0.108
//相对绝对误差
Relative absolute error 5.2482 %
//相对均方根误差
Root relative squared error 22.9089 %
//案例的覆盖程度 百分数越大越好
Coverage of cases (0.95 level) 98.6667 %
//平均相对区域的大小
Mean rel. region size (0.95 level) 34 %
//实例总数
Total Number of Instances 150
//按照类别的详细准确性
=== Detailed Accuracy By Class ===
TP Rate FP Rate Precision Recall F-Measure MCC ROC Area PRC Area Class
1.000 0.000 1.000 1.000 1.000 1.000 1.000 1.000 Iris-setosa
0.980 0.020 0.961 0.980 0.970 0.955 0.990 0.969 Iris-versicolor
0.960 0.010 0.980 0.960 0.970 0.955 0.990 0.970 Iris-virginica
Weighted Avg. 0.980 0.010 0.980 0.980 0.980 0.970 0.993 0.980
混淆矩阵
=== Confusion Matrix ===
a b c <-- classified as
50 0 0 | a = Iris-setosa
0 49 1 | b = Iris-versicolor
0 2 48 | c = Iris-virginica4. 分类算法介绍
下面介绍一下常用分类算法,贝叶斯和神经网络分类算法,我们放在后面在专题分析。
4.1 线性回归
线性回归是利用数理统计中的回归分析,来确定多个变量之间相互依赖的定量关系的一种统计分析方法。线性回归的主要目标是用于预测。线性回归使用观测数据集y值和x值来拟合一个预测模型,构建这样一个模型后,如果给出一个新的x值,但没有给出相应的y值,这时就可以用预测模型预测y值。
4.2决策树
决策树是一种预测模型,它包括决策结点、分支和叶结点三个部分。其中,决策结点代表一个测试,通常代表分类样本的某个属性,在该属性不同测试结果就代表一个分支,分支表示某个决策结点的不同取值。每个叶结点存放某个类别标签,表示一种可能的分类结果。
4.3基于规则的分类器
基于规则的分类器是使用一组判断规则来对记录进行分类的技术。模型的规则使用析取范式。
4.4 基于实例的算法
基于决策树分类和基于规则的分类框架包括两个步骤:第一步是归纳步,由训练数据构建分类模型;第二步是演绎步,将模型应用于测试样本。
前面介绍的分类都是先对训练数据进行学习,得到分类模型,然后对未知数据进行分类,这种分类方法称为积极学习器。与之相反的策略是推迟对训练数据的建模,知道需要对未知样本进行分类时才进行建模,采用这种策略的分类器称为消极学习器。最典型的代表是最近邻方法。KNN(Nearest Neighbor)途径是找出与测试样本相对接近的所有训练样本,这些训练样本称为NN,然后使用最近邻的类别标签来确定测试样本的类别属性。
4.5 支持向量机
支持向量机(SVM)是一种监督式学习的分类器。广泛应用于统计分类和回归分析。SVM的特点是能够同时最小化经验误差与最大化几何边缘。
支持向量机有坚实的统计学理论基础,并且在时间上有诸多成功的案例。SVM可以很好的用于高维数据,避免维数灾难。她有一个独特的特点,就是使用训练实例的一个子集来表示决策边界,该子集称为支持向量。支持向量机的使用原理就是要构建找到最大边缘超平面,所定义的线性分类器称为最大边缘分类器。














 541
541











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









