







一 Protocol Buffers 简介
Protocol Buffers是一个独立于语言和平台的,扩展性良好的存取结构数据的技术,主要用于传输协议格式和数据存储方面。 它是Google公司的一个开源 项目,最初用以解决索引服务器的请求、响应协议。
简单地说,Protocol Buffers其实和XML 差不多,也就是把某种数据结构的信息,以某种格式保存起来。
和XML相比,Protocol Buffers的性能好和效率比XML高,XML序列化和反序列化的速度没有Protocol Buffers效率高,尤其是反序列化的速度。还有就是空间的开销,XML格式为了有较好的可读性,引入了一些冗余的文本信息。由于Google公司赖以吹嘘的就是它的海量数据和海量处理能力。对于几十万、上百万机器的集群,动不动就是PB级的数据量,哪怕性能稍微提高 0.1% 也是相当可观。所以Google自然无法容忍XML在性能上的明显缺点,正是在这样的情况以protobuf也就应运而生了。
另外,Protocol Buffers具有良好的版本兼容性,在原协议更新后,原有的老的协议可以继续在新协议上使用。
现在Google官方发布标准Protocol Buffers包支持C++,java,Python,包含一个Protocol Buffers编译器和一个Protocol Buffers使用的类库。除此之外还有开源社区贡献的支持其他语言版本的Protocol Buffers软件包,包括Golang,PHP,C#,Ruby等。在下一篇博客中我将会介绍Go 语言环境中使用Protocol Buffers.
二 Protocol Buffers的使用
1.定义消息格式 --书写.proto 消息描述文件
从某种意义上讲,可以把proto文件看成是描述通讯协议的规格说明书(或者叫接口规范)。
a.指定域类型
基本类型的描述如下图所示:
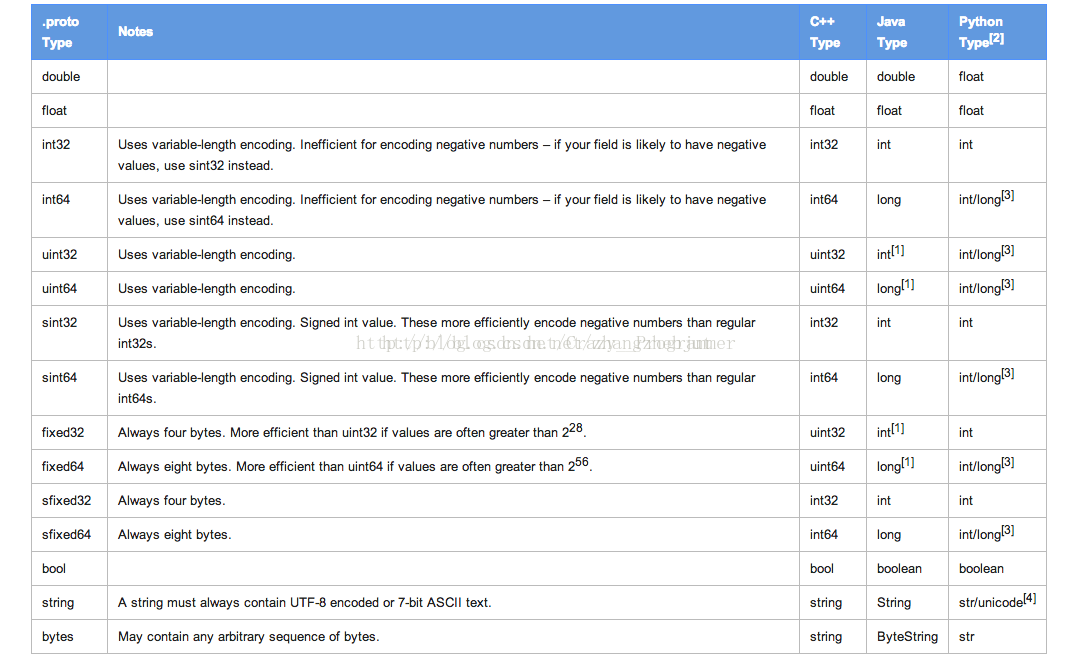
除此之外,还有枚举(enum)和消息(message)类型。
注:1. group类型已经不建议使用,使用message来代替。
2. 所有的类型关键字都是小写的 例如message enum int32 string等。
b.为每个域指定一个数字标签(TAG)
该标签是将消息转化为二进制格式时用来标示该字段用的,所以在一个消息体内,必须是唯一的。
注:
1.在进行编码的时候1-15号占用一个字节(包括域的数字标识标签和域的类型); 16-2047占用两个字节,所以在使用的时候尽量使用1-15号来表示经常使用的字段,这样可以减少消息体编码后的长度。
c.指定字段的访问属性
-
required: 非空字段 -
optional: 可选字段 -
repeated: 可重复字段 (相当于一个可变数组,会保持元素的顺序)
注:1.在使用required字段的时候一定要慎重,例如在实际的应用过程中业务发生了改变,如果你把原来的required改为了optional,那么原来使用required读取消息的使用者在收到新改变后的消息后如果没有这个这个字段的话可能会认为该消息不完整而丢弃。Google工程师建议是尽量少使用requried访问属性
2.可选字段会有默认的值,对于字符串默认值是空串 整型是零 布尔类型是假 枚举类型是枚举体中的第一个元素,除此之外我们也可以为其指定默认值。例如:
message SearchRequest {
required string query = 1;
optional int32 page_number = 2;
optional int32 result_per_page = 3 [default = 10];
enum Corpus {
UNIVERSAL = 0;
WEB = 1;
IMAGES = 2;
LOCAL = 3;
NEWS = 4;
PRODUCTS = 5;
VIDEO = 6;
}
optional Corpus corpus = 4 [default = UNIVERSAL];
}
关于消息的定义还应注意以下几点:
a.可以在一个.proto文件中定义多个message消息表述体,在定义消息体的时候可以添加自己的注释代码,这样增加易读性。
b.proto的定义是可以引用的,例如:
import "myproject/other_protos.proto";
c.对于message建议使用驼峰命名法,对于消息体内的变量建议使用下划线分割单词的方法,例如:
message SongServerRequest {
required string song_name = 1; }
d.经过Google Base 128 Varints编码后的二进制流中,每个字段都是以键值对的形式进行序列化,键为字段的Tag编号和类型编号组合。
2.使用protocol buffer编译器
protoc --proto_path=IMPORT_PATH --cpp_out=DST_DIR --java_out=DST_DIR --python_out=DST_DIR path/to/file.proto
1.proto_path 表示.proto文件所在的文件夹
2.DST_DIR 表示编译后生成的文件存放路径
3. ccp_out 表示要产生c++相应代码
java_out 表示j要产生ava相应代码
4.path/to/file.proto 用来表示.proto文件
注意:
--proto_path=IMPORT_PATH 可以使用 -I=IMPORT_PATH 来简写。
3.使用c++ protocol buffer API 来读写消息
https://developers.google.com/protocol-buffers/docs/overview (需要翻墙)
https://developers.google.com/protocol-buffers/docs/overview (需要翻墙)
三 总结
什么东西都是两面性,虽然Protocol Buffers “格式小 速度快 兼容性好”,但是它也有自己的缺点。
主要是以下几个方面:
a.Protocol Buffers可读性差 XML是便于人类阅读和编辑的,而ProtocolBuffer则不是。XML是自解释的,而 ProtocolBuffer仅在你拥有报文格式定义的 .proto 文件时才有意义. XML是自描述的,而protobuf格式则不是,它采用的是二进制格式进行编码(Base 128 Varints)。给你一段二进制格式的协议内容,如果不配合相应的proto文件,那简直就像天书一般。
b.技术比较新 由于protobuf刚公布没多久,相比XML而言,protobuf还属于初出茅庐。因此,在知名度、应用广度等方面都远不如XML。由于这个原因,假如你设计的系统需要提供若干对外的接口给第三方系统调用,俺奉劝你暂时不要考虑protobuf格式。
总之,Protocol Buffers并不是在任何时候都比XML更合适,例如Protocol Buffers无法对一个基于标记文本的文档建模,因为你根本没法方便的在文本中插入结构。我们应该根据具体的项目需要,选取合适的技术。
补充关于 Google Base 128 Varints
Google Protobuf里面提出了“Base 128 Varints”编码,这是一种变字节长度的编码,官方描述为:varints是用一个或多个字节序列化整形的一种方法。它的编码方式如下:
(1)除了最后一个字节,varint中的每个字节的最高位设为1,表示后面还有字节出现,如果是0表示后面没有字节了
例如:0000 0001表示一个字节 1010 1100 0000 0010表示两个字节,由于第一个字节后面还有一个字节,所以第一个字节的最高位设置为1,表示后面还有后继字节,第二个字节的最高位为0。
(2)每个字节的低7位看成是一个组(group),这个组和他相邻的下一个7位组共同存储某个整形的“组合表示”,最低有效组在前面。
对于1010 1100 0000 0010,去掉每个字节的最高位,我们对两个字节进行分组。第一个7位组:0101100,第二个7位组:0000010,组合起来就是:0101100 0000010,由于最低有效组在前面,所以两个7位组进行调换,结果为:0000010 0101100,中间的空格是为了大家区分,去掉前面的0,也就是:100101100,十进制为1*2^8 + 1*2^5 + 1*2^3 + 1*2^2 = 256 + 32 + 8 + 4 = 300。
(3)三个字节。我们换种方式,给定某个整形,要求写出他的varint表示,这里当然是落在需要3个字节表示的整形。16380可以吗?不可以!因为16380 < 2^14,所以2个字节足以,我们就以27491为例,27491的二进制表示为:
0110 1011 0110 0011
注意这里是高字节之前,低字节在后,和varint的编码规则相反,首先按照7位一组划分为:0000001 1010110 1100011,然后反转为:1100011 1010110 0000001,最后将末尾的7位组前面补0组成一个字节,两个7位组都补1分别组成一个字节:11100011 11010110 00000001
(4)更多字节。聪明的你可能发现,varint编码中4个字节最大表示的数为2^28,非常正确,同时说明了天下没有免费的午餐,有得有失。Protobuf引入了fixed32解决这个问题的,如果某个字段经常大于2^28,应当优选fixed32,他是固定长度为32位的。














 1930
1930











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









