







这篇论文提出了一种获取词向量的方法,该方法不仅考虑词的局部段落(local context)信息,也考虑了全局文本(global context)信息,这样得到的词向量不仅能表示语义信息,也能表示句法信息。同时,本文还提出了一种识别一词多义的方法,在聚类时同一个词的不同意思能划分到不同的类别之中。
下面是本文的一些要点:
1、 常见VSM(vector-spacemodel)的问题
一个词只能表示为一个向量,无法解决同音异义词(发音相同但意义不同)和一词多义的词。针对这一点,本文提出了一个新的基于神经网络的语言模型,该模型把局部和全局文本结合起来作为训练目标,结果表明这要比单独使用局部文本或单独使用全局文本的效果要好。
2、 global context-aware neural language model(考虑全局文本的神经网络语言模型)
这个模型的特点就是考虑了全局文本,训练的目标不再是给出一些词考虑下一个词是某个词的概率,而是学习得到一种有用的词表示方式。在给定词序列s以及文档d的情况下,试图从一批随机词中区别出位于s序列最后的一个正确的词。目标函数为:
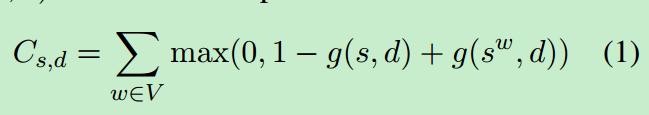
其中g(s,d)为得分函数,g(sw,d)为s序列中最后一个词由词w替代后的得分函数。同时,需要把两者差值控制在[0,1]范围之内。
有了目标函数之后,神经网络的结构表示如下:
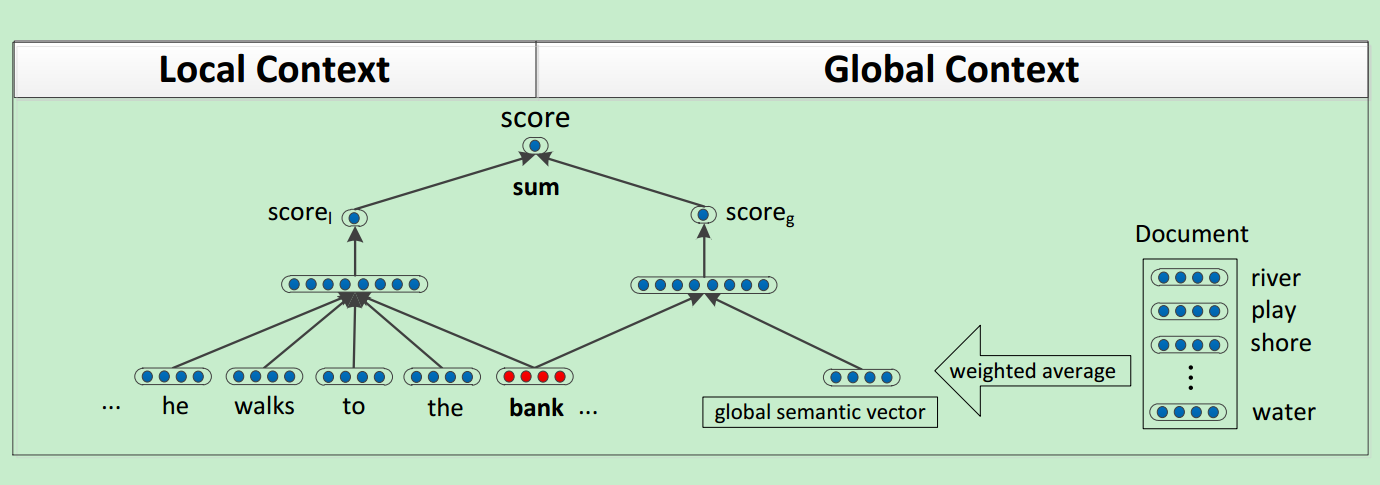
得分函数由两个神经网络构成,一个是针对局部上下文进行训练,一个针对全局文本进行训练。
针对局部上下文时,针对一个文本序列s,可以将其表示为一系列的向量x=(x1,x2…xm),得分函数如下:
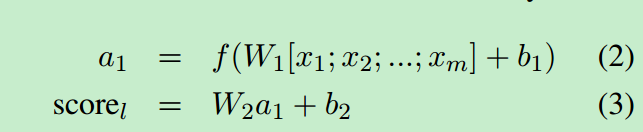
其中f是一个激活函数,W1,W2为神经网络第一层和第二层的权重。a1是隐层的激活函数,b1,b2是每一层的偏差值。
针对全局上下文时,我们把整个文档表示为一个词向量列表,d={d1,d2…dk},首先计算出所有文档中的词的平均权重:
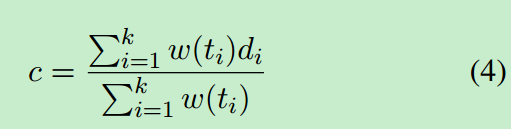
其中w(ti)表示词ti在文本中的重要度,这里可以用idf权值来表示。得分函数如下:
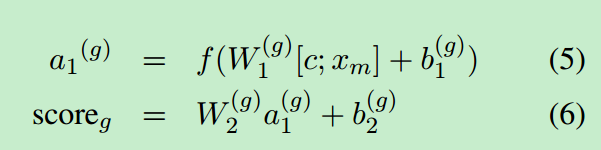
其中c就是平均权重,其余同局部上下文中的参数。最终的得分为两个得分之和:
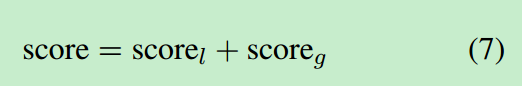
局部score保留了文档中词的顺序以及句法信息,全局score视野了权重特征,这一点类似于词袋模型,其中保存了文档的语义和话题信息。
3、 multi-prototype neural language model(多原型神经网络语言模型)
该神经网络是为了解决一词多义的问题,使用不同的表示形式来描述某个词的多组意义。为了能够学习多原型,需要经过下面几个步骤:
-首先针对每个词出现的位置设定一个固定大小的窗口(前后各5),得到一个短句,对窗口中的词求其平均权重,这一点类似于求全局权重c的步骤
-其次使用spherical k-means聚类方法对这些短句进行聚类
-最后每个词在其所属的类别中被重新标记,用于训练类别中的词向量
两个词之间的距离可以定义如下:
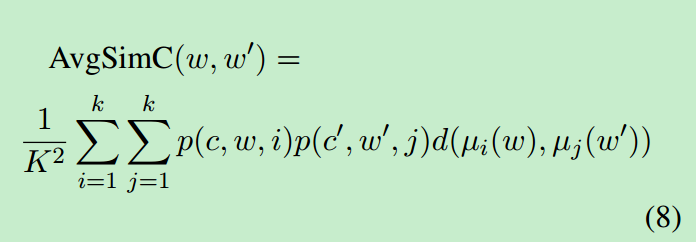
其中p(c,w,i)为词w在给定上下文c的情况下属于类别i的概率,ui(w)表示第i个类别中心点w,d(v,v’)为两个词之间距离计算函数。
4、 实验对比
本文提出了两种神经网络语言模型,故存在两个实验对比:
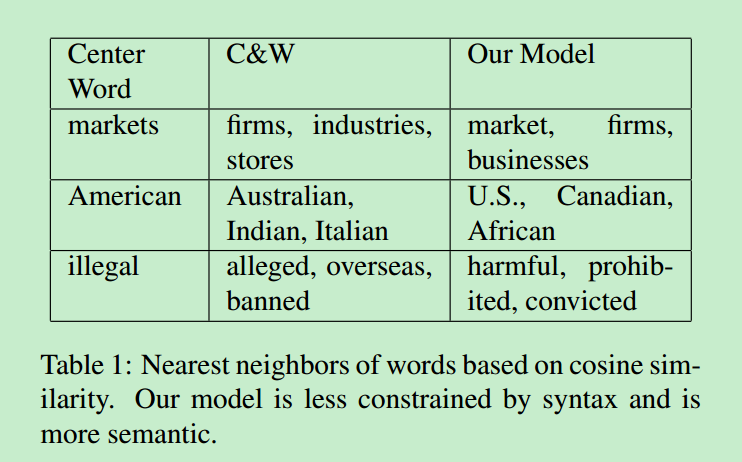
上表为对两种方法得到的聚类结果进行对比,其中C&W方法只使用了局部文本信息,可以看到本文提出的方法要优于该方法。
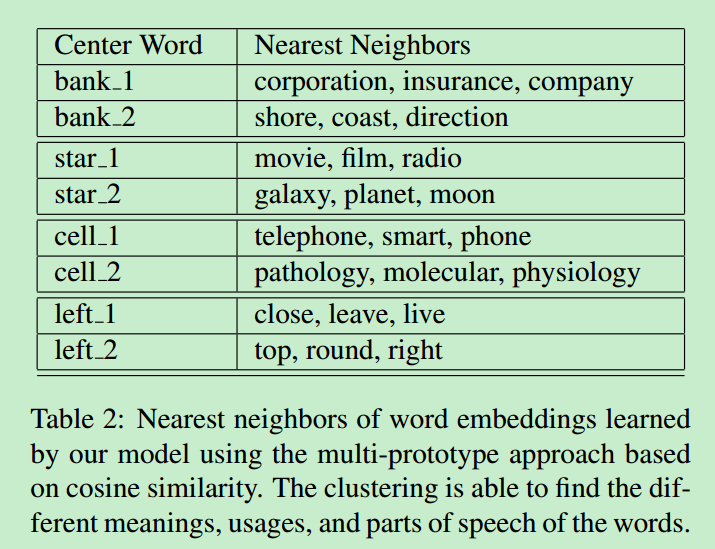
上表为一词多义的聚类结果,可以看到效果还是挺不错的。














 399
399











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









