






词向量的表示不仅是作为算法的输入还是作为单词的一种特征表示在自然语言处理的相关问题中都被证明是有效的。然而传统的词向量模型是建立在局部的文本之上的,全部的文本往往能够提供更加丰富的信息。而且每一个单词,只有唯一的一种表示,这对于处理多义词来说存在着问题。这篇文章就是针对这两个问题提出了一种新的模型,希望结合局部和全局的语义信息来学习到更好的词向量的表示,同时针对同音多义词和一词多义的情况,为每个单词建立多种词向量的表示。
这篇文章的目的就是要学习到一个好的词向量,而不是要给定前几个词来预测下一个词的概率。所以就可以利用整篇文档来提供全局的信息。所利用的局部信息是给定一个单词序列去猜测下一个出现的单词。而全局的信息则是猜测包含单词序列的文档。这篇文章的方法恰是将两者结合起来。给定一个单词序列s,和包含该序列的文档d,目标是预测序列的最后一个单词。需要计算两个指标g(s,d)和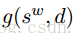
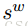
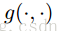
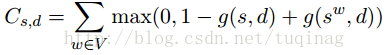
由于需要获取局部和全局的信息,就需要有两个神经网络来分别计算,网络的具体结构如下:
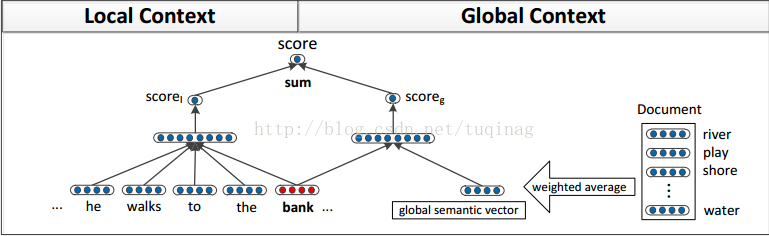
其中模型的输入均为单词的词向量。在对文档中的单词进行加权平均时,所使用的方法是: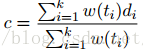
在训练时,获取目标函数的梯度的方式是:“choose a word from the dictionary as a corrupt example for each sequence-document pair, (s,d), and take derivative of the ranking loss with respect to the parameters.” 通过mini-batch L-BFGS 算法来实现模型参数的更新,这里的参数包括了网络中的连接权值和词向量矩阵。
文章中提出的计算每个单词不同表示的具体方法如下:首先以一个固定大小的窗口收集某一个单词的上下文信息(文章中窗口大小的取值是5)。然后使用idf系数作为权值对上下文的单词对应的词向量进行加权平均。随后使用spherical k-means 算法对之前的结果进行聚类,该聚类方法已被证明是能够较好地获取语义之间的联系。最后对每一个聚类中的单词计算其对于该聚类簇的词向量。















 466
466

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









