







有时候我们用爬虫来爬取搜索引擎时,想获取在搜索引擎中搜索关键字得到的结果页数,总不能一页一页的翻下去吧。。。
所以可以采用下面的技巧来获得:
如,我们在百度搜索引擎中搜索“无极道”这个关键字,想知道结果到底有几页,我们可以在浏览器的网址输入框中输入:https://www.baidu.com/s?wd=无极道&pn=750,注意一定要用750,好像其他的数字是不行的,原因我也不知道,哈哈,反正只要管用就行,“wd=”后面跟的是要搜索的关键字。

然后就会返回一个html页面,最下面的页数就是总页数,如图:
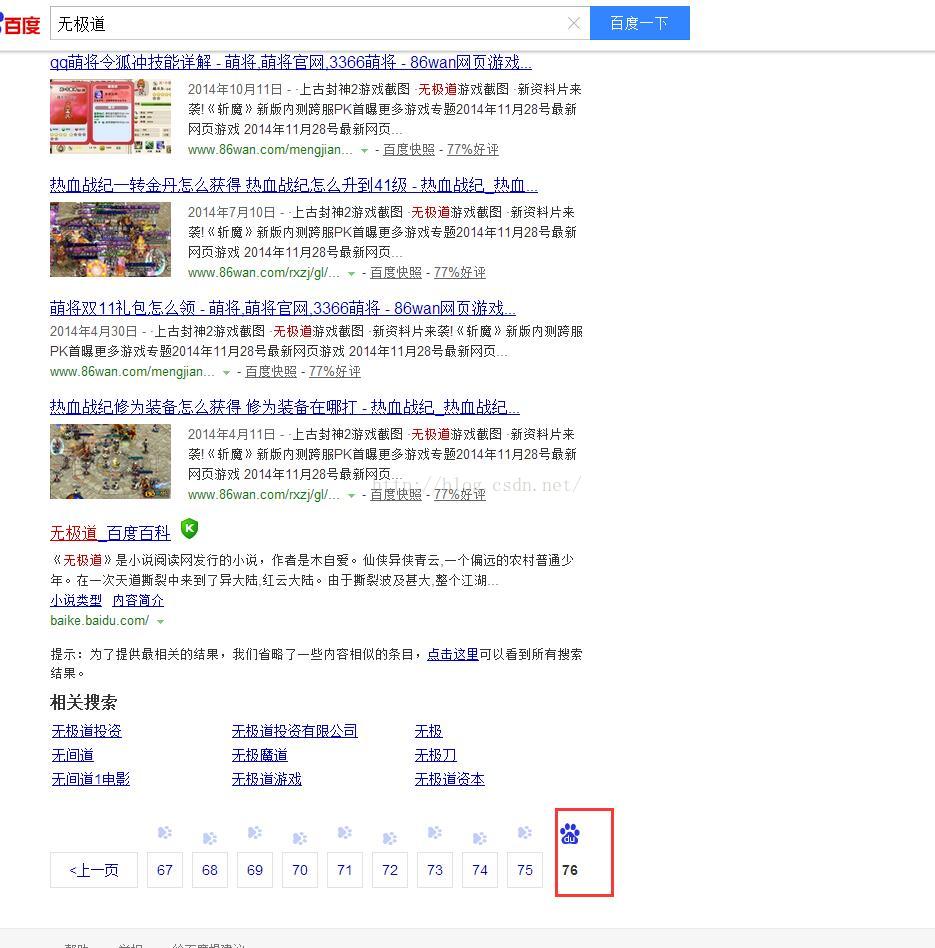
有时候不会这么幸运,有可能返回的是第一页。。。。
欧欧,不过没事,如果真的是这样的话还有另外一种方式:
查看这个返回页面的源码:右键鼠标->查看源代码,在源代码页,Ctrl+F,搜索:pageNum。如图:

上图中的那个数字就是总页数。666。。。。ok!!!














 765
765











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









