







转载请声明出处:http://blog.csdn.net/zhongkelee/article/details/46801449
综述
Java集合就是一个容器。面向对象语言对事物的体现都是以对象的形式存在,所以为了方便对多个对象的操作,就对对象进行存储,集合就是存储对象最常用的一种方式。集合只用于存储对象,集合长度是可变的,集合可以存储不同类型的对象。如果往集合里存放基本数据类型,在存取过程中会有个自动装箱和拆箱。
因为容器中数据结构不同,容器有很多种。不断地将共性功能向上抽取,形成了集合体系,称之为集合框架。
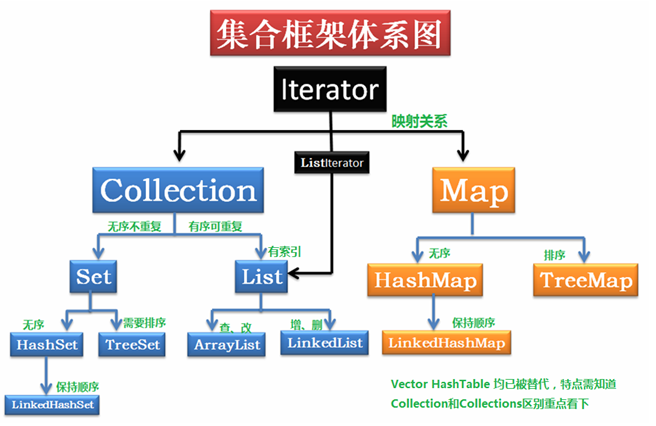
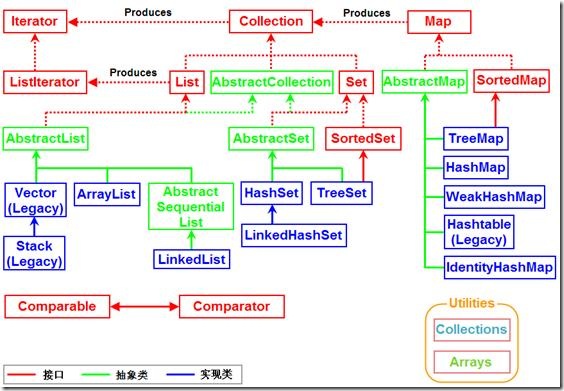
集合框架的顶层就称之为Collection接口。所有的集合类都位于java.util包下,查阅API可以得到如下体系结构。在使用一个体系时,原则:参阅顶层内容。建立底层对象。
集合和数组的区别:
1:数组是固定长度的;集合可变长度的。
2:数组可以存储基本数据类型,也可以存储引用数据类型;集合只能存储引用数据类型。
3:数组存储的元素必须是同一个数据类型;集合存储的对象可以是不同数据类型。
Collection<E>接口
Collection:单列集合
|--List:有序(元素存入集合的顺序和取出的顺序一致),元素都有索引,允许重复元素。
|--Set:无序(存入和取出顺序有可能不一致),不允许重复元素,必须保证元素的唯一性。
java.util.Collection接口中的共性方法有:
1.添加:
boolean add(Object obj):一次添加一个。
boolean addAll(Collection c):将指定容器中的所有元素添加。
2.删除:
void clear():将集合中的元素全删除,清空集合。
boolean remove(Object o):删除集合中指定的对象。注意:删除成功,集合的长度会改变。
boolean removeAll(Collection c):删除部分元素。部分元素和传入Collection一致。
3.取交集:
boolean retainAll(Collection c):对当前集合中保留和指定集合中的相同的元素。
如果两个集合元素相同,返回false;如果retainAll修改了当前集合,返回true。
4.获取长度:
int size():集合中有几个元素。
5.判断:
boolean isEmpty():集合中是否有元素。
boolean contains(Object o):集合中是否包含指定元素。
boolean containsAll(Collection c)集合中是否包含指定的多个元素。
6.将集合转成数组。
toArray()
toArray([])
下面的代码就是演示Collection中的基本功能。
package ustc.lichunchun.collection.demo;
import java.util.ArrayList;
import java.util.Collection;
public class CollectionDemo {
public static void main(String[] args) {
Collection coll = new ArrayList();
methodDemo(coll);
System.out.println("------------------");
methodAllDemo();
}
/*
* 演示Collection中的基本功能。
*/
public static void methodDemo(Collection coll){
//1.添加元素。
coll.add("abc1");
coll.add("abc2");
coll.add("abc3");
//2.删除
coll.remove("abc2");//移除和添加元素 --> 会改变集合的长度 --> 集合里面实际上存的是对象们的引用
//3.清除。
coll.clear();
//4.判断包含。
System.out.println("contains: "+coll.contains("abc1"));//底层实现判断用的是equals()
System.out.println(coll);
}
/*
* 演示带All的方法。
*/
public static void methodAllDemo(){
//1.创建两个容器。
Collection c1 = new ArrayList();
Collection c2 = new ArrayList();
//2.添加元素。
c1.add("abc1");
c1.add("abc2");
c1.add("abc3");
c1.add("abc4");
c2.add("abc2");
c2.add("abc3");
c2.add("abc5");
//往c1中添加c2。
c1.addAll(c2);
//判断c1中是否包含c2中的所有元素。
boolean b = c1.containsAll(c2);
System.out.println("b = "+b);
//从c1中删除c2。将c1中和c2相同的元素从c1中删除。
c1.removeAll(c2);
//将c1中和c2不同的元素从c1中删除。保留c1中和c2相同的元素。
c1.retainAll(c2);
System.out.println(c1);
}
}疑问:Collection 接口中明明没有toString()声明,怎么可能有权利调用这个ArrayList类的"特有"方法? (虽然ArrayList类继承它父类有toString()复写的方法了,但这个是ArrayList子类特有的方法啊,不符合多态的解释呀?)
下面这段解释截取自Google找到的答案:
楼主懂得思考,先表扬一下。下面将引用一段接口的说明,你可以看看:
9.2 Interface Members
The members of an interface are:Those members declared in the interface.
Those members inherited from direct superinterfaces.
If an interface has no direct superinterfaces, then the interface implicitly declares a public abstract member method m with signature s, return type r, and throws clause t corresponding to each public instance method m with signature s, return type r, and throws clause t declared in Object, unless a method with the same signature, same return type, and a compatible throws clause is explicitly declared by the interface. It is a compile-time error if the interface explicitly declares such a method m in the case where m is declared to be final in Object.
大致意思如下:
9.2 接口方法
一个接口中的方法有:
1).直接声明在接口中的成员方法;
2).直接从父类接口中继承而来的方法;
3).如果一个接口没有直接的父类接口(也就是其自身就是顶层接口),并且在其没有显示声明相关方法时,那该接口则会根据Object中所有的public的实例方法进行一一映射(比如toString,Hashcode等)。当然如果此接口显示去声明一个与Object签名相同并且带有final修饰的方法时,则会有编译期错误。
所以:由超类声明,子类来new。调用的最终是子类中定义的方法,如果子类没有,则调用子类的父类方法。这存在一种向上追溯的过程。说明是完全正确的。
完全赞同!
这里做一点补充。
根据这一条说明,在List list=new ArrayList()之后,在list当中将可以调用object当中所有声明public的方法,而调用的方法实体是来自ArrayList的。而之所以没有list不可以调用,clone()与finalize()方法,只是因为它们是protected的。
学习了。
不过很好奇,33楼的大哥,这条如此原版的声明出自哪个参考书籍呢?学java就该看这种资料啊。 7.取出集合元素。
Iterator iterator():获取集合中元素上迭代功能的迭代器对象。
Iterator<E>接口
java.util.Iterator接口是一个对 collection 进行迭代的迭代器,作用是取出集合中的元素。
Iterator iterator():获取集合中元素上迭代功能的迭代器对象。
迭代:取出元素的一种方式。有没有啊?有!取一个。还有没有啊?有!取一个。还有没有啊?没有。算了。
迭代器:具备着迭代功能的对象。迭代器对象不需要new。直接通过 iterator()方法获取即可。
迭代器是取出Collection集合中元素的公共方法。

每一个集合都有自己的数据结构,都有特定的取出自己内部元素的方式。为了便于操作所有的容器,取出元素,将容器内部的取出方式按照一个统一的规则向外提供,这个规则就是Iterator接口。
也就说,只要通过该接口就可以取出Collection集合中的元素,至于每一个具体的容器依据自己的数据结构,如何实现的具体取出细节,这个不用关心,这样就降低了取出元素和具体集合的耦合性。
Iterator it = coll.iterator();//获取容器中的迭代器对象,至于这个对象是是什么不重要。这对象肯定符合一个规则Iterator接口。
package ustc.lichunchun.collection.demo;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
public class IteratorDemo {
public static void main(String[] args) {
//1.创建集合。
Collection coll = new ArrayList();
coll.add("abc1");
coll.add("abc2");
coll.add("abc3");
//方式一:获取该容器的迭代器。
Iterator it = coll.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
//方式二:直接for+alt+/,选择第三个。
for (Iterator it = coll.iterator(); it.hasNext();) {
System.out.println(it.next());
}
System.out.println(it.next());//abc1
System.out.println(it.next());//abc2
System.out.println(it.next());//abc3
System.out.println(it.next());//java.util.NoSuchElementException
}
}public Iterator<E> iterator() {
return new Itr();//取出ArrayList容器中元素的迭代器功能,返回的是一个Itr()迭代器对象,也就是实现Iterator接口的内部类对象。
}
/**
* An optimized version of AbstractList.Itr
*/
private class Itr implements Iterator<E> {//-->ArrayList容器的内部类,实现了Iterator迭代接口(迭代器),里面有hasNext()、next()、remove()方法。
int cursor; // index of next element to return
int lastRet = -1; // index of last element returned; -1 if no such
int expectedModCount = modCount;
public boolean hasNext() {
return cursor != size;
}
@SuppressWarnings("unchecked")
public E next() {
checkForComodification();
int i = cursor;
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[lastRet = i];
}
public void remove() {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
ArrayList.this.remove(lastRet);
cursor = lastRet;
lastRet = -1;
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
@Override
@SuppressWarnings("unchecked")
public void forEachRemaining(Consumer<? super E> consumer) {
Objects.requireNonNull(consumer);
final int size = ArrayList.this.size;
int i = cursor;
if (i >= size) {
return;
}
final Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length) {
throw new ConcurrentModificationException();
}
while (i != size && modCount == expectedModCount) {
consumer.accept((E) elementData[i++]);
}
// update once at end of iteration to reduce heap write traffic
cursor = i;
lastRet = i - 1;
checkForComodification();
}
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}List本身是Collection接口的子接口,具备了Collection的所有方法。List集合的具体子类:子类之所以区分是因为内部的数据结构(存储数据的方式)不同。
List:有序(元素存入集合顺序和取出一致),元素都有索引,允许重复元素-->自定义元素类型都要复写equals方法。
|--Vector:底层的数据结构是数组。数组是可变长度的。线程同步的。增删和查询都巨慢!
|--ArrayList:底层的也是数组结构,也是长度可变的。线程不同步的,替代了Vector。增删速度不快。查询速度很快。(因为在内存中是连续空间)
|--LinkedList:底层的数据结构是链表,线程不同步的。增删速度很快。查询速度较慢。(因为在内存中需要一个个查询、判断地址来寻找下一元素)
可变长度数组的原理:
不断new新数组并将原数组元素复制到新数组。即当元素超出数组长度,会产生一个新数组,将原数组的数据复制到新数组中,再将新的元素添加到新数组中。
ArrayList:是按照原数组的50%延长。构造一个初始容量为 10 的空列表。
Vector:是按照原数组的100%延长。
首先学习List体系特有的共性方法,查阅方法发现List的特有方法都有索引(角标),这是该集合最大的特点。也就是说,List的特有方法都是围绕索引(角标)定义的。
List集合支持对元素的增、删、改、查。
1.添加(增):
add(index, element):在指定的索引位插入元素。
addAll(index, collection):在指定的索引位插入一堆元素。
2.删除(删):
remove(index):删除指定索引位的元素。 返回被删的元素。
3.获取(查):
element get(index):通过索引获取指定元素。
int indexOf(element):获取指定元素第一次出现的索引位,如果该元素不存在返回—1;所以,通过—1,可以判断一个元素是否存在。
int lastIndexOf(element) :反向索引指定元素的位置。
List subList(start,end) :获取子列表。
4.修改(改):
element set(index, newElement):对指定索引位进行元素的修改。
下面的代码演示了List的特有方法:
package ustc.lichunchun.list.demo;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class ListDemo {
public static void main(String[] args) {
List list = new ArrayList();
methodDemo(list);
}
/*
* 演示List特有的方法。
*/
public static void methodDemo(List list){
//1.常规添加元素。
list.add("abc1");
list.add("abc2");
list.add("abc3");
//2.插入元素。
list.add(1,"hehe");
//3.删除。
list.remove(1);
list.remove(1);
//4.获取。
System.out.println(list.get(3));// java.lang.IndexOutOfBoundsException
System.out.println(list.get(1));
System.out.println(list.indexOf("abc3"));
//5.修改。
list.set(1,"keke");
System.out.println(list);
//6.取出集合中所有的元素。
for (Iterator it = list.iterator(); it.hasNext();) {
System.out.println("iterator: "+it.next());
}
//7.List集合特有的取出方式。遍历。
for (int i = 0; i < list.size(); i++) {
System.out.println("get: "+list.get(i));
}
}
}ListIterator listIterator():list集合特有的迭代器。
在进行list列表元素迭代的时候,如果想要在迭代过程中,想要对元素进行操作的时候,比如满足条件添加新元素。会发生ConcurrentModificationException并发修改异常。
导致的原因是:集合引用和迭代器引用在同时操作元素,通过集合获取到对应的迭代器后,在迭代中,进行集合引用的元素添加,迭代器并不知道,所以会出现异常情况。
如何解决呢?既然是在迭代中对元素进行操作,找迭代器的方法最为合适。可是Iterator中只有hasNext,next,remove方法。通过查阅的它的子接口,ListIterator,发现该列表迭代器接口具备了对元素的增、删、改、查的动作。
ListIterator是List集合特有的迭代器。
ListIterator it = list.listIterator; //取代Iterator it = list.iterator;

package ustc.lichunchun.list.demo;
import java.util.ArrayList;
import java.util.List;
import java.util.ListIterator;
public class ListIteratorDemo {
public static void main(String[] args) {
List list = new ArrayList();
list.add("abc1");
list.add("abc2");
list.add("abc3");
list.add("abc4");
//需求:在遍历的过程中,如果遍历到abc2,添加一个元素haha
for (Iterator it = list.iterator(); it.hasNext();) {
Object obj = it.next();//java.util.ConcurrentModificationException
if(obj.equals("abc2")){
list.add("haha");
}
}
//上述代码出现的问题:
//迭代器it在操作容器元素,迭代过程中使用了集合对象list同时对元素进行操作。
//产生迭代结果的不确定性,引发了并发修改异常。
//解决思想:在迭代过程中,想要执行一些操作,使用迭代器的方法就可以了。
//使用List集合特有的迭代器:ListIterator,通过List集合的方法listIterator()获取该列表迭代器对象。
//ListIterator可以实现在迭代过程中的增删改查,还可以逆向遍历。(底层使用了List集合的角标)
//总结:在迭代过程中想要对列表List元素进行操作的时候,就要使用列表迭代器ListIterator.
for (ListIterator it = list.listIterator(); it.hasNext();) {
Object obj = it.next();
if(obj.equals("abc2")){
it.add("haha");
}
}
System.out.println(list);//[abc1, abc2, haha, abc3, abc4]
}
}接下来先讨论List接口的第一个重要子类:java.util.ArrayList<E>类,我这里先抛开泛型不说,本篇后面有专门阐述。但要注意,由于还没有使用泛型,利用Iterator的next()方法取出的元素必须向下转型,才可使用子类特有方法。针对ArrayList类,我们最需要注意的是,ArrayList的contains方法底层使用的equals方法判别的,所以自定义元素类型中必须复写Object的equals方法。
针对这个问题,我们来讲几个小练习。
练习1: 往ArrayList中存储自定义对象。Person(name, age)
思路:
1.描述Person。
2.定义容器对象。
3.将多个Person对象,存储到集合中。
4.取出Person对象。-->注意自定义对象复写toString方法,直接打印p才有意义。
package ustc.lichunchun.list.test;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import ustc.lichunchun.domian.Person;
public class ArrayListTest {
public static void main(String[] args) {
//1.创建ArrayList集合对象。
List list = new ArrayList();
//2.添加Person类型的对象。
Person p1 = new Person("lisi1", 21);
Person p2 = new Person("lisi2", 22);
list.add(p1);//add(Object obj)
list.add(p2);
list.add(new Person("lisi3", 23));
//3.取出元素。
for (Iterator it = list.iterator(); it.hasNext();) {
//it.next():取出的元素都是Object类型的。需要用到具体对象内容时,需要向下转型。
Person p = (Person)it.next();
System.out.println(p.getName()+":"+p.getAge());//如果不向下转型,Object类对象没有getName、getAge方法。
}
}
} 思路:
1.最后唯一性的元素也很多,可以先定义一个容器用于存储这些唯一性的元素。
2.对原有容器进行元素的获取,并到临时容器中去判断是否存在。容器本身就有这功能,判断元素是否存在。
-->contains()底层原理就是使用的equals(),而且这里用的是String类复写的的equals。
3.存在就不存储,不存在就存储。
4.遍历完原容器后,临时容器中存储的就是唯一性的元素。
package ustc.lichunchun.list.test;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.ListIterator;
public class ArrayListTest2 {
public static void main(String[] args) {
/*
* 练习2:定义功能,去除ArrayList集合中的重复元素。
*/
List list = new ArrayList();
list.add("abc1");
list.add("abc4");
list.add("abc2");
list.add("abc1");
list.add("abc4");
list.add("abc4");
list.add("abc2");
list.add("abc1");
list.add("abc4");
list.add("abc2");
System.out.println(list);//[abc1, abc4, abc2, abc1, abc4, abc4, abc2, abc1, abc4, abc2]
singleElement2(list);
System.out.println(list);//[abc1, abc4, abc2]
}
/*
* 取出重复元素方式一。
* 定义功能,取出重复元素。因为List带有角标,比较容易进行for循环。
*/
public static void singleElement(List list){
for (int x = 0; x < list.size()-1; x++){
Object obj = list.get(x);
for(int y = x+1; y < list.size(); y++){
if (obj.equals(list.get(y))){
list.remove(y--);//记住:remove、add等方法,会改变原数组长度!注意角标变化。
}
}
}
}
/*
* 取出重复元素方式二。
* 思路:
* 1.最后唯一性的元素也很多,可以先定义一个容器用于存储这些唯一性的元素。
* 2.对原有容器进行元素的获取,并到临时容器中去判断是否存在。容器本身就有这功能,判断元素是否存在。
* 3.存在就不存储,不存在就存储。
* 4.遍历完原容器后,临时容器中存储的就是唯一性的元素。
*/
public static void singleElement2(List list){
//1.定义一个临时容器
List temp = new ArrayList();
//2.遍历原容器
for (Iterator it = list.iterator(); it.hasNext();) {
Object obj = (Object) it.next();
//3.在临时容器中判断遍历到的元素是否存在
if(!temp.contains(obj))//contains()底层原理就是使用的equals(),而且这里用的是String类复写的equals。
//如果不存在,就存储到临时容器中
temp.add(obj);
}
//将原容器清空
list.clear();
//将临时容器中的元素都存储到原容器中
list.addAll(temp);
}
}记住:往集合里面存储自定义元素,该元素所属类一定要覆盖equals、toString方法!
package ustc.lichunchun.domian;
public class Person{
private String name;
private int age;
public Person() {
super();
}
public Person(String name, int age) {
super();
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Person [name=" + name + ", age=" + age + "]";
}
/*
* 建立Person类自己的判断对象是否相同的依据,必须要覆盖Object类中的equals方法。
*/
public boolean equals(Object obj) {
//为了提高效率,如果比较的对象是同一个,直接返回true即可。
if(this == obj)
return true;
if(!(obj instanceof Person))
throw new ClassCastException("类型错误");
Person p = (Person)obj;
return this.name.equals(p.name) && this.age==p.age;
}
/*@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Person other = (Person) obj;
if (age != other.age)
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}*/
}contains()方法底层调用的是容器中元素对象的equals()方法!这里如果Person类自身不定义equals方法,就使用Object的equals方法,比较的就仅仅是地址了。
package ustc.lichunchun.list.test;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import ustc.lichunchun.domian.Person;
public class ArrayListTest3 {
public static void main(String[] args) {
/*
* 练习3:ArrayList取出重复的自定义元素。
*
* 记住:往集合里面存储自定义元素,该元素所属类一定要覆盖equals、toString方法!
*/
List list = new ArrayList();
Person p = new Person("li",19);
list.add(p);
list.add(p);//存储了一个地址相同的对象。在equals方法中直接先this==obj即可。
list.add(new Person("li",20));
list.add(new Person("li",23));
list.add(new Person("li",26));
list.add(new Person("li",23));
list.add(new Person("li",26));
list.add(new Person("li",20));
System.out.println(list);
singleElement(list);
System.out.println(list);
}
public static void singleElement(List list){
List temp = new ArrayList();
for (Iterator it = list.iterator(); it.hasNext();) {
Object obj = (Object) it.next();
if(!temp.contains(obj))// --> contains()方法底层调用的是容器中元素对象的equals()方法!
//这里如果Person类自身不定义equals方法,就使用Object的equals方法,比较的就仅仅是地址了。
temp.add(obj);
}
list.clear();
list.addAll(temp);
}
}java.util.LinkedList<E>类是List接口的链表实现,可以利用LinkedList实现堆栈、队列结构。它的特有方法有如下这些:
addFirst();
addLast();
在jdk1.6以后:
offerFirst();
offerLast();
getFirst():获取链表中的第一个元素。如果链表为空,抛出NoSuchElementException;
getLast();
在jdk1.6以后:
peekFirst();获取链表中的第一个元素。如果链表为空,返回null。
peekLast();
removeFirst():获取链表中的第一个元素,但是会删除链表中的第一个元素。如果链表为空,抛出NoSuchElementException
removeLast();
在jdk1.6以后:
pollFirst();获取链表中的第一个元素,但是会删除链表中的第一个元素。如果链表为空,返回null。
pollLast();
package ustc.lichunchun.list.linkedlist;
import java.util.LinkedList;
public class LinkedListDemo {
public static void main(String[] args) {
//1.创建一个链表对象。
LinkedList link = new LinkedList();
//演示xxxFirst()、xxxLast()方法。
//2.添加方法。
link.addFirst("abc1");
link.addFirst("abc2");
link.addFirst("abc3");
//3.获取元素。
System.out.println(link.getFirst());//abc3
System.out.println(link.getFirst());//abc3
//4.删除元素。
System.out.println(link.removeFirst());//abc3
System.out.println(link.removeFirst());//abc2
//5.取出link中所有元素。
while(!link.isEmpty())
System.out.println(link.removeLast());//removeFirst()
link.contains("abc3");//false
}
}堆栈:先进后出。First In Last Out FILO。
队列:先进先出。First In First Out FIFO。
队列结构代码如下:
package ustc.lichunchun.list.linkedlist;
import java.util.LinkedList;
/*
* 描述一个队列数据结构。内部使用的是LinkedList。
*/
public class MyQueue {
private LinkedList link;
MyQueue() {
link = new LinkedList();
}
/**
* 添加元素的方法。
*/
public void myAdd(Object obj) {
// 内部使用的是LinkedList的方法。
link.addFirst(obj);
}
/**
* 获取队列元素的方法。
*/
public Object myGet() {
return link.removeLast();
}
/**
* 集合中是否有元素的方法。
*/
public boolean isNull() {
return link.isEmpty();
}
}堆栈结构代码如下:
package ustc.lichunchun.list.linkedlist;
import java.util.LinkedList;
/*
* 实现一个堆栈结构。内部使用的是LinkedList。
*/
public class MyStack {
private LinkedList link;
MyStack() {
link = new LinkedList();
}
public void myAdd(Object obj) {
link.addFirst(obj);
}
public Object myGet() {
return link.removeFirst();
}
public boolean isNull() {
return link.isEmpty();
}
}测试:
package ustc.lichunchun.list.linkedlist;
import java.util.LinkedList;
public class LinkedListTest {
public static void main(String[] args) {
/*
* 练习:请通过LInkedList实现一个堆栈,或者队列数据结构。
* 堆栈:先进后出。First In Last Out FILO.
* 队列:先进先出。First In First Out FIFO.
*/
//1.创建自定义的队列对象。
MyQueue queue = new MyQueue();
//2.添加元素。
queue.myAdd("abc1");
queue.myAdd("abc2");
queue.myAdd("abc3");
queue.myAdd("abc4");
//3.获取所有元素。先进先出。
while(!queue.isNull())
System.out.println(queue.myGet());
System.out.println("--------------------------");
//1.创建自定义的堆栈对象。
MyStack stack = new MyStack();
//2.添加元素。
stack.myAdd("def5");
stack.myAdd("def6");
stack.myAdd("def7");
stack.myAdd("def8");
//3.获取所有元素。先进后出。
while(!stack.isNull())
System.out.println(stack.myGet());
}
}练习1:带猜数字游戏的用户登录注册案例--集合版。
需求分析:
需求:用户登录注册案例。
按照如下的操作,可以让我们更符号面向对象思想
A:有哪些类呢?
B:每个类有哪些东西呢?
C:类与类之间的关系是什么呢?
分析:
A:有哪些类呢?
用户类
测试类
B:每个类有哪些东西呢?
用户类:
成员变量:用户名,密码
构造方法:无参构造
成员方法:getXxx()/setXxx()
登录,注册
假如用户类的内容比较对,将来维护起来就比较麻烦,为了更清晰的分类,我们就把用户又划分成了两类
用户基本描述类
成员变量:用户名,密码
构造方法:无参构造
成员方法:getXxx()/setXxx()
用户操作类
登录,注册
测试类:
main方法。
C:类与类之间的关系是什么呢?
在测试类中创建用户操作类和用户基本描述类的对象,并使用其功能。
分包:
A:功能划分
B:模块划分
C:先按模块划分,再按功能划分
今天我们选择按照功能划分:
用户基本描述类包 ustc.lichunchun.pojo
用户操作接口 ustc.lichunchun.dao
用户操作类包 ustc.lichunchun.dao.impl
本文中是集合实现,后续会有IO实现、GUI实现和数据库实现。
用户测试类 ustc.lichunchun.test
package ustc.lichunchun.pojo;
/**
* 这是用户基本描述类
*
* @author 李春春
* @version V1.0
*
*/
public class User {
// 用户名
private String username;
// 密码
private String password;
public User() {
super();
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
}package ustc.lichunchun.dao;
import ustc.lichunchun.pojo.User;
/**
* 这时针对用户进行操作的接口
*
* @author 李春春
* @version V1.0
*
*/
public interface UserDao {
/**
* 这是用户登录功能
*
* @param username
* 用户名
* @param password
* 密码
* @return 返回登陆是否成功
*/
public abstract boolean isLogin(String username, String password);
/**
* 这是用户注册功能
*
* @param user
* 要注册的用户信息
*/
public abstract void regist(User user);
}package ustc.lichunchun.dao.impl;
import java.util.ArrayList;
import ustc.lichunchun.dao.UserDao;
import ustc.lichunchun.pojo.User;
/**
* 这是用户操作的具体实现类(集合版)
*
* @author 李春春
* @version V1.0
*
*/
public class UserDaoImpl implements UserDao {
//为了让多个方法能够使用同一个集合,就把集合定义为成员变量。
//为了不让外人看到,用private
//为了让多个对象共享同一个成员变量,用static
private static ArrayList<User> array = new ArrayList<User>();
@Override
public boolean isLogin(String username, String password) {
//遍历集合,获取每一个用户,并判断用户的用户名和密码是否和传递过来的匹配
boolean flag = false;
for(User u : array){
if(u.getUsername().equalsIgnoreCase(username) && u.getPassword().equalsIgnoreCase(password)){
flag = true;
break;
}
}
return flag;
}
@Override
public void regist(User user) {
//把用户信息存入集合
array.add(user);
}
}package ustc.lichunchun.test;
import java.util.Scanner;
import ustc.lichunchun.dao.UserDao;
import ustc.lichunchun.dao.impl.UserDaoImpl;
import ustc.lichunchun.game.GuessNumber;
import ustc.lichunchun.pojo.User;
/**
* 用户测试类
*
* @author 李春春
* @version V1.0
*
* 新增加了两个小问题:
* A.多个对象共享同一个成员变量,用静态
* B.循环里面如果有switch,并且在switch里面有break,那么结束的不是循环,而是switch语句
*
*/
public class UserTest {
public static void main(String[] args) {
//为了能够回来
while (true) {
// 欢迎界面,给出选择项
System.out.println("--------------欢迎光临--------------");
System.out.println("1 登陆");
System.out.println("2 注册");
System.out.println("3 退出");
System.out.println("请输入你的选择:");
//键盘录入选择,根据选择做不同的操作
Scanner sc = new Scanner(System.in);
//为了后面的录入信息的方便,所有的数据录入全部用字符串接收
String choiceString = sc.nextLine();
//switch语句的多个地方要使用,我就定义到外面
UserDao ud = new UserDaoImpl();//多态
//经过简单的思考,我选择了switch
switch (choiceString) {
case "1":
//登陆界面,请输入用户名和密码
System.out.println("--------------登录界面--------------");
System.out.println("请输入用户名:");
String username = sc.nextLine();
System.out.println("请输入密码:");
String password = sc.nextLine();
//调用登录功能
boolean flag = ud.isLogin(username, password);
if (flag) {
System.out.println("登陆成功,可以开始玩游戏了");
System.out.println("你玩么?y/n");
while(true){
String resultString = sc.nextLine();
if(resultString.equalsIgnoreCase("y")){
GuessNumber.start();
System.out.println("你还玩么?y/n");
}else{
break;
}
}
System.out.println("谢谢使用,欢迎下次再来");
System.exit(0);
//break;这里写break,结束的是switch
} else {
System.out.println("用户名或者密码有误,登录失败");
}
break;
case "2":
//注册界面,请输入用户名和密码
System.out.println("--------------注册界面--------------");
System.out.println("请输入用户名:");
String newUserName = sc.nextLine();
System.out.println("请输入密码:");
String newPassword = sc.nextLine();
//把用户名和密码封装到一个对象中
User user = new User();
user.setUsername(newUserName);
user.setPassword(newPassword);
//调用注册功能
ud.regist(user);
System.out.println("注册成功");
break;
case "3":
default:
System.out.println("谢谢使用,欢迎下次再来");
System.exit(0);
}
}
}
}
package ustc.lichunchun.game;
import java.util.Scanner;
/**
* 这是猜数字小游戏
*
* @author 李春春
*
*/
public class GuessNumber {
private GuessNumber() {
}
public static void start() {
int num = (int) (Math.random() * 100) + 1;
int count = 0;
while (true) {
System.out.println("请输入数据(1-100):");
Scanner sc = new Scanner(System.in);
int guessNum = sc.nextInt();
count++;
if (guessNum > num) {
System.out.println("你猜的数据" + guessNum + "大了");
} else if (guessNum < num) {
System.out.println("你猜的数据" + guessNum + "小了");
} else {
System.out.println("恭喜你," + count + "次就猜中了");
break;
}
}
}
}
这个练习的程序代码较长,我上传到资源里,有兴趣的读者可以下载下来瞅一眼。
详见:http://download.csdn.net/detail/zhongkelee/8981865
程序运行截图:

Set<E>接口
java.util.Set<E>接口,一个不包含重复元素的 collection。更确切地讲,set 不包含满足e1.equals(e2) 的元素对e1 和e2,并且最多包含一个 null 元素。
Set:不允许重复元素。和Collection的方法相同。Set集合取出方法只有一个:迭代器。
|--HashSet:底层数据结构是哈希表(散列表)。无序,比数组查询的效率高。线程不同步的。
-->根据哈希冲突的特点,为了保证哈希表中元素的唯一性,
该容器中存储元素所属类应该复写Object类的hashCode、equals方法。
|--LinkedhashSet:有序,HashSet的子类。
|--TreeSet:底层数据结构是二叉树。可以对Set集合的元素按照指定规则进行排序。线程不同步的。
-->add方法新添加元素必须可以同容器已有元素进行比较,
所以元素所属类应该实现Comparable接口的compareTo方法,以完成排序。
或者添加Comparator比较器,实现compare方法。
代码示例:
package ustc.lichunchun.set.demo;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
public class HashSetDemo {
public static void main(String[] args) {
//1.创建一个Set容器对象。
Set set = new HashSet();
//Set set = new LinkedHashSet();如果改成LinkedHashSet,可以实现有序。
//2.添加元素。
set.add("haha");
set.add("nba");
set.add("abc");
set.add("nba");
set.add("heihei");
//3.只能用迭代器取出。
for (Iterator it = set.iterator(); it.hasNext();) {
System.out.println(it.next());
}
}
}java.util.HashSet<E>类实现Set 接口,由哈希表(实际上是一个HashMap 实例)支持。它不保证 set 的迭代顺序;特别是它不保证该顺序恒久不变。此类允许使用null 元素。
堆内存的底层实现就是一种哈希表结构,需要通过哈希算法来计算对象在该结构中存储的地址。这个方法每个对象都具备,叫做hashCode()方法,隶属于java.lang.Objecct类。hashCode本身调用的是wondows系统本地的算法,也可以自己定义。
哈希表的原理:
1.对对象元素中的关键字(对象中的特有数据),进行哈希算法的运算,并得出一个具体的算法值,这个值称为哈希值。
2.哈希值就是这个元素的位置。
3.如果哈希值出现冲突,再次判断这个关键字对应的对象是否相同。
如果对象相同,就不存储,因为元素重复。如果对象不同,就存储,在原来对象的哈希值基础 +1顺延。
4.存储哈希值的结构,我们称为哈希表。
5.既然哈希表是根据哈希值存储的,为了提高效率,最好保证对象的关键字是唯一的。
这样可以尽量少的判断关键字对应的对象是否相同,提高了哈希表的操作效率。
哈希表的特点:
1.不允许存储重复元素,因为会发生查找的不确定性。
2.不保证存入和取出的顺序一致,即不保证有序。
3.比数组查询的效率高。
哈希冲突:
当哈希算法算出的两个元素的值相同时,称为哈希冲突。冲突后,需要对元素进行进一步的判断。判断的是元素的内容,equals。如果不同,还要继续计算新的位置,比如地址链接法,相当于挂一个链表扩展下来。
如何保证哈希表中元素的唯一性?
元素必须覆盖hashCode和equals方法。
覆盖hashCode方法是为了根据元素自身的特点确定哈希值。
覆盖equals方法,是为了解决哈希值的冲突。
如何实现有序?
LinkedHashSet类,可以实现有序。
废话不所说,下面我来举一个例子演示。
练习:往HashSet中存储学生对象(姓名,年龄)。同姓名、同年龄视为同一个人,不存。
思路:
1.描述学生。
2.定义容器。
3.将学生对象存储到容器中。
package ustc.lichunchun.domian;
public class Student {
private String name;
private int age;
public Student() {
super();
}
public Student(String name, int age) {
super();
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student [name=" + name + ", age=" + age + "]";
}
/*
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Student other = (Student) obj;
if (age != other.age)
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
*/
//覆盖hashCode方法。根据对象自身的特点定义哈希值。
public int hashCode(){
final int NUMBER = 31;
return name.hashCode()+ age*NUMBER;
}
//需要定义对象自身判断内容相同的依据。覆盖equals方法。
public boolean equals(Object obj){
if (this == obj)
return true;
if(!(obj instanceof Student))
throw new ClassCastException(obj.getClass().getName()+"类型错误");
Student stu = (Student)obj;
return this.name.equals(stu.name) && this.age == stu.age;
}
}package ustc.lichunchun.set.demo;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
import ustc.lichunchun.domian.Student;
public class HashSetTest {
public static void main(String[] args) {
/*
* 练习:往HashSet中存储学生对象(姓名,年龄)。同姓名、同年龄视为同一个人,不存。
* 1.描述学生。
* 2.定义容器。
* 3.将学生对象存储到容器中。
*
* 发现存储了同姓名、同年龄的学生是可以的。
* 原因是每一次存储学生对象,都先调用hashCode()方法获取哈希值。
* 但此时调用的是Object类中的hashCode。所以同姓名同年龄了,但因为是不同的对象,哈希值也不同。
* 这就是同姓名同年龄存入的原因。
*
* 解决:
* 需要根据学生对象自身的特点来定义哈希值。
* 所以就需要覆盖hashCode方法。
*
* 发现,当hashCode返回值相同时,会调用equals方法比较两个对象是否相等。
* 还是会出现同姓名同年龄的对象,因为子类没有复写equals方法,
* 直接用Object类的equals方法仅仅比较了两个对象的地址值。
* 这就是同姓名同年龄还会存入的原因。
*
* 解决:
* 需要定义对象自身判断内容相同的依据。
* 所以就需要覆盖equals方法。
*
* 效率问题:
* 尽量减少哈希算法求得的哈希值的冲突。减少equals方法的调用。
*/
//1.创建容器对象。
Set set = new HashSet();
//2.存储学生对象。
set.add(new Student("xiaoqiang",20));
set.add(new Student("wangcai",27));
set.add(new Student("xiaoming",22));
set.add(new Student("xiaoqiang",20));
set.add(new Student("daniu",24));
set.add(new Student("xiaoming",22));
//3.获取所有学生。
for (Iterator it = set.iterator(); it.hasNext();) {
Student stu = (Student) it.next();
System.out.println(stu.getName()+":"+stu.getAge());
}
}
}HashSet判断元素是否相同:依据的是hashCode和equals方法。如果哈希冲突(哈希值相同),再判断元素的equals方法。如果equals方法返回true,不存;返回false,存储!
TreeSet<E>类
java.util.Set<E>类基于TreeMap的NavigableSet实现。使用元素的自然顺序(Comparable的compareTo方法)对元素进行排序,或者根据创建 set 时提供的自定义比较器(Comparator的compare方法)进行排序,具体取决于使用的构造方法。此实现为基本操作(add、remove和contains)提供受保证的 log(n) 时间开销。
TreeSet:可以对元素排序。
有序:存入和取出的顺序一致。--> List
排序:升序or降序。--> TreeSet
代码示例:
package ustc.lichunchun.set.demo;
import java.util.Iterator;
import java.util.Set;
import java.util.TreeSet;
import ustc.lichunchun.domian.Student;
public class TreeSetDemo {
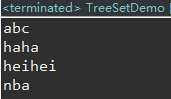
public static void main(String[] args) {
Set set = new TreeSet();
set.add("abc");
set.add("heihei");
set.add("nba");
set.add("haha");
set.add("heihei");
for (Iterator it = set.iterator(); it.hasNext();) {
System.out.println(it.next());
}
}
}
那如果往TreeSet集合中存入的是自定义元素呢?
TreeSet排序方式:
需要元素自身具备比较功能。所以元素需要实现Comparable接口。覆盖compareTo方法。如果元素不具备比较性,在运行时会发生ClassCastException异常。
TreeSet能够进行排序。但是自定义的Person类并没有给出排序的规则。即普通的自定义类不具备排序的功能,所以要实现Comparable接口,强制让元素具备比较性,复写compareTo方法。
如何保证元素唯一性?
参考的就是比较方法(比如compareTo)的返回值是否是0。是0,就是重复元素,不存。
注意:在进行比较时,如果判断元素不唯一,比如,同姓名同年龄,才视为同一个人。
在判断时,需要分主要条件和次要条件,当主要条件相同时,再判断次要条件,按照次要条件排序。
示例:往TreeSet集合存入上一节所描述的学生类对象。要求按照年龄进行排序。
package ustc.lichunchun.domian;
/*
* 学生类本身继承自Object类,具备一些方法。
* 我们想要学生类具备比较的方法,就应该在学生类的基础上进行功能的扩展。
* 比较的功能已经在Comparable接口中定义下来了,学生类只需要实现Comparable接口即可。
* 记住:需要对象具备比较性,只要让对象实现comparable接口即可。
*/
public class Student implements Comparable{
private String name;
private int age;
public Student() {
super();
}
public Student(String name, int age) {
super();
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student [name=" + name + ", age=" + age + "]";
}
/*
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Student other = (Student) obj;
if (age != other.age)
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
*/
//覆盖hashCode方法。根据对象自身的特点定义哈希值。
public int hashCode(){
final int NUMBER = 31;
return name.hashCode()+ age*NUMBER;
}
//需要定义对象自身判断内容相同的依据。覆盖equals方法。
public boolean equals(Object obj){
if (this == obj)
return true;
if(!(obj instanceof Student))
throw new ClassCastException(obj.getClass().getName()+"类型错误");
Student stu = (Student)obj;
return this.name.equals(stu.name) && this.age == stu.age;
}
//实现了comparable接口,学生就具备了比较功能。该功能是自然排序使用的方法。
//自然排序就以年龄的升序排序为主。
//既然是同姓名同年龄是同一个人,视为重复元素,要判断的要素就有两个。
//既然是按照年龄进行排序。所以先判断年龄,再判断姓名。
@Override
public int compareTo(Object o) {
Student stu = (Student)o;
System.out.println(this.name+":"+this.age+"......"+stu.name+":"+stu.age);
if(this.age > stu.age)
return 1;
if(this.age < stu.age)
return -1;
//return 0;//0表示重复元素,不存。
return this.name.compareTo(stu.name);//进一步细化条件,只有姓名、年龄都一样,才是重复元素。
/*
主要条件:
return this.age - stu.age;
*/
/*
主要条件+次要条件:
int temp = this.age - stu.age;
return temp==0?this.name.compareTo(stu.age):temp;
*/
}
}package ustc.lichunchun.set.demo;
import java.util.Iterator;
import java.util.Set;
import java.util.TreeSet;
import ustc.lichunchun.domian.Student;
public class TreeSetDemo {
public static void main(String[] args) {
Set set = new TreeSet();
set.add(new Student("xiaoqiang",20));//java.lang.ClassCastException 类型转换异常
//问题:因为学生要排序,就需要比较,而没有定义比较方法,无法完成排序。
//解决:add方法中实现比较功能,使用的是Comparable接口的比较方法。
//comparable接口抽取并定义规则,强行对实现它的每个类的对象进行整体排序,实现我的类就得实现我的compareTo方法,否则不能创建对象。
set.add(new Student("daniu",24));
set.add(new Student("xiaoming",22));
set.add(new Student("huanhuan",22));//根据复写的compareTo方法,huanhuan和xiaoming两个对象属于重复元素(进一步细化条件之前,compareTo返回值为0即视为重复),又TreeSet容器不存重复元素,所以huanhuan没有存进去。
set.add(new Student("tudou",18));
set.add(new Student("dahuang",19));
/*set.add(new Student("lisi02", 22));
set.add(new Student("lisi007", 20));
set.add(new Student("lisi09", 19));
set.add(new Student("lisi08", 19));
set.add(new Student("lisi11", 40));
set.add(new Student("lisi16", 30));
set.add(new Student("lisi12", 36));
set.add(new Student("lisi10", 29));
set.add(new Student("lisi22", 90));
*/
for (Iterator it = set.iterator(); it.hasNext();) {
Student stu = (Student)it.next();
System.out.println(stu.getName()+":"+stu.getAge());
}
}
}保证二叉树只return一边,比如:
public int compareTo(Object o){
if (this.age == o.age)
return 0;//保证TreeSet不存入自定义的重复元素。
return 1;//保证添加的元素都存入二叉树的右子树。
} TreeSet二叉树建立过程:
TreeSet底层是二叉树结构,二叉树结构特点是可以排序。并且对二叉树的建立过程内部优化,以减少比较次数。例子中将已排序的xiaoming:22作为根节点,是基于折半的排序思想。xiaoqiang:20、xiaoming:22、daniu:24已经按照顺序存好,为了提高效率,在已排序的数组中去找一个新元素存放的位置,折半的方法最快。所以第四个进来的元素huanhuan:22会先和中间的xiaoming:22比较,然后确定往大的方向还是小的方向走。按照改进前的规则,huanhuan:22和xiaoming:22属重复元素,不存。tudou:18进来,再和已排序的中间元素xiaoming:22比较。比xiaoming:22小,往小的方向走,接着和xiaoqiang:20比较,比它小,tudou:18放在xiaoqiang:20左子树位置上。此时,已排序的依次为:tudou:18、xiaoqiang:20、xiaoming:22、daniu:24。中间元素为xiaoming:22。
dahuang:19先和xiaoming:22比,比它小;再和xiaoqiang:20比,比它小;接着和tudou:18比,比它大,放在tudou:18的右子树上。
建树完毕,TreeSet容器存入元素完毕。
取出元素过程:
根节点的左子树<右子树,所以先遍历左子树,再根节点,最后右子树即可。
所以上述往TreeSet集合存入Student类元素的建树、取元素过程的输出结果为:
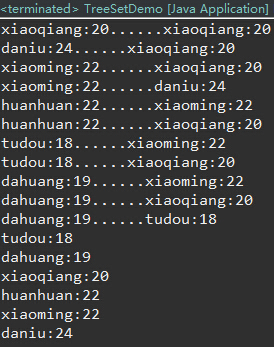
TreeSet第一种排序方式:需要元素具备比较功能。所以元素需要实现Comparable接口。覆盖compareTo方法。
需求中也有这样一种情况,元素具备的比较功能不是所需要的,也就是说不想按照自然排序的方式,而是按照自定义的排序方式,对元素进行排序。而且,存储到TreeSet中的元素万一没有比较功能,该如何排序呢?
这时,就只能使用第二种排序方式--是让集合具备比较功能,定义一个比较器。联想到集合的构造函数,去查API。
TreeSet第二种排序方式:需要集合具备比较功能,定义一个比较器。所以要实现java.util.Comparator<T>接口,覆盖compare方法。将Comparator接口的对象,作为参数传递给TreeSet集合的构造函数。
示例:自定义一个比较器,用来对学生对象按照姓名进行排序。
实现Comparator自定义比较器的代码如下:
package ustc.lichunchun.comparator;
import java.util.Comparator;
import ustc.lichunchun.domian.Student;
/**
* 自定义一个比较器,用来对学生对象按照姓名进行排序。
*
* @author lichunchun
*/
public class ComparatorByName extends Object implements Comparator {
@Override
public int compare(Object o1, Object o2) {
Student s1 = (Student) o1;
Student s2 = (Student) o2;
int temp = s1.getName().compareTo(s2.getName());
return temp == 0 ? s1.getAge() - s2.getAge() : temp;
}
//ComparatorByName类通过继承Object类,已经复写了Comparator接口的equals方法。
//这里的equals方法是用来判断多个比较器是否相同。
//如果程序中有多个比较器,这时实现Comparator的类就应该自己复写equals方法,来判断几个比较器之间是否相同。
}package ustc.lichunchun.set.demo;
import java.util.Iterator;
import java.util.Set;
import java.util.TreeSet;
import ustc.lichunchun.comparator.ComparatorByName;
import ustc.lichunchun.domian.Student;
public class TreeSetDemo2 {
public static void main(String[] args) {
//初始化TreeSet集合明确一个比较器。
Set set = new TreeSet(new ComparatorByName());
set.add(new Student("xiaoqiang",20));
set.add(new Student("daniu",24));
set.add(new Student("xiaoming",22));
set.add(new Student("tudou",18));
set.add(new Student("daming",19));
set.add(new Student("dahuang",19));
for (Iterator it = set.iterator(); it.hasNext();) {
Student stu = (Student)it.next();
System.out.println(stu.getName()+":"+stu.getAge());
}
}
}1.让元素自身具备比较性,需要元素对象实现Comparable接口,覆盖compareTo方法。
2.让集合自身具备比较性,需要定义一个实现了Comparator接口的比较器,并覆盖compare方法,并将该类对象作为实际参数传递给TreeSet集合的构造函数。
3.容器使用Comparator比较器接口对元素进行排序,只要实现比较器对象就可以。
-->降低了比较方式和集合之间的耦合性-->自定义比较器的方式更为灵活。
元素自身可以具备比较功能
-->自然排序通常都作为元素的默认排序。
4.Comparable接口的compareTo方法,一个参数;Comparator接口的compare方法,两个参数。
List是数组或者链表结构,允许重复元素。
HashSet是哈希表结构,查询速度快。
TreeSet是二叉树数据结构。二叉树结构可以实现排序,一堆数据只要存入二叉树,自动完成排序。
如果你坚持看完了本博文上面这部分内容,可以尝试自己动手做下面这6个小练习:
package ustc.lichunchun.test;
import java.util.Comparator;
import java.util.Set;
import java.util.TreeSet;
import ustc.lichunchun.comparator.ComparatorByLength;
/*
* 练习1:将Person对象存储到HashSet集合中,同姓名同年龄视为同一个人,不存。(复写Person类的hashCode、equals方法)
*
* 练习2:将Person对象存储到TreeSet集合中,同姓名同年龄视为同一个人,不存,姓名升序排序为自然排序。(实现Comparable接口,复写compareTo方法,姓名为主要条件、年龄为次要条件)
*
* 练习3:基于练习2,实现Person对象按照年龄升序排序。(实现Comparable接口,复写compareTo方法,年龄为主要条件)
*
* 练习4:对多个字符串(不重复)按照长度排序(由短到长)。(字符串中已复写Comparable接口,但是是按照字典顺序排序,无法使用。这里应该实现Comparator比较器,复写compare方法,创建对象实例传参给TreeSet构造函数)
*
* 练习5:对多个字符串(重复),按照长度排序。(不可以使用Set。数组、List都可以解决这个问题)
*
* 练习6:通过LinkedList,定义一个堆栈数据结构。(利用addFirst、removeLast实现队列,addFirst、removeFirst实现堆栈)
*/
public class Test1 {
public static void main(String[] args) {
/*
HashSet set = new HashSet();
TreeSet set = new TreeSet();
set.add(new Person("lisi",18));
set.add(new Person("wanger",18));
set.add(new Person("zengcen",10));
set.add(new Person("huanhuan",22));
set.add(new Person("wanger",18));
set.add(new Person("hehe",24));
for (Iterator it = set.iterator(); it.hasNext();) {
System.out.println(it.next());
}
*/
sortStringByLength2();
}
/*
* 练习4:对多个字符串(不重复)按照长度排序(由短到长)。
* 思路:
* 1.多个字符串,需要容器存储。
* 2.选择哪个容器?字符串是对象,可以选择集合,而且不重复,选择set集合。
* 3.还需要排序,可以选择TreeSet集合。
*/
public static void sortStringByLength(){
//Set set = new TreeSet();//自然排序的方式。
Set set = new TreeSet(new ComparatorByLength());//按照字符串长度排序。
set.add("haha");
set.add("abc");
set.add("zz");
set.add("nba");
set.add("xixixi");
for (Object obj : set) {
System.out.println(obj);
}
}
/*
* 练习5:对多个字符串(重复),按照长度排序。
* 1.能使用TreeSet吗?不能。
* 2.可以存储到数组、List。这里先选择数组。后面会讲解List。
*/
public static void sortStringByLength2(){
String[] strs = {"nba","haha","abccc","zero","xixi","nba","abccc","cctv","zero"};
//自然排序可以使用String类中的compareTo方法。
//但是现在要的是长度排序,这就需要比较器。
//定义一个按照长度排序的比较器对象。
Comparator comp = new ComparatorByLength();
//排序就需要嵌套循环。位置置换。
for(int x = 0; x < strs.length-1; x++){
for(int y = x+1; y < strs.length; y++){
//if(strs[x].compareTo(strs[y] > 0)){//按照字典顺序
if(comp.compare(strs[x], strs[y]) > 0)//按照长度顺序
swap(strs,x,y);
}
}
for(String s : strs){
System.out.println(s);
}
}
public static void swap(String[] strs, int x, int y){
String temp = strs[x];
strs[x] = strs[y];
strs[y] = temp;
}
}
package ustc.lichunchun.domian;
public class Person implements Comparable{
private String name;
private int age;
public Person() {
super();
}
public Person(String name, int age) {
super();
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Person [name=" + name + ", age=" + age + "]";
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
/*
* 建立Person类自己的判断对象是否相同的依据,必须要覆盖Object类中的equals方法。
*/
public boolean equals(Object obj) {
//为了提高效率,如果比较的对象是同一个,直接返回true即可。
if(this == obj)
return true;
if(!(obj instanceof Person))
throw new ClassCastException("类型错误");
Person p = (Person)obj;
return this.name.equals(p.name) && this.age==p.age;
}
/*@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Person other = (Person) obj;
if (age != other.age)
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}*/
/*@Override//按照姓名升序为自然排序
public int compareTo(Object o) {
Person p = (Person)o;
int temp = this.getName().compareTo(p.getName());
return temp==0?this.getAge()-p.getAge():temp;
}*/
@Override//按照年龄升序为自然排序
public int compareTo(Object o) {
Person p = (Person)o;
int temp = this.getAge()-p.getAge();
return temp==0?this.getName().compareTo(p.getName()):temp;
}
}
package ustc.lichunchun.comparator;
import java.util.Comparator;
public class ComparatorByLength implements Comparator {
@Override
public int compare(Object o1, Object o2) {
// 对字符串按照长度比较。
// 向下转型
String s1 = (String) o1;
String s2 = (String) o2;
// 比较长度
int temp = s1.length() - s2.length();
// 长度相同,再按字典序比较
return temp == 0 ? s1.compareTo(s2) : temp;
}
}
/*
在二叉树(TreeSet)结构中,该比较器的compare方法返回0,代表相同的重复元素,就不存了。
在数组结构实现按长度排序中,该比较器的compare方法返回0,代表相同的重复元素,但只是不交换位置而已。
*/使用Collection集合的技巧
jdk1.2以后出现的集合框架中的常用子类对象,存在的规律。
需要唯一吗?
需要:Set
需要制定顺序:
需要:TreeSet
不需要:HashSet
但是想要一个和存储一致的顺序(有序):LinkedHashSet
不需要:List
需要频繁增删吗?
需要:LinkedList
不需要:ArrayList
如何记录每一个容器的结构和所属体系呢?看名字!
List
|--ArrayList
|--LinkedList
Set
|--HashSet
|--TreeSet
前缀名是数据结构名,后缀名是所属体系名。
ArrayList:数组结构。看到数组,就知道查询快,看到List,就知道可以重复。可以增删改查。
LinkedList:链表结构,增删快。xxxFirst、xxxLast方法,xxx:add、get、remove
HashSet:哈希表,查询速度更快,就要想到唯一性、元素必须覆盖hashCode、equals。不保证有序。看到Set,就知道不可以重复。
LinkedHashSet:链表+哈希表。可以实现有序,因为有链表。但保证元素唯一性。
TreeSet:二叉树,可以排序。就要想到两种比较方式(两个接口):一种是自然排序Comparable,一种是比较器Comparator。
而且通常这些常用的集合容器都是不同步的。
Foreach循环语句(for/in语句)
JDK1.5特性:增强for循环。
作用:用于遍历Collection集合or数组。
格式:
for(元素类型 变量:Collection容器or数组)
{
}
传统for循环和增强for循环有什么区别呢?
增强for必须有被遍历的目标。该目标只能是Collection、数组。不可以是Map。
代码示例:
package ustc.lichunchun.foreach;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
public class ForeachDemo {
public static void main(String[] args) {
Collection coll = new ArrayList();
coll.add("abc1");
coll.add("abc2");
coll.add("abc3");
for (Object obj : coll) {
System.out.println(obj);
}
/*for (Iterator it = coll.iterator(); it.hasNext();) {
Object obj = it.next();
System.out.println(obj);
}*/
//对于数组的遍历,如果不操作其角标,可以使用增强for循环;如果要操作角标,使用传统的for。
int[] arr = {23,15,32,78};
for (int i : arr) {
System.out.println("i = "+i);
}
}
}引入原因:替换Iterator复杂写法,本质就是Iterator
foreach语句主要应用:
1、遍历数组
2、遍历Collection 集合对象
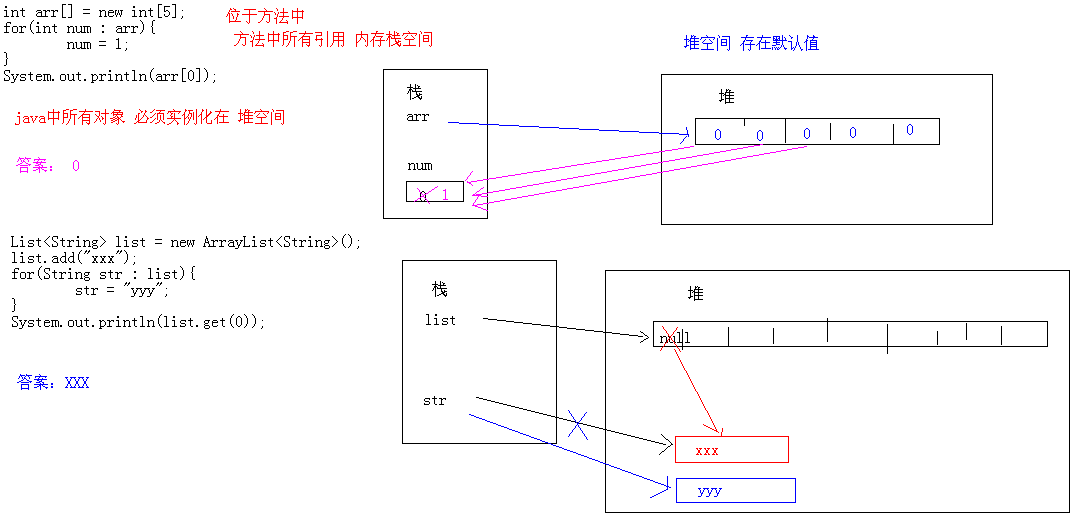
forin输出 结果内存分析,见下图:
代码示例:
package cn.itcast.jdk5;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.concurrent.CopyOnWriteArrayList;
import org.junit.Test;
/**
* for in 语句
*/
public class ForInTest {
@Test
public void demo1() {
List<String> list = new ArrayList<String>();
list.add("abc");
list.add("def");
list.add("qwe");
// JDK5之前 两种遍历方式 :通过下标遍历、通过Iterator
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
System.out.println("--------------------------------");
for (Iterator iterator2 = list.iterator(); iterator2.hasNext();) {
String string = (String) iterator2.next();
System.out.println(string);
}
System.out.println("--------------------------------");
// for in 简化 Iterator --- for in 就是 Iterator
for (String s : list) { // String s 表示 list中每一个字符串
System.out.println(s);
}
}
}
1、类 必须实现 Iterable 接口
2、类 实现 iterater 方法
* 编写Car 让 Car对象用于forin 语句
代码示例:
package cn.itcast.jdk5;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.concurrent.CopyOnWriteArrayList;
import org.junit.Test;
public class ForInTest {
@Test
public void demo3() {
// Car 用于 forin语句的
Car car = new Car();
for (String name : car) {
System.out.println(name);
}
// 原理
Iterator<String> iterator = car.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
}
}
// Car对象 可以用于 for in 语句
class Car implements Iterable<String> {
String[] names = { "保时捷", "宝马", "奥迪", "桑塔纳", "大众" };
@Override
public Iterator<String> iterator() {
// 自定义迭代器
return new MyIterator();
}
class MyIterator implements Iterator<String> {
int index = 0; // 当前遍历数组下标
@Override
public boolean hasNext() {
if (index >= names.length) { // 证明下标无法取得元素
return false;
}
return true;
}
@Override
public String next() {
String name = names[index];
index++;
return name;
}
@Override
public void remove() {
}
}
}移除练习
练习:”abc”,”bcd”,”asf”,”ceg”,”daf”,”dfs” 移除所有包含a 字符串
使用迭代器和for/in 进行list循环 ,删除元素时 : java.util.ConcurrentModificationException
1、解决方案:使用Iterator自带 remove方法
2、如果只删除一个元素,可以forin语句删除元素后,通过break跳出循环
3、使用解决这类异常线程安全集合 CopyOnWriteArrayList<E>
forin删除并发异常分析,见下图:

代码示例:
package cn.itcast.jdk5;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.concurrent.CopyOnWriteArrayList;
import org.junit.Test;
/**
* for in 语句
*
* @author seawind
*
*/
public class ForInTest {
@Test
public void demo6() {
// 使用线程安全集合对象 ,在forin循环中删除
List<String> list = new CopyOnWriteArrayList<String>();
list.add("abc");
list.add("asf");
list.add("bcd");
list.add("daf");
list.add("ceg");
list.add("dfs");
// 移除所有包含a 元素
for (String s : list) {
if (s.contains("a")) {
list.remove(s);
}
}
System.out.println(list);
}
@Test
public void demo5() {
// 如果在 for循环中只删除一个元素
List<String> list = new ArrayList<String>();
list.add("abc");
list.add("asf");
list.add("bcd");
list.add("daf");
list.add("ceg");
list.add("dfs");
// 删除 daf
for (String s : list) {
if (s.equals("daf")) {
list.remove(s);// 删除 ceg
break;
}
}
System.out.println(list);
}
@Test
public void demo4() {
// List 移除练习
// ”abc”,”bcd”,”asf”,”ceg”,”daf”,”dfs”
List<String> list = new ArrayList<String>();
list.add("abc");
list.add("asf");
list.add("bcd");
list.add("daf");
list.add("ceg");
list.add("dfs");
// 遍历集合移除所有包含字母”a” 的字符串
// 遍历List 三种写法: 通过下标、通过Iterator 、通过forin语句
// 通过下标
// for (int i = 0; i < list.size(); i++) {
// String s = list.get(i);
// if (s.contains("a")) {
// // 需要将s 从 list中移除
// list.remove(s);
// // 防止 元素被跳过
// i--;
// }
// }
// 通过for in
for (String s : list) {
if (s.contains("a")) {
// list.remove(s); // 产生并发异常
// 第一种解决方案 --- 使用迭代器自身删除
}
}
// 使用Iterator进行 List遍历
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()) {
String s = iterator.next();
if (s.contains("a")) {
iterator.remove();
}
}
System.out.println(list);
}
}Enumeration<E>接口
java.util.Enumeration:枚举。具备枚举取出方式的容器只有Vector。已被淘汰。举例如下:
package ustc.lichunchun.enumeration;
import java.util.Enumeration;
import java.util.Iterator;
import java.util.Vector;
public class EnumerationDemo {
public static void main(String[] args) {
/*
* Enumeration:枚举。
* 具备枚举取出方式的容器只有Vector。
*/
Vector v = new Vector();
v.add("abc1");
v.add("abc2");
v.add("abc3");
/*Enumeration en = v.elements();
while(en.hasMoreElements()){
System.out.println(en.nextElement());
}*/
//获取枚举。-->淘汰了
for(Enumeration en = v.elements(); en.hasMoreElements();){
System.out.println("enumeration: "+en.nextElement());
}
//获取迭代。-->好用。
for (Iterator it = v.iterator(); it.hasNext();) {
System.out.println("iterator: "+it.next());
}
//获取高级for。-->无角标,仅为遍历。
for (Object obj : v) {
System.out.println("foreach: "+obj);
}
}
}泛型
接下来,我要介绍JDK1.5以后出现的新技术,集合框架中的重点--泛型。
在JDK1.4版本之前,容器什么类型的对象都可以存储。但是在取出时,需要用到对象的特有内容时,需要做向下转型。但是对象的类型不一致,导致了向下转型发生了ClassCastException异常。为了避免这个问题,只能主观上控制,往集合中存储的对象类型保持一致。
JDK1.5以后,解决了该问题。在定义集合时,就直接明确集合中存储元素的具体类型。这样,编译器在编译时,就可以对集合中存储的对象类型进行检查。一旦发现类型不匹配,就编译失败。这个技术就是泛型技术。
package ustc.lichunchun.generic.demo;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class GenericDemo {
public static void main(String[] args) {
List list = new ArrayList();
list.add("abc");
list.add(4);//list.add(Integer.valueOf(4));自动装箱.
for (Iterator it = list.iterator(); it.hasNext();) {
System.out.println(it.next());
//等价于:
Object obj = it.next();
System.out.println(obj.toString());
//因为String和Integer类都复写了Object类的toString方法,所以可以这么做。
String str = (String)it.next();
System.out.println(str.length());
//->java.lang.ClassCastException:java.lang.Integer cannot be cast to java.lang.String
}
//为了在运行时期不出现类型异常,可以在定义容器时,就明确容器中的元素的类型。-->泛型
List<String> list = new ArrayList<String>();
list.add("abc");
for (Iterator<String> it = list.iterator(); it.hasNext();) {
String str = it.next();
//class文件中怎么保证it.next()返回的Object类型一定能够变成String类型?
//虽然class文件中,没有泛型标识。但是在编译时期就已经保证了元素类型的统一,一定都是某一类元素。
//那么在底层,就会有自动的相应类型转换。这叫做泛型的补偿。
System.out.println(str.length());
}
}
}编译器通过泛型对元素类型进行检查,只要检查通过,就会生成class文件,但在class文件中,就将泛型标识去掉了。
泛型只在源代码中体现。但是通过编译后的程序,保证了容器中元素类型的一致。
泛型的补偿:
在运行时,通过获取元素的类型进行转换操作。不用使用者再强制转换了。
泛型的好处:
1.将运行时期的问题,转移到了编译时期,可以更好的让程序员发现问题并解决问题。
2.避免了强制转换、向下转型的麻烦。
package ustc.lichunchun.generic.demo;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class GenericDemo2 {
public static void main(String[] args) {
//创建一个List集合,存储整数。List ArraytList
List<Integer> list = new ArrayList<Integer>();
list.add(5);//自动装箱
list.add(6);
for (Iterator<Integer> it = list.iterator(); it.hasNext();) {
Integer integer = it.next();//使用了泛型后,it.next()返回的就是指定的元素类型。
System.out.println(integer);
}
}
}例子一枚:
package ustc.lichunchun.domain;
public class Person implements Comparable<Person> {
private String name;
private int age;
public Person() {
super();
}
public Person(String name, int age) {
super();
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Person [name=" + name + ", age=" + age + "]";
}
@Override
public int compareTo(Person o) {
int temp = this.getAge() - o.getAge();
return temp == 0 ? this.getName().compareTo(o.getName()) : temp;
}
@Override
public int hashCode() {
final int NUMBER = 31;
return this.name.hashCode()+this.age*NUMBER;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if(!(obj instanceof Person))
throw new ClassCastException("类型不匹配");
Person p = (Person)obj;
return this.name.equals(p.name) && this.age == p.age;
}
}package ustc.lichunchun.generic.demo;
import java.util.HashSet;
import java.util.Set;
import java.util.TreeSet;
import ustc.lichunchun.comparator.ComparatorByName;
import ustc.lichunchun.domain.Person;
public class GenericDemo3 {
public static void main(String[] args) {
Set<String> set = new TreeSet<String>();
set.add("abcd");
set.add("aa");
set.add("nba");
set.add("cba");
for (String s : set) {
System.out.println(s);
}
//按照年龄排序
Set<Person> set = new TreeSet<Person>();
set.add(new Person("abcd",20));
set.add(new Person("aa",26));
set.add(new Person("nba",22));
set.add(new Person("cba",24));
for(Person p: set){
System.out.println(p);
}
//按照姓名排序
Set<Person> set = new TreeSet<Person>(new ComparatorByName());
set.add(new Person("abcd",20));
set.add(new Person("aa",26));
set.add(new Person("nba",22));
set.add(new Person("cba",24));
for(Person p: set){
System.out.println(p);
}
//HashSet不重复的实现
Set<Person> set = new HashSet<Person>();
set.add(new Person("aa",26));
set.add(new Person("abcd",20));
set.add(new Person("abcd",20));
set.add(new Person("nba",22));
set.add(new Person("nba",22));
set.add(new Person("cba",24));
for(Person p: set){
System.out.println(p);
}
}
} 泛型的表现:
泛型技术在集合框架中应用的范围很大。
什么时候需要写泛型呢?
当类中的操作的引用数据类型不确定的时候,以前用的Object来进行扩展的,现在可以用泛型来表示。这样可以避免强转的麻烦,而且将运行问题转移到的编译时期。
只要看到类或者接口在描述时右边定义<>,就需要泛型。其实是,容器在不明确操作元素的类型的情况下,对外提供了一个参数,用<>封装。使用容器时,只要将具体的类型实参传递给该参数即可。说白了,泛型就是,传递类型参数。
下面依次介绍泛型类、泛型方法、泛型接口。
1. 泛型类 --> 泛型定义在类上
首先,我们实现两个继承自Person类的子类,分别是Student类、Worker类,代码如下:
package ustc.lichunchun.domain;
public class Student extends Person {
public Student() {
super();
}
public Student(String name, int age) {
super(name, age);
}
@Override
public String toString() {
return "Student [name="+getName()+", age="+getAge()+"]";
}
}package ustc.lichunchun.domain;
public class Worker extends Person {
public Worker() {
super();
}
public Worker(String name, int age) {
super(name, age);
}
@Override
public String toString() {
return "Worker [name=" + getName() + ", age=" + getAge() + "]";
}
}class Tool1{
private Student stu;
public Student getStu() {
return stu;
}
public void setStu(Student stu) {
this.stu = stu;
}
}//JDk 1.4 类型向上抽取到Object-->向下转型在运行时期报ClassCastException。
class Tool2{
private Object obj;
public Object getObj() {
return obj;
}
public void setObj(Object obj) {
this.obj = obj;
}
}JDK1.5以后,新的解决方案:使用泛型。类型不确定时,可以对外提供参数。由使用者通过传递参数的形式完成类型的确定。
//JDK 1.5 在类定义时就明确参数。由使用该类的调用者,来传递具体的类型。
class Util<W>{//-->泛型类。
private W obj;
public W getObj() {
return obj;
}
public void setObj(W obj) {
this.obj = obj;
}
}利用泛型类,我们就可以直接在编译时期及时发现程序错误,同时避免了向下转型的麻烦。利用上述泛型类工具,示例代码如下:
package ustc.lichunchun.generic.demo;
import ustc.lichunchun.domain.Student;
import ustc.lichunchun.domain.Worker;
public class GenericDemo4 {
public static void main(String[] args) {
/*
* 泛型1:泛型类-->泛型定义在类上。
*/
//JDK 1.4
Tool2 tool = new Tool2();
tool.setObj(new Worker());
Student stu = (Student)tool.getObj();//异常-->java.lang.ClassCastException: Worker cannot be cast to Student
System.out.println(stu);
//JDK 1.5
Util<Student> util = new Util<Student>();
//util.setObj(new Worker());//编译报错-->如果类型不匹配,直接编译失败。
//Student stu = util.getObj();//避免了向下转型。不用强制类型转换。
System.out.println(stu);
//总结:什么时候定义泛型?
//当类型不明确时,就应该使用泛型来表示,在类上定义参数,由调用者来传递实际类型参数。
}
}2. 泛型方法 --> 泛型定义在方法上。这里只需要注意一点,如果静态方法需要定义泛型,泛型只能定义在方法上。代码示例如下:
package ustc.lichunchun.generic.demo;
public class GenericDemo5 {
public static void main(String[] args) {
/*
* 泛型2:泛型方法-->泛型定义在方法上。
*/
Demo1<String> d = new Demo1<String>();
d.show("abc");
//d.print(6);在类上明确类型后,错误参数类型在编译时期就报错。
Demo1<Integer> d1 = new Demo1<Integer>();
d1.print(6);
//d1.show("abc");
System.out.println("----------------");
Demo2<String> d2 = new Demo2<String>();
d2.show("abc");
d2.print("bcd");
d2.print(6);
}
}
class Demo1<W>{
public void show(W w){
System.out.println("show: "+w);
}
public void print(W w){
System.out.println("print: "+w);
}
}
class Demo2<W>{
public void show(W w){
System.out.println("show: "+w);
}
public <Q> void print(Q w){//-->泛型方法。某种意义上可以将Q理解为Object。
System.out.println("print: "+w);
}
/*
public static void show(W w){//报错-->静态方法是无法访问类上定义的泛型的。
//因为静态方法优先于对象存在,而泛型的类型参数确定,需要对象明确。
System.out.println("show: "+w);
}
*/
public static <A> void staticShow(A a){//如果静态方法需要定义泛型,泛型只能定义在方法上。
System.out.println("static show: "+a);
}
}3. 泛型接口--> 泛型定义在接口上。
package ustc.lichunchun.generic.demo;
public class GenericDemo6 {
public static void main(String[] args) {
/*
* 泛型3:泛型接口-->泛型定义在接口上。
*/
SubDemo d = new SubDemo();
d.show("abc");
}
}
interface Inter<T>{//泛型接口。
public void show(T t);
}
class InterImpl<W> implements Inter<W>{//依然不明确要操作什么类型。
@Override
public void show(W t) {
System.out.println("show: "+t);
}
}
class SubDemo extends InterImpl<String>{
}
/*
interface Inter<T>{//泛型接口。
public void show(T t);
}
class InterImpl implements Inter<String>{
@Override
public void show(String t) {
}
}
*/可以解决当具体类型不确定的时候,这个通配符就是<?>
当操作类型时,不需要使用类型的具体功能时,只使用Object类中的功能。那么可以用 ? 通配符来表未知类型。
package ustc.lichunchun.generic.demo;
import java.util.ArrayList;
import java.util.Collection;
import java.util.HashSet;
import java.util.Iterator;
import java.util.List;
import java.util.Set;
import ustc.lichunchun.domain.Student;
public class GenericDemo7 {
public static void main(String[] args) {
/*
* 通配符<?> --> 相当于<? extends Object>
*/
List<String> list = new ArrayList<String>();
list.add("abc1");
list.add("abc2");
list.add("abc3");
printCollection(list);
Set<String> set = new HashSet<String>();
set.add("haha");
set.add("xixi");
set.add("hoho");
printCollection(set);
List<Student> list2 = new ArrayList<Student>();
list2.add(new Student("abc1",21));
list2.add(new Student("abc2",22));
list2.add(new Student("abc3",23));
list2.add(new Student("abc4",24));
//Collection<Object> coll = new ArrayList<Student>();-->wrong-->左右不一样,可能会出现类型不匹配
//Collection<Student> coll = new ArrayList<Object>();-->wrong-->左右不一样,可能会出现类型不匹配
//Collection<?> coll = new ArrayList<Student>();-->right-->通配符
printCollection(list2);
}
/*private static void printCollection(List<String> list) {
for (Iterator<String> it = list.iterator(); it.hasNext();) {
String str = it.next();
System.out.println(str);
}
}*/
/*private static void printCollection(Collection<String> coll) {
for (Iterator<String> it = coll.iterator(); it.hasNext();) {
String str = it.next();
System.out.println(str);
}
}*/
private static void printCollection(Collection<?> coll) {//在不明确具体类型的情况下,可以使用通配符来表示。
for (Iterator<?> it = coll.iterator(); it.hasNext();) {//技巧:迭代器泛型始终保持和具体集合对象一致的泛型。
Object obj = it.next();
System.out.println(obj);
}
}
} <? extends E>:接收E类型或者E的子类型对象。上限。一般存储对象的时候用。比如添加元素 addAll。
<? super E>:接收E类型或者E的父类型对象。下限。一般取出对象的时候用。比如比较器。
示例代码:
package ustc.lichunchun.generic.demo;
import java.util.ArrayList;
import java.util.Collection;
import java.util.HashSet;
import java.util.Iterator;
import java.util.List;
import java.util.Set;
import ustc.lichunchun.domain.Person;
import ustc.lichunchun.domain.Student;
import ustc.lichunchun.domain.Worker;
public class GenericDemo8 {
public static void main(String[] args) {
/*
* 泛型的限定
*/
List<Student> list = new ArrayList<Student>();
list.add(new Student("abc1",21));
list.add(new Student("abc2",22));
list.add(new Student("abc3",23));
list.add(new Student("abc4",24));
printCollection(list);
Set<Worker> set = new HashSet<Worker>();
set.add(new Worker("haha",23));
set.add(new Worker("xixi",24));
set.add(new Worker("hoho",21));
set.add(new Worker("haha",29));
printCollection(set);
}
/*
* 泛型的限定:
* ? extends E :接收E类型或者E的子类型。-->泛型上限。
* ? super E :接收E类型或者E的父类型。-->泛型下限。
*/
private static void printCollection(Collection<? extends Person> coll) {//泛型的限定,支持一部分类型。
for (Iterator<? extends Person> it = coll.iterator(); it.hasNext();) {
Person obj = it.next();//就可以使用Person的特有方法了。
System.out.println(obj.getName()+":"+obj.getAge());
}
}
}
练习1:演示泛型上限在API中的体现。我们这里使用的是TreeSet的构造函数:TreeSet<E>(Collection<? extends E> coll)
package ustc.lichunchun.generic.demo;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
import java.util.TreeSet;
import ustc.lichunchun.domain.Person;
import ustc.lichunchun.domain.Student;
import ustc.lichunchun.domain.Worker;
public class GenericDemo9 {
public static void main(String[] args) {
/*
* 演示泛型限定在API中的体现。
* TreeSet的构造函数。
* TreeSet<E>(Collection<? extends E> coll);
*
* 什么时候会用到上限呢?
* 一般往集合存储元素时。如果集合定义了E类型,通常情况下应该存储E类型的对象。
* 对于E的子类型的对象,E类型也可以接受(多态)。所以这时可以将泛型从E改为 ? extends E.
*/
Collection<Student> coll = new ArrayList<Student>();
coll.add(new Student("abc1",21));
coll.add(new Student("abc2",22));
coll.add(new Student("abc3",23));
coll.add(new Student("abc4",24));
Collection<Worker> coll2 = new ArrayList<Worker>();
coll2.add(new Worker("abc11",21));
coll2.add(new Worker("abc22",27));
coll2.add(new Worker("abc33",35));
coll2.add(new Worker("abc44",29));
TreeSet<Person> ts = new TreeSet<Person>(coll);//coll2 也可以传进来。
ts.add(new Person("abc8",21));
ts.addAll(coll2);//addAll(Collection<? extends E> c);
for (Iterator<Person> it = ts.iterator(); it.hasNext();) {
Person person = it.next();
System.out.println(person.getName());
}
}
}
//原理
class MyTreeSet<E>{
MyTreeSet(){
}
MyTreeSet(Collection<? extends E> c){
}
}package ustc.lichunchun.generic.demo;
import java.util.Comparator;
import java.util.Iterator;
import java.util.TreeSet;
import ustc.lichunchun.domain.Person;
import ustc.lichunchun.domain.Student;
import ustc.lichunchun.domain.Worker;
public class GenericDemo10 {
public static void main(String[] args) {
/*
* 演示泛型限定在API中的体现。
* TreeSet的构造函数。
* TreeSet<E>(Comparator<? super E> comparator)
*
* 什么时候用到下限呢?
* 当从容器中取出元素操作时,可以用E类型接收,也可以用E的父类型接收。
*
*/
//创建一个Student、Worker都能接收的比较器。
Comparator<Person> comp = new Comparator<Person>() {//匿名内部类
@Override
public int compare(Person o1, Person o2) {//每次都是容器中的两个元素过来进行比较。
int temp = o1.getAge()-o2.getAge();
return temp==0?o1.getName().compareTo(o2.getName()):temp;
}
};
TreeSet<Student> ts = new TreeSet<Student>(comp);
ts.add(new Student("abc1",21));
ts.add(new Student("abc2",28));
ts.add(new Student("abc3",23));
ts.add(new Student("abc4",25));
TreeSet<Worker> ts1 = new TreeSet<Worker>(comp);
ts1.add(new Worker("abc11",21));
ts1.add(new Worker("abc22",27));
ts1.add(new Worker("abc33",22));
ts1.add(new Worker("abc44",29));
for (Iterator<? extends Person> it = ts1.iterator(); it.hasNext();) {
Person p = it.next();//多态
System.out.println(p);
}
}
}
//原理
class YouTreeSet<E>{
YouTreeSet(Comparator<? super E> comparator){
}
} 1.泛型到底代表什么类型取决于调用者传入的类型,如果没传,默认是Object类型;
2.使用带泛型的类创建对象时,等式两边指定的泛型必须一致;
原因:编译器检查对象调用方法时只看变量,然而程序运行期间调用方法时就要考虑对象具体类型了;
3.等式两边可以在任意一边使用泛型,在另一边不使用(考虑向后兼容);
ArrayList<String> al = new ArrayList<Object>(); //错
//要保证左右两边的泛型具体类型一致就可以了,这样不容易出错。
ArrayList<? extends Object> al = new ArrayList<String>();
al.add("aa"); //错
//因为集合具体对象中既可存储String,也可以存储Object的其他子类,所以添加具体的类型对象不合适,类型检查会出现安全问题。
// ?extends Object 代表Object的子类型不确定,怎么能添加具体类型的对象呢?
public static void method(ArrayList<? extends Object> al) {
al.add("abc"); //错
//只能对al集合中的元素调用Object类中的方法,具体子类型的方法都不能用,因为子类型不确定。
}java.util.Map<K,V>接口,将键映射到值的对象。一个映射不能包含重复的键;每个键最多只能映射到一个值。要保证键的唯一性-->Set。值可以重复-->Collection。
Map:双列集合,一次存一对,键值对。
|--Hashtable:底层是哈希表数据结构,是线程同步的,不允许存储null键,null值。
|--Properties:用来存储键值对型的配置文件的信息,可以和IO技术相结合。
|--HashMap:底层是哈希表数据结构,是线程不同步的,允许存储null键,null值。替代了Hashtable。
|--TreeMap:底层是二叉树结构,线程不同步的。可以对map集合中的键进行指定顺序的排序。
揭秘:HashSet、TreeSet的底层是用HashMap、TreeMap实现的,只操作键,就是Set集合。
Map集合存储和Collection有着很大不同:
Collection一次存一个元素;Map一次存一对元素。
Collection是单列集合;Map是双列集合。
Map中的存储的一对元素:一个是键,一个是值,键与值之间有对应(映射)关系。
特点:要保证map集合中键的唯一性。
Map接口中的共性功能:
1.添加:
v put(key, value):当存储的键相同时,新的值会替换老的值,并将老值返回。如果键没有重复,返回null。
putAll(Map<k,v> map);
2.删除:
void clear():清空
v remove(key):删除指定键- -> 会改变集合长度!
3.判断:
boolean containsKey(Object key):是否包含key
boolean containsValue(Object value):是否包含value
boolean isEmpty();
4.取出:
v get(key):通过指定键获取对应的值。如果返回null,可以判断该键不存在。
当然有特殊情况,就是在hashmap集合中,是可以存储null键null值的。
int size():返回长度。
代码示例:
package ustc.lichunchun.map;
import java.util.HashMap;
import java.util.Map;
public class MapDemo {
public static void main(String[] args) {
/*
* 需求:Map集合中存储学号、姓名。
*/
Map<Integer, String> map = new HashMap<Integer, String>();
methodDemo(map);
}
public static void methodDemo(Map<Integer, String> map){
//1.存储键值对。如果键相同,会出现值覆盖。
System.out.println(map.put(3, "xiaoqiang"));
System.out.println(map.put(3, "erhu"));
map.put(7, "wangcai");
map.put(2, "daniu");
//2.移除。-->会改变长度。
//System.out.println(map.remove(7));
//3.获取。
System.out.println(map.get(7));
System.out.println(map);
}
}原理:map中是没有迭代器的,collection具备迭代器,只要将map集合转成Set集合,可以使用迭代器了。之所以转成set,是因为map集合具备着键的唯一性,其实set集合就来自于map,set集合底层其实用的就是map的方法。
把Map集合转成Set的方法:
方式1: Set keySet();
可以将map集合中的键都取出存放到set集合中。对set集合进行迭代。迭代完成,再通过get方法对获取到的键进行值的获取。
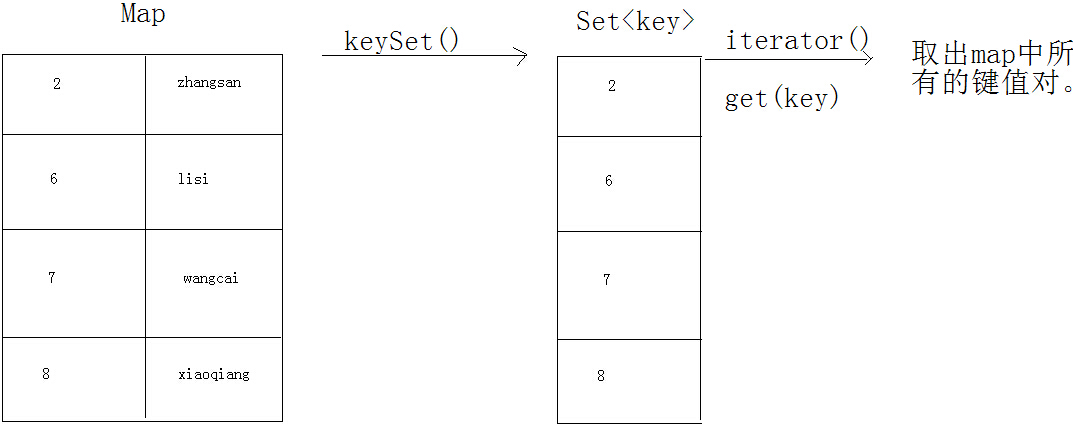
Set keySet = map.keySet();
Iterator it = keySet.iterator();
while(it.hasNext()) {
Object key = it.next();
Object value = map.get(key);
System.out.println(key+":"+value);
}方式2: Set entrySet();
取的是键和值的映射关系。Map.Entry:其实就是一个Map接口中的内部接口。为什么要定义在map内部呢?entry是访问键值关系的入口,是map的入口,访问的是map中的键值对。
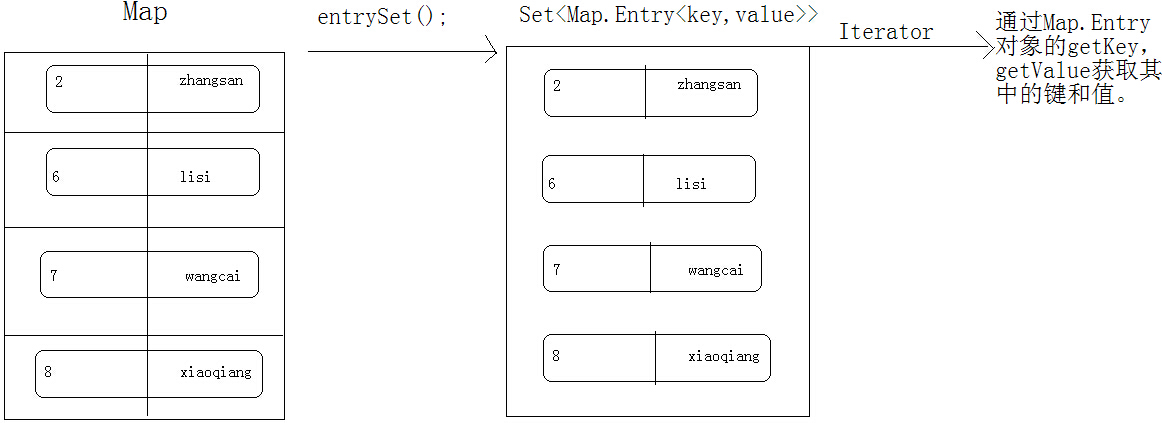
Set entrySet = map.entrySet();
Iterator it = entrySet.iterator();
while(it.hasNext()) {
Map.Entry me = (Map.Entry)it.next();
System.out.println(me.getKey()+"::::"+me.getValue());
}package ustc.lichunchun.map;
import java.util.Collection;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
public class MapDemo2 {
public static void main(String[] args) {
/*
* 取出Map中所有的元素。 map存储姓名---归属地。
*/
Map<String, String> map = new HashMap<String, String>();
map.put("xiaoqiang", "beijing");
map.put("wangcai", "funiushan");
map.put("daniu", "heifengzhai");
map.put("erhu", "wohudong");
map.put("zhizunbao", "funiushan");
//System.out.println(map.get("wangcai"));
/*
//演示keySet(); 取出所有的键,并存储到Set集合中。
Set<String> keySet = map.keySet();
//Map集合没有迭代器。但是可以将Map集合转成Set集合,在使用迭代器就ok了。
for (Iterator<String> it = keySet.iterator(); it.hasNext();) {
String key = it.next();
String value = map.get(key);
System.out.println(key+":"+value);
}
//演示entrySet(); Map.Entry:其实就是一个Map接口中的内部接口。
Set<Map.Entry<String, String>> entrySet = map.entrySet();
for (Iterator<Map.Entry<String, String>> it = entrySet.iterator(); it.hasNext();) {
Map.Entry<String, String> me = it.next();
String key = me.getKey();
String value = me.getValue();
System.out.println(key+"::"+value);
}
*/
//演示values(); 获取所有的值。
Collection<String> values = map.values();
for (Iterator<String> it = values.iterator(); it.hasNext();) {
String value = it.next();
System.out.println(value);
}
}
}
//原理
interface MyMap{//-->键值对
//entry就是map接口中的内部接口。
public static interface MyEntry{//-->键值对的映射关系
}
}
class MyDemo implements MyMap.MyEntry{
}当需求中出现映射关系时,应该最先想到map集合。
举例,获取星期几,代码如下:
package ustc.lichunchun.map;
import java.util.HashMap;
import java.util.Map;
import ustc.lichunchun.exception.NoWeekException;
public class MapTest {
public static void main(String[] args) {
/*
* 什么时候使用map集合呢?
* 当需求中出现映射关系时,应该最先想到map集合。
*/
String cnWeek = getCnWeek(3);
System.out.println(cnWeek);
String enWeek = getEnWeek(cnWeek);
System.out.println(enWeek);
}
/*
* 根据中文的星期,获取对应的英文星期。
* 中文与英文相对应,可以建立表,没有有序的编号,只能通过map集合。
*/
public static String getEnWeek(String cnWeek){
//创建一个表。
Map<String,String> map = new HashMap<String, String>();
map.put("星期一","Monday");
map.put("星期二","Tuesday");
map.put("星期三","Wednesday");
map.put("星期四","Thursday");
map.put("星期五","Friday");
map.put("星期六","Saturday");
map.put("星期日","Sunday");
return map.get(cnWeek);
}
/*
* 根据用户指定的数据获取对应的星期。
*/
public static String getCnWeek(int num){
if (num>7 || num<=0)
throw new NotWeekException(num+", 没有对应的星期");
String[] cnWeeks = {"","星期一","星期二","星期三","星期四","星期五","星期六","星期日"};
return cnWeeks[num];
}
}程序中用到的NotWeekException异常代码如下:
package ustc.lichunchun.exception;
public class NotWeekException extends RuntimeException {
/**
*
*/
private static final long serialVersionUID = 1L;
public NotWeekException() {
super();
}
public NotWeekException(String message, Throwable cause,
boolean enableSuppression, boolean writableStackTrace) {
super(message, cause, enableSuppression, writableStackTrace);
}
public NotWeekException(String message, Throwable cause) {
super(message, cause);
}
public NotWeekException(String message) {
super(message);
}
public NotWeekException(Throwable cause) {
super(cause);
}
}练习1: 员工对象(姓名,年龄)都有对应的归属地, 将员工和归属存储到HashMap集合中并取出。同姓名同年龄视为同一个员工。
package ustc.lichunchun.domain;
public class Employee implements Comparable<Employee>{
private String name;
private int age;
public Employee() {
super();
}
public Employee(String name, int age) {
super();
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Employee [name=" + name + ", age=" + age + "]";
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Employee other = (Employee) obj;
if (age != other.age)
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
@Override
public int compareTo(Employee o) {
int temp = this.age-o.age;
return temp==0?this.name.compareTo(o.name):temp;
}
}package ustc.lichunchun.map;
import java.util.HashMap;
import java.util.Map;
import ustc.lichunchun.domain.Employee;
public class HashMapTest {
public static void main(String[] args) {
/*
* 练习:
* 员工对象(姓名,年龄)都有对应的归属地。
* key=Employee value=String
*
* 1.
* 将员工和归属存储到HashMap集合中并取出。
* 同姓名同年龄视为同一个员工。
*
*/
Map<Employee,String> map = new HashMap<Employee,String>();//如果改成LinkedHashMap可以实现有序。
map.put(new Employee("xiaozhang",24),"北京");
map.put(new Employee("laoli",34),"上海");
map.put(new Employee("mingming",26),"南京");
map.put(new Employee("xili",30),"广州");
map.put(new Employee("laoli",34),"铁岭");//上海被覆盖掉了
for (Employee employee : map.keySet()) {
System.out.println(employee.getName()+":"+employee.getAge()+"..."+map.get(employee));
}
}
}练习2:接着上例,按照员工的年龄进行升序排序并取出。-->Comparable。再按照员工的姓名进行升序排序并取出。-->Comparator。
package ustc.lichunchun.map;
import java.util.Comparator;
import java.util.Map;
import java.util.TreeMap;
import ustc.lichunchun.domain.Employee;
public class TreeMapTest {
public static void main(String[] args) {
/*
* 练习:
* 2.
* 按照员工的年龄进行升序排序并取出。-->Comparable
* 按照员工的姓名进行升序排序并取出。-->Comparator
*/
Comparator<Employee> comparator = new Comparator<Employee>(){
@Override
public int compare(Employee o1, Employee o2) {
int temp = o1.getName().compareTo(o2.getName());
return temp==0?o1.getAge()-o2.getAge():temp;
}
};
//Map<Employee,String> map = new TreeMap<Employee,String>();// 按照年龄
Map<Employee,String> map = new TreeMap<Employee,String>(comparator);//按照姓名
map.put(new Employee("xiaozhang",24),"北京");
map.put(new Employee("laoli",34),"上海");
map.put(new Employee("mingming",26),"南京");
map.put(new Employee("xili",30),"广州");
map.put(new Employee("laoli",34),"铁岭");
for(Map.Entry<Employee, String> me : map.entrySet()){
System.out.println(me.getKey().getName()+"::"+me.getKey().getAge()+"..."+me.getValue());
}
}
}"bwa-er+b+c=tyx_bac?ecrtdcvr" 获取字符串中每一个字母出现的次数。要求结果格式:a(2)b(1)d(3)...
思路:
1.获取到字母。
2.如何获取字母次数?
发现字母和次数有对应关系。而且对应关系的一方具备唯一性。就想到了Map集合。map集合就是一张表。
3.使用查表法就可以了。
先查第一个字母在表中的次数。如果次数不存在,说明是第一次出现,将该字母和1存储到表中。以此类推。当要查的次数存在,将次数取出并自增后,再和对应的字母存储到到表中,map表的特点是相同键,值覆盖!
4.查完每一个字母后,表中存储的就是每一个字母出现的次数。
package ustc.lichunchun.test;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
import java.util.TreeMap;
public class Test {
public static void main(String[] args) {
/*
* 作业:"bwa-er+b+c=tyx_bac?ecrtdcvr"
* 获取字符串中每一个字母出现的次数。要求结果格式:a(2)b(1)d(3)...
* 思路:
* 1.获取到字母。
* 2.如何获取字母次数?
* 发现字母和次数有对应关系。而且对应关系的一方具备唯一性。
* 就想到了Map集合。map集合就是一张表。
* 3.使用查表法就可以了。
* 先查第一个字母在表中的次数。如果次数不存在,说明是第一次出现,将该字母和1存储到表中。
* 以此类推。当要查的次数存在,将次数取出并自增后,再和对应的字母存储到到表中,map表的特点是相同键,值覆盖!
* 4.查完每一个字母后,表中存储的就是每一个字母出现的次数。
*/
String str = "bwa-er+b+c=tyx_bac?ecrtdcvr";
String char_count = getCharCount(str);
System.out.println(char_count);
}
public static String getCharCount(String str) {
//1.将字符串转成字符数组。
char[] chs = str.toCharArray();
//2.定义map集合表。
Map<Character, Integer> map = new TreeMap<Character, Integer>();
//3.遍历字符数组。获取每一个字母。
for (int i = 0; i < chs.length; i++) {
//只对字母操作。
//if(!(chs[i]>='a'&&chs[i]<='z' || chs[i]>='A'&&chs[i]<='Z'))
if(!(Character.isLowerCase(chs[i]) || Character.isUpperCase(chs[i])))
continue;
//将遍历到的字母作为键去查表。获取值。
Integer value = map.get(chs[i]);
int count = 0;//用于记录次数
//如果次数存在,就用count记录该次数。如果次数不存在,就不记录,只对count自增变成1。
if(value != null){
count = value;
}
count++;
map.put(chs[i],count);
/*
if(value == null){
map.put(chs[i],1);
}else{
value++;
map.put(chs[i],value);
}*/
}
return mapToString(map);
}
/*
* 将map集合中的元素转成指定格式的字符串。a(2)b(1)d(3)......
*/
private static String mapToString(Map<Character, Integer> map) {
//1.数据多,无论类型是什么,最终都要变成字符串。所以可以使用StringBuilder
StringBuilder sb = new StringBuilder();
//2.遍历集合map。keySet()
for(Character key : map.keySet()){
Integer value = map.get(key);
sb.append(key+"("+value+")");
}
/*
Set<Character> keySet = map.keySet();
for (Iterator<Character> it = keySet.iterator(); it.hasNext();) {
Character key = it.next();
Integer value = map.get(key);
//将键值存储到sb中。
sb.append(key+"("+value+")");
}*/
return sb.toString();
}
}Collections类
java.util.Collections类的出现给集合操作提供了更多的功能。这个类不需要创建对象,完全由在 collection 上进行操作或返回 collection 的静态方法组成。
1.对List排序:
sort(list);//具备泛型限定,保证安全。
2.逆序:
reverseOrder
3.最值:
max
min
4.二分查找:
binarySearch
5.将非同步集合转成同步集合:
synchronizedCollection
synchronizedList
SynchronizedSet
synchronizedMa
上述部分功能的解释:
1.排序方法上的泛型的由来:
interface Comparable<T>
{
void compareTo(T o);
}
class Student extends Person implements Comparable<Person>
{
public int compareTo(Person p){//Person可以接受Student类型。
}
}
public static <T extends Comparable<? super T>> void sort(List<T> list)//直接定义泛型T,在编译时期就保证类型的正确。
{
//<T extends Comparable>:必须是Comparable的子类才具备比较功能。
//<? super T>:只要是T的父类,都可以接受T类型,进行比较。
}
public static void sort(List<Object> list)//老版本,即使编译通过,运行时期不安全,容易出现类型转换异常。
{
stu1.compareTo(stu2);
}/*
* 模拟一个获取字符串集合最大值的功能。
*/
public static String getMax(Collection<String> coll){
Iterator<String> it = coll.iterator();
//定义变量记录容器中其中一个。
String max = it.next();
//遍历容器所有的元素。
while(it.hasNext()){
String temp = it.next();
//在遍历过程中进行比较。只要比变量中的值大。用变量记录下来,就哦了。
if(temp.compareTo(max)>0){
max = temp;
}
}
return max;
}
/*
* 模拟一个Collections的min方法。
*/
public static <T extends Object & Comparable<? super T>> T min(Collection<? extends T> coll) {
Iterator<? extends T> i = coll.iterator();
T candidate = i.next();
while (i.hasNext()) {
T next = i.next();
if (next.compareTo(candidate) < 0)
candidate = next;
}
return candidate;
}List list = new ArrayList();//非同步的。
list = MyCollections.synList(list);//返回一个同步的list。
class MyCollections{
public static List synList(List list){
return new MyList(list);
}
private class MyList{
private List list;
private static final Object lock = new Object();
MyList(List list){
this.list = list;
}
public boolean add(Object obj){
synchronized(lock){
return list.add(obj);
}
}
public boolean remove(Object obj){
synchronized(lock){
return list.remove(obj);
}
}
}
}Collections工具类代码示例:
package ustc.lichunchun.collections;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Collections;
import java.util.Iterator;
import java.util.List;
import ustc.lichunchun.comparator.ComparatorByLength;
public class CollectionsDemo {
public static void main(String[] args) {
/*
* Collections排序、逆序、最值、同步方法演示
*/
methodDemo1();
Collection<String> coll = new ArrayList<String>();
coll.add("abcd");
coll.add("ab");
coll.add("haha");
coll.add("zzz");
String max = getMax(coll);
String max1 = Collections.max(coll,new ComparatorByLength());
System.out.println("max = "+max);
System.out.println("max1 = "+max1);
/*
* Collections中有一个可以将非同步集合转成同步集合的方法。
* 同步集合 synchronized集合(非同步集合);
*/
Collection<String> synColl = Collections.synchronizedCollection(coll);
}
public static void methodDemo1() {
List<String> list = new ArrayList<String>();
list.add("abc");
list.add("xy");
list.add("haha");
list.add("nba");
System.out.println(list);
//对list排序。自然排序。使用的是元素的compareTo方法。
Collections.sort(list);
System.out.println(list);
//按照长度排序。
Collections.sort(list,new ComparatorByLength());
System.out.println(list);
//按照长度逆序。
Collections.sort(list,Collections.reverseOrder(new ComparatorByLength()));//reverseOrder强行逆转比较器顺序。
System.out.println(list);
}
}package ustc.lichunchun.comparator;
import java.util.Comparator;
public class ComparatorByLength implements Comparator<String> {
@Override
public int compare(String o1, String o2) {
int temp = o1.length()-o2.length();
return temp==0?o1.compareTo(o2):temp;
}
}Collection 和 Collections的区别:
Collections是个java.util下的类,是针对集合类的一个工具类,提供一系列静态方法,实现对集合的查找、排序、替换、线程安全化(将非同步的集合转换成同步的)等操作。
Collection是个java.util下的接口,它是各种集合结构的父接口,继承于它的接口主要有Set和List,提供了关于集合的一些操作,如插入、删除、判断一个元素是否其成员、遍历等。
Arrays类
java.util.Arrays类是用来操作数组的工具类,里面的方法都是静态的。代码示例:
package ustc.lichunchun.arrays;
import java.util.Arrays;
public class ArraysDemo {
public static void main(String[] args) {
//int[] arr = new int[3];
Integer[] arr = new Integer[3];
String[] arr1 = new String[3];
swap(arr,1,2);
swap(arr1,1,2);
int[] arr2 = {45,1,23,56,67};
System.out.println(arr2);//[I@1db9742
System.out.println(Arrays.toString(arr2));//[45, 1, 23, 56, 67],底层用的是StringBuilder。
}
public static <T> void swap(T[] arr, int x, int y){//T必须是引用类型。int--->Integer,自动装箱拆箱。
T temp = arr[x];
arr[x] = arr[y];
arr[y] = temp;
}
//toString的源码实现。
public static String toString(int[] a) {
if (a == null)
return "null";
int iMax = a.length - 1;
if (iMax == -1)
return "[]";
StringBuilder b = new StringBuilder();
b.append('[');
for (int i = 0; ; i++) {//中间省略条件判断,提高了效率。
b.append(a[i]);
if (i == iMax)
return b.append(']').toString();
b.append(", ");
}
}
}1.数组转成集合
Arrays.asList方法:将数组转换成list集合。
<span style="font-size:14px;">String[] arr = {"abc","kk","qq"};
List<String> list = Arrays.asList(arr);//将arr数组转成list集合。</span>用aslist方法,将数组变成集合;可以通过list集合中的方法来操作数组中的元素:isEmpty()、contains、indexOf、set等方法。
注意(局限性):
数组是固定长度,不可以使用集合对象增加或者删除等,会改变数组长度的功能方法。比如add、remove、clear。(会报不支持操作异常UnsupportedOperationException)。
如果数组中存储的引用数据类型,直接作为集合的元素可以直接用集合方法操作。
如果数组中存储的是基本数据类型,asList会将数组实体作为集合元素存在。
package ustc.lichunchun.arrays;
import java.util.Arrays;
import java.util.List;
public class ArraysDemo2 {
public static void main(String[] args) {
/*
* 数组转成集合。
*
* Arrays:用来操作数组的工具类,里面的方法都是静态的。
*/
demo_1();
demo_2();
}
public static void demo_1() {
/*
* 重点:Arrays asList(数组) 将数组转成集合。
*
* 为什么要把数组转成集合?
* 因为数组能用的方法是有限的:折半、排序、toString、equals、fill,没了。
* 我想知道数组的位置、是否包含某个元素,这些都没有,但是集合中有这些方法。
*
* 好处:数组转成List集合,就是为了使用集合的方法操作数组中的元素。
*
* 注意:数组的长度是固定的,所以对于集合的增删方法是不可以使用的,
* 否则会发生UnsupportedOperationException
*/
String[] strs = {"abc","haha","nba","zz"};
//以前的做法:自己定义一个函数实现功能
boolean b = myContains(strs, "nba");
System.out.println("contains:"+b);
//现在的做法:数组转成集合,从而利用集合的方法
List<String> list = Arrays.asList(strs);
System.out.println("list contains:"+list.contains("nba"));
System.out.println(list);
//list.add("qq");//报错--> java.lang.UnsupportedOperationException
//因为数组是固定长度的。
}
/*
* 自定义 对数组中某元素进行查找。
*/
public static boolean myContains(String[] arr, String key){
for (int i = 0; i < arr.length; i++) {
String str = arr[i];
if(str.equals(key))
return true;
}
return false;
}
public static void demo_2() {
/*
* 如果数组中都是引用数据类型,转成集合时,数组元素直接作为集合元素。
* 如果数组中都是基本数据类型,会将数组对象作为集合中的元素。(因为集合中只能存对象)
*/
int[] arr = {45,23,78,11,99};
List<int[]> list = Arrays.asList(arr);
System.out.println(list);//[[I@1db9742]
System.out.println(list.size());//1
System.out.println(list.get(0));//[I@1db9742
//原因:把数组作为元素,存进了集合中。
//那上面代码的泛型该咋写?
//泛型应该是集合中元素的类型。arr是int[]类型,所以是List<int[]> list
//实际中,我们应该声明为Integer数组,而不是int数组,如下:
Integer[] arr1 = {45,23,78,11,99};
List<Integer> list1 = Arrays.asList(arr1);
System.out.println(list1);//[45, 23, 78, 11, 99]
System.out.println(list1.get(0));//45
}
}2.集合转成数组
用的是Collection接口中的方法:toArray()。
注意:
如果给toArray传递的指定类型的数据长度小于了集合的size,那么toArray方法,会自定再创建一个该类型的数据,长度为集合的size。
如果传递的指定的类型的数组的长度大于了集合的size,那么toArray方法,就不会创建新数组,直接使用该数组即可,并将集合中的元素存储到数组中,其他为存储元素的位置默认值null。
所以,在传递指定类型数组时,最好的方式就是指定的长度和size相等的数组。
将集合变成数组后有什么好处?
限定了对集合中的元素进行增删操作,只要获取这些元素即可。
package ustc.lichunchun.arrays;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
public class ArraysDemo3 {
public static void main(String[] args) {
/*
* 集合转成数组。
*
* 使用的就是Collection接口中的toArray方法。
*
* 为什么要把集合转成数组?
* 可以对集合中的元素操作的方法进行限定,不允许对其进行增删。
*/
List<String> list = new ArrayList<String>();
list.add("abc");
list.add("haha");
/*
* toArray方法需要传入一个指定类型的数组。
* 长度该如何定义呢?
* 传入的数组长度,如果小于集合长度,那么该方法会创建一个同类型并和集合相同size的数组。
* 传入的数组长度,如果大于集合长度,那么该方法会使用指定的数组,存储集合中的元素,其他位置默认为null。
*
* 所以建议,长度就指定为集合的size();
*/
String[] arr =list.toArray(new String[0]);
System.out.println(Arrays.toString(arr));//[abc, haha]
String[] arr1 =list.toArray(new String[3]);
System.out.println(Arrays.toString(arr1));//[abc, haha, null]
String[] arr2 =list.toArray(new String[list.size()]);
System.out.println(Arrays.toString(arr2));//[abc, haha]
}
}JDK1.5出现的技术,用到函数的参数上,当要操作的同一个类型元素个数不确定的时候,可是用这个方式,这个参数可以接受任意个数的同一类型的数据。
以前我们计算元素之和,用的是下面的方法,针对不同个数,要定义多个函数。
public static int add(int i, int j, int k) {
return i + j + k;
}
public static int add(int i, int j) {
return i + j;
}public static int add(int[] arr) {
int sum = 0;
for (int i = 0; i < arr.length; i++) {
sum += arr[i];
}
return sum;
}但是问题是,数组的长度是固定的,如果不同需求中,个数不一样,那么要用不同容量的数组先去存起来,比较麻烦。
和以前接收数组不一样的是:以前定义数组类型,需要先创建一个数组对象,再将这个数组对象作为参数传递给函数。
现在,直接将数组中的元素作为参数传递即可。底层其实是将这些元素进行数组的封装,而这个封装动作,是在底层完成的,被隐藏了。所以简化了用户的书写,少了调用者定义数组的动作。
注意:
如果在参数列表中使用了可变参数,可变参数必须定义在参数列表结尾(也就是必须是最后一个参数,否则编译会失败)。
如果要获取多个int数的和呢?可以使用将多个int数封装到数组中,直接对数组求和即可。
package ustc.lichunchun.param;
public class ParamDemo {
public static void main(String[] args) {
int sum = add(4, 5);
int sum1 = add(4, 5, 6);
/*
* 计算多个整数的和。
*/
int[] arr = {34,1,4,6};
int[] arr2 = {23,35,45,6,57,6};
int sum2 = add(arr);
int sum3 = add(arr2);
/*
* JDK 1.5 可变参数,不用定义数组了。编译后的class文件中自动带着数组。
* 注意事项:只能定义在参数列表的最后。
* public static int add1(int x, int... arr) --> right
* public static int add1(int... arr, int x) --> wrong
*/
int sum4 = add1(34,1,4,6,57,9);
int sum5 = add1(99,11,24,56);
}
public static int add1(int... arr){
int sum = 0;
for (int i = 0; i < arr.length; i++) {
sum += arr[i];
}
return sum;
}
public static int add(int[] arr) {
int sum = 0;
for (int i = 0; i < arr.length; i++) {
sum += arr[i];
}
return sum;
}
public static int add(int i, int j, int k) {
return i + j + k;
}
public static int add(int i, int j) {
return i + j;
}
}导入了类中的所有静态成员,简化静态成员的书写。例如:import static java.util.Collections.*; -->导入了Collections类中的所有静态成员。但如果同名了,还是要加上各自的包名的。
package ustc.lichunchun.staticimport;
import static java.util.Collections.*;
import static java.lang.System.*;
public class StaticImportDemo {
public static void main(String[] args) {
/*
* 静态导入。
*/
java.util.List<String> list = new java.util.ArrayList<String>();
list.add("a");
list.add("c");
sort(list);
System.out.println(max(list));
out.println("hello");
}
}模拟斗地主
1.首先模拟一下QQ斗地主的洗牌和发牌:
package ustc.lichunchun.poker;
import java.util.ArrayList;
import java.util.Collections;
/*
* 模拟斗地主洗牌和发牌
*
* 分析:
* A:创建一个牌盒
* B:装牌
* C:洗牌
* D:发牌
* E:看牌
*/
public class PokerDemo {
public static void main(String[] args) {
//创建一个牌盒
ArrayList<String> array = new ArrayList<String>();
//装牌
//黑桃A,黑桃2,黑桃3,...,黑桃k
//红桃A,...
//梅花A,...
//方块A,...
//定义一个花色数组
String[] colors = {"♠","♥","♣","♦"};
//定义一个点数数组
String[] numbers = {"A","2","3","4","5","6","7","8","9","10","J","Q","K"};
//装牌
for(String color : colors){
for(String number : numbers){
array.add(color.concat(number));
}
}
array.add("小王 ");
array.add("大王 ");
//洗牌
Collections.shuffle(array);
//发牌
ArrayList<String> fengQingYang = new ArrayList<String>();
ArrayList<String> linQingXia = new ArrayList<String>();
ArrayList<String> liChunChun = new ArrayList<String>();
ArrayList<String> diPai = new ArrayList<String>();
for (int i = 0; i < array.size(); i++) {
if(i >= array.size() - 3){
diPai.add(array.get(i));
}else if(i % 3 == 0){
fengQingYang.add(array.get(i));
}else if(i % 3 == 1){
linQingXia.add(array.get(i));
}else{
liChunChun.add(array.get(i));
}
}
//看牌
lookPoker("风清扬",fengQingYang);
lookPoker("林青霞",linQingXia);
lookPoker("李春春",liChunChun);
lookPoker("底牌",diPai);
}
public static void lookPoker(String name, ArrayList<String> array) {
System.out.print(name + "的牌是:");
for(String s : array){
System.out.print(s + " ");
}
System.out.println();
}
}

2.根据上述程序运行结果,我们得考虑发到手里的牌进行排序,这样看起来比较舒服。这里有一个要求,需要尽可能多的使用到本篇博文前面的知识点。所以,做了如下的分析:
package ustc.lichunchun.poker;
import java.util.ArrayList;
import java.util.Collections;
import java.util.HashMap;
import java.util.TreeSet;
/*
* 思路:
* A:创建一个HashMap集合
* B:创建一个ArrayList集合
* C:创建花色数组和点数数组
* D:从0开始往HashMap里面存储编号,并存储对应的牌
* 同时往ArrayList里面存储编号即可。
* E:洗牌(洗的是编号)
* F:发牌(发的也是编号,为了保证编号是排序的,就创建TreeSet集合接收)
* G:看牌(遍历TreeSet集合,获取编号,到HashMap集合找对应的牌)
*/
public class PokerDemo2 {
public static void main(String[] args) {
//创建一个HashMap集合
HashMap<Integer, String> hm = new HashMap<Integer, String>();
//创建一个ArrayList集合
ArrayList<Integer> array = new ArrayList<Integer>();
//创建花色数组和点数数组
//定义一个花色数组
String[] colors = {"♦","♣","♥","♠"};
//定义一个点数数组
String[] numbers = {"3","4","5","6","7","8","9","10","J","Q","K","A","2"};
//从0开始往HashMap里面存储编号,并存储对应的牌,同时往ArrayList里面存储编号即可。
int index = 0;
for(String number : numbers){
for(String color : colors){
String poker = color.concat(number);
hm.put(index, poker);
array.add(index);
index++;
}
}
hm.put(index, "小王");
array.add(index++);
hm.put(index, "大王");
array.add(index);
//洗牌(洗的是编号)
Collections.shuffle(array);
//发牌(发的也是编号,为了保证编号是排序的,就创建TreeSet集合接收)
TreeSet<Integer> fengQingYang = new TreeSet<Integer>();
TreeSet<Integer> linQingXia = new TreeSet<Integer>();
TreeSet<Integer> liChunChun = new TreeSet<Integer>();
TreeSet<Integer> diPai = new TreeSet<Integer>();
for(int i = 0; i < array.size(); i++){
if(i >= array.size()-3){
diPai.add(array.get(i));
}else if(i % 3 == 0){
fengQingYang.add(array.get(i));
}else if(i % 3 == 1){
linQingXia.add(array.get(i));
}else{
liChunChun.add(array.get(i));
}
}
//看牌(遍历TreeSet集合,获取编号,到HashMap集合找对应的牌)
lookPoker("风清扬", fengQingYang, hm);
lookPoker("林青霞", linQingXia, hm);
lookPoker("李春春", liChunChun, hm);
lookPoker("底牌", diPai, hm);
}
//写看牌的功能
public static void lookPoker(String name, TreeSet<Integer> ts, HashMap<Integer, String> hm){
System.out.print(name + "的牌是:");
for(Integer key : ts){
String value = hm.get(key);
System.out.print(value + " ");
}
System.out.println();
}
}程序运行结果如下:

好了,集合框架的基础部分学习,我就记录到这里。
如果有疑问,欢迎和我讨论,共同进步:lichunchun4.0@gmail.com
转载请声明出处:http://blog.csdn.net/zhongkelee/article/details/46801449
另附:Java集合框架面试问题集锦 -- 摘自ImportNew公众号。















 256
256

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









