









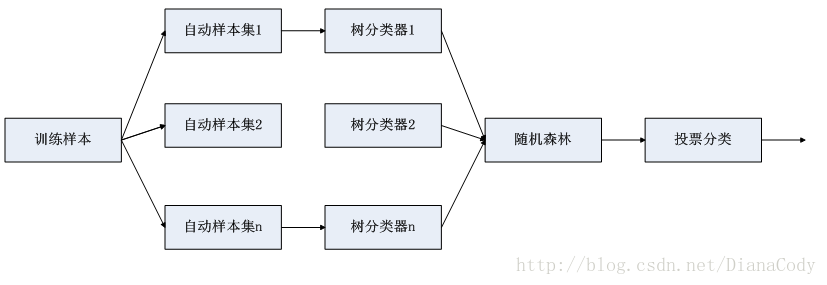
随机森林(RF, RandomForest)包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定。通过自助法(boot-strap)重采样技术,不断生成训练样本和测试样本,由训练样本生成多个分类树组成的随机森林,测试数据的分类结果按分类树投票多少形成的分数而定。
随机森林以随机的方式建立一个森林,森林里有很多决策树,且每棵树之间无关联,当有一个新样本进入后,让森林中每棵决策树分别各自独立判断,看这个样本应该属于哪一类(对于分类算法)。然后看哪一类被选择最多,就选择预测此样本为那一类。
→ 每个节点处随机选择特征进行分支。
利用bootstrap重抽样方法,从原始样本中抽出多个样本,对每个bootstrap样本进行决策树建模。
主要思想是bagging并行算法,用很多弱模型组合出一种强模型。
一、随机决策树的构造
建立每棵决策树的过程中,有2点:采样与完全分裂。首先是两个随机采样的过程,RF要对输入数据进行一下行(样本)、列(特征)采样,对于行采样(样本)采用有放回的方式,也就是在采样得到的样本中可以有重复。从M个特征中(列采样)出m特征。之后就是用完全分裂的方式建立出决策树。
一般决策树会剪枝,但这里采用随机化,就算不剪枝也不会出现“过拟合”现象。
二、随机森林的构造
1.有N个样本,则有放回地随机选择N个样本(每次取1个,放回抽样)。这选择好了的N各样本用来训练一个决策树,作为决策树根节点处的样本。
2.当每个样本有M个属性时,在决策树的每个节点需要分裂时,随机从这M个属性中选取出m个属性,满足条件m<<M。然后从这m个属性中采用某种策略(如信息增益)来选择一个属性,作为该节点的分裂属性。
3.决策树形成过程中,每个节点都要按照步骤2来分裂(很容易理解,如果下一次该节点选出来的那一个属性是刚刚父节点分裂时用过的属性,则该节点已经达到了叶子节点,无需继续分裂)。一直到不能再分裂为止,注意整个决策树形成过程中没有剪枝。
4.按步骤1-3建立大量决策树,如此形成RF。
(从上面步骤可以看出,RF的随机性体现在每棵树的训练样本是随机的,树中每个节点的分类属性也是随机选择的,有了这两个随机的保证,RF就不会产生过拟合现象了)
三、随机森林参数
随机森林有2个重要参数:一是树节点预选变量个数,二是随机森林中树的个数(m的大小)
RF中有2个要人为控制的参数:1.森林中树的数量,一般建议取很大;2.m的大小,推荐m的值为M的均方根。
四、RF性能及优缺点
优点:
1.很多的数据集上表现良好;
2.能处理高维度数据,并且不用做特征选择;
3.训练完后,能够给出那些feature比较重要;
4.训练速度快,容易并行化计算。
缺点:
1.在噪音较大的分类或回归问题上会出现过拟合现象;
2.对于不同级别属性的数据,级别划分较多的属性会对随机森林有较大影响,则RF在这种数据上产出的数值是不可信的。















 1981
1981

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









