







 本文深入分析了DCMTK与fo-dicom在保存DICOM文件时的异同,重点讨论了DCMTK中采用的状态机同步模式和fo-dicom的异步编程模型(APM)。通过对源码剖析和性能检测,展示了两者在文件保存过程中的执行机制。最后,探讨了C#中不同异步编程模式的原理和应用场景,为理解异步编程和状态机提供了参考。
本文深入分析了DCMTK与fo-dicom在保存DICOM文件时的异同,重点讨论了DCMTK中采用的状态机同步模式和fo-dicom的异步编程模型(APM)。通过对源码剖析和性能检测,展示了两者在文件保存过程中的执行机制。最后,探讨了C#中不同异步编程模式的原理和应用场景,为理解异步编程和状态机提供了参考。
一、背景:
最近一直在做DCM相关的编程工作,以前项目使用C++居多,所以使用DCMTK开源库,而目前团队使用C#居多,所以需要转向使用fo-dicom库,由于前一篇专栏文章DICOM医学图像处理:利用fo-dicom发送C-Find查询Worklist在调试过程中需要对DIMSE信息进行手动保存,偶然间发现了dcmtk开源库与fo-dicom开源库在保存dcm文件时使用的方式差异很大,因此决定研究一下,期望通过对比分析来看一下孰优孰劣。
二、dcmtk与fo-dicom保存文件函数的源码剖析:
1)dcmtk中DcmFileFormat的saveFile
saveFile中将文件写入状态划分为四种,即ERW_init 、ERW_ready、ERW_inWork、ERW_notInitialized四个状态。针对不同的状态进行不同的处理,因此可以认为dcmtk中的文件保存使用的是“状态机”方式,这有点类似于我以前用C++写过的一个自解析C++代码的程序,也是通过判别当前的环境来设定不同的状态,从而跳转到不同的操作中 。状态机(State Machine)这种方式在数字电路、编译原理中是很常见的(http://blog.chinaunix.net/uid-14880649-id-3011358.html),只不过dcmtk在文件写入过程中用到的是最直观的状态机而已(http://blog.csdn.net/xgbing/article/details/2784127)。
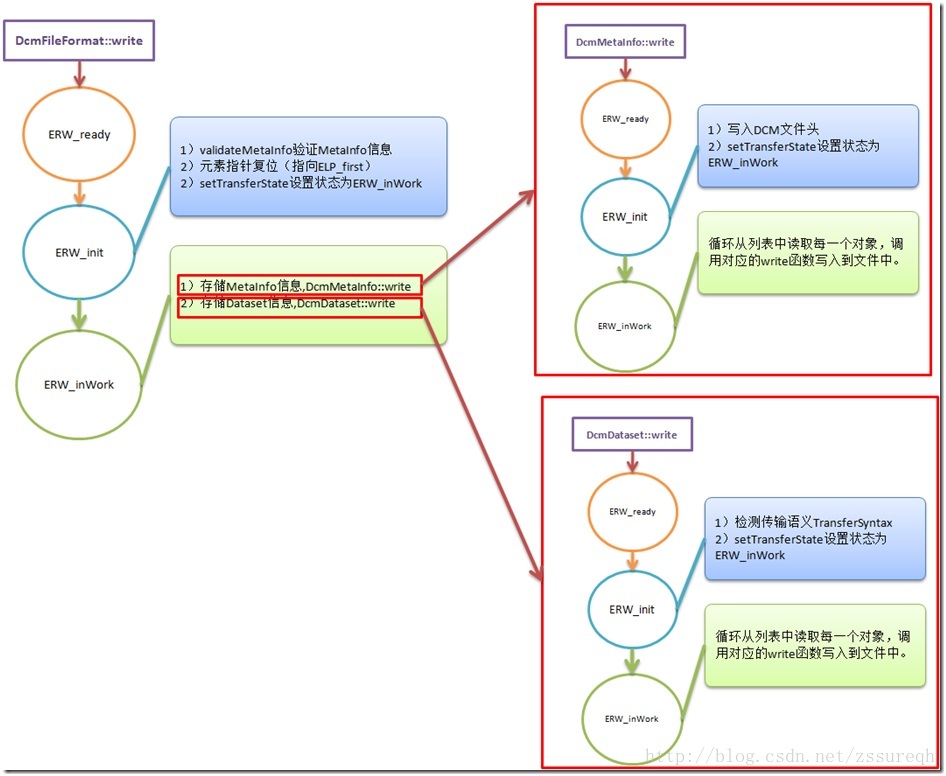
状态机可以简单的理解为“特定状态,针对输入字符,发生状态改变,没有额外的行为”,在DCMTK中实现的状态机可能并不是十分符合原始状态机的定义,因为各个状态的跳转并非是按照当前输入来决定的,而是根据DCM文件当前写入的程度(是否可以理解为事件?)来设定各个状态(即ERW_XXX四个状态),不同的阶段分别需要完成格式检查、写入准备、写入、写入完成。
状态机的编程写法有两种,竖写法——即针对每一种状态下发生的种种事件来进行分类处理;横写法——即针对每一种事件所能引起的状态改变来分类处理(详情参见http://blog.csdn.net/tomsen00/article/details/4932789),dcmtk的文件保存函数中使用的就是“竖写法”,因为各个状态之间有先后顺序,并非无序的跳转,必须先完成前缀(Preamble),然后才能写信息元(MetaInfo)、最后是真正的数据体(Dataset)。另外比较特殊的是:由于DCM文件本身的自包含性,即MetaInfo与Dataset两部分的互嵌套性(可参照我以前的博文http://blog.csdn.net/zssureqh/article/details/9275271),针对于DCM文件的不同部分又分别利用“状态机”来控制各部分的写入确保顺利进行。
2)fo-dicom中Dicom的Save
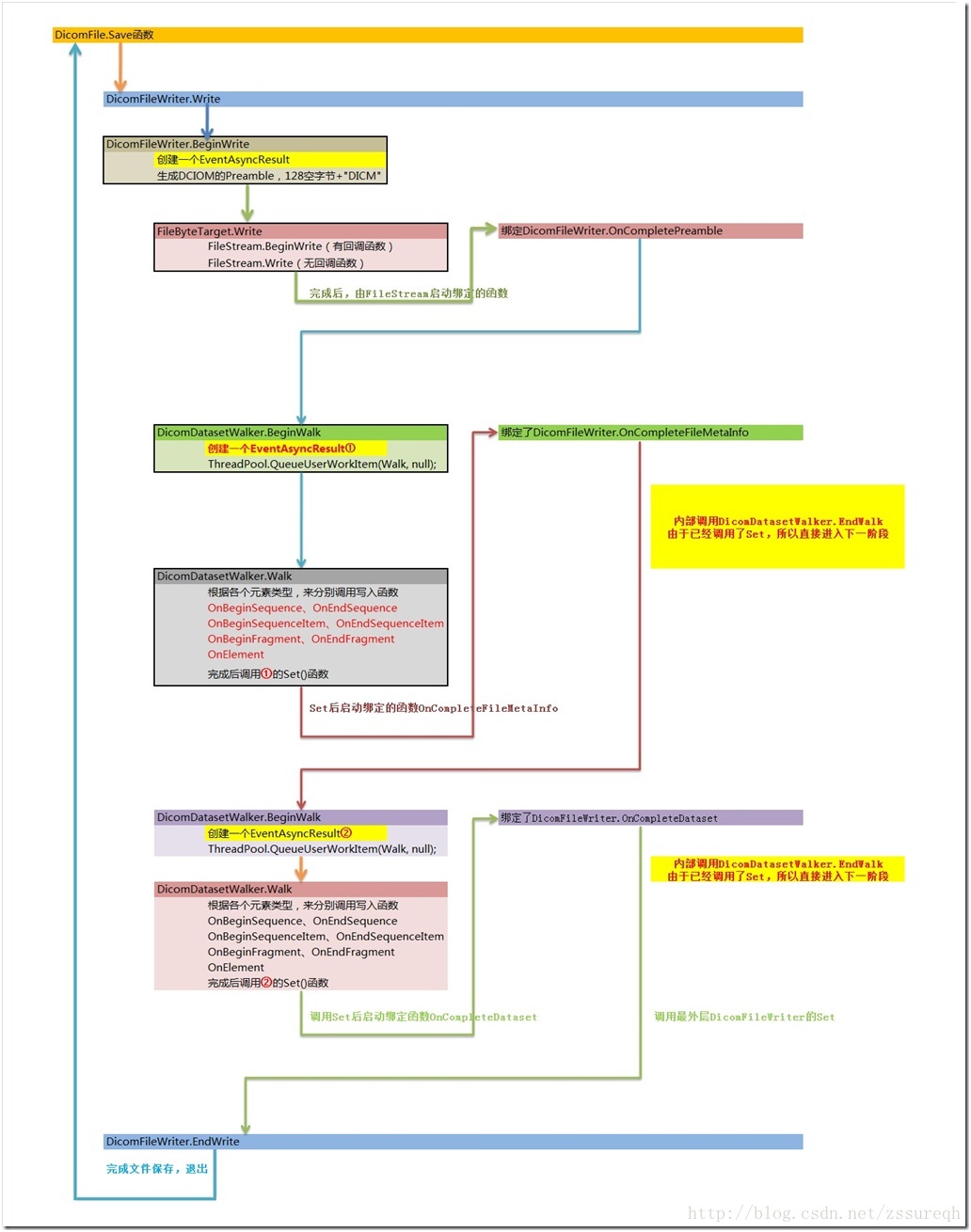
DicomFileWriter类中的同步函数Write内直接发起了异步调用请求,代码如下:
< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











