







引入: 在我们的思维中,会有一种习惯,当遇到某种问题时,会直接考虑用最直接的语言去去实现它,而往往忽略了整个程序的可维护性、可扩展性。 比如,我们写一个基本的计算器功能,要求能计算四则运算,大家或许会直接写:
public class ProgramDemo{
public static void main(String[] args) throws Exception {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
System.out.println("请输入数字A :");
String a = br.readLine();
System.out.println("请输入运算符 :");
String o = br.readLine();
System.out.println("请输入数字B :");
String b = br.readLine();
double numA = Double.parseDouble(a);
double numB = Double.parseDouble(b);
double result = 0;
switch (o.charAt(0)) {
case '+':
result = numA + numB;
break;
case '-':
result = numA - numB;
break;
case '*':
result = numA * numB;
break;
case '/':
result = numA / numB;
break;
default:
break;
}
System.out.println(result);
}
}如此代码,确实能够完成简单的四则运算,但是,我们可以发现,在main方法里,我们不仅要获取用户输入,还要执行运算,也就是说,该段代码既有了界面编程、又有了逻辑实现,可以想像,这个代码多么的繁杂,根本不利于以后的维护。
那当然了,我们可以用面向对象的思想,将界面逻辑和运算逻辑分开,把运算单独的封装起来,可以实现重复利用:
运算逻辑实现类Operation.java:
public class Operation {
public static double getResult(double numA, double numB, char operate) {
double result = 0;
switch (operate) {
case '+':
result = numA + numB;
break;
case '-':
result = numA - numB;
break;
case '*':
result = numA * numB;
break;
case '/':
result = numA / numB;
break;
default:
break;
}
return result;
}
}public class ProgramDemo{
public static void main(String[] args) throws Exception {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
System.out.println("请输入数字A :");
String a = br.readLine();
System.out.println("请输入运算符 :");
String o = br.readLine();
System.out.println("请输入数字B :");
String b = br.readLine();
double result = Operation.getResult(Double.parseDouble(a),
Double.parseDouble(b), o.charAt(0));
System.out.println(result);
}
}当然不够了,你要想想,这个地方,我们要加一个求余数操作,但是我们需要其余的加减乘除的运算都参与编译,显然这是不合适的,会降低程序的运行效率。
显然,为了降低程序的耦合度,我们需要将加减乘除等各种运算分离开,利用继承和多态的思想,完成运算操作:
public abstract class Operation {
// 输入的第一个数
private double numA;
// 输入的第二个数
private double numB;
public double getNumA() {
return numA;
}
public void setNumA(double numA) {
this.numA = numA;
}
public double getNumB() {
return numB;
}
public void setNumB(double numB) {
this.numB = numB;
}
// 获取结果
public abstract double getResult();
}以上,我们定义了一个抽象类Operation,该类里有一个抽象方法getResult(),专门用户获取运算结果,所有的 Operation的子类都必须重写该方法。
public class OperationAdd extends Operation {
@Override
public double getResult() {
double result = 0;
result = getNumA() + getNumB();
return result;
}
}public class OperationDiv extends Operation {
@Override
public double getResult() {
double result = 0;
if (getNumB() == 0) {
try {
throw new Exception("除数不能为0");
} catch (Exception e) {
e.printStackTrace();
}
}
result = getNumA() / getNumB();
return result;
}
}public class OperationMul extends Operation {
@Override
public double getResult() {
double result = 0;
result = getNumA() * getNumB();
return result;
}
}public class OperationSub extends Operation {
@Override
public double getResult() {
double result = 0;
result = getNumA() - getNumB();
return result;
}
}
看,我们已经成功的分离了各种运算方法,使得程序具有更好的扩展性: 如果想增加一个别的运算方法,可以直接继承Operation,
实现自己的运算法则即可。那接下来,如何让我们的计算机知道你希望用哪一个算法呢?这里就要引出了简单工厂模式。
什么是简单工厂模式:
简单工厂模式(Simple Factory Pattern)属于类的创新型模式,又叫静态工厂方法模式(Static FactoryMethod Pattern),是通过专门定义一个类来负责创建其他类的实例,被创建的实例通常都具有共同的父类。
简单工厂模式的UML图:
简单工厂模式中包含的角色及其相应的职责如下:
工厂角色(Creator):这是简单工厂模式的核心,由它负责创建所有的类的内部逻辑。当然工厂类必须能够被外界调用,创建所需要的产品对象。
抽象(Product)产品角色:简单工厂模式所创建的所有对象的父类,注意,这里的父类可以是接口也可以是抽象类,它负责描述所有实例所共有的公共接口。
具体产品(Concrete Product)角色:简单工厂所创建的具体实例对象,这些具体的产品往往都拥有共同的父类。
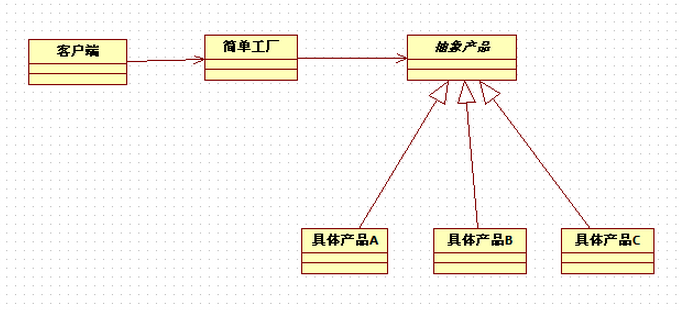
了解简单工厂模式后,我们用简单工厂模式,来“生产”运算类:
public class OperateFactory {
public static Operation createOperate(char operate) {
Operation oper = null;
switch (operate) {
case '+':
oper = new OperationAdd();
break;
case '-':
oper = new OperationSub();
break;
case '*':
oper = new OperationMul();
break;
case '/':
oper = new OperationDiv();
break;
default:
break;
}
return oper;
}
}可见,我们利用继承及多态,实现工厂,可以实现对“运算类”的“生产”操作,以后再添加别的运算,可以直接使用工厂类去添加运算操作类。
简单工厂模式的优缺点分析:
优点:工厂类是整个模式的关键所在。它包含必要的判断逻辑,能够根据外界给定的信息,决定究竟应该创建哪个具体类的对象。用户在使用时可以直接根据工厂类去创建所需的实例,而无需了解这些对象是如何创建以及如何组织的。有利于整个软件体系结构的优化。
缺点:由于工厂类集中了所有实例的创建逻辑,这就直接导致一旦这个工厂出了问题,所有的客户端都会受到牵连;而且由于简单工厂模式的产品室基于一个共同的抽象类或者接口,这样一来,但产品的种类增加的时候,即有不同的产品接口或者抽象类的时候,工厂类就需要判断何时创建何种种类的产品,这就和创建何种种类产品的产品相互混淆在了一起,违背了单一职责,导致系统丧失灵活性和可维护性。而且更重要的是,简单工厂模式违背了“开放封闭原则”,就是违背了“系统对扩展开放,对修改关闭”的原则,因为当我新增加一个产品的时候必须修改工厂类,相应的工厂类就需要重新编译一遍。
总结一下:简单工厂模式分离产品的创建者和消费者,有利于软件系统结构的优化;但是由于一切逻辑都集中在一个工厂类中,导致了没有很高的内聚性,同时也违背了“开放封闭原则”。另外,简单工厂模式的方法一般都是静态的,而静态工厂方法是无法让子类继承的,因此,简单工厂模式无法形成基于基类的继承树结构。
简单工厂模式的实际应用简介:
作为一个最基本和最简单的设计模式,简单工厂模式却有很非常广泛的应用,我们这里以Java中的JDBC操作数据库为例来说明。
JDBC是SUN公司提供的一套数据库编程接口API,它利用Java语言提供简单、一致的方式来访问各种关系型数据库。Java程序通过JDBC可以执行SQL语句,对获取的数据进行处理,并将变化了的数据存回数据库,因此,JDBC是Java应用程序与各种关系数据进行对话的一种机制。用JDBC进行数据库访问时,要使用数据库厂商提供的驱动程序接口与数据库管理系统进行数据交互。
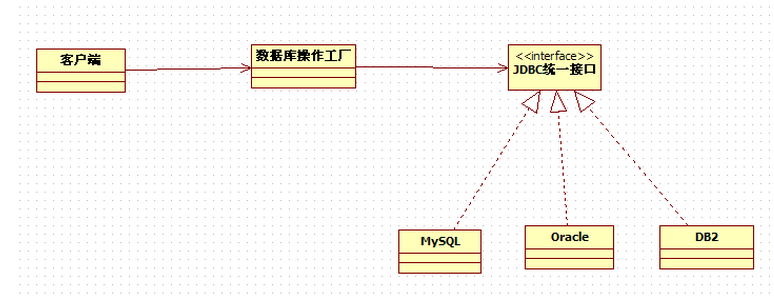
客户端要使用使用数据时,只需要和工厂进行交互即可,这就导致操作步骤得到极大的简化,操作步骤按照顺序依次为:注册并加载数据库驱动,一般使用Class.forName();创建与数据库的链接Connection对象;创建SQL语句对象preparedStatement(sql);提交SQL语句,根据实际情况使用executeQuery()或者executeUpdate();显示相应的结果;关闭数据库。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









