







 本文探讨了scrapy-redis在所有request爬取完毕后如何避免爬虫空跑的问题。解决方案包括利用scrapy的关闭spider扩展功能设置超时时间,以及修改scrapy-redis源码,当爬取队列长时间为空时自动关闭spider。在修改源码时,需要注意线程同步问题和不同类型的调度队列选择。
本文探讨了scrapy-redis在所有request爬取完毕后如何避免爬虫空跑的问题。解决方案包括利用scrapy的关闭spider扩展功能设置超时时间,以及修改scrapy-redis源码,当爬取队列长时间为空时自动关闭spider。在修改源码时,需要注意线程同步问题和不同类型的调度队列选择。
scrapy-redis所有request爬取完毕,如何解决爬虫空跑问题?
1. 背景
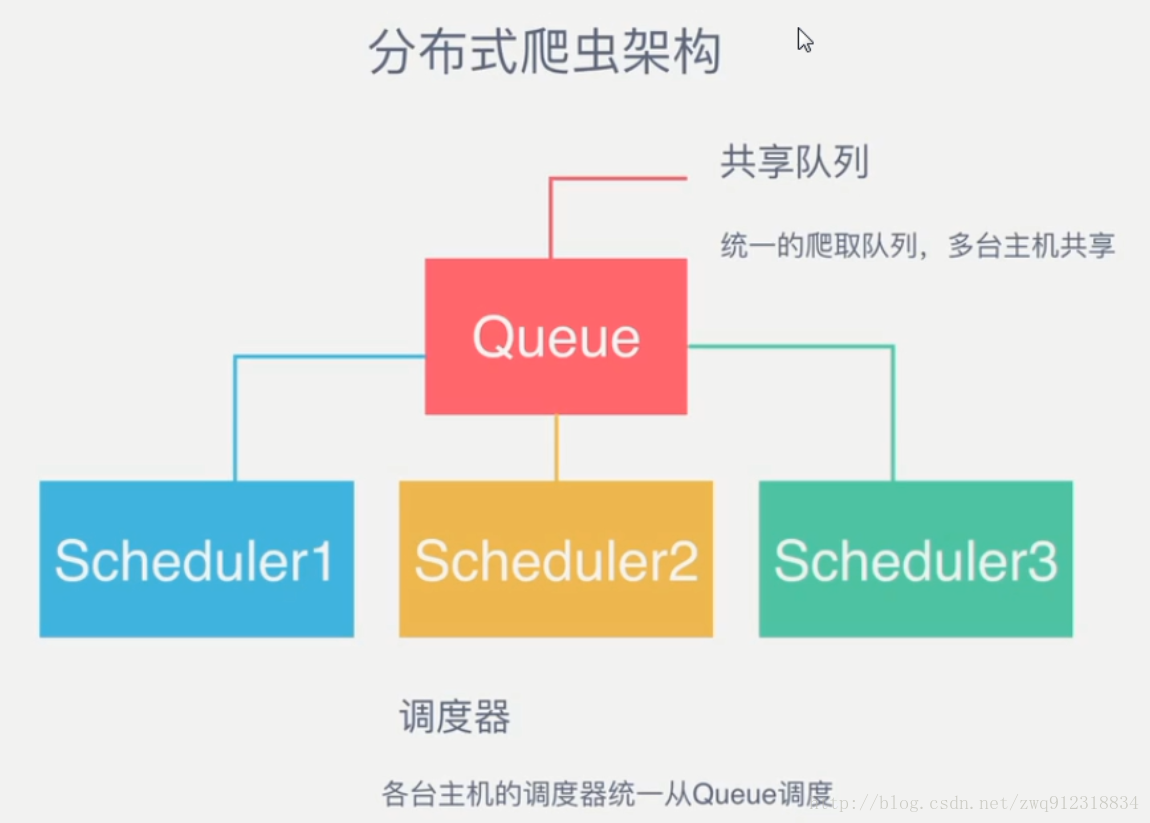
根据scrapy-redis分布式爬虫的原理,多台爬虫主机共享一个爬取队列。当爬取队列中存在request时,爬虫就会取出request进行爬取,如果爬取队列中不存在request时,爬虫就会处于等待状态,行如下:
E:\Miniconda\python.exe E:/PyCharmCode/redisClawerSlaver/redisClawerSlaver/spiders/main.py
2017-12-12 15:54:18 [scrapy.utils.log] INFO: Scrapy 1.4.0 started (bot: scrapybot)
2017-12-12 15:54:18 [scrapy.utils.log] INFO: Overridden settings: {
'SPIDER_LOADER_WARN_ONLY': True}
2017-12-12 15:54:18 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.logstats.LogStats']
2017-12-12 15:54:18 [myspider_redis] INFO: Reading start URLs from redis key 'myspider:start_urls' (batch size: 110, encoding: utf-8
2017-12-12 15:54:18 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'redisClawerSlaver.middlewares.ProxiesMiddleware',
'redisClawerSlaver.middlewares.HeadersMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2017-12-12 15:54:18 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2017-12-12 15:54:18 [scrapy.middleware] INFO: Enabled item pipelines:
['redisClawerSlaver.pipelines.ExamplePipeline',
'scrapy_redis.pipelines.RedisPipeline']
2017-12-12 15:54:18 [scrapy.core.engine] INFO: Spider opened
2017-12-12 15:54:18 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2017-12-12 15:55:18 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2017-12-12 15:56:18 [scrapy.extension 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2416
2416

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









