







scrapy-redis分布式爬虫的搭建过程(代码篇)
1. 背景
- 关于环境搭建和理论部分请参考前面的文章:
- scrapy-redis分布式爬虫的搭建过程(理论篇):http://blog.csdn.net/zwq912318834/article/details/78854571
- redis数据库在windows下的安装,配置与使用:http://blog.csdn.net/zwq912318834/article/details/78770209
2. 环境
- 系统:win7
- scrapy-redis
- redis 3.0.5
- python 3.6.1
3. 代码结构
3.1. 主机分布。
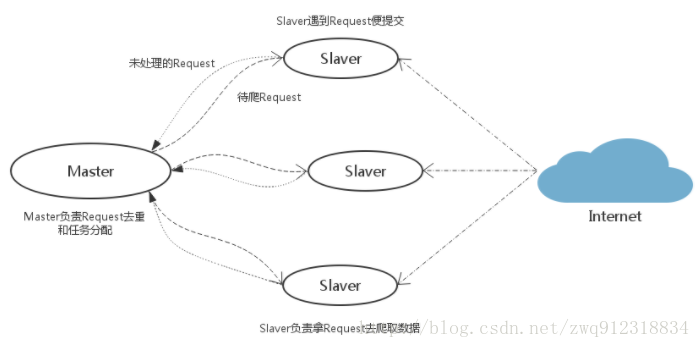
3.2. Master机器。
3.3. Slaver机器。
4. 执行步骤
- 第一步:在slaver端的爬虫中,指定好 redis_key,并指定好redis数据库的地址,比如:
class MySpider(RedisSpider):
"""Spider that reads urls from redis queue (myspider:st 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









