







使用BloomFilter优化scrapy-redis去重
1. 背景
- 做爬虫的都知道,scrapy是一个非常好用的爬虫框架,但是scrapy吃内存非常的厉害。其中有个很关键的点就在于去重。
- “去重”需要考虑三个问题:去重的速度和去重的数据量大小,以及持久化存储来保证爬虫能够续爬。
- 去重的速度:为了保证较高的去重速度,一般是将去重放到内存中来做的。例如python内置的set( ),redis的set数据结构。但是当数据量变得非常大,达到千万级亿级时,因为内存有限,就需要用“位”来去重了, 因此BloomFilter应运而生,将去重工作由字符串直接转到bit位上,大大降低了内存占有率。
- 去重的数据量大小:当数据量较大时,我们可以使用不同的加密算法,压缩算法(例如md5,hash)等,将长字符串压缩成16/32 长度的短字符串。然后再使用set等方式来去重。
- 持久化存储:scrapy默认是开启去重的,而且提供了续爬设计,在爬虫终止时,会记录一个状态文件记录爬取过的request和状态。scrapy-redis的去重工作交给了redis,去重队列放到了redis中,而redis可以提供持久化存储。Bloomfilter是将去重对象映射到几个内存“位”,通过几个位的 0/1值来判断一个对象是否已经存在。Bloomfilter运行在一台机器的内存上,并不方便持久化,爬虫一旦终止,数据就丢失了。
- 如上所述,对于scrapy-redis分布式爬虫来说,使用Bloomfilter来优化,必然会遇到两个问题:
- 第一,要想办法让Bloomfilter能持久化存储下来。
- 第二,对于scrapy-redis分布式爬虫来说,爬虫分布在好几台不同的机器上。而Bloomfilter是基于内存的,如何让各个不同的爬虫机器能够共享到同一个Bloomfilter,来达到统一去重?
- 综上所述,将Bloomfilter挂载到redis上,持久化存储以及让各爬虫共享去重队列,这两个问题就都解决了。
2. 环境
- 系统:win7
- scrapy-redis
- redis 3.0.5
- python 3.6.1
3. Bloom Filter基本概念以及原理
- 详情请参考文章:http://blog.csdn.net/jiaomeng/article/details/1495500
简单来说,Bloom Filter是:
- Bloom Filter 是一种空间效率很高的随机数据结构,利用位数组表示一个集合,并能判断一个元素是否属于这个集合。
- Bloom Filter的这种高效是有一定代价的:在判断一个元素是否属于某个集合时,有可能会把不属于这个集合的元素误认为属于这个集合(false positive)。当然,如果这个元素属于这个集合,是一定不会被误判为不存在这个集合。
- Bloom Filter不适合那些“0错误”的应用场合。
为了能理解Bloom Filter的原理,必须熟悉以下几个基本元素的概念:
3.1. Bloom Filter位数组
- Bloom Filter是用位数组表示集合的。初始状态时,Bloom Filter是一个包含m位的位数组 { 1, …, m },每一位都置为0。表现形式可以是一段空白的内存,长字符串,任意一种占用内存空间的数据结构……

3.2. 待去重元素
- 对爬虫来说,也就是request队列,我们记为 S = { R1, R2, …, Rn } 这样一个n个元素的集合。
3.3. k个相互独立的哈希函数
- Bloom Filter使用k个相互独立的哈希函数,我们记为 H = { H1( ), H2( ), …, Hk( ) }。利用这些hash函数,对集合S = { R1, R2, …, Rn } 中的每个元素进行处理,映射到Bloom Filter开辟内存{ 1, …, m }的某一位上。这样,对于R1来说,映射的结果就是{ H1( R1 ), H2( R1 ), …, Hk( R1 ) }
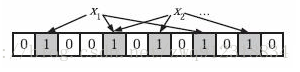
- 需要注意的是,如果一个位置多次被置为1,那么只有第一次会起作用,后面几次将没有任何效果。
从这一点就可以看出为什么会有误判,有可能会把不属于这个集合的元素误认为属于这个集合,就是因为这个元素被映射后的集合上那些位上,可能已经被置成1了。
3.4. 错误率
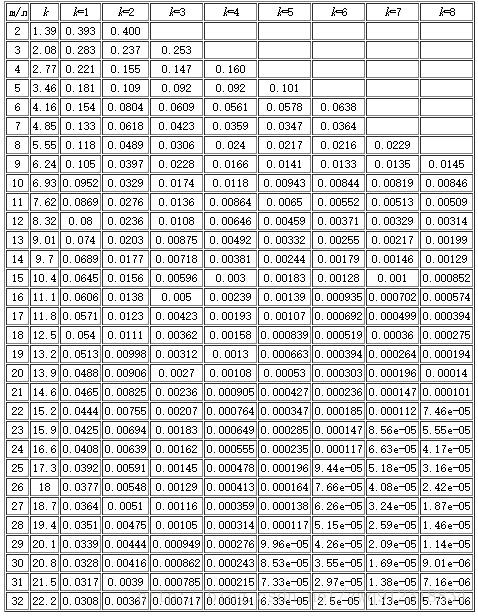
- Bloomfilter算法会有漏失概率,即不存在的字符串有一定概率被误判为已经存在。这个概率的大小与seeds的数量、申请的内存大小、去重对象的数量有关。下面有一张表,m表示内存大小(多少个位),n表示去重对象的数量,k表示seed的个数。例如我代码中申请了256M,即1<<31(m=2^31,约21.5亿),seed设置了7个。看k=7那一列,当漏失率为8.56e-05时,m/n值为23。所以n = 21.5/23 = 0.93(亿),表示漏失概率为8.56e-05时,256M内存可满足0.93亿条字符串的去重。同理当漏失率为0.000112时,256M内存可满足0.98亿条字符串的去重。
4. redis的setbit功能
4.1. 官方说明
# SETBIT key offset value :设置或清除该位在存储在键的字符串值偏移
对 key 所储存的字符串值,设置或清除指定偏移量上的位(bit)。
位的设置或清除取决于 value 参数,可以是 0 也可以是 1 。
当 key 不存在时,自动生成一个新的字符串值。
字符串会进行伸展(grown)以确保它可以将 value 保存在指定的偏移量上。当字符串值进行伸展时,空白位置以 0 填充。
offset 参数必须大于或等于 0 ,小于 2^32 (bit 映射被限制在 512 MB 之内)。4.2. 使用案例
在redis中,字符串都是以二级制的形式进行存储的。
第一步:设置一个 key-value ,字符串 testStr = ‘ab’
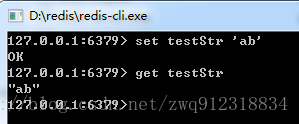
我们知道 ‘a’ 的ASCII码是 97, 转换为二进制是:01100001
‘b’的的ASCII码是 98,转换为二进制是:01100010。
‘ab’转换成二进制就是:0110000101100010
第二步:设置偏移
offset代表偏移,从0开始,从左往右计数的,也就是从高位往低位 。
比如我们想将 011000010110001 0 (ab)置成 011000010110001 1(ac) ,也就是将第15位由0置成1,此时b变成了c
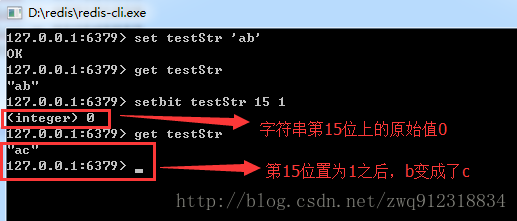
setbit完之后,会有有一个(integer) 0或者(integer)1的返回值,这个是在进行setbit 之前,该offset位的比特值。
这就是redis 中 “SETBIT” 的基本用法。
redis还有一个与此相关的功能:bitcount,就是统计字符串的二级制编码中有多少个’1’。 所以这里
bitcount testStr 得到的结果就是 7

5. 详细部署
- 结合上面Bloom Filter和redis的setbit功能,我们就知道如何将Bloom Filter挂载在redis上了。没错,就是一个大的字符串!
- 下面是在scrapy-redis分布式爬虫中挂入Bloom Filter的详细步骤:
5.1. 编写Bloom Filter算法。
# 文件:Bloomfilter.py
# encoding=utf-8
import redis
from hashlib import md5
# 根据 开辟内存大小 和 种子,生成不同的hash函数
# 也就是构造上述提到的:Bloom Filter使用k个相互独立的哈希函数,我们记为 **H = { H1( ), H2( ), ..., Hk( ) }**
class SimpleHash 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1485
1485











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









