







缘由
主要参考了博客:
- 笔试面试(1)腾讯2014校园招聘软件开发类笔试试题
- 我的解法是我自己做的,不表示正确答案。
- 考试时长:120分钟
不定项选择题
(共25题,每题4分,共100分,少选、错选、多选均不得分)
第一题
1 已知一棵二叉树,如果先序遍历的节点顺序是:ADCEFGHB,中序遍历是:CDFEGHAB,则后序遍历结果为:()A.CFHGEBDA B.CDFEGHBA C.FGHCDEBA D.CFHGEDBA
参考解答:
解析:由先序遍历序列和中序遍历序列可以唯一确定树的结构步骤: 由先序序列确定根节点;按根节点把中序序列分为两端,前面的是左子树,后面的是右子树;对左右子树重复前面的步骤

后续遍历序列:CFHGEDBA
答案选 D
我的解答:
先序遍历:根、左、右中序:左、根、右
后序:左、右、根
显然可以画出具体的全部的排序,但是这样解题速度慢,所以我决定采用一些技巧。首先可以知道先序的A在最前面,所以根肯定是A,而中序以AB结尾。所以后序的肯定以BA相连,并且在最后面,所以排除A。
对于左子树,先序:DCEFGH。中序:CDFEGH。D肯定是左子树的根,C是左子树的左孩子。所以我想肯定C肯定是后序的开头。所以选D。
第二题
2 下列哪两个数据结构,同时具有较高的查找和删除性能?()A.有序数组 B.有序链表 C.AVL树 D.Hash表
参考解答
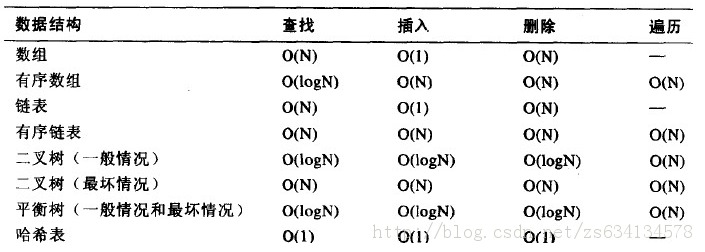
由上图可见,平衡二叉树的查找,插入和删除性能都是O(logN),其中查找和删除性能较好;哈希表的查找、插入和删除性能都是O(1),都是最好的。
答案:CD
我的解答
排除法。可以知道选CD。因为数组在删除的时候需要移动的数组元素。而有序链表在查找的时候需要遍历。AVL是自平衡二叉查找树,而红黑树就一种自平衡二叉查找树。Hash表就不说了。
第三题
3 下列排序算法中,哪些时间复杂度不会超过nlogn?()A.快速排序 B.堆排序 C.归并排序 D.冒泡排序
参考解答
几种常见的排序算法对比: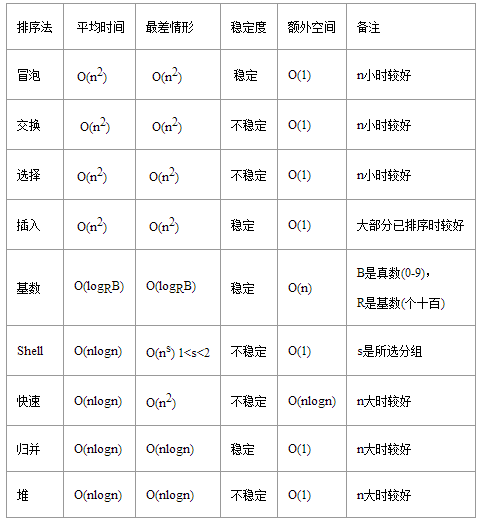
稳定的排序:冒泡,插入,基数,归并
答案:BC
我的解答
BC,因为快速排序在最坏的情况的时间复杂度是n^2,而冒泡排序的时间复杂度无论在什么情况下都是n^2。
第四题
4 初始序列为1 8 6 2 5 4 7 3一组数采用堆排序,当建堆(小根堆)完毕时,堆所对应的二叉树中序遍历序列为:()A.8 3 2 5 1 6 4 7
B.3 2 8 5 1 4 6 7
C.3 8 2 5 1 6 7 4
D.8 2 3 5 1 4 7 6
参考解答
没有找到别人的答案,自己看了书之后做出来了,选A书中建大堆的过程

我的解答
过程

我的解答
建堆过程?我突然感觉不会了。那么我用排除法选B,因为A、D以8开头,这显然是不可能的,怎么最左的元素是8呢?而且C的3、8排序肯定也是不对的。但是B选项3、2、8也让我觉得不太对。第五题
5 当n=5时,下列函数的返回值是:()int foo(int n)
{
if(n<2)return n;
return foo(n-1)+foo(n-2);
}
A.5 B.7 C.8 D.10
参考解答
直接给了答案A。
我的解答
从1开始就好了。Foo(0)=0
Foo(1)=1
Foo(2)=1
Foo(3)=2
Foo(4)=3
Foo(5)=5
固选A。
第六题
6 S市A,B共有两个区,人口比例为3:5,据历史统计A的犯罪率为0.01%,B区为0.015%,现有一起新案件发生在S市,那么案件发生在A区的可能性有多大?()A.37.5% B.32.5% C.28.6% D.26.1%
参考解答
犯罪率可以理解为AB两区的犯罪人数与总人口数的比。由此不难列出下式:( 3*0.01% ) / ( 3*0.01% + 5*0.015% ) = 0.2587 = 28.6%
答案:C
我的解答
S市共有8千人,3000人在A区,5000人在B区,A区有罪犯3人,B区有7.5人。如果一起犯罪,那么在是这3个人中的一个的概率是:3/3+7.5 = 0.286.所以选C。第七题
7 Unix系统中,哪些可以用于进程间的通信?()A.Socket B.共享内存 C.消息队列 D.信号量
参考解答
(1)管道(Pipe):管道可用于具有亲缘关系进程间的通信,允许一个进程和另一个与它有共同祖先的进程之间进行通信。(2)命名管道(named pipe):命名管道克服了管道没有名字的限制,因此,除具有管道所具有的功能外,它还允许无亲缘关系进程间的通信。命名管道在文件系统中有对应的文件名。命名管道通过命令mkfifo或系统调用mkfifo来创建。
(3)信号(Signal):信号是比较复杂的通信方式,用于通知接受进程有某种事件发生,除了用于进程间通信外,进程还可以发送信号给进程本身;linux除了支持Unix早期信号语义函数sigal外,还支持语义符合Posix.1标准的信号函数sigaction(实际上,该函数是基于BSD的,BSD为了实现可靠信号机制,又能够统一对外接口,用sigaction函数重新实现了signal函数)。
(4)消息(Message)队列:消息队列是消息的链接表,包括Posix消息队列system V消息队列。有足够权限的进程可以向队列中添加消息,被赋予读权限的进程则可以读走队列中的消息。消息队列克服了信号承载信息量少,管道只能承载无格式字节流以及缓冲区大小受限等缺
(5)共享内存:使得多个进程可以访问同一块内存空间,是最快的可用IPC形式。是针对其他通信机制运行效率较低而设计的。往往与其它通信机制,如信号量结合使用,来达到进程间的同步及互斥。
(6)内存映射(mapped memory):内存映射允许任何多个进程间通信,每一个使用该机制的进程通过把一个共享的文件映射到自己的进程地址空间来实现它。
(7)信号量(semaphore):主要作为进程间以及同一进程不同线程之间的同步手段。
(8)套接口(Socket):更为一般的进程间通信机制,可用于不同机器之间的进程间通信。起初是由Unix系统的BSD分支开发出来的,但现在一般可以移植到其它类Unix系统上:Linux和System V的变种都支持套接字。
答案:ABCD
我的解答
ABD肯定可以,C我有点不确定。Unix里面有消息队列么?有点忘了。第八题
8 静态变量通常存储在进程哪个区?()A.栈区 B.堆区 C.全局区 D.代码区
参考解答
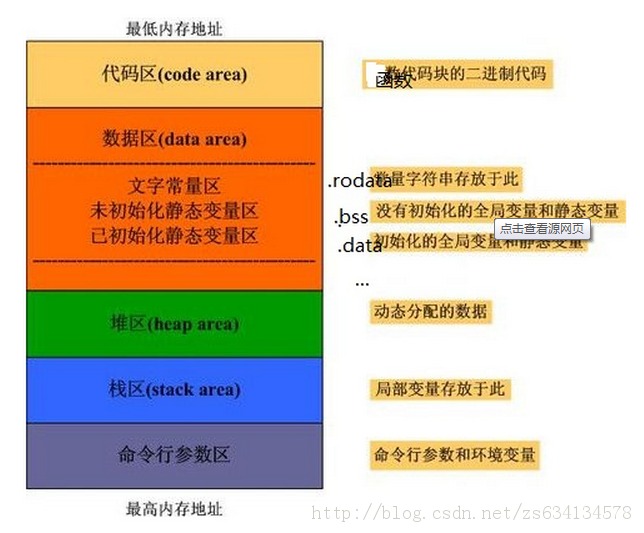
其中动态分配的数据是指:经常直到程序实际运行的时候,才知道某个数据结构的大小。在linux中,主要是用malloc和free函数来完成动态分配。用malloc分配的内存就是从堆中取得。(摘自 深入理解计算机系统)
答案:C
我的解答
显然B区。另外有全局区这样的说法?
第九题
9 查询性能()A. 在Name字段上添加主键
B. 在Name字段上添加索引
C. 在Age字段上添加主键
D. 在Age字段上添加索引
这题应该是问:为了提高查询性能,可以()。
别人的解答
索引:对数据库表中一列或多列的值进行排序(或构成特定的数据结构,如树或哈希表)的一种结构,使用索引可快速访问数据库表中的特定信息。优点:
- 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性
- 可以大大加快数据的检索速度
- 可以加快表与表之间的连接
- 使用分组和排序子句进行检索时,同样可以显著减少查询中分组和排序的事件
- 在查询的过程中优化隐藏器,提高系统的性能
- 创建和维护所以你需要耗费时间
- 索引需要占物理空间,如果建立聚簇索引,需要的空间更大
- 表的数据更新时,索引也要动态的维护
- 表的主键、外键必须有索引;
- 数据量超过300的表应该有索引;
- 经常与其他表进行连接的表,在连接字段上应该建立索引;
- 经常出现在Where子句中的字段,特别是大表的字段,应该建立索引;
- 索引应该建在选择性高的字段上;
- 索引应该建在小字段上,对于大的文本字段甚至超长字段,不要建索引;
- 复合索引的建立需要进行仔细分析;尽量考虑用单字段索引代替:
- 正确选择复合索引中的主列字段,一般是选择性较好的字段;
- 复合索引的几个字段是否经常同时以AND方式出现在Where子句中?单字段查询是否极少甚至没有?如果是,则可以建立复合索引;否则考虑单字段索引;
- 如果复合索引中包含的字段经常单独出现在Where子句中,则分解为多个单字段索引;
- 如果复合索引所包含的字段超过3个,那么仔细考虑其必要性,考虑减少复合的字段;
- 如果既有单字段索引,又有这几个字段上的复合索引,一般可以删除复合索引;
- 频繁进行数据操作的表,不要建立太多的索引;
- 删除无用的索引,避免对执行计划造成负面影响;
我的总结
索引是对数据库表中一个或多个列(例如,employee 表的姓氏 (lname) 列)的值进行排序的结构。如果想按特定职员的姓来查找他或她,则与在表中搜索所有的行相比,索引有助于更快地获取信息。例如这样一个查询:select * from table1 where id=10000。如果没有索引,必须遍历整个表,直到ID等于10000的这一行被找到为止;有了索引之后(必须是在ID这一列上建立的索引),即可在索引中查找。由于索引是经过某种算法优化过的,因而查找次数要少的多的多。可见,索引是用来定位的。
如下图(SQL Server的B树结构)所示:

反正不可能是添加主键吧,主键对性能的提升没有用。
我的解答
选B吧。我也不太知道是什么意思。感觉题目不太完整。第十题
10 IP地址131.153.12.71是一个()类IP地址。
A.A B.B C.C D.D
参考解答
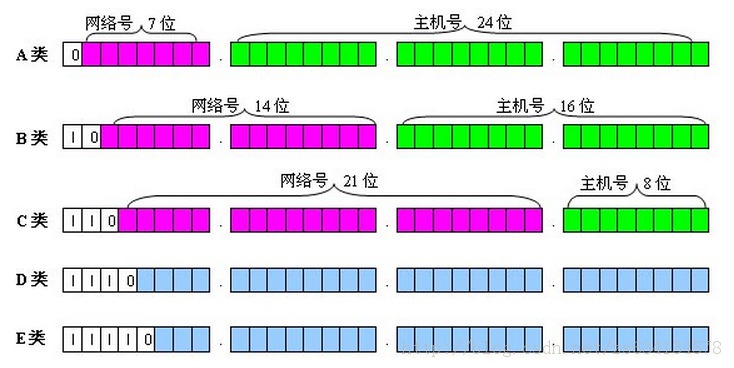
IP地址分类- A类网络的IP地址范围为1.0.0.1-127.255.255.254;
- B类网络的IP地址范围为:128.1.0.1-191.255.255.254;
- C类网络的IP地址范围为:192.0.1.1-223.255.255.254。
我的解答
好像A类是1-125。所以131我觉得是B类地址。第十一题
11 下推自动识别机的语言是:()A. 0型语言 B.1型语言 C.2型语言 D.3型语言
参考解答
在自动机理论中,下推自动机(Pushdown automaton)是使用了包含数据的栈的有限自动机。使用的语言为2型语言。
我的解答
不知道第十二题
12 下列程序的输出是:()#define add(a+b) a+b
int main()
{
printf(“%d\n”,5*add(3+4));
return 0;
}
A.23 B.35 C.16 D.19
参考解答
宏是完全的文本替换,宏替换时容易犯的错误。使用宏时,带上括号是安全的做法。答案:D
我的解答
应该是19,因为5*3+4,这很显然是因为宏define是替换,而不是真正的计算。第十三题
13 浏览器访问某页面,HTTP协议返回状态码为403时表示:()A 找不到该页面
B 禁止访问
C 内部服务器访问
D 服务器繁忙
参考解答
- 找不到该页面:404
- 禁止访问:403
- 内部服务器访问:500
- 服务器繁忙:503

我的解答
我还做了网页了一段时间的网页开发,看样子只能说是A了。第十四题
14 如果某系统15*4=112成立,则系统采用的是()进制。A.6 B.7 C.8 D.9
参考解答
验证A需要注意的是,当选定六进制时,15,4 和112都应该为六进制。
15由六进制转为十进制为11,计算方法:1*6 + 5*1 = 11
同理:4转为十进制为4,112转为十进制为44
所以转换后的等式左边为 11*4, 右边为44。相等。
所以,答案为A。如果如何从别的进制转到十进制,比如二进制:
用二进制: 11101.010转为十进制表示 来举例:
整数部分 11101=2^4+2^3+2^2+0*2^1+1=33
分数部分 0.010=0.01=0/2^1+1/2^2=0+0.25=0.25
结果是 33+0.25=33.25
那么六进制的112的十进制应该是:1*6^2+1*6^1+2*6^0 = 44
我的解答
15+15+15+15如果是6进制:34+15+15 –>53+15=112
一算第一个就正确了。运气不错。注意大于6的对应数字关系。当然要进位。
6->0 7->1 8->2 9->3 10->4 11->5 12->0
第十五题
15 某段文本中各个字母出现的频率分别是{a:4,b:3,o:12,h:7,i:10},使用哈夫曼编码,则哪种是可能的编码:()A a(000) b(001) h(01) i(10) o(11)
B a(0000) b(0001) h(001) o(01) i(1)
C a(000) b(001) h(01) i(10) o(00)
D a(0000) b(0001) h(001) o(000) i(1)
参考解答
没有什么意义我的总结
这道题肯定是用排除法无疑。因为题中已经说的很清楚可能的编码是什么。所以答案肯定是不唯一。我所以必须找出不对的另外三个。B:我认为是违反了哈弗曼编码希望编码越来越短的原则,因为频率最高的是o,但是o居然需要两个数来表示,比起频率低的i却需要一个数字,这是必定错误的地方。
C:因为o(00)和a(000)容易造成混淆。00001 是表示 000 01 还是 00 001 呢?前一个表示 ai,后一个表示ob。
D:和C一样。
下面是哈弗曼编码的过程:
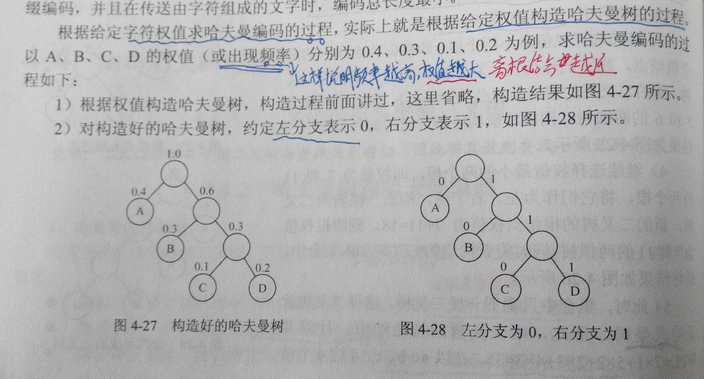

还有我画的选项A的哈夫曼树:
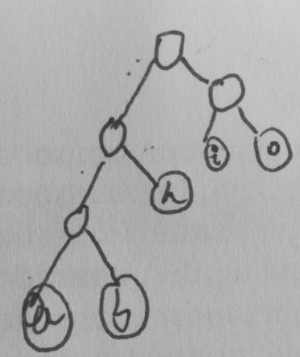
我的解答
考研的时候复习过,依稀记得。好像该题可以用排除法。A就行。很显然C不行,因为o(00)和a(000)容易造成混淆。B好像是因为太长了。D和C的原因一样。第十六题
16 TCP和IP分别对应了OSI中的哪几层?()A Application layer
B Presentation layer
C Transport layer
D Network layer
参考解答
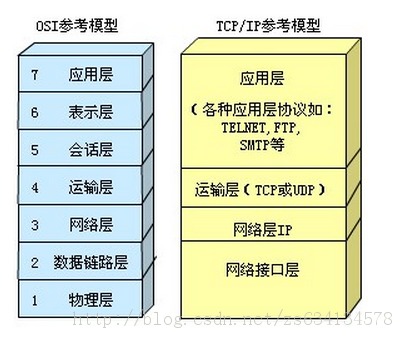
我的解答
直觉传输层。选C第十七题
17 一个栈的入栈序列是A,B,C,D,E,则栈的不可能的输出序列是?()A.EDCBA B.DECBA C.DCEAB D.ABCDE
我的解答
选C。因为此时A不可能比B先出,而D选项中,A在B前面的原因是因为A进栈就出来了。第十八题
18 同一进程下的线程可以共享以下?()A. stack B.data section C.register set D.file fd
参考解答
线程共享的内容包括:- 进程代码段
- 进程的公有数据(利用这些共享的数据,线程很容易的实现相互之间的通讯)、
- 进程打开的文件描述符、
- 信号的处理器、
- 进程的当前目录和
- 进程用户ID与进程组ID
- 线程ID
- 寄存器组的值(register set)
- 线程的堆栈
- 错误返回码
- 线程的信号屏蔽码
我的解答
选个BD。A太夸张了。C不知道是什么东西。第十九题
19 对于派生类的构造函数,在定义对象时构造函数的执行顺序为?()1:成员对象的构造函数
2:基类的构造函数
3:派生类本身的构造函数
A.123 B.231 C.321 D.213
参考解答
当派生类中不含对象成员时- 在创建派生类对象时,构造函数的执行顺序是:基类的构造函数→派生类的构造函数;
- 在撤消派生类对象时,析构函数的执行顺序是:派生类的构造函数→基类的构造函数。
- 在定义派生类对象时,构造函数的执行顺序:基类的构造函数→对象成员的构造函数→派生类的构造函数;
- 在撤消派生类对象时,析构函数的执行顺序:派生类的构造函数→对象成员的构造函数→基类的构造函数。
我的解答
直觉B第二十题
20 如何减少换页错误?()A 进程倾向于占用CPU
B 访问局部性(locality of reference)满足进程要求
C 进程倾向于占用I/O
D 使用基于最短剩余时间(shortest remaining time)的调度机制
参考解答
参考一下:如何减少换页错误?答案:BD
我的总结
其实选D我还是有点印象的:就是这个B:实际上就说是访问局部性,也就是程序的局部性原理,即程序的地址访问流有很强的时序相关性,未来的访问模式与最近已发生的访问模式相似。根据这一局部性原理,把主存储器中访问概率最高的内容存放在Cache中,当CPU需要读取数据时就首先在Cache中查找是否有所需内容,如果有则直接从Cache中读取;若没有再从主存中读取该数据,然后同时送往CPU和Cache。
关键就是说如果进程满足了局部性的要求,那么在一定的时间和空间内都是由这个进程来占用内存和cpu,那么肯定减少了换页错误(在一定时间内没有别的进程来干扰)。
我的解答
有点晕,选D第二十一题
21 递归函数最终会结束,那么这个函数一定?()A 使用了局部变量
B 有一个分支不调用自身
C 使用了全局变量或者使用了一个或多个参数
D 没有循环调用
参考答案
直接排除AD,注意力集中在B和C。B肯定是对的,只有一次循环满足某个条件,不调用自己就返回,递归才会一层一层向上返回。
那么C呢,想一下,全局变量和参数确实可以用来控制递归的结束与否。
该不该选C呢?再仔细看一下题目(说实话,我很讨厌这种文字游戏),“这个函数一定...“,所以,问题集中在,是否是一定会使用这两种方式呢?
显然不是的。除了C中提到的两种情况外,还有如下控制递归的方式:
局部静态变量是可以控制递归函数最终结束的
可能通过异常来控制递归的结束。
可以利用BIOS或OS的一些数据或一些标准库的全局值来控制递归过程的终止。
可以把一些数据写入到BIOS或OS的系统数据区,也可以把数据写入到一个文件中,以此来控制递归函数的终止。
所以,答案为B
我的解答
B不是一定,而C是一定的。不然真的没法结束了。第二十二题
22 编译过程中,语法分析器的任务是()A分析单词是怎样构成的
B 分析单词串是如何构成语言和说明的
C 分析语句和说明是如何构成程序的
D 分析程序的结构
参考答案
语法分析器(Parser)通常是作为编译器或解释器的组件出现的,它的作用是进行语法检查、并构建由输入的单词组成的数据结构(一般是语法分析树、抽象语法树等层次化的数据结构)。我的总结
其实我做的时候应该深入的猜一下的。因为:
A:显然不可能,因为从二十六个字母的角度分析如何形成单词?
C:太大的了,和语法无关
D:更大了,和语法无关。
我的解答
不用猜了,完全不知道了。第二十三题
23 同步机制应该遵循哪些基本准则?()A.空闲让进 B.忙则等待 C.有限等待 D.让权等待
参考答案
同步机制应该遵循的基本准则- 空闲让进:当无进程处于临界区时,表明临界资源处于空闲状态,允许一个请求进入临界区的进程立即进入临界区,以有效利用临界资源
- 忙则等待:当已有进程处于临界区时,表明临界资源正在被访问,因而其他试图进入临界区的进程必须等待,以保证对临界资源的互斥访问
- 有限等待:对要求访问临界资源的进程,应保证在有限时间内能进入自己的临界区,以免陷入“死等”状态
- 让权等待:当进程不能进入自己的临界区时,应立即释放处理机,以免进程陷入“忙等”状态
我的解答
ABCD全选依稀记得。第二十四题
24 进程进入等待状态有哪几种方式?()A CPU调度给优先级更高的线程
B 阻塞的线程获得资源或者信号
C 在时间片轮转的情况下,如果时间片到了
D 获得spinlock未果
参考解答
等待状态应该是我们说的阻塞态,因为一般阻塞态是在等待某一触发时间的发生,才能进入就绪状态。spinlock就是一种锁。
所以答案:D
我的总结
由于该题所谓的“等待状态”应该还是有歧义的,因为我们只知道 运行、就绪、阻塞状态,而且这个三个状态很好的和英文单词相对应:running、ready、blocked我的解答
选择AC。B应该是不会的,只会让阻塞的线程进准备状态。第二十五题
25 设计模式中,属于结构型模式的有哪些?()A 状态模式 B 装饰模式 C 代理模式 D 观察者模式
参考答案
创建型模式前面讲过,社会化的分工越来越细,自然在软件设计方面也是如此,因此对象的创建和对象的使用分开也就成为了必然趋势。因为对象的创建会消耗掉系统的很多资源,所以单独对对象的创建进行研究,从而能够高效地创建对象就是创建型模式要探讨的问题。这里有6个具体的创建型模式可供研究,它们分别是:
- 简单工厂模式(Simple Factory);
- 工厂方法模式(Factory Method);
- 抽象工厂模式(Abstract Factory);
- 创建者模式(Builder);
- 原型模式(Prototype);
- 单例模式(Singleton)。
说明:严格来说,简单工厂模式不是GoF总结出来的23种设计模式之一。
在解决了对象的创建问题之后,对象的组成以及对象之间的依赖关系就成了开发人员关注的焦点,因为如何设计对象的结构、继承和依赖关系会影响到后续程序的维护性、代码的健壮性、耦合性等。对象结构的设计很容易体现出设计人员水平的高低,这里有7个具体的结构型模式可供研究,它们分别是:
- 外观模式(Facade);
- 适配器模式(Adapter);
- 代理模式(Proxy);
- 装饰模式(Decorator);
- 桥模式(Bridge);
- 组合模式(Composite);
- 享元模式(Flyweight)。
行为型模式
在对象的结构和对象的创建问题都解决了之后,就剩下对象的行为问题了,如果对象的行为设计的好,那么对象的行为就会更清晰,它们之间的协作效率就会提高,这里有11个具体的行为型模式可供研究,它们分别是:- 模板方法模式(Template Method);
- 观察者模式(Observer);
- 状态模式(State);
- 策略模式(Strategy);
- 职责链模式(Chain of Responsibility);
- 命令模式(Command);
- 访问者模式(Visitor);
- 调停者模式(Mediator);
- 备忘录模式(Memento);
- 迭代器模式(Iterator);
- 解释器模式(Interpreter)。
我的解答
不知道!居然学了那么久的设计模式。哎。。没想到这一点会单独出题。填空题
(共4题10个空,每空2分,共20 分)
第一题
1 设有字母序列{Q,D,F,X,A,P,N,B,Y,M,C,W},请写出按二路归并方法对该序列进行一趟扫描后的结果为 。我的总结
我晕,我居然把希尔和二路归并记混了。归并就是相连的两个先排序,而希尔是跳着来的。所以我很快的写出了答案:DQFXAPBNMYCW
我的解答
记不得归并算法了。第二题
2 关键码序列(Q,H,C,Y,Q,A,M,S,R,D,F,X),要按照关键码值递增的次序进行排序,若采用初始步长为4的Shell的排序法,则一趟扫描的结果是 ;若采用以第一个元素为分界元素的快速排序法,则扫描一趟的结果是 。我的总结
重写希尔:1 2 3 4 5 6 7 8 9 10 11 12
Q,H,C,Y,Q,A,M,S,R, D, F, X
过程如下:
- 1-5-9:不变
- 2-6-10: Q,A,C,Y,Q,D,M,S,R, H, F, X
- 3-7-11: Q,A,C,Y,Q,D,F,S,R, H, M, X
- 4-8-12: Q,A,C,S,Q,D,F,X,R, H, M, Y
- 最终结果:Q,A,C,S,Q,D,F,X,R, H, M, Y


- 起始:Q,H,C,Y,Q,A,M,S,R, D, F, X
- 将第一个Q存入临时表示:F,H,C,Y,Q,A,M,S,R, D, , X
- F,H,C, ,Q,A,M,S,R, D, Y , X
- F,H,C,D ,Q,A,M,S,R, , Y , X
- F,H,C,D ,Q,A,M, ,R,S , Y , X
- 将放在临时变量内的Q放在最终位置:F,H,C,D ,Q,A,M, Q,R,S , Y , X
我的解答
Shell:Q,H,C,Y,Q,A,M,S,R,D,F,X
第一趟扫描结果:C,H,Q,Y,A,M,Q,R,D,F,R,X
快速排序:
Q,H,C,Y,Q,A,M,S,R,D,F,X
Q,H,C, F,Q,A,M,D,R,S,Y ,X
Q,H,C, F,Q,A,M,D,R,S,Y ,X
D,H,C, F,Q,A,M, Q ,R,S,Y ,X
所以第一轮排序结果:D,H,C, F,Q,A,M, Q ,R,S,Y ,X
第三题
3.二进制地址为011011110000,大小为(4)10和(16)10块的伙伴地址分别为:_________,_________。参考解答
地址011011110000,可以被2^(2+1)整除,所以伙伴地址是其下半部,加4就行,所以答案是011011110100;16大小时,不能被2^(4+1)整除,所以伙伴地址是其上半部,地址减去16,结果为0110 1110 0000。至于为什么这样整除决定,请查看伙伴地址定义。
我的解答
不懂伙伴地址第四题
4.设t是给定的一棵二叉树,下面的递归程序count(t)用于求得:二叉树t中具有非空的左,右两个儿子的结点个数N2;只有非空左儿子的个数NL;只有非空右儿子的结点个数NR和叶子结点个数N0。N2、NL、NR、N0都是全局量,且在调用count(t)之前都置为0。请填写算法中得空白处,完成其功能。 typedef struct node
{int data; struct node *lchild,*rchild;}node;
int N2,NL,NR,N0;
void count(node *t)
{
if (t->lchild!=NULL)
if (1)___ N2++;
else NL++;
else if (2)___ NR++; else (3)__
if(t->lchild!=NULL)(4)____; if (t->rchild!=NULL) (5)____; }参考解答
typedef struct node
{
int data;
struct node *lchild,*rchild;
}node;
int N2,NL,NR,N0;
void count(node *t)
{
if (t->lchild!=NULL)
if (t->rchild!=NULL) N2++;
else NL++;
else if (t->rchild!=NULL) NR++;
else N0++;
if(t->lchild!=NULL) count(t->lchild);
if(t->rchild!=NULL) count(t->rchild);
}/* call form :if(t!=NULL) count(t);*/
(1): (t->rchild!=NULL)
(2):(t->rchild!=NULL)
(3):N0++
(4): count(t->lchild)
(5): count(t-> rchild) 其他方向简答题
(共2题,每题20分),选作题,不计入总分)
第一题
1 请设计一个排队系统,能够让每个进入队伍的用户都能看到自己在队列中所处的位置和变化,队伍可能随时有人加入和退出;当有人退出影响到用户的位置排名时需要及时反馈到用户。参考我的另一篇博客:http://blog.csdn.net/zy825316/article/details/33727855
第二题
2、A,B两个整数集合,设计一个算法求他们的交集,尽可能的高效。参考我的另一篇博客: 求两个整数集合的交集(Java代码,索引法)
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









