







 本文介绍了如何运用Jaccard系数计算歌曲相似度,通过分析和对比不同方法,探讨了其在音乐推荐系统中的适用性。在实践中遇到的问题包括数据存储、分析以及数据库操作效率等,提出了一种改进策略,即先找到相似用户,再推荐他们收藏的独特歌曲。
本文介绍了如何运用Jaccard系数计算歌曲相似度,通过分析和对比不同方法,探讨了其在音乐推荐系统中的适用性。在实践中遇到的问题包括数据存储、分析以及数据库操作效率等,提出了一种改进策略,即先找到相似用户,再推荐他们收藏的独特歌曲。
什么是Jaccard系数
其公式如下:
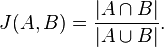
可以看出,其含义是集合A、B中相同的个数,除以A与B交集个数。可以看出,Jaccard系统主要关注的是元素是的个体是否相同,而不能用数值具体表示其差异。从这个意义上讲,我认为适合我的音乐,音乐推荐中计算相似度的过程。因为,我确定两个用户是否相似就是判断这两个用户是否收藏了相同的歌曲。
举例:
A=[shirt,shoes,pants,socks]
B=[shirt,shirt,shoes]
个人认为,这里我们是将其作为集合来看的话,由于集合的互异性,所以B改为:B=[shirt,shoes]
交集:2
并集:4
Jaccard系数为2/4=0.5
可以看出,其含义是集合A、B中相同的个数,除以A与B交集个数。可以看出,Jaccard系统主要关注的是元素是的个体是否相同,而不能用数值具体表示其差异。从这个意义上讲,我认为适合我的音乐,音乐推荐中计算相似度的过程。因为,我确定两个用户是否相似就是判断这两个用户是否收藏了相同的歌曲。
举例:
A=[shirt,shoes,pants,socks]
B=[shirt,shirt,shoes]
个人认为,这里我们是将其作为集合来看的话,由于集合的互异性,所以B改为:B=[shirt,shoes]
交集:2
并集:4
Jaccard系数为2/4=0.5
- 更多内容请看,我之前总结的博客:相似度计算方式的总结:java或python实现代码
java代码
之前只是总结Jaccard系数的python代码,这次我打算总结写出其java代码,并使用java计算,我相信计算速度会快很多。一个简单的计算Jaccard系数的代码如下:
/**
* 计算jaccard系数
* @param userIds1 List是收藏了某一首歌曲用户id集合,是int类型
* @param userIds2 List是收藏了另一首歌曲用户id集合,是int类型
* @return
*/
private static float jaccard(List userIds1, List userIds2) {
float intersectionNum=0;//等下计算Jaccard的时候我们需要产生小数,所以这里直接设置为float算了
Iterator it1 = userIds1.iterator();
Iterator it2 = userIds2.iterator();
while(it1.hasNext()){
int userId1=(int) it1.next();
while(it2.hasNext()){
int userId2=(int) it2.next();
if(userId1==userId2){
intersectionNum++;
}
}
}
float Jaccard=intersectionNum/(userIds1.size()+userIds2.size()-intersectionNum);
return Jaccard;
}哪些歌曲
是由被用户收藏数最多的10000首歌曲。也就是我们数据库中:mostsmallfavorites表内的歌曲。具体来历请看:利用协同过滤算法:计算歌曲相似度
看一下其sql语句能想起很多,如下所示:
CREATE TABLE mostsmallFavorites SELECT *
FROM (
SELECT *
FROM moresmallfavorites, (
SELECT userid AS uid
FROM moresmallfavorites
GROUP BY userid
HAVING COUNT( userid ) >80
AND COUNT( userid ) <500
)a
WHERE moresmallfavorites.userid = a.uid
)b 执行
思路非常简单,无非就是
- 读取所有歌曲id
- 找到每一个歌曲的收藏用户
- 计算某一个歌曲与其他歌曲的相似度
- 相似度排序
- 取出前10位
- 插入数据库
也是使用了一些机制,包括hastable、arraylist这样的容器,具体代码请看源代码。
结果的存储、分析
存储
对于每一首歌曲,我们将保留10首与其相似度最高的歌曲ID和相似度(用0-1之间的数来表示)。结果将会插入到一个表中,我取名为:simmusicjaccard。格式与simmusic一模一样。
sql语句如下:
CREATE TABLE simmusicjaccard(
id INT NOT NULL AUTO_INCREMENT PRIMARY KEY ,
musicid INT,
simmusicid INT,
similarity FLOAT
)分析结果
非常令人震撼,结果单单从相似度的数值的角度来看,非常差,而且这个结果都快到了没有用的地步了,我随机抽查了一个歌曲,找到了其相似度最高和最低的歌曲,进行观察:选择一首歌曲,看其相似度的10首歌曲
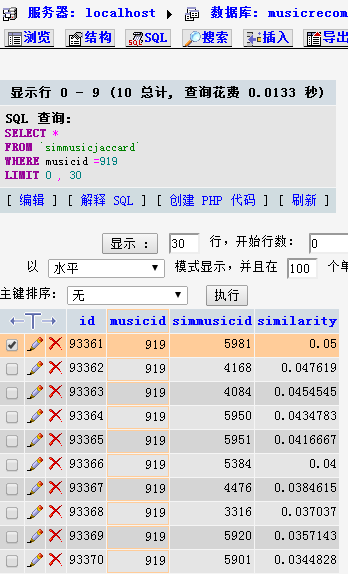
查看其该歌的收藏用户列表:
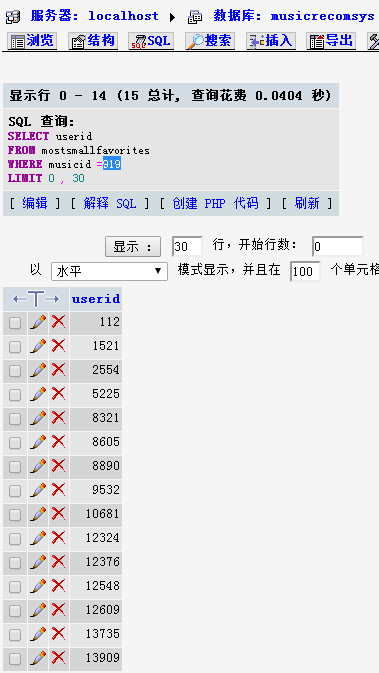
查看与其最相似度的歌曲的用户列表:
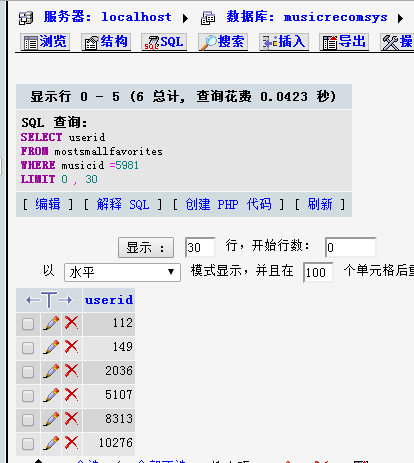
查看与相似度最低的歌曲的用户列表:
有以下现象:
- 无论是相似度最高还是最低的歌曲,都只有一两个用户重合了
- 相似度高的歌曲之所以高,是因为那首歌的用户列表数量少
我认为很
失败。
失败原因
歌曲有一万首,而用户只有1881位(为什么请看mostsmallfavorites的来历):歌曲很显然对于一首歌而言,收藏的其的用户本来就非常少。当计算两首歌的相似度,比较这两首歌的收藏用户时,就会更少。所以才会出现,计算相似度最高的两首歌,他们的用户重合度也只是1首而已。我觉得这个方式根本不适合用来计算歌曲相似度,反而非常适合用于计算用户相似度。因为用户收藏的歌曲非常多,所以产生的歌曲的重合度也想对比较高。
由此,我产生了另一个推荐引擎的思路:
- 给某一个目标用户推荐时,先使用Jaccar
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 178
178

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









