







文章目录
1.快乐数

- 就分别取出这个数的每一个位,对其进行平方就好了。
- 如果它变成了1就是快乐数,如果没变成1,就一定会出现循环,
- 那么用哈希表记录一下,如果出现循环就不是快乐数
bool isHappy(int n)
{
int tmp = n;
int map[10000] = {0};
while(tmp != 1)
{
int sum = 0;
while(tmp != 0)
{
sum += pow(tmp%10,2);
tmp /=10;
}
if(map[sum] == 1)
{
return false;
}
map[sum] = 1;
tmp = sum;
}
return true;
}
还有我发现一种投机取巧的办法,如果各位的平方和是4,也就会出现循环了?
这个样子也能过,不是很懂?有理解的麻烦评论一下。

2.错误的集合

- 用哈希表记录各自出现的次数
- 然后从1开始遍历,发现出现不止1次的就是重复的,发现出现0次的。
- 这俩都发现即可完成。
/**
* Note: The returned array must be malloced, assume caller calls free().
*/
int* findErrorNums(int* nums, int numsSize, int* returnSize)
{
int map[100000] = {0};
int i;
int* ans = (int*)malloc(sizeof(int) * 2);
*returnSize = 2;
for (i = 0; i < numsSize; i++)
{
map[nums[i]]++;
}
int flag1 = 0,flag2 = 0;
for (i = 1; i <= numsSize; i++)
{
if(flag1 && flag2)
{
break;
}
if(map[i] > 1)
{
ans[0] = i;
flag1 = 1;
}
if(map[i] == 0)
{
ans[1] = i;
flag2 = 1;
}
}
return ans;
}
3.数组的长度

- 首先构造三个哈表。
- 记录第一次出现时候的下标,记录出现多少次的下标,记录最后一次出现时的下标
- 在遍历第一遍数组的时候,就需要把这些东西全部记录下来。
- 那么去遍历哈希表的时候,去判断各自出现的次数,也就是该题目中出现度。
- 如果等于度,那么就去判断其的长度,是否小就好了。
- 最后返回那个长度即可。
int findShortestSubArray(int* nums, int numsSize)
{
int begin[50000] = {0}; //在begin中记录改数字第一次出现时候的位置(下标)
int map[50000] = {0}; //在map中记录该数字出现的次数
int end[50000] = {0}; //在end中记录该数字最后一次出现的位置
int i,minlen = numsSize,maxdegree = 0;
for (i = 0; i < 50000; i++)
{
begin[i] = -1;
end[i] = -1;
}
for (i = 0; i < numsSize; i++)
{
int num = nums[i];
if(begin[num] == -1)
{
begin[num] = i; //只记录刚开始第一次出现时候的下标
}
map[num]++; //记录次数
end[num] = i; //记录最后一次出现的次数
if(maxdegree < map[num])
{
maxdegree = map[num];
}
}
for (i = 0; i < 50000; i++)
{
//找到度的次数,可能重复,需要一直找
if(map[i] == maxdegree)
{
int len = end[i] - begin[i] + 1;
if(len < minlen)
{
minlen = len;
}
}
}
return minlen;
}
4.设计哈希集合

我这是使用的除留余数法继续计算,然后使用链地址法进行保存的。
就如下图,所有的数都膜上一个7,这里的数组大小最取一个质数。
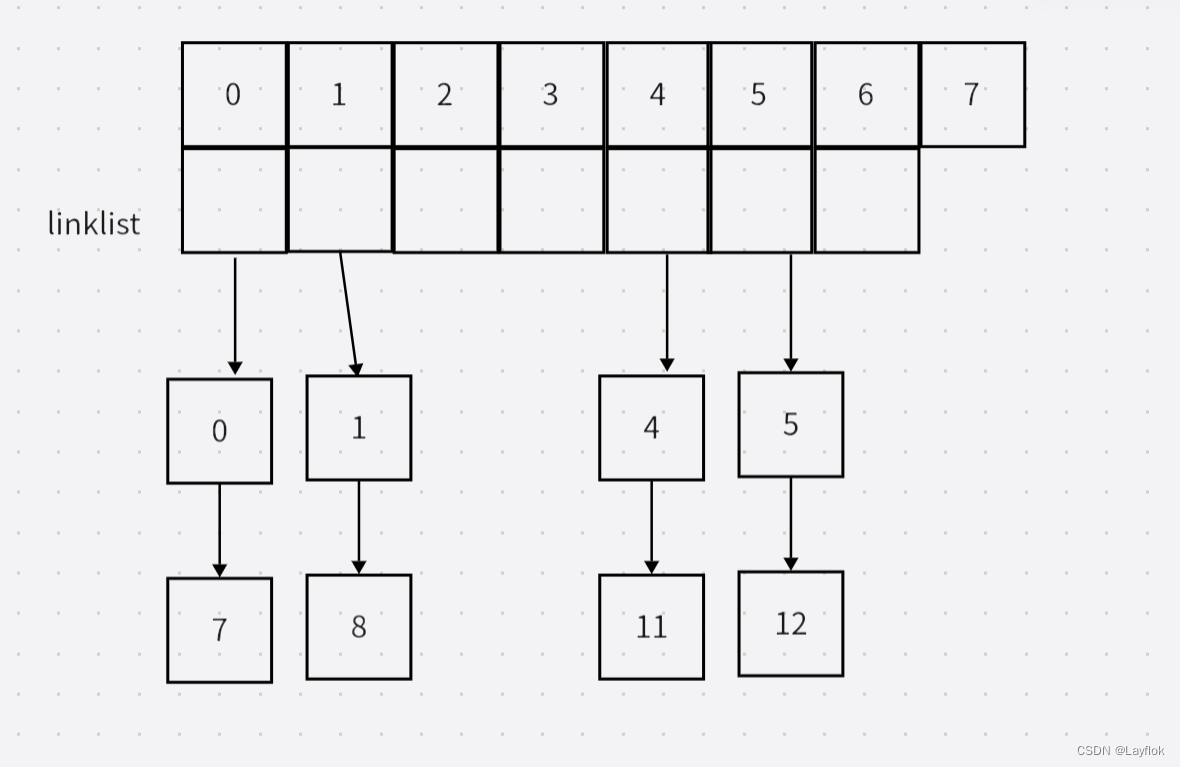
然后就是对数组和链表的操作了
#define MAX_SIZE 769
typedef struct Node
{
int key; //关键字
struct Node* next; //下一个关键字
}Node;
typedef struct
{
Node box[MAX_SIZE];
} MyHashSet;
bool myHashSetContains(MyHashSet* obj, int key);
Node* BuyNode(int key)
{
Node* newnode = (Node*)malloc(sizeof(Node));
newnode -> key = key;
newnode -> next = NULL;
return newnode;
}
MyHashSet* myHashSetCreate()
{
MyHashSet* hash = (MyHashSet*)malloc(sizeof(MyHashSet));
int i;
for (i = 0; i < MAX_SIZE; i++)
{
hash -> box[i].next = NULL;
}
return hash;
}
void myHashSetAdd(MyHashSet* obj, int key)
{
//如果有则不插入
if(myHashSetContains(obj,key))
{
return;
}
int num = key % MAX_SIZE;
Node* newnode = BuyNode(key);
if(obj -> box[num].next == NULL)
{
obj -> box[num].next = newnode;
}
else
{
//头插
newnode -> next = obj -> box[num].next;
obj -> box[num].next = newnode;
}
}
void myHashSetRemove(MyHashSet* obj, int key)
{
int num = key % MAX_SIZE;
Node* cur = obj -> box[num].next;
Node* prev = NULL;
while(cur != NULL)
{
//找到了
if(cur -> key == key)
{
//头删
if(cur == obj -> box[num].next)
{
obj -> box[num].next = cur -> next;
}
else
{
prev -> next = cur -> next;
}
free(cur);
break;
}
prev = cur;
cur = cur -> next;
}
}
bool myHashSetContains(MyHashSet* obj, int key)
{
int num = key % MAX_SIZE;
Node* cur = obj -> box[num].next;
while(cur != NULL)
{
if(cur -> key == key)
{
return true;
}
cur = cur -> next;
}
return false;
}
5.设计哈希映射

这道题和上面刚刚做过的题一样,都是让你构造一个哈希表,我这里就不用上边用过的那种方式了。
我用的是直接定位法,然后开辟非常大的空间,以防止它有非常大的数。

这种方式其实在平时刷一些题的时候,直接就可以在函数中实现,去使用,建立一个数组就好了,但是缺点就是浪费的空间太大了。又因为这个在结构体中中定义,无法直接初始化 不能进行key[MAX_SIZE] = {0}; 这样的操作,所以在时间上也会很大。
#define MAX_SIZE 1000001
typedef struct
{
int key[MAX_SIZE]; //索引即关键字 数组中放的值即val
} MyHashMap;
MyHashMap* myHashMapCreate()
{
MyHashMap* hash = (MyHashMap*)malloc(sizeof(MyHashMap));
for (int i = 0; i < MAX_SIZE; i++)
{
hash -> key[i] = -1;
}
return hash;
}
void myHashMapPut(MyHashMap* obj, int key, int value)
{
if(key > MAX_SIZE)
{
printf("请重新设置哈希表的大小\n");
exit(-1);
}
obj -> key[key] = value;
}
int myHashMapGet(MyHashMap* obj, int key)
{
int val = obj -> key[key];
return val == -1 ? -1 : val;
}
void myHashMapRemove(MyHashMap* obj, int key)
{
// if(myHashMapGet(obj,key) == -1)
// {
// printf("表中没有改值\n");
// exit(-1);
// }
obj -> key[key] = -1;
}
6. 最短的补全单词

- 我们首先用哈希表记录一下所给字符串各个单词出现的次数。
- 然后去到单词数组中去挨个比较,那一个能满足哈希表中的次数,选出其中长度最短的即可。
char* shortestCompletingWord(char* licensePlate, char** words, int wordsSize)
{
//哈希表
int map[26] = {0};
int i,len = strlen(licensePlate);
//求出字符串各个字母出现的次数
for (i = 0; i < len; i++)
{
char ch = licensePlate[i];
if( (ch >= 'a' && ch <= 'z') || (ch >= 'A' && ch <= 'Z'))
{
ch = tolower(ch);
map[ch - 'a']++;
}
}
//去单词数组中挨个找
int minlen = 9999;
int index;
for (i = 0; i < wordsSize; i++)
{
int j = 0;
int curlen = strlen(words[i]);
int tmp[26] = {0};
for (j = 0; j < curlen; j++)
{
tmp[words[i][j] - 'a']++;
}
for (j = 0; j < 26; j++)
{
//如果字符串中的字符 比单词中的多,就意味着不可能
if(map[j] > tmp[j])
{
break;
}
}
//证明哈希表全部比完了
if(j == 26)
{
if(curlen < minlen)
{
minlen = curlen;
index = i;
}
}
}
return words[index];
}
7.宝石与石头

- 遍历一遍宝石,记录一下,那一个是宝石。
- 然后去石头数组里面去找,对应的哈希表直接查看。
- 如果是,那儿就++;
int numJewelsInStones(char* jewels, char* stones)
{
int map[52] ={0}; //(大小写的英文字母)
int i,len = strlen(jewels);
for (i = 0; i < len; i++)
{
char ch = jewels[i];
if(ch >= 'A' && ch <= 'Z')
{
map[ch - 'A']++;
}
else
{
map[ch - 'a' + 26]++;
}
}
//比较
int size = strlen(stones);
int ans = 0;
for (i = 0; i < size; i++)
{
char ch = stones[i];
if(ch >= 'A' && ch <= 'Z')
{
//是宝石
if(map[ch - 'A'] != 0)
{
ans++;
}
}
else
{
if(map[ch - 'a' + 26] != 0)
{
ans++;
}
}
}
return ans;
}
8.唯一的摩尔斯密码词

这道题其实不难,但是难在了C语言上。。。。它本身是没有哈希表的,所以所有的东西都得自己去构造。
- 第一步:创建一个哈希表,里面存放着26个字母所对应的摩斯密码。
- 第二步:创建一个数组,里面存放着原来单词所对应翻译过来的摩斯密码。
- 第三步:创建一个哈希表,这个哈希表是用来,记录第二个数组中出现多少次摩斯密码,从而判断有几种不一样的。
- 但是C那种现成的轮子,所以我是用数组记录它,就线性查找,如果没有,那么拷贝进去,如果有,那么就不拷贝了。
- 最后数组有多大,答案就是啥。
int uniqueMorseRepresentations(char** words, int wordsSize)
{
char** mose[26] = { ".-", "-...", "-.-.", "-..", ".", "..-.", "--.", "....", "..", ".---",
"-.-", ".-..", "--", "-.", "---", ".--.", "--.-", ".-.", "...", "-", "..-",
"...-", ".--", "-..-", "-.--", "--.." };
char** tmp = (char**)malloc(sizeof(char*) * wordsSize);
int i;
for (i = 0 ; i < wordsSize; i++)
{
//每一个单词,每一个字母的进行转译
int j,len = strlen(words[i]);
tmp[i] = (char*)malloc(sizeof(char) * MAX_SIZE);
tmp[i][0] = 0; //追加字符串必须有'\0'这个终止标志才可以追加
for (j = 0; j < len; j++)
{
strcat(tmp[i],mose[words[i][j] - 'a']);
}
}
//至此,得到了一个tmp里面放的全是各个单词对应的翻译
char** map = MapCreate(wordsSize);
int size = 0;
for (i = 0; i < wordsSize; i++)
{
//里面没有改串
if(MapFind(map,size,tmp[i]) == -1)
{
strcpy(map[size++],tmp[i]);
}
}
return size;
}
下面是内部函数的实现
#define MAX_SIZE 1000
//创造一个map 关键字是 字符串(莫斯密码)
char** MapCreate(int size)
{
char** map = (char**)malloc(sizeof(char*) * size);
int i;
for (i = 0; i < size; i++)
{
map[i] = (char*)malloc(sizeof(char) * MAX_SIZE);
map[i][0] = 0;
}
return map;
}
//如果改map中出现了 cur 字符串那么返回1 否则 返回 -1 size 为当前里面有多少个字符串
int MapFind(char** map,int size,char* cur)
{
int i;
for (i = 0; i < size; i++)
{
if(strcmp(map[i],cur) == 0)
{
return 1;
}
}
return -1;
}
9.最常见的单词

这道题,我手动构造了一个哈希表,用单词的首字母来决定他们放在哪里
- 这道题的思路很简单,就是去查哈希表,试着把字符串想象成一个数字,很简单的。但是关键字是一个字符串,所以得去实现这个数据结构。
char* mostCommonWord(char* paragraph, char** banned, int bannedSize)
{
StrMap* map = MapCreate();
StrMap* banmap = MapCreate();
int i,len = strlen(paragraph);
//这里面记录的是禁止的
for (i = 0; i < bannedSize; i++)
{
MapInsert(banmap,banned[i]);
}
i = 0;
while(paragraph[i] != '\0')
{
char* tmp = (char*)malloc(sizeof(char) * MAX_SIZE);
int index = 0;
//将tmp构造成单词
while(isalpha(paragraph[i]) && paragraph[i] != '\0')
{
char ch = tolower(paragraph[i]); //转化为小写字母
tmp[index++] = ch;
i++;
}
tmp[index] = '\0';
//至此单词构造完成
//不是禁止的才能去插入
if(tmp[0] != '\0' && MapFind(banmap,tmp) == NULL)
{
MapInsert(map,tmp);
}
//更新i
while(!isalpha(paragraph[i]) && paragraph[i] != '\0')
{
i++;
}
}
int max = 0;
char* maxkey = (char*)malloc(sizeof(char) * MAX_SIZE);
for (i = 0; i < 26; i++)
{
SNode* cur = map -> box[i].next;
while(cur != NULL)
{
if(cur -> count > max)
{
max = cur -> count;
strcpy(maxkey,cur->key);
}
cur = cur ->next;
}
}
return maxkey;
}
下面是StrMap相关的函数
#define MAX_SIZE 15
typedef struct SNode
{
char* key;
int count; //这个关键词出现了多少次。
struct SNode* next;
}SNode;
typedef struct
{
SNode box[26]; //这里面存放着每个字符串(单词的首字母)
}StrMap;
StrMap* MapCreate()
{
StrMap* map = (StrMap*)malloc(sizeof(StrMap));
for (int i = 0; i < 26; i++)
{
map -> box[i].key = NULL;
map -> box[i].count = 0;
map -> box[i].next = NULL;
}
return map;
}
SNode* BuyNode(char* s)
{
SNode* newnode = (SNode*)malloc(sizeof(SNode));
newnode -> key = (char*)malloc(sizeof(char) * MAX_SIZE);
strcpy(newnode->key,s);
newnode -> count = 1;
newnode -> next = NULL;
return newnode;
}
SNode* MapFind(StrMap* map,char* s)
{
if(!(s[0] >= 'a' && s[0] <= 'z'))
{
printf("%c\n",s[0]);
printf("首字母不是小写字母\n");
exit(-1);
}
int index = s[0] - 'a';
SNode* cur = map -> box[index].next;
//找
while(cur != NULL)
{
if(strcmp(cur->key,s) == 0)
{
return cur;
}
cur = cur -> next;
}
return NULL;
}
//在map中插入 新的value 并且记录它的次数
void MapInsert(StrMap* map, char* s)
{
//传进来的s必须全是由小写字母构成的单词
SNode* node = MapFind(map,s);
//如果有该字符串,则记录其出现的次数
if( node != NULL)
{
node -> count++;
return;
}
int index = s[0] - 'a'; //首字母
SNode* newnode = BuyNode(s);
if(map -> box[index].next == NULL)//头插
{
map -> box[index].next = newnode;
}
else
{
newnode -> next = map -> box[index].next;
map -> box[index].next = newnode;
}
}
我设计这个数据结构,函数实现,以及题目函数加起来也就半个消失,结果下面有个bug搞了我快1个小时,服了!

我是真的服了,我不知道为啥,然后我去看这个测试用例

我一看,我知道是就是应该是把代码中的tmp[0] = 0; 就是把‘\0’传入那个查找函数中去,又因为哈希表中 0 - ‘a’ 成负的了,肯定是错的,然后我改成这样
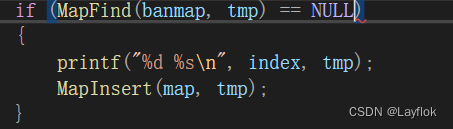

结果还是错的,我也是脑子抽住了,那个查找函数肯定是先执行啊。
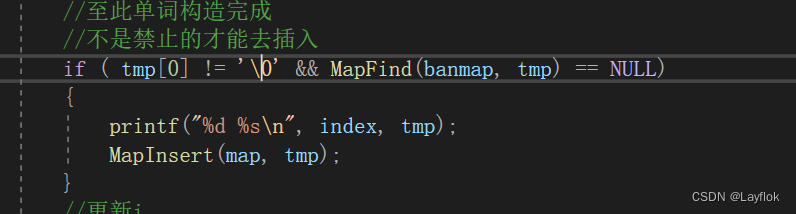
有被自己傻到。
10.公平的糖果交换

这道题,可以直接用暴力求法,一个一个的去枚举,就能成功,但是时间太慢了。
int ArrSum(int* nums,int size)
{
int sum = 0;
int i;
for (i = 0; i < size; i++)
{
sum += nums[i];
}
return sum;
}
int* fairCandySwap(int* aliceSizes, int aliceSizesSize, int* bobSizes, int bobSizesSize, int* returnSize)
{
int i;
int* ans = (int*)malloc(sizeof(int) * 2);
*returnSize = 2;
for (i = 0; i < aliceSizesSize; i++)
{
int suma = ArrSum(aliceSizes,aliceSizesSize);
int sumb = ArrSum(bobSizes,bobSizesSize);
if(suma != sumb)
{
int j;
for (j = 0; j < bobSizesSize; j++)
{
if(suma - aliceSizes[i] + bobSizes[j] == sumb - bobSizes[j] + aliceSizes[i])
{
break;
}
}
//证明是中间发现合适的了
if(j < bobSizesSize)
{
ans[0] = aliceSizes[i];
ans[1] = bobSizes[j];
break;
}
}
}
return ans;
}
这样暴力太费时了,有时候你的网速不是很好,这个还过不了,所以用哈希表来做还是相当不错的。

在上面的代码中,有这样一个条件,然后我转化一下,如下图:

意思就是说,如果第一个数组中有一个数,满足右边的公式即可。
- 首先构造一个哈希表,将第一个数组中的数字全部存放进去。
- 然后遍历第二个数组,与第二个公式进行嵌套,得出数,去哈希表里面查。
- 如果查到的话,就是了。
int* fairCandySwap(int* aliceSizes, int aliceSizesSize, int* bobSizes, int bobSizesSize, int* returnSize)
{
int i;
int* ans = (int*)malloc(sizeof(int) * 2);
*returnSize = 2;
int suma = ArrSum(aliceSizes,aliceSizesSize);
int sumb = ArrSum(bobSizes,bobSizesSize);
int map[1000000] = {0};
for (i = 0; i < aliceSizesSize; i++)
{
map[aliceSizes[i]] = 1; //表示里面有这个数
}
for (i = 0; i < bobSizesSize; i++)
{
int x = bobSizes[i] + ((suma - sumb) / 2);
if(x >= 0 && map[x] != 0) //代表有这个数
{
ans[0] = x;
ans[1] = bobSizes[i];
break;
}
}
return ans;
}
11. 卡牌分组

- 构造一个哈希表记录数组中每一个数出现的次数
- 然后分别对其,求最大公约数,
- 如果其中次数俩个数都是质数,那么肯定是分不好的。
int gcd(int x, int y)
{
if(y == 0)
{
return x;
}
return gcd(y,x%y);
}
bool hasGroupsSizeX(int* deck, int deckSize)
{
if(deckSize == 1)
{
return false;
}
int map[10000] = {0};
int i;
for (i = 0; i < deckSize; i++)
{
map[deck[i]]++;
}
int x = map[0];
for (i = 1; i < 10000; i++)
{
if(map[i] == 1)
{
return false;
}
x = gcd(x,map[i]);
if(x == 1) //如果最大公约数是1证明这俩数 都是质数,
{
return false;
}
}
return true;
}
12.亲密的字符串

这道题,给你两个字符串,去判断其中是否只能通过交换一次
这个交换一次有说法的,不能不交换,也不能交换2次,这点很重要。
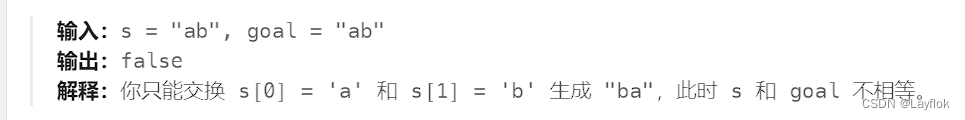
上面这张图,不交换就还是可以的,但是return的是false

而这张图,交换两次即可,但是还是false
懂了只能交换一次,这道题就好做了
- 首先你得判断两个字符串长度是否一样,如果不一样,那么一定不会相同的
- 然后你将两个字符串中字母出现的次数记录到哈希表中去,同时要记录他们中不同字母的次数(这个很关键)
- 然后去遍历哈希表,如果两个表中字母出现的次数有不同的,那么你如何交换都是不行的,直接返回false即可,看下图,虽然长度一样,但是字母出现的次数不同。
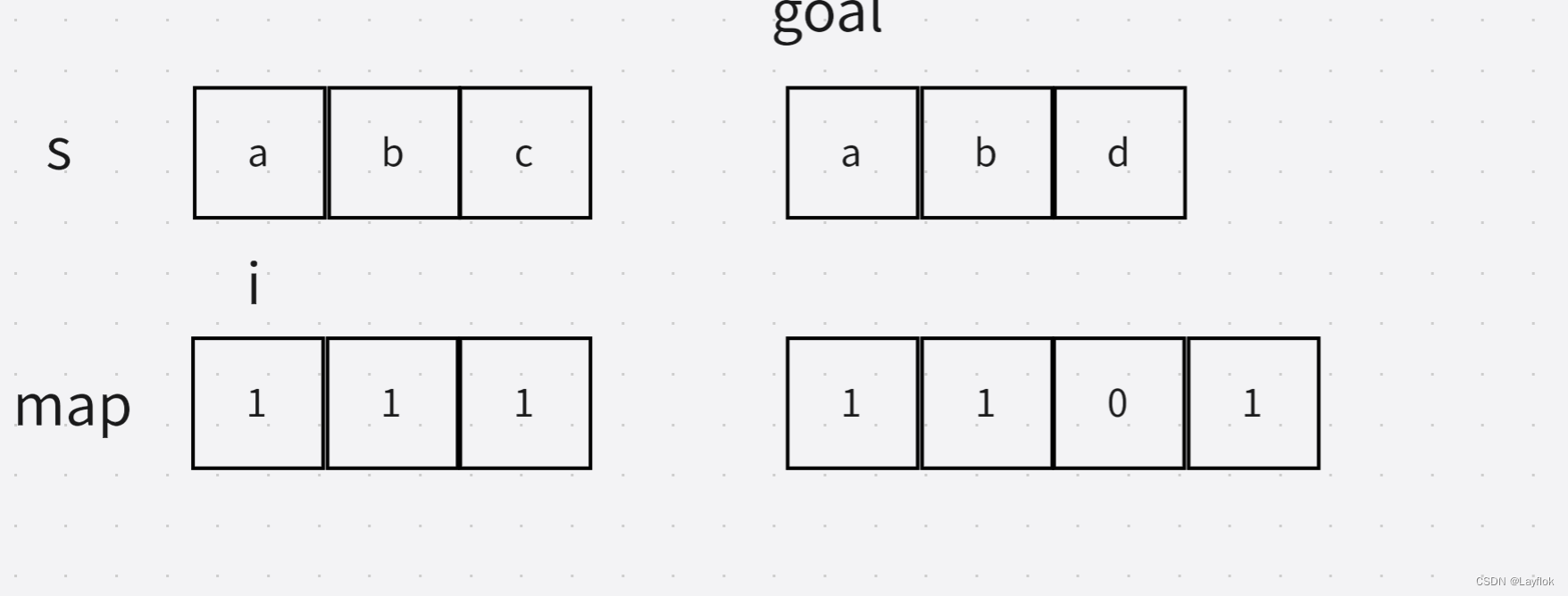
- 至此,即可判断两个字符串中,字母出现的次数是相同的。
- 然后你接着去判断有没有重复的字母,如果有,那么记录一下,跳出循环。
- 最后去判断其相对应的条件即可。
bool buddyStrings(char* s, char* goal)
{
int maps[26] = {0};
int mapg[26] = {0};
int lens = strlen(s);
int leng = strlen(goal);
if(lens != leng)
{
return false;
}
int i;
int different = 0;
for (i = 0; i < lens; i++)
{
if(s[i] != goal[i])
{
different++; //两个字符串,其中有字母的顺序不同
}
maps[s[i] - 'a']++; //记录出现的次数
mapg[goal[i] - 'a']++;
}
for (i = 0 ; i < 26; i++)
{
//如果字母出现次数都不同,交换也不行
if(maps[i] != mapg[i])
{
return false;
}
}
bool flag = false;
//到了这里还没有出现结果,就在证明其实两个字符串是相等的,下面去判断它有没有相同的元素
for (i = 0; i < 26; i++)
{
if(maps[i] >= 2) //重复的字母
{
flag = true;
break;
}
}
//因为只能交换一次,所以,只能有1对不同的,也就是只能是2
if(different == 2 || (different == 0 && flag == true))
{
return true;
}
else
{
return false;
}
}
13.两句话中的不常见单词

这道题其实在数组中做过类似的感觉。你可以将两个字符串中出现的单词同时录入到一个哈希表中去,然后去遍历哈希表,如果该单词只出现一次就拷贝到ans中去
- 构造一个关键字是字符串的哈希表
- 然后遍历两个字符串的同时,将其单词录入到哈希表中
- 最后遍历哈希表,寻找只出现一次的单词即可
下面是代码的主体逻辑,其中StrMap在目录中的第9题有实现,这里就不放出去来了
void Push(StrMap* map,char* s)
{
int i = 0,len = strlen(s);
while(i < len)
{
char* tmp = (char*)malloc(sizeof(char) * MAX_SIZE);
int index = 0;
//分隔单词
while(s[i] != ' ' && s[i] != '\0')
{
tmp[index++] = s[i++];
}
i++;
tmp[index] = '\0';
MapInsert(map,tmp); //记录到哈希表中去
}
}
char** uncommonFromSentences(char* s1, char* s2, int* returnSize)
{
int len1 = strlen(s1),len2 = strlen(s2);
int i = 0;
StrMap* map = MapCreate();
char** ans = (char**)malloc(sizeof(char*) * len1);
*returnSize = 0;
//录入哈希值,将两个字符串中的单词次数,全部录入到一个哈希表中去
Push(map,s1);
Push(map,s2);
for (i = 0; i < 26; i++)
{
SNode* cur = map -> box[i].next;
while(cur != NULL)
{
//只出现一次的单词
if(cur -> count == 1)
{
ans[(*returnSize)] = (char*)malloc(sizeof(char) * MAX_SIZE);
strcpy(ans[(*returnSize)++],cur -> key);
}
cur = cur -> next;
}
}
return ans;
}
14.独特的电子邮件地址

这道题完全可以理解成,一个数组中,出现了多少个不同的数字。
这里只是将数字换成了字符串而已。
下面代码中的哈希表上面题目中也有,通用的都是
- 首先将每个邮箱地址都转化为规则的。
- 然后将它插入到哈希表中,如果表中已有,就没有必要了。
- 主要还是得会将邮箱进行相对应的转换
//将传过来的邮箱,调整成规范的邮箱。
char* Adjust(char* s)
{
int len = strlen(s);
char* ans = (char*)malloc(sizeof(char) * MAX_STR_SIZE);
int index = 0;
int i = 0;
bool locaName = true; //代表的本地名
bool domainName = false; //域名
for (i = 0; i < len; i++)
{
if(s[i] == '+')
{
locaName = false;
}
if(s[i] == '@') //域名以后的
{
locaName = true;
domainName = true;
}
if((s[i] != '.' && locaName) || domainName)
{
ans[index++] = s[i];
}
}
ans[index] = '\0';
return ans;
}
int numUniqueEmails(char** emails, int emailsSize)
{
int i,ans = 0;
StrMap* map = MapCreate();
for (i = 0; i < emailsSize; i++)
{
char* tmp = Adjust(emails[i]); //调整好的邮箱地址
if(MapFind(map,tmp) == NULL)
{
//里面没有的话,记录
ans++;
MapInsert(map,tmp);
}
}
return ans;
}
15. 在长度 2N 的数组中找出重复 N 次的元素

这道题,它说恰有一个元素重复了n次,就意思是,只有个元素是重复的。所以当你发现这个元素重复出现时候,直接返回就好了。
- 利用哈希表存储出现的次数。
- 然后发现重复出现两次,就找到这个数了。
int repeatedNTimes(int* nums, int numsSize)
{
int map[100000] = {0};
int i;
for (i= 0; i < numsSize; i++)
{
map[nums[i]]++;
if(map[nums[i]] >= 2)
{
return nums[i];
}
}
return 0;
}
16.找到小镇的法官

这道题,通俗易懂一点,就是找到一个:
除了自己以外,全部人都相信他,并且,自己不相信任何人。
- 创建两个哈希表,一共用来记录有多少人信我
- 另一个用来记录我是否相信别人。
- 然后去遍历每个人,找到那个,所有人都相信自己的,并且自己不信别人的人就好了。
int findJudge(int n, int** trust, int trustSize, int* trustColSize)
{
int row = trustSize;
int i,map1[10000] = {0},map2[10000] = {0};
for (i = 0; i < row; i++)
{
map1[trust[i][1]]++; //别人信我
if(map2[trust[i][0]] == 0)
{
map2[trust[i][0]] = 1; //表示我信别人
}
}
for(i = 1; i <= n; i++)
{
//别人信我的人数是 n - 1 而我必须谁也不信.
if(map1[i] == n -1 && map2[i] == 0)
{
return i;
}
}
return -1;
}
17.查找共用的字符

下面是leetcode官网题解。
/**
* Note: The returned array must be malloced, assume caller calls free().
*/
char** commonChars(char** words, int wordsSize, int* returnSize) {
int minfreq[26], freq[26];
for (int i = 0; i < 26; ++i) {
minfreq[i] = INT_MAX;
freq[i] = 0;
}
for (int i = 0; i < wordsSize; ++i) {
memset(freq, 0, sizeof(freq));
int n = strlen(words[i]);
for (int j = 0; j < n; ++j) {
++freq[words[i][j] - 'a'];
}
for (int j = 0; j < 26; ++j) {
minfreq[j] = fmin(minfreq[j], freq[j]);
}
}
int sum = 0;
for (int i = 0; i < 26; ++i) {
sum += minfreq[i];
}
char** ans = malloc(sizeof(char*) * sum);
*returnSize = 0;
for (int i = 0; i < 26; ++i) {
for (int j = 0; j < minfreq[i]; ++j) {
ans[*returnSize] = malloc(sizeof(char) * 2);
ans[*returnSize][0] = i + 'a';
ans[*returnSize][1] = 0;
(*returnSize)++;
}
}
return ans;
}
作者:力扣官方题解
链接:https://leetcode.cn/problems/find-common-characters/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
最后一道题不是清楚我这边也。















 157
157











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









