第 1 章 Linux 操作系统的使用
1
目录
1. 实验一:Linux 常用命令................................................. 2
1.1. 实验目的 .......................................................... 2
1.2. 实验要求 .......................................................... 2
1.3. 实验环境 .......................................................... 2
1.4. 实验过程 .......................................................... 2
1.4.1. 实验任务一:文件与目录操作 .................................... 2
1.4.2. 实验任务二:用户操作 .......................................... 5
1.4.3. 实验任务三:文本操作 .......................................... 7
1.4.4. 实验任务四:系统操作 .......................................... 7
第
1
章
Linux
操作系统的使用
2
1.
实验一:
Linux
常用命令
1.1.
实验目的
完成本实验,您应该能够:
掌握
linux
操作系统常用命令
1.2.
实验要求
熟悉常用
Linux
操作系统命令
1.3.
实验环境
本实验所需之主要资源环境如表
1-1
所示。
表 1-1 资源环境
服务器集群
单节点,机器最低配置:双核
CPU
、
8GB
内存、
100G
硬盘
运行环境
CentOS 7.4
服务和组件
服务和组件根据实验需求安装
1.4.
实验过程
1.4.1.
实验任务一:文件与目录操作
1.4.1.1.
步骤一:
pwd
命令
格式:pwd
功能:显示当前所在目录(即工作目录)。
[root@VM-M-01597287170765 ~]# pwd
/root
1.4.1.2.
步骤二:
ls
命令
格式:ls [选项] [文件|目录]
功能:显示指定目录中的文件或子目录信息。当不指定文件或目录时,显示
当前工作目录中的文件或子目录信息。
命令常用选项如下:
-a :全部的档案,连同隐藏档( 开头为 . 的档案) 一起列出来。
-l :长格式显示,包含文件和目录的详细信息。
-R :连同子目录内容一起列出来。
说明:命令“ls –l”设置了别名:ll,即输入 ll 命令,执行的是 ls –l
命令。
[root@VM-M-01597287170765 ~]# ls -a /
. bin dev home lib64 mnt proc run srv tmp var
第
1
章
Linux
操作系统的使用
.. boot etc lib media opt root sbin sys usr
[root@VM-M-01597287170765 ~]# ls -l /
总用量
28
lrwxrwxrwx. 1 root root 7 6
月
17 09:43 bin -> usr/bin
dr-xr-xr-x. 5 root root 4096 6
月
17 09:53 boot
drwxr-xr-x. 19 root root 3220 6
月
17 10:34 dev
drwxr-xr-x. 141 root root 8192 7
月
2 09:15 etc
drwxr-xr-x. 5 root root 48 6
月
17 16:21 home
……
[root@VM-M-01597287170765 ~]# ls -R /home/
/home/:
hadoop VM-M-01597287170765 nagios
/home/hadoop:
1+X bigdata_work.java
……
1.4.1.3.
步骤三:cd 命令
格式:cd <路径>
功能:用于切换当前用户所在的工作目录,其中路径可以是绝对路径也可
以是相对路径。
[root@VM-M-01597287170765 ~]# cd /home/hadoop/
[root@VM-M-01597287170765 hadoop]# cd ..
[root@VM-M-01597287170765 home]# cd ./hadoop
1.4.1.4.
步骤四:mkdir 命令
格式: mkdir [选项] 目录
功能:用于创建目录。创建目录前需保证当前用户对当前路径有修改的权限。
参数 -p 用于创建多级文件夹。
[root@VM-M-01597287170765 hadoop]# mkdir test
[root@VM-M-01597287170765 hadoop]# mkdir -p /test/test1
1.4.1.5.
步骤五:rm 命令
格式: rm [选项] <文件>
功能:用于删除文件或目录,常用选项-r -f,-r 表示删除目录,也可以用
于删除文件,-f 表示强制删除,不需要确认。删除文件前需保证当前用户对当
前路径有修改的权限。
[root@VM-M-01597287170765 hadoop]# rm -r -f test/
1.4.1.6.
步骤六:cp 命令
格式: cp [选项] <文件> <目标文件>
3
第
1
章
Linux
操作系统的使用
功能:复制文件或目录。
[root@VM-M-01597287170765 hadoop]# cp /etc/profile ./
[root@VM-M-01597287170765 hadoop]# ls
1+X bigdata_work.java profile
1.4.1.7.
步骤七:
mv
命令
格式:mv [选项] <文件> <目标文件>
功能:移动文件或对其改名。常用选项-i -f -b,-i 表示若存在同名文件,
则向用户询问是否覆盖;-f 直接覆盖已有文件,不进行任何提示;-b 当文件
存在时,覆盖前为其创建一个备份。
[root@VM-M-01597287170765 hadoop]# mv profile profile_test.log
[root@VM-M-01597287170765 hadoop]# ls
1+X bigdata_work.java profile_test.log
1.4.1.8.
步骤八:
cat
命令
格式:cat [选项] [文件]
功能:查看文件内容。常用选项:-n 显示行号(空行也编号)。
[root@VM-M-01597287170765 hadoop]# cat -n profile_test.log
1 # /etc/profile
2
3 # System wide environment and startup programs, for login
setup
4 # Functions and aliases go in /etc/bashrc
……
1.4.1.9.
步骤九:tar 命令
格式:tar [选项] [档案名] [文件或目录]
功能:为文件和目录创建档案。利用 tar 命令,可以把一大堆的文件和目录
全部打包成一个文件,这对于备份文件或将几个文件组合成为一个文件以便于网
络传输是非常有用的。该命令还可以反过来,将档案文件中的文件和目录释放出
来。
常用选项:
-c 建立新的备份文件。
-C <目录> 切换工作目录,先进入指定目录再执行压缩/解压缩操作,可用
于仅压缩特定目录里的内容或解压缩到特定目录。
-x 从归档文件中提取文件。
-z 通过 gzip 指令压缩/解压缩文件,文件名为*.tar.gz。
-f<备份文件> 指定备份文件。
-v 显示命令执行过程。
[root@VM-M-01597287170765 hadoop]# tar -cvf all.tar *.log
profile_test.log
[root@VM-M-01597287170765 hadoop]# tar -zcvf log.tar.gz all.tar
4
第
1
章
Linux
操作系统的使用
5
all.tar
[root@VM-M-01597287170765 hadoop]# tar -zxvf log.tar.gz -C ./
all.tar
1.4.2.
实验任务二:用户操作
1.4.2.1.
步骤一:useradd 命令
格式:useradd 用户名
功能:创建新用户,该命令只能由 root 用户使用。
#
创建
teacher
用户
[root@VM-M-01597287170765 hadoop]# adduser teacher
1.4.2.2.
步骤二:
passwd
命令
格式:passwd 用户名
功能:设置或修改指定用户的口令。
[root@VM-M-01597287170765 hadoop]# passwd teacher
更改用户
teacher
的密码 。
新的 密码:
无效的密码: 密码未通过字典检查
-
它基于字典单词
重新输入新的 密码:
passwd
:所有的身份验证令牌已经成功更新。
1.4.2.3.
步骤三:
chown
命令
格式:chown [选项]
功能:将文件或目录的拥有者改为指定的用户或组,用户可以是用户名或者
用户 ID,组可以是组名或者组 ID,文件是以空格分开的要改变权限的文件列表,
支持通配符。选项“-R”表示对目前目录下的所有文件与子目录进行相同的拥有
者变更
[root@VM-M-01597287170765 hadoop]# chown bin:bin log.tar.gz
[root@VM-M-01597287170765 hadoop]# ll
总用量
32
drwxrwxr-x. 3 hadoop hadoop 20 7
月
1 11:39 1+X
-rw-r--r--. 1 root root 10240 7
月
2 10:40 all.tar
-rw-rw-r--. 1 hadoop hadoop 11309 6
月
30 16:43 bigdata_work.java
-rw-r--r--. 1 bin bin 1322 7
月
2 10:41 log.tar.gz
-rw-r--r--. 1 root root 2922 7
月
2 10:30 profile_test.log
[root@VM-M-01597287170765 hadoop]# chown -R teacher:teacher
log.tar.gz
[root@VM-M-01597287170765 hadoop]# ll
总用量
32
drwxrwxr-x. 3 hadoop hadoop 20 7
月
1 11:39 1+X
-rw-r--r--. 1 root root 10240 7
月
2 10:40 all.tar
第
1
章
Linux
操作系统的使用
6
-rw-rw-r--. 1 hadoop hadoop 11309 6
月
30 16:43
bigdata_work.java
-rw-r--r--. 1 teacher teacher 1322 7
月
2 10:41 log.tar.gz
-rw-r--r--. 1 root root 2922 7
月
2 10:30 profile_test.log
1.4.2.4.
步骤四:
chmod
命令
格式:chmod [-R] 模式 文件或目录
功能:修改文件或目录的访问权限。选项“-R”表示递归设置指定目录下的
所有文件和目录的权限。
模式为文件或目录的权限表示,有三种表示方法。
(1)数字表示
用 3 个数字表示文件或目录的权限,第 1 个数字表示所有者的权限,第 2 个
数字表示与所有者同组用户的权限,第 3 个数字表示其他用户的权限。每类用户
都有 3 类权限:读、写、执行,对应的数字分别是 4、2、1。一个用户的权限数
字表示为三类权限的数字之和,如一个用户对 A 文件拥有读写权限,则这个用户
的权限数字为 6(4+2=6)。
示例:
[root@VM-M-01597287170765 hadoop]# chmod 764 profile_test.log
(2)字符赋值
用字符 u 表示所有者,用字符 g 表示与所有者同组用户,用字符 o 表示其他
用户。用字符 r、w、x 分别表示读、写、执行权限。用等号“=”来给用户赋权
限。
示例:
[root@VM-M-01597287170765
hadoop]# chmod u=rwx,g=rw,o=r
profile_test.log
(3)字符加减权限
用字符 u 表示所有者,用字符 g 表示与所有者同组用户,用字符 o 表示其他
用户。用字符 r、w、x 分别表示读、写、执行权限。用加号“+”来给用户加权
限,加号“-”来给用户减权限。
示例:
[root@VM-M-01597287170765
hadoop]# chmod u+x,g+w,o-w
profile_test.log
1.4.2.5.
步骤五:
su
命令
格式:su [-] 用户名
功能:将当前操作员的身份切换到指定用户。如果使用选项“-”,则用户切
换后使用新用户的环境变量,否则环境变量不变。
[root@VM-M-01597287170765 hadoop]# su teacher
第
1
章
Linux
操作系统的使用
[teacher@VM-M-01597287170765 hadoop]$ exit
1.4.3.
实验任务三:文本操作
文本编辑器这里只介绍一个 vi 命令,vim 命令的操作与 vi 一样。
格式:vi [文件名]
功能:vi 是 Linux 的常用文本编辑器,vim 是从 vi 发展出来的一个文本编
辑器,其在代码补全、编译等方便的功能特别丰富,在程序员中被广泛使用。
vi/vim 有三个工作模式:
1.4.3.1.
步骤一:命令模式
用户刚刚启动 vi/vim,便进入了命令模式。
此状态下敲击键盘动作会被 vi 识别为命令,而非输入字符。以下是常用的
几个命令:
i 切换到输入模式,以输入字符。
x 删除当前光标所在处的字符。
: 切换到末行模式,用以在最底一行输入命令
[root@VM-M-01597287170765 ~]# cd /home/hadoop/
[root@VM-M-01597287170765 hadoop]# vim profile_test.log
之后输入 i、x 或:会有相应的效果
1.4.3.2.
步骤二:输入模式
在输入模式下可以对文件执行写操作,编写完成后按 Esc 键即可返回命令
模式。
1.4.3.3.
步骤三:末行模式
如果要保存、查找或者替换一些内容等,就需要进入末行模式。以下是常用
的几个命令:
Set nu:每一行显示行号
r 文件名:读取指定的文件。
w 文件名:将编辑内容保存到指定的文件内。
q:退出 vi
wq:保存文件并退出 vi
q!:强制退出 vi,不管是否保存文档内容。
1.4.4.
实验任务四:系统操作
1.4.4.1.
步骤一:
clear
命令
格式:clear
7
第
1
章
Linux
操作系统的使用
功能:清除屏幕。实质上只是让终端显示页向后翻了一页,如果向上滚动屏
幕还可以看到之前的操作信息。
[root@VM-M-01597287170765 hadoop]# clear
1.4.4.2.
步骤二:
hostname
命令
格式:hostname [选项]
功能:用于显示和设置系统的主机名称。在使用 hostname 命令设置主机名
后,系统并不会永久保存新的主机名,重新启动机器之后还是原来的主机名。如
果需要永久修改主机名,需要同时修改/etc/hostname 的相关内容。常用选项:
-a 显示主机别名,-i 显示主机的 ip 地址。
[root@VM-M-01597287170765 hadoop]# hostname
VM-M-01597287170765
1.4.4.3.
步骤三:
hostnamectl
命令
格式 1:hostnamectl
功能:显示当前主机的名称和系统版本。
格式 2:hostnamectl set-hostname <host-name>
功能:永久设置当前主机的名称。
示例:
#
将当前主机的名称改为
master
,需要注销用户,重新登录就可以查看新的主机名。
[root@VM-M-01597287170765 hadoop]# hostnamectl set-hostname
master
1.4.4.4.
步骤四:
ip
命令
CentOS 7 已不使用 ifconfig 命令,其功能可通过 ip 命令代替。
格式 1:ip link <命令选项> dev <设备名>
功能:对网络设备(网卡)进行操作,选项 add、delete、show、set 分别对
应增加、删除、查看和设置网络设备。
示例:
[root@VM-M-01597287170765 hadoop]# ip link show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state
UNKNOWN mode DEFAULT qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: ens160: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq
state UP mode DEFAULT qlen 1000
link/ether 00:50:56:82:4a:22 brd ff:ff:ff:ff:ff:ff
3: virbr0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc
noqueue state DOWN mode DEFAULT qlen 1000
link/ether 52:54:00:d9:66:c3 brd ff:ff:ff:ff:ff:ff
4: virbr0-nic: <BROADCAST,MULTICAST> mtu 1500 qdisc pfifo_fast
VM-M-01597287170765 virbr0 state DOWN mode DEFAULT qlen 1000
link/ether 52:54:00:d9:66:c3 brd ff:ff:ff:ff:ff:ff
8
第
1
章
Linux
操作系统的使用
9
格式 2:ip address <命令选项> dev <设备名>
功能:对网卡的网络协议地址(IPv4/IPv6)进行操作,选项 add、change、
del、show 分别对应增加、修改、删除、查看 IP 地址。
示例:
#
这里将
address
缩写为
addr
[root@VM-M-01597287170765 hadoop]# ip addr show
1.4.4.5.
步骤五:
systemctl
命令
格式:systemctl <命令选项> service_name.service
功能:管理系统中的服务,“.service”表示管理的服务均包含了一个
以 .service 结尾的文件,存放于 /lib/systemd/目录中,可以省略。命令选项
有 start、restart、reload、stop、status,分别对应服务的启动、重启、重新
加载、停止和显示状态。另外选项 enable 表示开机时启动,disable 表示撤销
开机启动。
示例:
#
启动网络服务
[root@VM-M-01597287170765 hadoop]# systemctl start network
#
关闭防火墙,注意
CentOS 7
的防火墙服务名称改为
firewalld
[root@VM-M-01597287170765 hadoop]# systemctl stop firewalld
#
查看
ssh
服务的状态
[root@VM-M-01597287170765 hadoop]# systemctl status sshd
#
设置
ssh
服务开机启动
[root@VM-M-01597287170765 hadoop]# systemctl enable sshd
1.4.4.6.
步骤六:
reboot
命令
格式: reboot
功能:用于重新启动计算机,但是机器重启必须要 root 用户才有权限。
注意
:
本操作无需在平台系统执行
[root@VM-M-01597287170765 hadoop]# reboot
1.4.4.7.
步骤八:
poweroff
命令
格式:poweroff
功能:用来关闭计算机操作系统并且切断系统电源。如果确认系统中已经没
有用户存在且所有数据都已保存,需要立即关闭系统,可以使用 poweroff 命令。
注意
:
本操作无需在平台系统执行
[root@VM-M-01597287170765 hadoop]# poweroff
1.4.4.8.
步骤九:
export
命令
格式:export [选项] [变量名]
功能:用于将 Shell 变量输出为环境变量,或者将 Shell 函数输出为环境变
第
1
章
Linux
操作系统的使用
10
量。一个变量创建时,它不会自动地为在它之后创建的 Shell 进程所知,而命令
export 可以向后面的 Shell 传递变量的值。当一个 Shell 脚本调用并执行时,
它不会自动得到父脚本(调用者)里定义的变量的访问权,除非这些变量已经被
显式地设置为可用。export 命令可以用于传递一个或多个变量的值到任何子脚
本。
常用选项:
-f 代表[变量名称]中为函数名称。
-n 删除指定的变量。变量实际上并未删除,只是不会输出到后续指令的执
行环境中。
-p 列出所有的 Shell 赋予程序的环境变量。
示例:
#
列出当前所有的环境变量
[root@VM-M-01597287170765 hadoop]# export -p
#
定义环境变量
MYENV
[root@VM-M-01597287170765 hadoop]# export MYENV
#
定义环境变量,并赋值
MYENV=7
[root@VM-M-01597287170765 hadoop]# export MYENV=7
1.4.4.9.
步骤十:
echo
命令
格式:echo [字符串]
功能:用于在终端设备上输出字符串或变量提取后的值。一般使用在变量前
加上$符号的方式提取出变量的值,例如:$PATH,然后再用 echo 命令予以输出。
示例:
#
输出一段字符串
LinuxCool.com
[root@VM-M-01597287170765 hadoop]# echo "LinuxCool.com"
#
输出变量
PATH
值
[root@VM-M-01597287170765 hadoop]# echo $PATH
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
1.4.4.10.
步骤十一:
source
命令
格式:source [文件]
功能:用于重新执行刚修改的初始化文件,使之立即生效,而不必注销用户,
重新登录。
示例:
#
读取和执行
~/.bash_profile
文件
[root@VM-M-01597287170765 hadoop]# source ~/.bash_profile
第 2 章 Hadoop 平台安装
1
目录
1. 实验一:Linux 操作系统环境设置......................................... 2
1.1. 实验目的 .......................................................... 2
1.2. 实验要求 .......................................................... 2
1.3. 实验环境 .......................................................... 2
1.4. 实验过程 .......................................................... 2
1.4.1. 实验任务一:配置 Linux 系统基础环境 ............................ 2
1.4.2. 实验任务二:安装 JAVA 环境 ..................................... 4
2. 实验二 安装 Hadoop 软件................................................ 7
2.1. 实验目标 .......................................................... 7
2.2. 实验要求 .......................................................... 7
2.3. 实验环境 .......................................................... 7
2.4. 实验过程 .......................................................... 7
2.4.1. 实验任务一:获取 Hadoop 安装包 ................................. 7
2.4.2. 实验任务二:安装 Hadoop 软件 ................................... 7
3. 实验三 安装单机版 Hadoop 系统 ......................................... 10
3.1. 实验目标 ......................................................... 10
3.2. 实验要求 ......................................................... 10
3.3. 实验环境 ......................................................... 10
3.4. 实验过程 ......................................................... 10
3.4.1. 实验任务一:配置 Hadoop 配置文件 .............................. 10
3.4.2. 实验任务二:测试 Hadoop 本地模式的运行 ........................ 11
第
2
章
Hadoop
平台安装
2
1.
实验一:
Linux
操作系统环境设置
1.1.
实验目的
完成本实验,您应该能够:
掌握
linux
操作系统环境设置
掌握
hadoop
安装的环境要求
1.2.
实验要求
熟悉常用
Linux
操作系统命令
熟悉
hadoop
安装的环境
了解
linux
修改系统变量命令及各参数
1.3.
实验环境
本实验所需之主要资源环境如表
1-1
所示。
表 1-1 资源环境
服务器集群
单节点,机器最低配置:双核
CPU
、
8GB
内存、
100G
硬盘
运行环境
CentOS 7.4
服务和组件
服务和组件根据实验需求安装
1.4.
实验过程
1.4.1.
实验任务一:配置
Linux
系统基础环境
1.4.1.1.
步骤一:查看服务器的
IP
地址
查看服务器的 IP 地址
[root@VM-M-01597287170765 ~]# ip address show
1.4.1.2.
步骤二:设置服务器的主机名称
按前面设定的主机名称进行设置,具体命令如下所示
[root@VM-M-01597287170765 ~]# hostnamectl set-hostname master
设置完后查看当前服务器的名称,结果为 master。
[root@VM-M-01597287170765 ~]# hostname
master
这时 root 用户的提示符中主机名仍然是 localhost,其实只要换一下用户或
者 root 用户注销再登录,主机名就会改为 master 了。
另外,也可以用 nmtui 命令直接修改主机的 IP 地址和主机名称,具体的方
法见 2.2 节。
第
2
章
Hadoop
平台安装
1.4.1.3.
步骤三:绑定主机名与
IP
地址
可以将主机名称与 IP 地址绑定,这样就可以通过主机名来访问主机,方便
记忆。同时在后面的配置文件中也可以用主机名来代替 IP 地址表示主机,当
IP 地址改变时,只要修改主机名与 IP 地址的绑定文件,不用在多个配置文件
中去修改。主机名与 IP 地址的绑定文件是本地名字解析文件 hosts,在/etc 目
录中,使用 vi 对该文件进行编辑。
[root@master ~]# vi /etc/hosts
在其中增加如下一行内容:
192.168.1.6 master
1.4.1.4.
步骤四:查看
SSH
服务状态
SSH 为 Secure Shell 的缩写,是专为远程登录会话和其他网络服务提供安
全性的协议。一般的用法是在本地计算机安装 SSH 客服端,在服务器端安装 SSH
服务,然后本地计算机利用 SSH 协议远程登录服务器,对服务器进行管理。这
样可以非常方便地对多台服务器进行管理。同时在 Hadoop 分布式环境下,集群
中的各个节点之间(节点可以看作是一台主机)需要使用 SSH 协议进行通信。因
此 Linux 系统必须安装并启用 SSH 服务。
CentOS 7 默认安装 SSH 服务,可以使用如下命令查看 SSH 的状态。
[root@master ~]# systemctl status sshd
sshd.service - OpenSSH server daemon
Loaded: loaded (/usr/lib/systemd/system/sshd.service;
enabled; vendor preset: enabled)
Active: active (running) since
六
2020-05-02 17:24:51 CST;
30min ago
……
省略
…..
看到 active (running)就表示 SSH 已经安装并启用。
1.4.1.5.
步骤五:关闭防火墙
Hadoop 可以使用 Web 页面进行管理,但需要关闭防火墙,否则打不开 Web 页
面。同时不关闭防火墙也会造成 Hadoop 后台运行脚本出现莫名其妙的错误。关
闭命令如下:
[root@master ~]# systemctl stop firewalld
关闭防火墙后要查看防火墙的状态,确认一下。
[root@master ~]# systemctl status firewalld
● firewalld.service - firewalld - dynamic firewall daemon
Loaded: loaded (/usr/lib/systemd/system/firewalld.service;
enabled; vendor preset: enabled)
Active: inactive (dead) since
六
2020-05-02 17:58:15 CST; 3s
ago
……
省略
…..
3
第
2
章
Hadoop
平台安装
4
看到 inactive (dead)就表示防火墙已经关闭。不过这样设置后,Linux 系
统如果重启,防火墙仍然会重新启动。执行如下命令可以永久关闭防火墙。
[root@master ~]# systemctl disable firewalld
1.4.1.6.
步骤六:创建
hadoop
用户
在 Linux 系统中 root 用户为超级管理员,具有全部权限,使用 root 用户在
Linux 系统中进行操作,很可能因为误操作而对 Linux 系统造成损害。正常的作
法是创建一个普通用户,平时使用普通用户在系统进行操作,当用户需要使用管
理员权限,可以使用两种方法达到目的:一种方法是使用 su 命令,从普通用户
切换到 root 用户,这需要知道 root 用户的密码。另一种方法是使用 sudo 命令。
用户的 sudo 可以执行的命令由 root 用户事先设置好。
在本教材中使用 root 用户来安装 Hadoop 的运行环境,当 Hadoop 运行环境
都安装配置好后,使用 hadoop 用户(这只是一个用户名,也可以使用其他的用
户名)来运行 Hadoop,实际工作中也是这样操作的。因此需要创建一个 hadoop
用户来使用 Hadoop。创建命令如下:
[root@master ~]# useradd hadoop
设置用户 hadoop 的密码为 passwd,由于密码太简单需要输入两次。
[root@master ~]# passwd hadoop
Changing password for user hadoop.
New password:
BAD PASSWORD: The password is shorter than 8 characters
Retype new password:
passwd: all authentication tokens updated successfully.
1.4.2.
实验任务二:安装
JAVA
环境
1.4.2.1.
步骤一:下载
JDK
安装包
JDK
安 装 包 需 要 在
Oracle
官 网 下 载 , 下 载 地 址 为 :
https://www.oracle.com/java /technologies /javase-jdk8-downloads.html,
本教材采用的 Hadoop 2.7.1 所需要的 JDK 版本为 JDK7 以上,这里采用的安装包
为 jdk-8u152-linux-x64.tar.gz。
1.4.2.2.
步骤二:卸载自带
OpenJDK
键入命令
[root@master ~]# rpm -qa | grep java
java-1.8.0-openjdk-headless-1.8.0.131-11.b12.el7.x86_64
javapackages-tools-3.4.1-11.el7.noarch
tzdata-java-2017b-1.el7.noarch
java-1.7.0-openjdk-headless-1.7.0.141-2.6.10.5.el7.x86_64
java-1.7.0-openjdk-1.7.0.141-2.6.10.5.el7.x86_64
java-1.8.0-openjdk-1.8.0.131-11.b12.el7.x86_64
python-javapackages-3.4.1-11.el7.noarch
第
2
章
Hadoop
平台安装
5
图 3-0 查看 java
删除相关文件,键入命令
[root@master ~]# rpm -e --nodeps java-1.8.0-openjdk-headless-
1.8.0.131-11.b12.el7.x86_64
[root@master ~]# rpm -e --nodeps java-1.8.0-openjdk-1.8.0.131-
11.b12.el7.x86_64
[root@master ~]# rpm -e --nodeps java-1.7.0-openjdk-headless-
1.7.0.141-2.6.10.5.el7.x86_64
[root@master ~]# rpm -e --nodeps java-1.7.0-openjdk-1.7.0.141-
2.6.10.5.el7.x86_64
查看删除结果再次键入命令 java -version 出现以下结果表示删除成功
图 3-1 查看 java 版本
1.4.2.3.
步骤三:安装
JDK
Hadoop 2.7.1 要求 JDK 的版本为 1.7 以上,这里安装的是 JDK1.8 版(即
JAVA 8)。
安装命令如下,将安装包解压到/usr/local/src 目录下
[root@master ~]# tar -zxvf /opt/software/jdk-8u152-linux
x64.tar.gz -C /usr/local/src
解压完成后,查看目录确认一下。可以看出 JDK 安装在
/usr/local/src/jdk1.8.0_152 目录中。
[root@master ~]# ll /usr/local/src
total 0
drwxr-xr-x. 7 root root 245 Oct 5 2019 jdk1.8.0_152
1.4.2.4.
步骤四:设置
JAVA
环境变量
在 Linux 中设置环境变量的方法比较多,较常见的有两种:一是配置
/etc/profile 文件,配置结果对整个系统有效,系统所有用户都可以使用;二
是配置~/bashrc 文件,配置结果仅对当前用户有效。这里使用第一种方法。
[root@master ~]# vi /etc/profile
在文件的最后增加如下两行:
# JAVA_HOME
指向
JAVA
安装目录
export JAVA_HOME=/usr/local/src/jdk1.8.0_152
第
2
章
Hadoop
平台安装
export PATH=$PATH:$JAVA_HOME/bin #
将
JAVA
安装目录加入
PATH
路径
执行 source 使设置生效:
[root@master ~]# source /etc/profile
检查 JAVA 是否可用。
[root@master ~]# echo $JAVA_HOME
/usr/local/src/jdk1.8.0_152/
说明 JAVA_HOME 已指向 JAVA 安装目录。
[root@master ~]# java -version
java version "1.8.0_152"
Java(TM) SE Runtime Environment (build 1.8.0_152-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.231-b11, mixed mode)
能够正常显示 Java 版本则说明 JDK 安装并配置成功。
注意:
可先在 slave1,slave2 虚拟机上安装 Java 环境,在第四章 Hadoop 全分
布上需应用到 Java 环境
6
第
2
章
Hadoop
平台安装
7
2.
实验二 安装
Hadoop
软件
2.1.
实验目标
完成本实验,您应该能够:
掌握
hadoop
的安装步骤
掌握
hadoop
的运行原理
掌握运行
hadoop
的基本命令
2.2.
实验要求
熟悉运行
hadoop
的基本命令
熟悉
hadoop
的运行原理
熟悉
hadoop
的安装步骤
2.3.
实验环境
本实验所需之主要资源环境如表
1-1
所示。
表 1-1 资源环境
服务器集群
单节点,机器最低配置:双核
CPU
、
8GB
内存、
100G
硬盘
运行环境
CentOS 7.4
服务和组件
完成前面章节的实验,其他服务和组件根据实验需求安装
2.4.
实验过程
2.4.1.
实验任务一:获取
Hadoop
安装包
Apache Hadoop
各个版本的下载网址:
https://archive.apache.org/dist/hadoop /common/。本教材选用的是 Hadoop
2.7.1 版本,安装包为 hadoop-2.7.1.tar.gz。
需要先下载 Hadoop 安装包,再上传到 Linux 系统的/opt/software 目录。具
体的方法见前一节“实验一 Linux 操作系统环境设置”,这里就不再赘述。
2.4.2.
实验任务二:安装
Hadoop
软件
2.4.2.1.
步骤一:安装
Hadoop
软件
安装命令如下,将安装包解压到/usr/local/src/目录下
[root@master ~]#
tar
-zxvf ~/hadoop-2.7.1.tar.gz
-C
/usr/local/src/
解 压 完 成 后 , 查 看 目 录 确 认 一 下 。 可 以 看 出 Hadoop 安装在
第
2
章
Hadoop
平台安装
/usr/local/src/hadoop -2.7.1 目录中。
[root@master ~]# ll /usr/local/src/
total 0
drwxr-xr-x. 9 root root 149 6
月
29 2015 hadoop-2.7.1
drwxr-xr-x. 7 root root 245 10
月
5 2019 jdk1.8.0_152
查看 Hadoop 目录,得知 Hadoop 目录内容如下:
[root@master ~]# ll /usr/local/src/hadoop-2.7.1/
total 28
drwxr-xr-x. 2 root root 194 6
月
29 2015 bin
drwxr-xr-x. 3 root root 20 6
月
29 2015 etc
drwxr-xr-x. 2 root root 106 6
月
29 2015 include
drwxr-xr-x. 3 root root 20 6
月
29 2015 lib
drwxr-xr-x. 2 root root 239 6
月
29 2015 libexec
-rw-r--r--. 1 root root 15429 6
月
29 2015 LICENSE.txt
-rw-r--r--. 1 root root 101 6
月
29 2015 NOTICE.txt
-rw-r--r--. 1 root root 1366 6
月
29 2015 README.txt
drwxr-xr-x. 2 root root 4096 6
月
29 2015 sbin
drwxr-xr-x. 4 root root 31 6
月
29 2015 share
其中:
bin:此目录中存放 Hadoop、HDFS、YARN 和 MapReduce 运行程序和管理软件。
etc:存放 Hadoop 配置文件。
include: 类似 C 语言的头文件
lib:本地库文件,支持对数据进行压缩和解压。
libexe:同 lib
sbin:Hadoop 集群启动、停止命令
share:说明文档、案例和依赖 jar 包。
2.4.2.2.
步骤二:配置
Hadoop
环境变量
和设置 JAVA 环境变量类似,修改/etc/profile 文件。
[root@master ~]# vi /etc/profile
在文件的最后增加如下两行:
# HADOOP_HOME
指向
JAVA
安装目录
export HADOOP_HOME=/usr/local/src/hadoop-2.7.1
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
执行 source 使用设置生效:
[root@master ~]# source /etc/profile
检查设置是否生效:
[root@master ~]# hadoop
8
第
2
章
Hadoop
平台安装
Usage: hadoop [--config confdir] [COMMAND | CLASSNAME]
CLASSNAME run the class named CLASSNAME
…… 省略 ……
出现上述 Hadoop 帮助信息就说明 Hadoop 已经安装好了。
2.4.2.3.
步骤三:修改目录所有者和所有者组
上述安装完成的 Hadoop 软件只能让 root 用户使用,要让 hadoop 用户能够
运行 Hadoop 软件,需要将目录/usr/local/src 的所有者改为 hadoop 用户。
[root@master ~]# chown -R hadoop:hadoop /usr/local/src
[root@master ~]# ll /usr/local/src
total 0
drwxr-xr-x. 9 hadoop hadoop 149 Jun 29 2015 hadoop-2.7.1
drwxr-xr-x. 7 hadoop hadoop 245 Oct 5 2019 jdk1.8.0_152
/usr/local/src 目录的所有者已经改为 hadoop 了。
9
第
2
章
Hadoop
平台安装
10
3.
实验三 安装单机版
Hadoop
系统
3.1.
实验目标
完成本实验,您应该能够:
掌握
hadoop
的安装步骤
掌握
hadoop
的运行原理
掌握运行
hadoop
的基本命令
3.2.
实验要求
熟悉运行
hadoop
的基本命令
熟悉
hadoop
的运行原理
熟悉
hadoop
的安装步骤
3.3.
实验环境
本实验所需之主要资源环境如表
1-1
所示。
表 1-1 资源环境
服务器集群
单节点,机器最低配置:双核
CPU
、
8GB
内存、
100G
硬盘
运行环境
CentOS 7.4
服务和组件
完成前面章节的实验,其他服务和组件根据实验需求安装
3.4.
实验过程
3.4.1.
实验任务一:配置
Hadoop
配置文件
进入 Hadoop 目录
[root@master ~]# cd /usr/local/src/hadoop-2.7.1/
配置 hadoop-env.sh 文件,目的是告诉 Hadoop 系统 JDK 的安装目录。
[root@master ~]# vi etc/hadoop/hadoop-env.sh
在文件中查找 export JAVA_HOME 这行,将其改为如下所示内容。
export JAVA_HOME=/usr/local/src/jdk1.8.0_152
这样就设置好 Hadoop 的本地模式,下面使用官方案例来测试 Hadoop 是否运
行正常。
第
2
章
Hadoop
平台安装
3.4.2.
实验任务二:测试
Hadoop
本地模式的运
行
3.4.2.1.
步骤一
:
切换到
hadoop
用户
使用 hadoop 这个用户来运行 Hadoop 软件。
[root@master ~]# su - hadoop
[hadoop@master ~]$
3.4.2.2.
步骤二
:
创建输入数据存放目录
将输入数据存放在~/input 目录(hadoop 用户主目录下的 input 目录中)。
[hadoop@master ~]$ mkdir ~/input
3.4.2.3.
步骤三
:
创建数据输入文件
创建数据文件 data.txt,将要测试的数据内容输入到 data.txt 文件中。
[hadoop@master ~]$ vi ~/input/data.txt
输入如下内容,保存退出。
Hello World
Hello Hadoop
Hello Huasan
3.4.2.4.
步骤四
:
测试
MapReduce
运行
运行 WordCount 官方案例,统计 data.txt 文件中单词的出现频度。这个案
例可以用来统计年度十大热销产品、年度风云人物、年度最热名词等。命令如下:
[hadoop@master ~]$ hadoop jar /usr/local/src/hadoop-
2.7.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar
wordcount ~/input/data.txt ~/output
运行结果保存在~/output 目录中,命令执行后查看结果:
[hadoop@master ~]$ ll ~/output
total 4
-rw-r--r--. 1 hadoop hadoop 34 May 2 12:08 part-r-00000
-rw-r--r--. 1 hadoop hadoop 0 May 2 12:08 _SUCCESS
文件_SUCCESS 表示处理成功,处理的结果存放在 part-r-00000 文件中,查
看该文件。
[hadoop@master ~]$ cat ~/output/part-r-00000
Hadoop 1
Hello 3
Huasan 1
World 1
可以看出统计结果正确,说明 Hadoop 本地模式运行正常。读者可将这个运
行结果与“3.2.3 MapReduce”中的 WordCount 案例运行过程进行对照,来加深
对 MapReduce 框架的理解。
11
第
2
章
Hadoop
平台安装
注意:输出目录不能事先创建,如果已经有~/output 目录,就要选择另外的
输出目录,或者将~/output 目录先删除。删除命令如下所示。
[hadoop@master ~]$ rm -rf ~/output
12
第 3 章 平台的基础环境配置
1
目录
1.
实验一:集群网络配置
................................................................................................... 2
1.1.
实验目的
............................................................................................................ 2
1.2.
实验要求
............................................................................................................ 2
1.3.
实验环境
............................................................................................................ 2
1.4.
实验过程
............................................................................................................ 2
1.4.1.
实验任务一:实验环境下集群网络配置
........................................................ 2
2.
实验二
SSH
无密码验证配置
.......................................................................................... 3
2.1.
实验目标
............................................................................................................ 3
2.2.
实验要求
............................................................................................................ 3
2.3.
实验环境
............................................................................................................ 3
2.4.
实验过程
............................................................................................................ 3
2.4.1.
实验任务一:生成
SSH
密钥
............................................................................ 3
2.4.2.
实验任务二:交换
SSH
密钥
............................................................................ 7
2.4.3.
实验任务三:验证
SSH
无密码登录
................................................................ 8
第
3
章 平台的基础环境配置
2
1.
实验一:集群网络配置
1.1.
实验目的
完成本实验,您应该能够:
掌握集群网络连接与配置
1.2.
实验要求
熟悉集群网络连接与配置
1.3.
实验环境
本实验所需之主要资源环境如表
1-1
所示。
表 1-1 资源环境
服务器集群
3
个以上节点,节点间网络互通,各节点最低配置:双核
CPU
、
8GB
内存、
100G
硬盘
运行环境
CentOS 7.4
服务和组件
完成前面章节的实验,其他服务根据实验需求安装
1.4.
实验过程
1.4.1.
实验任务一:实验环境下集群网络配置
修改 slave1 机器主机名
[root@VM-M-01597287168620 ~]# hostnamectl set-hostname slave1
修改 slave2 机器主机名
[root@VM-M-01597287169688 ~]# hostnamectl set-hostname slave2
根据实验环境下集群网络 IP 地址规划,为主机 master 设置 IP 地址是“192.168.1.6”,
掩码是“255.255.255.0”;slave1 设置 IP 地址是“192.168.1.7”,掩码是“255.255.255.0”;
slave2 设置 IP 地址是“192.168.1.8”,掩码是“255.255.255.0”。
根据我们为 Hadoop 设置的主机名为“master、slave1、slave2”,映射地址是
“192.168.1.6、192.168.1.7、192.168.1.8”,分别修改主机配置文件“/etc/hosts”,在
命令终端输入如下命令:
[root@VM-M-01597287168620 ~]# vi /etc/hosts
192.168.1.6 master
192.168.1.7 slave1
192.168.1.8 slave2
[root@VM-M-01597287169688 ~]# vi /etc/hosts
192.168.1.6 master
第
3
章 平台的基础环境配置
3
192.168.1.7 slave1
192.168.1.8 slave2
[root@master ~]# vi /etc/hosts
192.168.1.7 slave1
192.168.1.8 slave2
配置完毕,执行“reboot”命令重新启动系统。
2.
实验二
SSH
无密码验证配置
2.1.
实验目标
完成本实验,您应该能够:
掌握
SSH
无密钥登录配置
2.2.
实验要求
熟悉
SSH
无密钥登录配置
2.3.
实验环境
本实验所需之主要资源环境如表
1-1
所示。
表 1-1 资源环境
服务器集群
3
个以上节点,节点间网络互通,各节点最低配置:双核
CPU
、
8GB
内存、
100G
硬盘
运行环境
CentOS 7.4
服务和组件
完成前面章节的实验,其他服务根据实验需求安装
2.4.
实验过程
2.4.1.
实验任务一:生成
SSH
密钥
2.4.1.1.
步骤一:每个节点安装和启动
SSH
协议
实现 SSH 登录需要 openssh 和 rsync 两个服务,一般情况下默认已经安装,可以通过
下面命令查看结果。
[root@master ~]# rpm -qa | grep openssh
openssh-server-7.4p1-11.el7.x86_64
openssh-7.4p1-11.el7.x86_64
openssh-clients-7.4p1-11.el7.x86_64
[root@master ~]# rpm -qa | grep rsync
rsync-3.1.2-6.el7_6.1.x86_64
第
3
章 平台的基础环境配置
2.4.1.2.
步骤二:切换到 hadoop 用户
[root@master ~]# su – hadoop
[root@slave1 ~]# su – hadoop
[root@slave2 ~]# su – hadoop
2.4.1.3.
步骤三:每个节点生成秘钥对
#
在
master
上生成密钥
[hadoop@master ~]$ ssh-keygen -t rsa -P ''
Generating public/private rsa key pair.
Enter file in which to save the key (/home/hadoop/.ssh/id_rsa):
Your identification has been saved in /home/hadoop/.ssh/id_rsa.
Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:UxFuDHHLiMNQsZ11o3F7NApvDPfKMBqaxE+rlccKdk4
hadoop@master
The key's randomart image is:
+---[RSA 2048]----+
| ..o.o.O.= o |
| + + X & * . |
| B * @ * o |
| . * O = o |
| = E o o |
| . B + |
| . o |
| |
| |
+----[SHA256]-----+
#slave1
生成密钥
[hadoop@slave1 ~]$ ssh-keygen -t rsa -P ''
#slave2
生成密钥
[hadoop@slave2 ~]$ ssh-keygen -t rsa -P ''
2.4.1.4.
步骤四:查看
"/home/hadoop/"
下是否有
".ssh"
文件夹,且
".ssh"
文件下是否有两
个刚生产的无密码密钥对。
[hadoop@master .ssh]$ cd ~/.ssh/
[hadoop@master .ssh]$ ls
id_rsa id_rsa.pub
2.4.1.5.
步骤五:将 id_rsa.pub 追加到授权 key 文件中
#master
[hadoop@master .ssh]$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
[hadoop@master .ssh]$ ls ~/.ssh/
4
第
3
章 平台的基础环境配置
authorized_keys id_rsa id_rsa.pub
#slave1
[hadoop@slave1 ~]$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
[hadoop@slave1 .ssh]$ ls ~/.ssh/
authorized_keys id_rsa id_rsa.pub
#slave2
[hadoop@slave2 ~]$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
[hadoop@slave2 .ssh]$ ls ~/.ssh/
authorized_keys id_rsa id_rsa.pub
2.4.1.6.
步骤六:修改文件"authorized_keys"权限
通过 ll 命令查看,可以看到修改后 authorized_keys 文件的权限为“rw-------”,表
示所有者可读写,其他用户没有访问权限。如果该文件权限太大,ssh 服务会拒绝工作,出
现无法通过密钥文件进行登录认证的情况。
#master
[hadoop@master .ssh]$ chmod 600 ~/.ssh/authorized_keys
[hadoop@master .ssh]$ ll ~/.ssh/
总用量
12
-rw-------. 1 hadoop hadoop 395 4
月
9 15:34 authorized_keys
-rw-------. 1 hadoop hadoop 1679 4
月
9 15:26 id_rsa
-rw-r--r--. 1 hadoop hadoop 395 4
月
9 15:26 id_rsa.pub
#slave1
[hadoop@slave1 .ssh]$ chmod 600 ~/.ssh/authorized_keys
[hadoop@slave1 .ssh]$ ll ~/.ssh/
总用量
12
-rw-------. 1 hadoop hadoop 395 4
月
9 15:34 authorized_keys
-rw-------. 1 hadoop hadoop 1679 4
月
9 15:26 id_rsa
-rw-r--r--. 1 hadoop hadoop 395 4
月
9 15:26 id_rsa.pub
#slave2
[hadoop@slave2 .ssh]$ chmod 600 ~/.ssh/authorized_keys
[hadoop@slave2 .ssh]$ ll ~/.ssh/
总用量
12
-rw-------. 1 hadoop hadoop 395 4
月
9 15:34 authorized_keys
5
第
3
章 平台的基础环境配置
-rw-------. 1 hadoop hadoop 1679 4
月
9 15:26 id_rsa
-rw-r--r--. 1 hadoop hadoop 395 4
月
9 15:26 id_rsa.pub
2.4.1.7.
步骤七:配置 SSH 服务
使用 root 用户登录,修改 SSH 配置文件"/etc/ssh/sshd_config"的下列内容,需要将
该配置字段前面的#号删除,启用公钥私钥配对认证方式。
#master
[hadoop@master .ssh]$ su - root
[root@master ~]# vi /etc/ssh/sshd_config
PubkeyAuthentication yes
#slave1
[hadoop@slave1 .ssh]$ su - root
[root@slave1 ~]# vi /etc/ssh/sshd_config
PubkeyAuthentication yes
#slave2
[hadoop@slave2 .ssh]$ su - root
[root@slave2 ~]# vi /etc/ssh/sshd_config
PubkeyAuthentication yes
2.4.1.8.
步骤八:重启 SSH 服务
设置完后需要重启 SSH 服务,才能使配置生效。
[root@master ~]# systemctl restart sshd
2.4.1.9.
步骤九:切换到 hadoop 用户
[root@master ~]# su - hadoop
上一次登录:四
4
月
9 15:25:35 CST 2020pts/0
上
2.4.1.10.
步骤十:验证 SSH 登录本机
在 hadoop 用户下验证能否嵌套登录本机,若可以不输入密码登录,则本机通过密钥登
录认证成功。
[hadoop@master ~]$ ssh localhost
The authenticity of host 'localhost (::1)' can't be established.
ECDSA key fingerprint is
SHA256:mCBXMeGA6BsP/aYJH3Ie5723JAWRSOzBr7FReICWLtQ.
ECDSA key fingerprint is
MD5:b2:88:99:ee:00:30:24:61:75:7e:7f:8a:f5:d0:98:97.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'localhost' (ECDSA) to the list of
6
第
3
章 平台的基础环境配置
known hosts.
Last login: Thu Apr 9 16:02:14 2020
首次登录时会提示系统无法确认 host 主机的真实性,只知道它的公钥指纹,询问用户
是否还想继续连接。需要输入“yes”,表示继续登录。第二次再登录同一个主机,则不会再
出现该提示,可以直接进行登录。
读者需要关注是否在登录过程中是否需要输入密码,不需要输入密码才表示通过密钥认
证成功。
2.4.2.
实验任务二:交换
SSH
密钥
2.4.2.1.
步骤一:将
Master
节点的公钥
id_rsa.pub
复制到每个
Slave
点
hadoop 用户登录,通过 scp 命令实现密钥拷贝。
[hadoop@master ~]$ scp ~/.ssh/id_rsa.pub hadoop@slave1:~/
[hadoop@master ~]$ scp ~/.ssh/id_rsa.pub hadoop@slave2:~/
The authenticity of host 'slave1 (192.168.10.12)' can't be
established.
ECDSA key fingerprint is
SHA256:VQHM02+x2s0xCE7Qw+EbjdPfgfZV3W7B+gDiozC80c4.
ECDSA key fingerprint is
MD5:3e:a1:47:e9:fe:1b:55:7e:cf:a9:90:58:9b:a2:0d:26.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'slave1,192.168.10.12' (ECDSA) to the
list of known hosts.
hadoop@slave1's password:
id_rsa.pub
100% 395 259.2KB/s 00:00
首次远程连接时系统会询问用户是否要继续连接。需要输入“yes”,表示继续。因为
目前尚未完成密钥认证的配置,所以使用 scp 命令拷贝文件需要输入 slave1 节点 hadoop
用户的密码。
2.4.2.2.
步骤二:在每个 Slave 节点把 Master 节点复制的公钥复制到 authorized_keys 文
件
hadoop 用户登录 slave1 和 slave2 节点,执行命令。
[hadoop@slave1 ~]$ cat ~/id_rsa.pub >>~/.ssh/authorized_keys
[hadoop@slave2 ~]$ cat ~/id_rsa.pub >>~/.ssh/authorized_keys
2.4.2.3.
步骤三:在每个 Slave 节点删除 id_rsa.pub 文件
[hadoop@slave1 ~]$ rm -f ~/id_rsa.pub
[hadoop@slave2 ~]$ rm -f ~/id_rsa.pub
2.4.2.4.
步骤四:将每个 Slave 节点的公钥保存到 Master
(1)将 Slave1 节点的公钥复制到 Master
[hadoop@slave1 ~]$ scp ~/.ssh/id_rsa.pub hadoop@master:~/
7
第
3
章 平台的基础环境配置
The authenticity of host 'master (192.168.10.11)' can't be
established.
ECDSA key fingerprint is
SHA256:mCBXMeGA6BsP/aYJH3Ie5723JAWRSOzBr7FReICWLtQ.
ECDSA key fingerprint is
MD5:b2:88:99:ee:00:30:24:61:75:7e:7f:8a:f5:d0:98:97.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'master,192.168.10.11' (ECDSA) to the
list of known hosts.
hadoop@master's password:
id_rsa.pub
100% 395 51.5KB/s 00:00
(2)在 Master 节点把从 Slave 节点复制的公钥复制到 authorized_keys 文件
[hadoop@master ~]$ cat ~/id_rsa.pub >>~/.ssh/authorized_keys
(3)在 Master 节点删除 id_rsa.pub 文件
[hadoop@master ~]$ rm -f ~/id_rsa.pub
(1)将 Slave2 节点的公钥复制到 Master
[hadoop@slave2 ~]$ scp ~/.ssh/id_rsa.pub hadoop@master:~/
The authenticity of host 'master (192.168.10.11)' can't be
established.
ECDSA key fingerprint is
SHA256:mCBXMeGA6BsP/aYJH3Ie5723JAWRSOzBr7FReICWLtQ.
ECDSA key fingerprint is
MD5:b2:88:99:ee:00:30:24:61:75:7e:7f:8a:f5:d0:98:97.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'master,192.168.10.11' (ECDSA) to the
list of known hosts.
hadoop@master's password:
id_rsa.pub
100% 395 51.5KB/s 00:00
(2)在 Master 节点把从 Slave 节点复制的公钥复制到 authorized_keys 文件
[hadoop@master ~]$ cat ~/id_rsa.pub >>~/.ssh/authorized_keys
(3)在 Master 节点删除 id_rsa.pub 文件
[hadoop@master ~]$ rm -f ~/id_rsa.pub
2.4.3.
实验任务三:验证
SSH
无密码登录
2.4.3.1.
步骤一:查看
Master
节点
authorized_keys
文件
[hadoop@master .ssh]$ cat ~/.ssh/authorized_keys
可以看到 Master 节点 authorized_keys 文件中包括 master、slave1、slave2 三个节点
的公钥。
2.4.3.2.
步骤二:查看 Slave 节点 authorized_keys 文件
[hadoop@slave1.ssh]$ cat ~/.ssh/authorized_keys
[hadoop@slave2.ssh]$ cat ~/.ssh/authorized_keys
8
第
3
章 平台的基础环境配置
可以看到 Slave 节点 authorized_keys 文件中包括 Master、当前 Slave 两个节点的公
钥。
2.4.3.3.
步骤三:验证 Master 到每个 Slave 节点无密码登录
hadoop 用户登录 master 节点,执行 SSH 命令登录 slave1 和 slave2 节点。可以观察到
不需要输入密码即可实现 SSH 登录。
[hadoop@master ~]$ ssh slave1
Last login: Thu Apr 9 19:24:36 2020
[hadoop@slave1 ~]$
[hadoop@master ~]$ ssh slave2
Last login: Thu Apr 9 19:32:09 2020
[hadoop@slave2 ~]$
2.4.3.4.
步骤四:验证两个 Slave 节点到 Master 节点无密码登录
[hadoop@slave1 ~]$ ssh master
Last login: Thu Apr 9 19:19:07 2020
[hadoop@master ~]$
子节点的JDK安装参考“第二章 安装JAVA环境”。安装成功JDK后即可开始安装Hadoop
分布式环境。
9
实训 3 伪分布式 hadoop 搭建
要求:
1
、配置
linux
环境(
单节点,机器最低配置:双核
CPU
、
8GB
内存、
100G
硬盘
)
2
、完成前面章节的实验(单机版
Hadoop
系统)
实验过程:(可在
hadoop
官网查看文档说明:
https://archive.apache.org
)
一、修改
etc/hadoop/core-site.xml
文件
可直接按照官网配置。
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/src/hadoop/tmp</value>
</property>
</configuration>
二、修改
hadoop
安装目录下
etc/hadoop/hdfs-site.xml
文件
可直接按照官网配置。
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
三、
Hadoop
格式化
步骤一:
NameNode
格式化
[root@master ~]# su – hadoop
[hadoop@master ~]# cd /usr/local/src/hadoop/
[hadoop@master hadoop]$ bin/hdfs namenode –format
步骤二:启动
NameNode
并查看进程
[hadoop@master hadoop]$ sbin/hadoop-daemon.sh start namenode
[hadoop@master hadoop]$ jps
步骤三:启动
DataNode
[hadoop@master hadoop]$ sbin/hadoop-daemon.sh start datanode
[hadoop@master hadoop]$ jps
四、通过浏览器查看节点状态
在浏览器的地址栏输入
http://master:50070
,进入页面可以查看
NameNode
和
DataNode
信息
五、测试
MapReduce
运行(
wordcount
案例)
[hadoop@master hadoop]$ bin/hdfs dfs -mkdir /input
[hadoop@master hadoop]$ bin/hdfs dfs -put ~/data.txt /input
[hadoop@master hadoop]$hadoop jar
/usr/local/src/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar
wordcount /input/data.txt /output
[hadoop@master hadoop]$ bin/hdfs dfs -cat
/output/part-r-00000
或者通过网页查
看统计结果。
六、配置集群在
Yarn
上运行
mapreduce
步骤一:配置
etc/hadoop/yarn-env.sh
,修改其中的
JAVA_HOME
变量(可不配,该文件内容
包含在
hadoop-env.sh
文件中)
步骤二:修改
etc/hadoop/yarn-site.xml
文件
可直接按照官网配置。
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
步骤三:配置
etc/hadoop/mapred-env.sh
,修改其中的
JAVA_HOME
变量(可不配,该文件内
容包含在
hadoop-env.sh
文件中)
步骤四:修改
etc/hadoop/mapred-site.xml
文件
默认没有
mapred-site.xml
文件,只有
mapred-site.xml.template
模版文件
可以重命名:
[hadoop@master hadoop]$mv mapred-site.xml.template mapred-site.xml
可直接按照官网配置。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
七、启动集群服务(
yarn
进程)
启动
yarn
进程之前,必须保证
namenode
和
datanode
已经被启动起来了。
输入命令:
启动
resourcemanager
[hadoop@master hadoop]$yarn-daemon.sh start resourcemanager
启动
nodemanager
[hadoop@master hadoop]$ yarn-daemon.sh start nodemanager
[hadoop@master hadoop]$jps
八、通过浏览器查看
mapreduce
在浏览器的地址栏输入地址:
master:8088
,进入页面可以查看程序运行过程
四、 完全分布式 hadoop 系统搭建
实验目的
完成本实验,您应该能够:
⚫
掌握
hadoop
全分布的配置
⚫
掌握
hadoop
全分布的安装
⚫
掌握
hadoop
配置文件的参数意义
实验要求
⚫
熟悉
hadoop
全分布的安装
⚫
了解
hadoop
配置文件的意义
实验环境
本实验所需之主要资源环境如下表所示。
资源环境表
服务器集群
2
个节点,节点间网络互通,各节点最低配置:双核
CPU
、
2GB
内存、
100G
硬盘
运行环境
CentOS 7.4
实验过程
一、集群部署规划
1.
集群架构规划,如表
1-1
所示。
表
1-1
master
slave1
Slave2
……
HDFS
NameNode
SecondaryNameNode
DataNode
DataNode
DataNode
……
YARN
ResourceManager
NodeManager
NodeManager
NodeManager
……
2.
集群网络规划,如表
1.2
所示(仅主机模式下配置)。
表
1-2
master
slave1
Slave2
……
IP
地址
192.168.1.2
192.168.1.3
192.168.1.4
……
二、
master
节点配置
1. Linux
环境配置
1.1
更改主机名为
master
1.2
对
master
节点配置网络
编辑网卡配置文件
/etc/sysconfig/network-scripts/ifcfg-en*
完成后重启网络。
1.3
绑定主机名和
IP
地址
编辑
/etc/hosts
文件。
1.4
关闭防火墙
1.5
新建
hadoop
用户
1.6
配置
ssh
服务,实现主机
master
免密访问主机
slave1
1.6.1
生成
SSH
密钥,实现本机免密登录
1
)切换用户为
hadoop
,并生成
SSH
密钥对
2
)将主机
master
下
hadoop
用户公钥文件追加到授权
key
文件中
3
)修改
key
文件
"authorized_keys"
权限
4
)验证
SSH
登录本机(主机
master
),完成后退出登录。
1.6.2
交换
SSH
密钥
1
)将主机
master
中的公钥复制到主机
slave1
中
2
)在主机
slave1
中切换用户为
hadoop
,并生成
SSH
密钥对
3
)在主机
slave1
中把从主机
master
中复制的公钥授权给
authorized_keys
文件
4
)修改
authorized_keys
文件权限
1.6.3
验证主机
master
到主机
slave1
的
SSH
无密码登录
,完成后退出登录。
2. java
安装和配置
2.1
切换
root
用户,卸载自带
OpenJDK
2.2
安装
JDK
2.3
设置
JAVA
环境变量
3
.
hadoop
安装和配置
3.1
安装
hadoop
3.2
设置
hadoop
环境变量
3.3
修改
hadoop
和
jdk
安装目录权限
3.4
关联
java
4
.配置
core-site.xml
文件
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/src/hadoop/tmp</value>
</property>
</configuration>
编辑完成后,新建文件夹
/usr/local/src/hadoop/tmp
5
.配置
hdfs-site.xml
文件
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/src/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/src/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
编辑完成后,新建文件夹
/usr/local/src/hadoop/dfs/data
和
/usr/local/src/hadoop/dfs/name
注意:如果
secondarynamenode
和
namenode
不在同一节点中,还需在
hdfs-site.xml
文
件配置参数
dfs.namenode.secondary.http-address
,值为
secondarynamenode
所在主机
名:端口号(
50090
),例如:
6
.配置
yarn-site.xml
文件
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--
指定
YARN
的
ResourceManager
的地址
-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>slave1</value>
</property>
</configuration>
7
.配置
mapred-site.xml
文件
生成
mapred-site.xml
文件后,编辑该文件
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
8
.配置
/usr/local/src/hadoop/etc/hadoop/slaves
文件
该文件用来记录所有的数据节点主机,即
datanode
注意:该文件中不允许出现任何空格
三、
slave1
节点配置
1. Linux
环境配置
1.1
更改主机名为
slave1
1.2
对
slave1
节点配置网络
编辑网卡配置文件
/etc/sysconfig/network-scripts/ifcfg-en*
完成后重启网络。
1.3
绑定主机名和
IP
地址
编辑
/etc/hosts
文件。
1.4
关闭防火墙
1.5
新建
hadoop
用户
1.6
配置
ssh
服务,实现主机
slave1
免密访问主机
master
1.6.1
生成
SSH
密钥,实现本机免密登录
1
)切换
hadoop
用户,将主机
slave1
下
hadoop
用户公钥文件追加到授权
key
文件中
2
)验证
SSH
登录本机(主机
slave1
),完成后退出登录。
1.6.2
交换
SSH
密钥
1
)将主机
slave1
中的公钥复制到主机
master
中
2
)在主机
master
中把从主机
slave1
中复制的公钥授权给
authorized_keys
文件
1.6.3
验证主机
slave1
到主机
master
的
SSH
无密码登录
,完成后退出登录。
2
.
java
安装和配置
3. hadoop
安装和配置
4.
配置
core-site.xml
文件
5.
配置
hdfs-site.xml
文件
6.
配置
mapred-site.xml
文件
7.
配置
yarn-site.xml
文件
8
.配置
/usr/local/src/hadoop/etc/hadoop/slaves
文件
四、集群的启动
1.
切换到
hadoop
用户,设置
Hadoop
格式化
2.
启动
hdfs
3.
启动
yarn
注意对比集群单点启动使用命令:
启动
SecondaryNameNode
:
启动
NameNode
:
启动
dataNode
:
启动
resourcemanager:
启动
nodemanager:
Hadoop伪分布式
将虚拟机ip和主机名绑定
vi /etc/hosts
192.168.1.6 master
启动并检测ssh服务运行正常
systemctl status sshd
关闭防火墙
systemctl stop firewalld.service
systemctl status firewalld.service
新建hadoop用户
useradd hadoop
安装并配置Java
卸载openjdk
rpm -qa | grep java
安装java、hadoop
tar zxf /software/jdk-8u152-linux-x64.tar.gz -C /use/local/src/
java -version
tar zxf /software/hadoop-2.7.1.tar.gz -C /use/local/src/
hadoop
配置环境变量
export JAVA_HOME= /use/local/src/java
export PATH= $PATH:$JAVA_HOME/bin
export HADOOP_HOME= /use/local/src/hadoop
export PATH= $PATH:$HADOOP_HOME/bin:
source /etc/profile
cd /use/local/src
mv
mv
修改目录权限
chown -R hadoop:hadoop .
关联
su - hadoop
cd /use/local/src/hadoop/etc/hadoop/
ls
vi hadoop
export JAVA_HOME=/use/local/src/java
配置文件(四个)
vi hadoop-env.sh
vi core-site.xml
vi hdfs-size.xml
vi yarn-size.xml
Hadoop完全分布式 (课程版)
hostnamectl set-hostname master
hostnamectl set-hostname slave
ifconfig
vi /etc/sysconfig/network-scripts/ifcfg-eno16777736
systemctl restart network
电脑网络适配器启用
虚拟机“已连接”
ping master 不可以
ping 192.168.1.6 可以
vi /etc/hosts 绑定主机名
su - hadoop
exit
su - hadoop
ssh-keygen -t rsa -P ''
cd .ssh
cat id_rsa.pub >>authorized_keys
ll
cat authorized_keys
chmod 600 authorized_keys
ssh master
exit
第一个实现:master无密码访问master
scp id_rsa.pub hadoop@slave:~ 发送过去
切换slave主机
ssh-keygen -t rsa -P ''
ls -a
ls
cat id_rsa.pub >>.ssh/authorized_keys 授权
cat authorized_keys
chmod 600 authorized_keys
切换master
ssh slave
exit
第二个实现slave主机无密码访问master
Hadoop完全分布式 (作业版)
修改各节点主机名
hostnamectl set-hostname sxz1
hostnamectl set-hostname sxz2
hostnamectl set-hostname sxz3
为主机sxz1设置ip地址是"192.168.1.6",掩码是"255.255.255.0";
vi /etc/sysconfig/network-scripts/ifcfg-eno16777736
为主机sxz2设置ip地址是"192.168.1.7",掩码是"255.255.255.0
为主机sxz3设置ip地址是"192.168.1.8",掩码是"255.255.255.0
分别在三台主机中将集群所有主机ip地址和主机名绑定
vi /etc/hosts
192.168.1.6 sxz1
192.168.1.7 sxz2
192.168.1.8 sxz3
使用ping命令测试网络是否配置成功
ping sxz1
ping sxz2
ping sxz3
实现主机sxz1对主机sxz2访问时的ssh无密码验证配置
生成ssh密匙
在主机sxz1中切换用户为hadoop
su - hadoop
在主机sxz2中生成ssh密匙对
ssh-keygen -t rsa -P ''
查看生成密匙文件
ls -a
cd .ssh
ls
将公匙文件追加到授权key文件中
-
cd ~/.ssh
-
cat id_rsa.pub>>authorized_keys
修改key文件"authorized_keys"权限
ll
chmod 600 authorized_keys
ll
切换到root用户,配置ssh服务并重启服务
systemctl restart sshd
切换回hadoop用户
su - hadoop
验证ssh登录本机sxz
ssh sxz1
交换ssh密匙
将主机sxz1中的公匙复制到主机sxz2中
cd .ssh
ls
scp id_rsa.pub hadoop@sxz2:~
在主机sxz2中生成ssh密匙对
su - hadoop
ssh-keygen -t rsa -P ' '
在主机sxz2中把从主机sxz1中复制的公匙授权给authorized_keys文件
cat id_rsa.pub >>authorized_keys
修改authorized_keys文件权限
chmod 600 authorized_keys
cat authorized_keys
ll
验证ssh无密码登录
查看主机sxz2中的authorized_keys文件
ll authorized_keys
验证主机sxz1到主机sxz2无密码登录
ssh hadoop@sxz2
else
在做centos7安装hadoop是,需要用到配置ssh免密登录,按照网络上的一篇文章配置成功,特将其文章在此记载,当时为单机版,因此单机版的部分已经验证,集群版的未验证,在此仅做纪录,后面有机会再验证并修改注释。。。。
以下用三台centos为例,ip分别为192.168.44.138、192.168.44.139、192.168.44.140,分别对应别名master、slave1、slave2
1、首先在每个机器上执行
ssh-keygen -t rsa
一直按回车默认就好
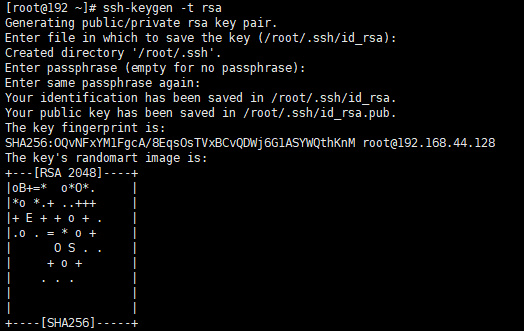
2、将公钥导入到认证文件中
将三个机器上id_rsa.pub的内容合并起来放在authorized_keys,可以用命令按下面的步骤来,也可以分别将三个机器的公钥拷贝出来放在一个文件里,之后分别复制到各自机器的authorized_keys,我用的是下面的命令
2.1 在master上执行
-
cd ~/.ssh
-
cat id_rsa.pub>>authorized_keys
(这时如果配单机的话,就可以免密登录本机了,可以执行ssh localhost 或ssh master验证一下,如下图)

如果不能免密登录,可能是文件权限不对,执行下面的命令,再验证一下
chmod 710 authorized_keys
然后将master的authorized_keys传到slave1上的.ssh目录下
scp -r authorized_keys root@slave1:~/.ssh

2.2 在slave1上执行
-
cd ~/.ssh
-
cat id_rsa.pub>>authorized_keys
-
scp -r authorized_keys root@slave2:~/.ssh
这一步实际是将salve1的id_rsa.pub和master传过来的authorized_keys里的内容合并起来存到authorized_keys,然后将authorized_keys传到slave2机器上
2.3 在slave2上执行
-
cd ~/.ssh
-
cat id_rsa.pub>>authorized_keys
-
scp -r authorized_keys root@master:~/.ssh
-
scp -r authorized_keys root@slave1:~/.ssh
这一步实际是将salve2的id_rsa.pub和slave1传过来的authorized_keys里的内容合并起来存到authorized_keys,然后将authorized_keys传到master、slave1机器上。
到这里,每台机器上的authorized_keys都含有三台机器的公钥,在每台机器上验证一下是否可以免密ssh登录到三台机器上了。
-
ssh master
-
ssh slave1
-
ssh slave2
如果都不需要输入密码,就代表配置成功!
四、 完全分布式 hadoop 系统搭建

二、master 节点配置
1. Linux
环境配置
1.1
更改主机名为
master
hostnamectl set-hostname master
1.2
对
master
节点配置网络
vi /etc/sysconfig/network-scripts/ifcfg-eno16777736
IPADDR=192.168.1.6
NETMASK=255.255.255.0
ONBOOT="yes"
完成后重启网络。
systemctl restart network
1.3 绑定主机名和 IP 地址
编辑/etc/hosts 文件。
1.4 关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
1.5 新建 hadoop 用户
1.6 配置 ssh 服务,实现主机 master 免密访问主机 slave1
1.6.1 生成 SSH 密钥,实现本机免密登录
1)切换用户为 hadoop,并生成 SSH 密钥对
su - hadoop
ssh-keygen -t rsa -P ''
2)将主机 master 下 hadoop 用户公钥文件追加到授权 key 文件中
cd .ssh
cat id_rsa.pub >>authorized_keys
3)修改 key 文件"authorized_keys"权限
chmod 600 authorized_keys
ll authorized_keys
4)验证 SSH 登录本机(主机 master),完成后退出登录。
ssh localhost
exit
1.6.2 交换 SSH 密钥
1)将主机 master 中的公钥复制到主机 slave中
scp .ssh/id_rsa.pub hadoop@slave:~
2)在主机 slave1 中切换用户为 hadoop,并生成 SSH 密钥对
su - hadoop
ssh-keygen -t rsa -P ''
3)在主机 slave1 中把从主机 master 中复制的公钥授权给 authorized_keys 文件
ls
cat id_rsa.pub >>.ssh/authorized_keys
4)修改 authorized_keys 文件权限
chmod 600 .ssh/authorized_keys
ll .ssh/authorized_keys
1.6.3 验证主机 master 到主机 slave1 的 SSH 无密码登录,完成后退出登录。
ssh slave
exit
2. java 安装和配置
2.1 切换 root 用户,卸载自带 OpenJDK
su root
rpm
2.2 安装 JDK
2.3 设置 JAVA 环境变量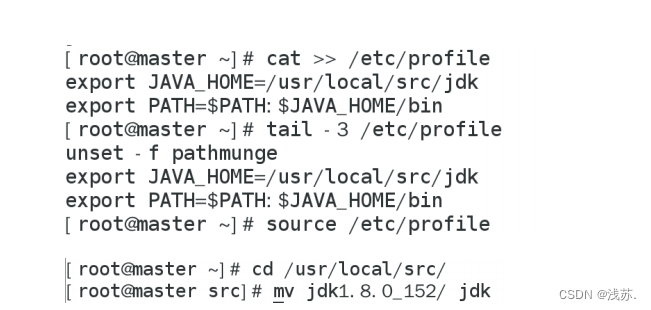
3.hadoop 安装和配置
3.1 安装 hadoop
3.2 设置 hadoop 环境变量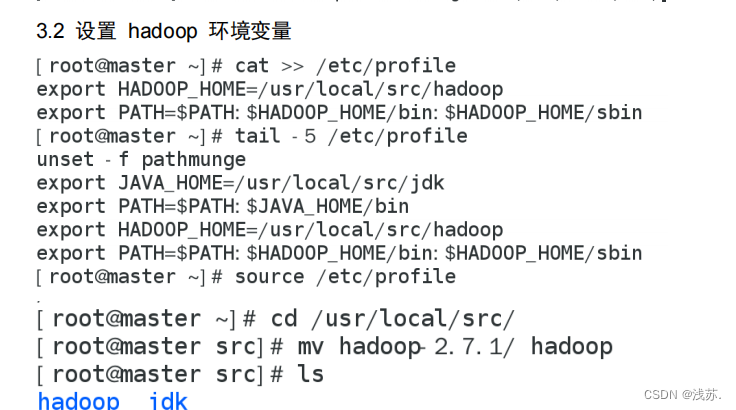
3.3 修改 hadoop 和 jdk 安装目录权限
chown -R hadoop:hadoop /usr/local/src/
3.4 关联 java
cd /usr/local/src/hadoop/etc/hadoop/
vi hadoop-env.sh
export JAVA_HOME=/usr/local/src/jdk
4.配置 core-site.xml 文件
cd /usr/local/src/hadoop/etc/hadoop/
vi core-size.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/src/hadoop/tmp</value>
</property>
</configuration>
编辑完成后,新建文件夹/usr/local/src/hadoop/tmp
mkdir /usr/local/src/hadoop/tmp
ls /usr/local/src/hadoop/
5.配置 hdfs-site.xml 文件
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/src/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/src/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
编辑完成后,新建文件夹/usr/local/src/hadoop/dfs/data 和/usr/local/src/hadoop/dfs/name
mkdir -p /usr/local/src/hadoop/dfs/data
mkdir -p /usr/local/src/hadoop/dfs/name
注意:如果 secondarynamenode 和 namenode 不在同一节点中,还需在 hdfs-site.xml 文
件配置参数 dfs.namenode.secondary.http-address,值为 secondarynamenode 所在主机
名:端口号(50090)
6.配置 yarn-site.xml 文件
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定 YARN 的 ResourceManager 的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>slave1</value>
</property>
</configuration>
7.配置 mapred-site.xml 文件
生成 mapred-site.xml 文件后,编辑该文件
mv mapred-size.xml.template mapred-size.xml
vi mapred-size.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
8.配置 /usr/local/src/hadoop/etc/hadoop/slaves 文件
pwd
cat etc/hadoop/slaves
该文件用来记录所有的数据节点主机,即 datanode
注意:该文件中不允许出现任何空格
三、slave1 节点配置
1. Linux 环境配置
1.1 更改主机名为 slave
1.2 对 slave节点配置网络
编辑网卡配置文件/etc/sysconfig/network-scripts/ifcfg-en*
完成后重启网络。
1.3 绑定主机名和 IP 地址
编辑/etc/hosts 文件。
1.4 关闭防火墙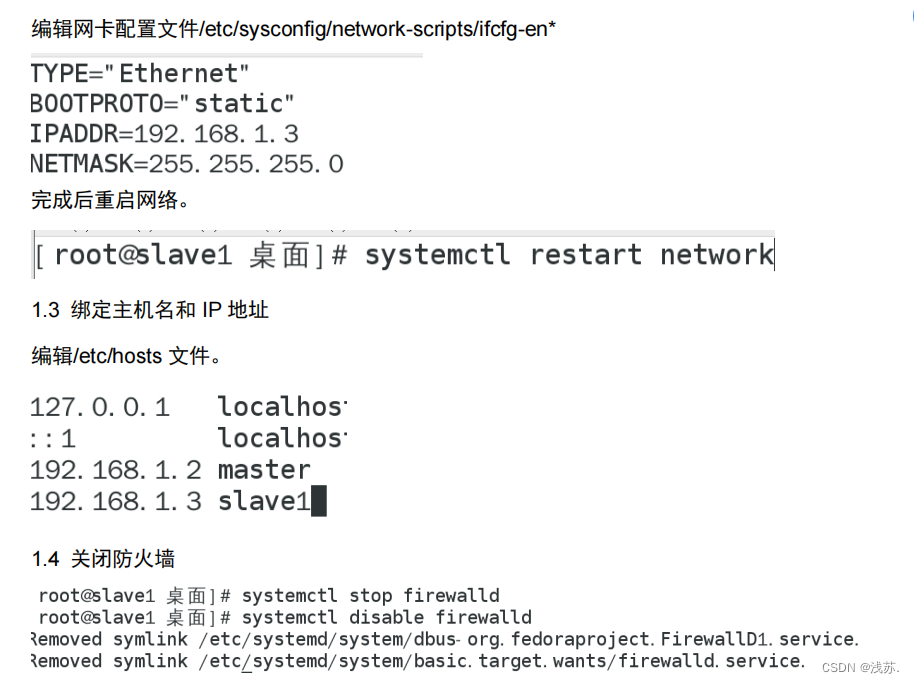
1.5 新建 hadoop 用户
1.6 配置 ssh 服务,实现主机 slave1 免密访问主机 master
1.6.1 生成 SSH 密钥,实现本机免密登录
1)切换 hadoop 用户,将主机 slave1 下 hadoop 用户公钥文件追加到授权 key 文件中
cd .ssh
cat id_rsa.pub >>.ssh/authorized_keys
2)验证 SSH 登录本机(主机 slave1),完成后退出登录。
ssh localhost
exit
1.6.2 交换 SSH 密钥
1)将主机 slave中的公钥复制到主机 master 中
cd .ssh
scp id_rsa.pub hadoop@master:~
2)在主机 master 中把从主机 slave1 中复制的公钥授权给 authorized_keys 文件
ls
cat id_rsa.pub >>.ssh/authorized_keys
1.6.3 验证主机 slave 到主机 master 的 SSH 无密码登录,完成后退出登录。
ssh master
exit
2.java 安装和配置
rpm -qa|grep java
rpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0.65-3.b17.el7.x86_64
rpm -e --nodeps java-1.8.0-openjdk-1.8.0.65-3.b17.el7.x86_64
3. hadoop 安装和配置
4. 配置 core-site.xml 文件
5. 配置 hdfs-site.xml 文件
6. 配置 mapred-site.xml 文件
7. 配置 yarn-site.xml 文件
8.配置 /usr/local/src/hadoop/etc/hadoop/slaves 文件
scp-r /usr/local/src/ root@slave:/usr/local/
scp /etc/profile root@slave:/etc
source /etc/profile
chown -R hadoop:hadoop /usr/local/src/
四、集群的启动
1. 切换到 hadoop 用户,设置 Hadoop 格式化
hdfs namenode -format
2. 启动 hdfs
start-dfs.sh
jps
3. 启动 yarn
start-yarn.sh
jps
注意对比集群单点启动使用命令:
启动 SecondaryNameNode:
hadoop-daemon.sh start SecondaryNameNode
启动 NameNode:
hadoop-daemon.sh start NameNode
启动 dataNode:
hadoop-daemon.sh start datanode
启动 resourcemanager:
yarn-daemon.sh start resourcemanager
启动 nodemanager:
yarn-daemon.sh start nodemanager
hadoop的启动
1.
vi /etc/profile
:$HADOOP_HOME/sbin
2.
vi /etc/hosts
scp /etc/profile /etc/hosts root@slave1:/etc
scp /etc/profile /etc/hosts root@slave2:/etc
su - hadoop
start-all.sh






















 2548
2548











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









