







实时数据一致性的定义以及面临的挑战
数据一致性通常指的是数据在整个系统或多个系统中保持准确、可靠和同步的状态。在实时数据处理中,一致性包括但不限于数据的准确性、完整性、时效性和顺序性。
下图是典型的实时/流式数据处理的流程:
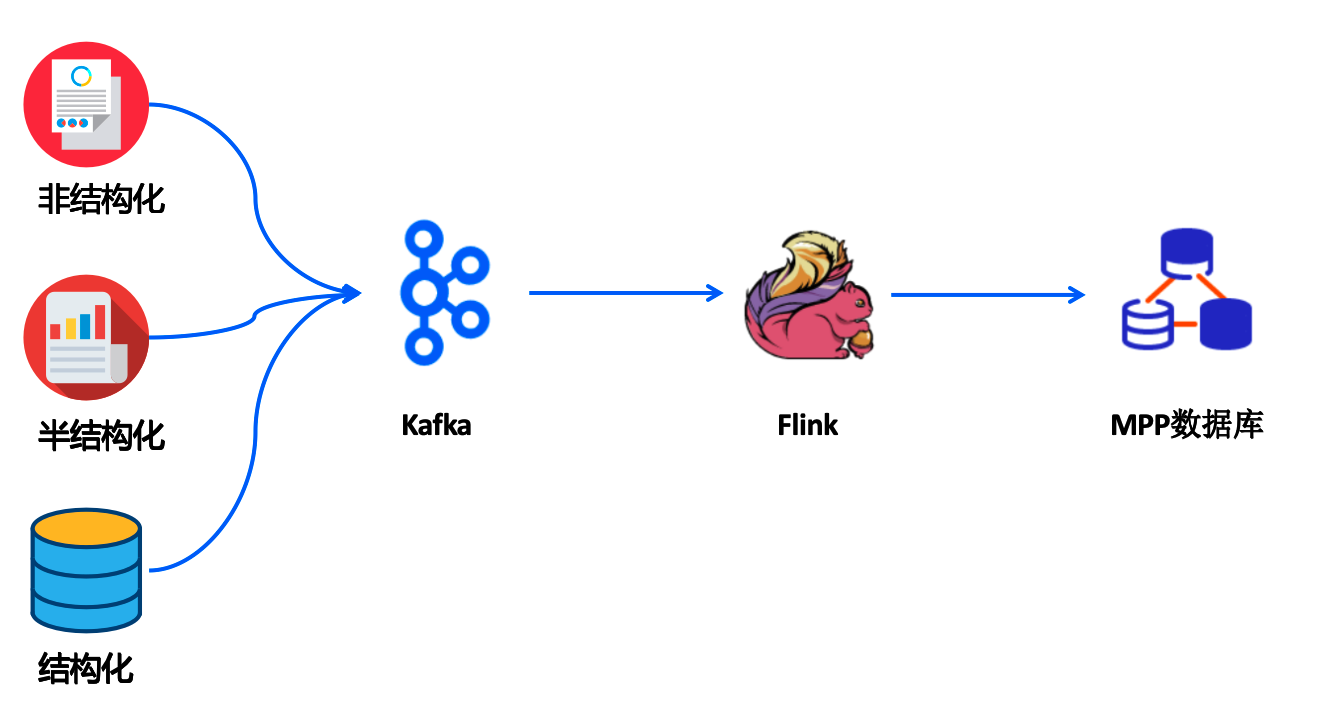
- 流式数据以各种方式推送到kafka中
- flink流式数据处理引擎将数据处理
- 处理完成的数据写入到Mpp数据库
由于整个数据链条是动态变化,因此,实时数据的一致性面临一些挑战。
高并发处理:实时系统需要处理大量并发数据流,增加了一致性维护的难度。主要是在分布式数据库端,如何处理高并发的写入?
网络延迟和故障:网络问题可能导致数据传输中断或延迟,影响数据同步。主要是在数据处理过程中如何保障数据处理的一致性?
实时数据处理系统如何保障一致性
数据源和数据处理之间采用消息队列
缓冲机制:使用消息队列作为缓冲,平衡数据生产者和消费者之间的速度差异。
顺序保证:确保消息按照发送顺序被处理。
Flink引擎在故障下保持数据一致性策略
数据重放(Data Replay)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











