







Spark引擎诞生的背景
Spark的发展历程可以追溯到2009年,由加州大学伯克利分校的AMPLab研究团队发起。成为Apache软件基金会的孵化项目后,于2012年发布了第一个稳定版本。
以下是Spark的主要发展里程碑:
- 初始版本发布:2010年开发的Matei Zaharia的研究项目成为Spark的前身。在2010年夏季,Spark首次公开亮相。
- Apache孵化项目:2013年,Apache Spark成为Apache软件基金会的孵化项目。这一举动增加了Spark的可信度和可靠性,吸引了更多的贡献者和用户。
- 发布1.0版本:2014年5月,Spark发布了第一个1.0版本,标志着其正式成熟和稳定可用。
- 成为顶级项目:2014年6月,Spark成为Apache软件基金会的顶级项目。这个里程碑确认了Spark在大数据处理领域的领导地位。
- Spark Streaming和MLlib:2014年6月,Spark 1.0版本中首次引入了Spark Streaming和MLlib(机器学习库),丰富了Spark的功能。
- Spark SQL和DataFrame:2015年,Spark 1.3版本中引入了Spark SQL和DataFrame API,使得开发者可以更方便地进行结构化数据处理。
- 发布2.0版本:2016年7月,Spark发布了2.0版本,引入了Dataset API,更加统一了Spark的编程模型。
- 扩展生态系统:Spark逐渐形成了一个庞大的生态系统,包括了许多扩展库和工具,如GraphX、SparkR、Sparklyr等。
- 运行更灵活:Spark不仅可以运行在独立模式下,还可以与其他大数据处理框架(如Hadoop YARN和Apache Mesos)集成。
目前,Spark已经成为大数据处理领域的主要引擎之一,并在各个行业和领域得到广泛应用。它的发展依然持续,持续推出新的功能和改进,以满足不断增长的大数据处理需求。
主要功能和hive 相比较的优势是哪些?
主要功能
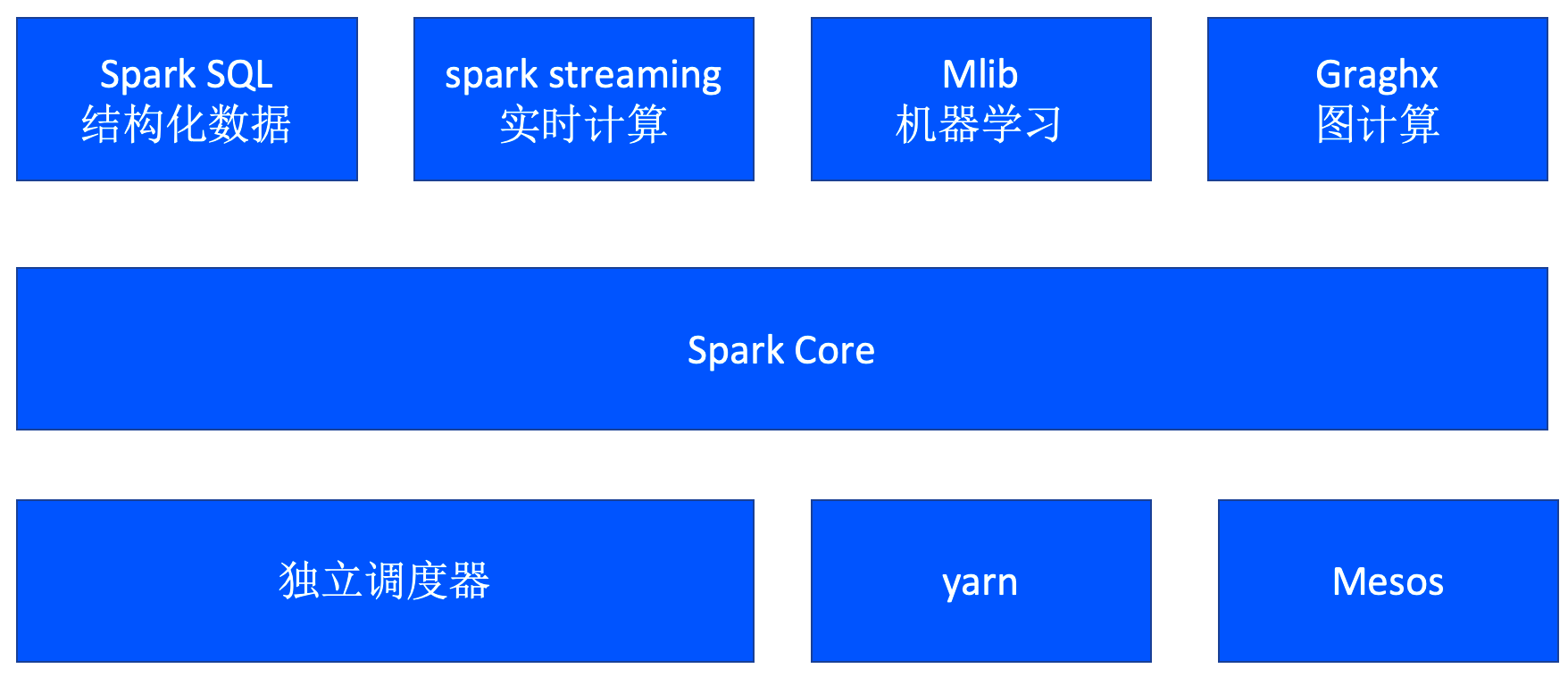
上图是spark 引擎的核心功能,其中包括Spark Core、Spark SQL、Spark Streaming、Spark MLlib、GraphX和Structured Streaming等。
- Spark Core:实现了Spark的基本功能,包含了RDD、任务调度、内存管理、错误恢复、与存储系统交互等模块。
- Spark SQL:用于操作结构化数据的程序包。通过Spark SQL,我们可以使用SQL操作数据,方便数据分析和处理。
- Spark Streaming:提供了对实时数据进行流式计算的组件。Spark Streaming提供了用于操作数据流的API,可以实时处理数据并进行计算。
- Spark MLlib:是Spark提供的机器学习功能的程序库。它包括了常见的机器学习算法,如分类、回归、聚类、协
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 9072
9072

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











