







目录
Excel文件读取
Day1
一.步骤解析(以统计火龙果可乐为例)
1.读取单个月份Excel表格数据
2.计算单个月份“火龙果可乐”的销售金额
3.计算多个月份“火龙果可乐”的销售金额
4.比较得出去年“火龙果可乐”哪个月份卖的最好
二.具体操作
1.读取单个月份Excel表格数据
(1)首先学习Excel基本结构:
一个Excel表格文件,又叫做一个工作簿(Workbook)。
一个工作簿中包含一个或多个工作表(Worksheet)。
在工作薄页面的左下方可以进行工作表的切换和增删。一个工作表由单元格(Cell)组成。Excel的数据存储在单元格中。
我们可以通过列号(Column)和行号(Row)对单元格进行定位。
行号默认从数字1开始,并依次递增。
列号默认从字母A开始,依次递增。超过字母Z后,以AA,AB的方式继续计数。

(2)分析得出需要的步骤 :
1. 读取工作表:“销售订单数据”
2. 逐行读取订单数据
3. 把“火龙果可乐”的订单总价相加
(3)前提条件
要使用Python对Excel表格进行读取,我们需要安装一个用于读取数据的工具 openpyxl 。openpyxl 是一个用于读、写Excel文件的开源模块。
安装openpyxl非常简单,在终端中输入代码:pip install openpyxl即可。
如果在自己电脑上安装不上或安装缓慢,可在命令后添加如下配置进行加速:
pip install openpyxl -i https://pypi.tuna.tsinghua.edu.cn/simple/
(4)读取指定路径的工作簿
在安装和导入openpyxl之后,读取指定路径的工作簿需要使用函数:openpyxl.load_workbook()。
工作簿文件的路径需要作为函数参数传入。若文件就在代码运行的工作目录,就可以直接传入文件名。 示例中,所有的Excel文件刚好都在工作目录 /Users/zhener/doc下。
我们读取了收到的12个Excel文件中的其中一个:2019年1月销售订单.xlsx,直接将文件名以字符串的形式填入函数的括号内即可。
openpyxl.load_workbook()函数读取成功后,会返回一个工作簿对象,本例中我们将这个对象赋值给了变量wb。
(5) 读取指定工作表
如果事先不知道工作簿内有哪些工作表,我们可以通过访问工作簿的 .sheetnames 属性来获取一个包含所有工作表名称的列表。
具体操作为在变量wb之后添加代码 .sheetnames 。
# 导入openpyxl模块
import openpyxl
# 读取工作目录里名为"2019年1月销售订单.xlsx"的工作簿并赋值给变量wb
wb = openpyxl.load_workbook("2019年1月销售订单.xlsx")
# 使用print输出工作簿中所有的工作表名称
print(wb.sheetnames)得到了工作表名称后,我们可以通过在变量wb后添加中括号[ ]和工作表名称的方式来获得对应的工作表对象。
Day1总结 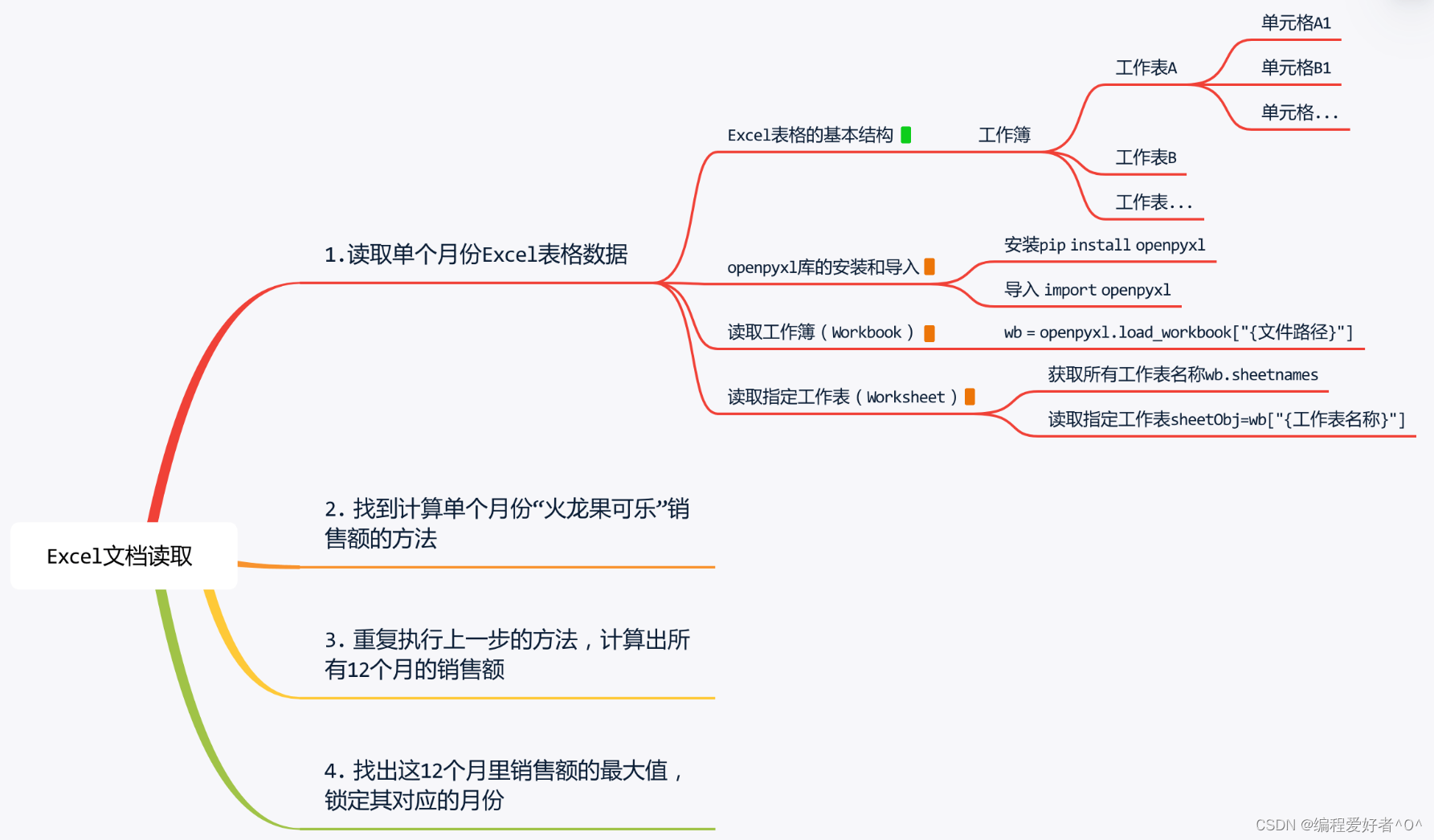
Day2
2.计算单个月份“火龙果可乐”的销售金额
(1)读取指定单元格
读取的单元格列数不区分大小写,C5和c5均可以正常读取
# 导入openpyxl模块
import openpyxl
# 读取工作目录里名为"2019年1月销售订单.xlsx"的工作簿并赋值给变量wb
wb = openpyxl.load_workbook("2019年1月销售订单.xlsx")
# 获取"销售商品"工作表
productSheet = wb["销售商品"]
# 使用print输出productSheet的C5单元格的值
print(productSheet["C5"].value)若单元格中包含公式,现有方式读取出的值是公式本身。
若需要读取公式计算后的值,要在读取工作簿的代码部分,传入一个参数: data_only=True ,便可以得出公式计算后的值了。# 导入openpyxl模块 import openpyxl # 原打开方式,直接读取公式本身 wb = openpyxl.load_workbook("2019年1月销售订单.xlsx") orderSheet = wb["销售订单数据"] # 输出公式本身 print(orderSheet["I3"].value) # 添加data_only=True打开工作簿,获取公式计算后的值 wb2 = openpyxl.load_workbook("2019年1月销售订单.xlsx", data_only=True) orderSheet2 = wb2["销售订单数据"] # 输出公式计算后的值 print(orderSheet2["I3"].value)
output
=G3*H3 20
(2)行数据的遍历
要对整个工作表的每一行数据进行浏览查询,可以使用for循环对工作表对象的行属性(rows)进行遍历。具体代码为 for rowData in orderSheet.rows:
这样程序就会以从上到下的顺序,逐个获取到“销售订单数据”工作表内的每一行数据。
可以从运行结果中看到,读取出的每一行数据是由单元格对象组成的元组。
如果要定位的列数字比较大,比如订单的总价在第M列,通过肉眼观察来确定索引略显繁琐。
这时,可以使用函数:openpyxl.utils.cell.column_index_from_string(),来获取列号对应的数字,比如传入参数“E”就会获取到数字5,表示“E”列是第5列。这个数字减一即可得到对应的索引。因为索引是从0开始的,所以需要减一。 (该函数也不区分大小写)
# 导入openpyxl模块
import openpyxl
# 添加data_only=True打开工作簿,获取公式计算后的值
wb = openpyxl.load_workbook("2019年1月销售订单.xlsx", data_only=True)
# 通过工作簿对象wb获取名为“销售订单数据”的工作表对象,并赋值给变量orderSheet
orderSheet = wb["销售订单数据"]
# 定义一个变量colaSold用来表示本月“火龙果可乐”的销售金额
colaSold = 0
# 遍历工作表的所有行数据
for rowData in orderSheet.rows:
# 商品名C列是第3列,索引也就是2
productName = rowData[2].value
# 获取订单总价I列的索引和总价
priceIndex = openpyxl.utils.cell.column_index_from_string("I") - 1
price = rowData[priceIndex].value
# TODO 判断如果productName是“火龙果可乐”
if productName =="火龙果可乐":
# TODO 逐个添加总价到本月销售额(colaSold)里
colaSold += price
# TODO 打印出本月销售额,格式为:2019年1月火龙果可乐销售额为{销售总额}元
print(f"2019年1月火龙果可乐销售额为{colaSold}元")Day2总结

Day3
3.计算多个月份“火龙果可乐”的销售金额
要计算多个月份的“火龙果可乐”销售额,只需把计算单月金额的代码重复执行多次即可。
在本例中,为了做到不写重复的代码,我们可以把计算单月“火龙果可乐”销售额的整个步骤写成一个函数,把Excel文件的路径作为输入的参数,计算出的销售额为函数的返回值。
接下来,通过观察销售订单的Excel文件名,我们可以发现,每个文件名仅有月份数字不同。
因此,我们可以很方便的使用for循环加range()函数,配合上格式化字符串,来批量生成每个Excel表格的文件路径:2019年{month}月销售订单.xlsx。
再把这个文件路径传入到getMonthlySold函数中,来计算各个月份的销售额。最后逐个添加到一个列表soldList中。
得到“火龙果可乐”每个月份的销售额后,要解决阿珍的问题,最后一步就是找出销售额的最大值,并定位到是几月份。
4. 比较得出去年“火龙果可乐”哪个月份卖的最好
要获取一个列表中的最大值,可以使用Python内置的max()函数。
将列表作为参数传入max()函数,该列表的最大值即会被返回。heightList = [188, 187, 197, 168, 184, 178] # 使用max()函数获取最大值 maxHeight = max(heightList) print(maxHeight)
当我们知道了列表中的一个元素,想要去列表中找到这个元素位于什么位置,可以使用列表的index()函数。
通过要查询的列表对象使用index()函数,将要查询的元素作为参数传入,则该元素从左往右第一次出现的索引将会被返回。
如果查询的元素不在列表中,会报一个ValueError的错误。
Day3总结

总代码:
# TODO 导入openpyxl模块
import openpyxl
# TODO 将计算单月销售额的步骤移到函数getMonthlySold中
# 获取单月“麻辣味口香糖”销售额的函数
# 参数 filePath: 销售数据Excel文件路径
# 返回值: 计算出的销售额结果
def getMonthlySold(filePath):
# 使用openpyxl.load_workbook()函数读取工作簿,文件路径使用函数参数filePath
# 添加data_only=True打开工作簿,获取公式计算后的值
wb = openpyxl.load_workbook(filePath, data_only=True)
# 通过工作簿对象wb获取名为“销售订单数据”的工作表对象,并赋值给变量orderSheet
orderSheet = wb["销售订单数据"]
# 定义一个变量gumSold用来表示本月“麻辣味口香糖”的销售金额
gumSold = 0
# 遍历工作表的所有行数据
for rowData in orderSheet.rows:
# 商品名C列是第3列,索引也就是2
productName = rowData[2].value
# 获取订单总价I列的索引和总价
priceIndex = openpyxl.utils.cell.column_index_from_string("I") - 1
price = rowData[priceIndex].value
# TODO 判断如果productName是“麻辣味口香糖”
if productName =="麻辣味口香糖":
# 逐个添加总价到本月销售额(gumSold)里
gumSold = gumSold + price
# TODO 将计算后的销售额gumSold返回
return gumSold
# 定义一个空列表soldList来逐个装入各个月份的销售额
soldList = []
# TODO 使用for循环和range,逐个遍历1~12的数字
# 注意:range的第二个参数是不包括到循环内的
for month in range(1,13):
# TODO 利用格式化字符串拼接Excel文件名,传入到获取单月销售额的函数并赋值给变量monthlySold
monthlySold = getMonthlySold(f"2019年{month}月销售订单.xlsx")
# 将“麻辣味口香糖”单月销售额monthlySold使用append函数逐个添加到列表中
soldList.append(monthlySold)
# TODO 使用max()函数获取最大的销售额并赋值给变量maxSold
maxSold = max(soldList)
# TODO 使用index()函数获取最大值的索引,索引值加1后得到月份赋值给maxMonth变量
maxMonth = soldList.index(maxSold)+1
# TODO 输出最终的结果:麻辣味口香糖在{maxMonth}月份卖得最好
print(f"麻辣味口香糖在{maxMonth}月份卖得最好")














 8847
8847

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









