






 本文详细介绍了常见的分类模型评估指标,如准确率、精确率、召回率、F1分数以及ROC曲线和AUC值的计算方法。特别讨论了ROC曲线和PR曲线的区别及其在不同场景的应用,以及KNN算法中不同k值对ROC曲线的影响。
本文详细介绍了常见的分类模型评估指标,如准确率、精确率、召回率、F1分数以及ROC曲线和AUC值的计算方法。特别讨论了ROC曲线和PR曲线的区别及其在不同场景的应用,以及KNN算法中不同k值对ROC曲线的影响。
常见的分类模型指标及计算方法
常见分类模型
常见的分类模型评估指标包括准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1分数(F1 Score)、ROC曲线和AUC值。
计算方法
1.准确率(Accuracy):准确率是分类模型预测正确的样本数量与总样本数量的比例。计算公式为:
Accuracy=
其中,TP是真正例(True Positives),TN是真负例(True Negatives),FP是假正例(False Positives),FN是假负例(False Negatives).
2.精确率(Precision):精确率是分类器预测为正例的样本中有多少是真正例的比例。计算公式为:
Precision=
3.召回率(Recall):召回率是真正例中有多少被分类器预测为正例的比例。计算公式为:
Recall=
4.召回率(Recall):召回率是真正例中有多少被分类器预测为正例的比例。计算公式为:
Recall=
5.ROC曲线和AUC值:ROC曲线是以假正例率(False Positive Rate,FPR)为横轴,真正例率(True Positive Rate,TPR)为纵轴绘制的曲线。AUC值(Area Under Curve)是ROC曲线下的面积,用于度量分类器的性能。AUC值越大,分类器的性能越好。
ROC曲线和PR曲线
ROC曲线(Receiver Operating Characteristic Curve)和PR曲线(Precision-Recall Curve)是用于评估二分类模型性能的两种常见工具。它们之间的主要区别在于所侧重的性能度量以及适用场景。
ROC曲线:
ROC曲线以假正例率(False Positive Rate,FPR)为横轴,真正例率(True Positive Rate,TPR,又称为召回率)为纵轴绘制的曲线。ROC曲线展示了在不同阈值下的分类器性能。
假正例率(FPR)定义为:
FPR=
真正例率(TPR)定义为召回率,即:
TPR=
ROC曲线越靠近左上角(0, 1)点,说明分类器的性能越好。ROC曲线下的面积(AUC,Area Under Curve)越大,表示分类器性能越好。
ROC曲线适用于数据不平衡(即正负样本比例差异较大)的情况,特别是当你关注的是分类器在不同阈值下的性能时。
PR曲线:
PR曲线以精确率(Precision)为横轴,召回率(Recall,又称为真正例率)为纵轴绘制的曲线。PR曲线展示了在不同阈值下的分类器性能。
精确率(Precision)定义为:
Precision=
PR曲线越靠近右上角(1, 1)点,说明分类器的性能越好。PR曲线下的面积(AUC)越大,表示分类器性能越好。
PR曲线适用于数据不平衡的情况,尤其是当正样本数量较少时。
区别
性能度量不同:ROC曲线关注的是真正例率(召回率)和假正例率,而PR曲线关注的是精确率和召回率。
适用场景不同:ROC曲线适用于数据不平衡情况下的二分类任务,尤其是当你关注分类器在不同阈值下的性能时;而PR曲线更适用于正负样本比例差异较大的情况,尤其是当你更关注正例的性能时。
knn实验中不同k值下的ROC曲线
ROC曲线的绘制
ROC曲线是用于评估二分类模型性能的一种常用工具。它显示了在不同阈值下真正例率与假正例率之间的关系。通常情况下,我们可以用ROC曲线来评估模型性能。而PR曲线是评估二分类模型性能的另一种重要工具,它显示了在不同阈值下精确率与召回率之间的关系。
以下是一个简单的示例代码,用于实验并绘制KNN算法不同k值下在某个数据集上的ROC曲线和PR曲线:
import numpy as np
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import precision_recall_curve, auc, roc_curve
import matplotlib.pyplot as plt
# 生成一个随机分类数据集
X, y = make_classification(n_samples=1000, n_features=20, n_classes=2, random_state=42)
# 将数据集分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 不同的K值
k_values = [1, 3, 5, 7]
plt.figure(figsize=(12, 6))
# 绘制PR曲线
plt.subplot(1, 2, 1)
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.title('Precision-Recall Curve')
# 绘制ROC曲线
plt.subplot(1, 2, 2)
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic (ROC)')
for k in k_values:
# 创建KNN分类器
knn = KNeighborsClassifier(n_neighbors=k)
# 在训练集上训练模型
knn.fit(X_train, y_train)
# 在测试集上获取预测概率
y_prob = knn.predict_proba(X_test)[:, 1]
# 计算PR曲线的参数
precision, recall, _ = precision_recall_curve(y_test, y_prob)
pr_auc = auc(recall, precision)
# 绘制PR曲线
plt.subplot(1, 2, 1)
plt.plot(recall, precision, lw=2, label=f'k={k}, AUC = {pr_auc:.2f}')
plt.legend(loc="lower left")
plt.grid(True)
# 计算ROC曲线的参数
fpr, tpr, _ = roc_curve(y_test, y_prob)
roc_auc = auc(fpr, tpr)
# 绘制ROC曲线
plt.subplot(1, 2, 2)
plt.plot(fpr, tpr, lw=2, label=f'k={k}, AUC = {roc_auc:.2f}')
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.legend(loc="lower right")
plt.grid(True)
plt.tight_layout()
plt.show()
这段代码首先生成了一个随机的二分类数据集,然后将数据集分成训练集和测试集。接着,使用KNN算法在训练集上训练模型,并在测试集上获取预测概率。最后,计算并绘制ROC曲线和PR曲线,在同一张图中绘制了不同k值下的ROC曲线和PR曲线。每条曲线的标签中包括了相应的k值和AUC值。
结果展示
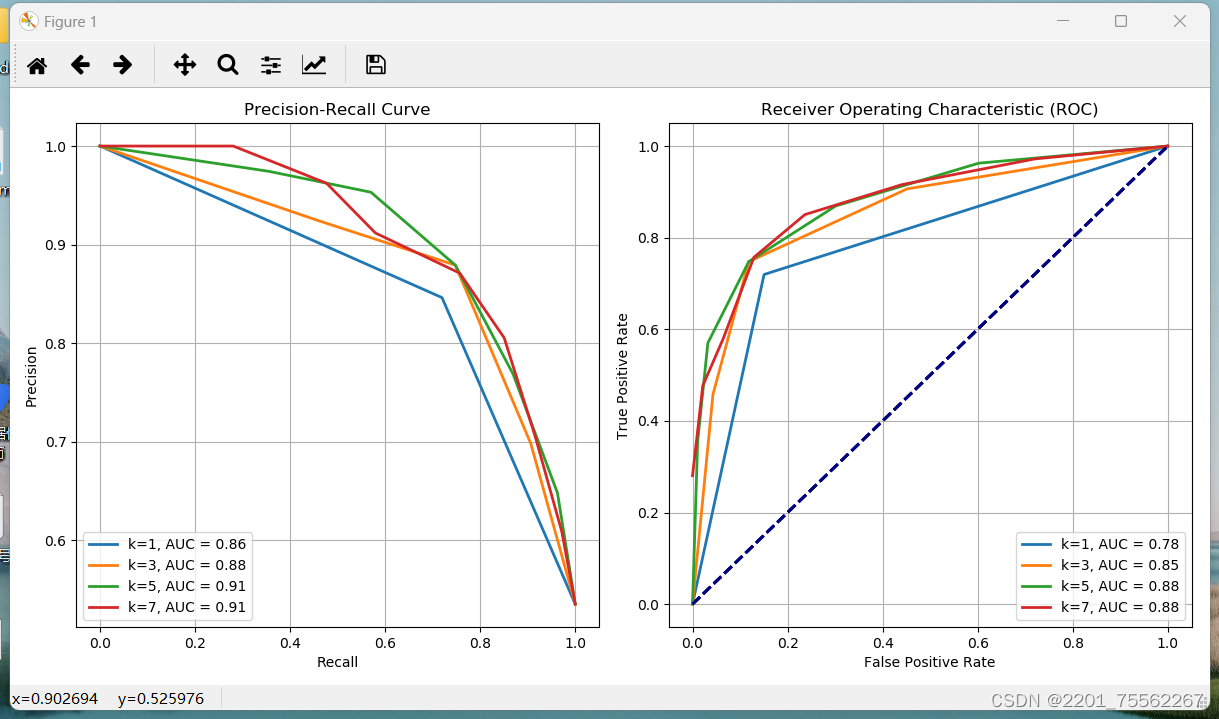
不同k值分析
在上述代码中,我们绘制了不同k值下的ROC曲线,并且对每条曲线计算了对应的AUC值。下面是对这些曲线的分析:
-
k=1:
- ROC曲线:k=1时,模型非常敏感,可能会过拟合。ROC曲线往往会更接近左上角,意味着高的真正例率和低的假正例率。这表明模型在这种情况下可能会在牺牲过多的误分类为负例的情况下,捕获到更多的真正例。
- AUC值:由于ROC曲线靠近左上角,因此AUC值可能较高。
-
k=3:
- ROC曲线:随着k值增加,模型变得更加平滑,不再过度拟合。ROC曲线可能更接近对角线,但仍然具有明显的弯曲。
- AUC值:AUC值可能会略微降低,但仍然可能比随机选择要好得多。
-
k=5:
- ROC曲线:随着k值进一步增加,模型的泛化能力可能进一步提高。ROC曲线可能更加平滑,并且可能更接近对角线。
- AUC值:AUC值可能进一步降低,但仍然可能高于随机选择。
-
k=7:
- ROC曲线:随着k值的进一步增加,模型更加平滑,可能更加接近对角线。ROC曲线可能表现出更平缓的下降趋势。
- AUC值:AUC值可能会进一步降低,但仍然可能高于随机选择。
综上所述,随着k值的增加,模型往往更倾向于平滑,泛化能力可能会提高,但可能会牺牲一些准确性。ROC曲线和AUC值是评估模型性能的重要指标,可以帮助选择最适合的模型参数。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









