



学习机器学习之前我们要学习机器学习会用到的几个第三方库
numpy,pandas,matplotlib,sklearn,scipy
一、numpy库
numpy是python的第三方库,numpy是矩阵库,学习numpy库是为学习机器学习。
这里我安装的版本为2以下版本,是为了后面方便opencv的学习,第三方库的下载可以参考https://blog.csdn.net/2201_75573294/article/details/155455973?fromshare=blogdetail&sharetype=blogdetail&sharerId=155455973&sharerefer=PC&sharesource=2201_75573294&sharefrom=from_link
一、numpy
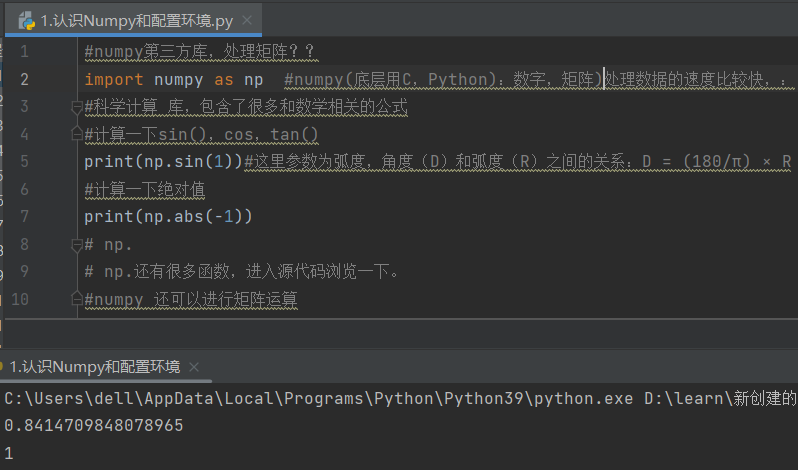
1.导入numpy库为np,np可以计算三角函数和绝对值
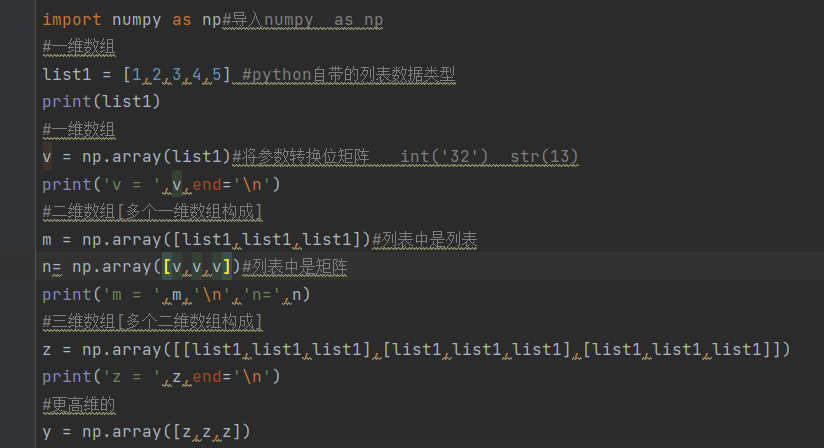
2.创建array
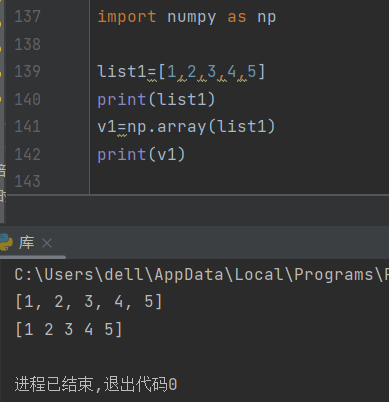
1).列表转化为矩阵
列表也可以有一维,二维,三维甚至更高维度的形式,矩阵也有,两者的区别在于,列表无论维度多少他只是一个形式,除了对其数据的索引和切片外,数据不带有计算的功能,而矩阵可以。
array的功能就是把列表转化为矩阵,让其数据又数学计算的功能。注意转化为矩阵的时候列表需要是“规整的”
例如下面
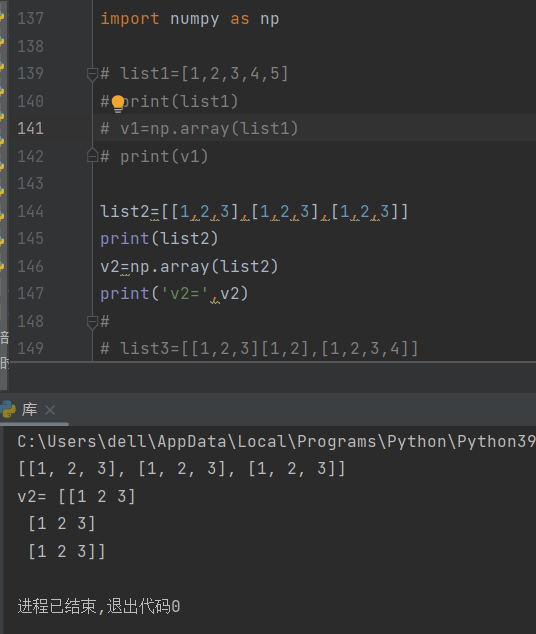
像列表3这样不规整的列表转化为矩阵的时候会出错的

array是库的函数,能将列表转化为矩阵。
运行结果
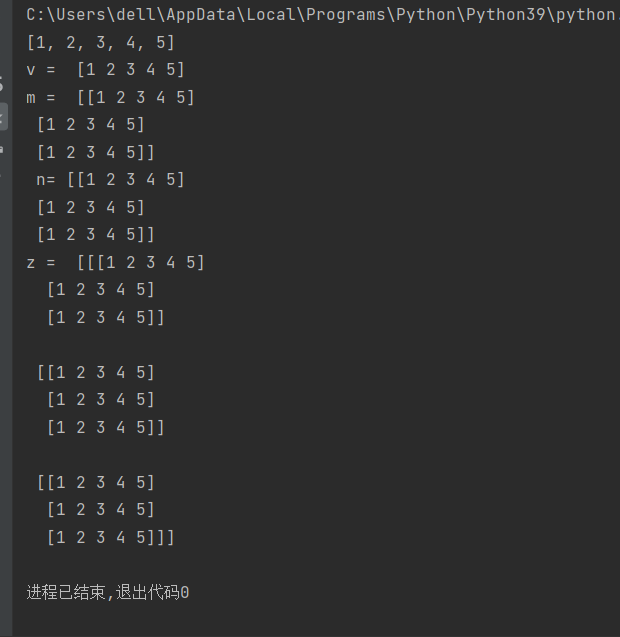
2).数组的基本属性
d = v.dtype
#查询数组中的元素类型,int8, int16, int32, int64: 表示不同长度的有符号整数。
# uint8, uint16, uint32, uint64: 表示不同长度的无符号整数。
# float16, float32, float64 (float 是 float64 的简写): 表示不同精度的浮点数。
# complex64, complex128 (complex 是 complex128 的简写): 表示复数,其中64和128表示复数的实部和虚部的位数。
# bool: 布尔类型,可以存储True或False。
# str_: 表示定长字符串,可以通过添加数字来指定字符串的长度,如 'S10' 表示长度为10的字符串。
# object: 表示Python对象类型,可以用来存储任意Python对象。对上面得到的数组进行以下操作
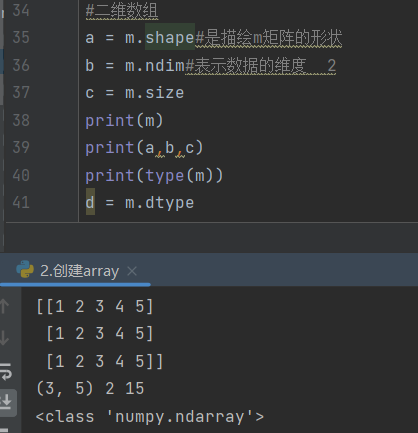
对v的查询和m的查询

对z的查询
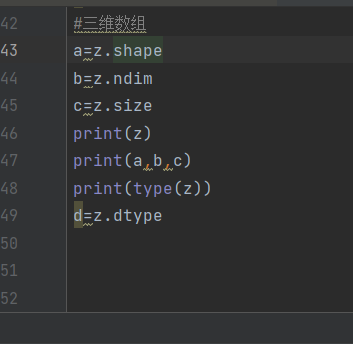
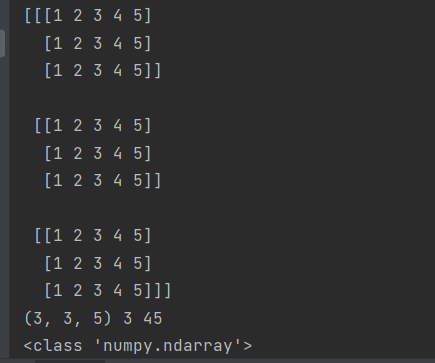
都很好理解,只有这个shape,v.shape这里是(5,)是对一维数组的特殊表达方式,根据对m的shape理解,(3,5)表示三行五列,或许v的shape能写为(1,5)意思为一行五列,但其实这是错误的。
v=[1 2 3 4 5]只能算作向量,shape表示为(5,)
而(1,5)表示的是行矩阵,(5,1)就是列矩阵,v=[[1 2 3 4 5]]才表示为(1,5)
矩阵是二维以上的,这里不要搞混
另外z的shape(3,3,5)意思就是三个三行五列的数据
3.数组的升维
1)一升二
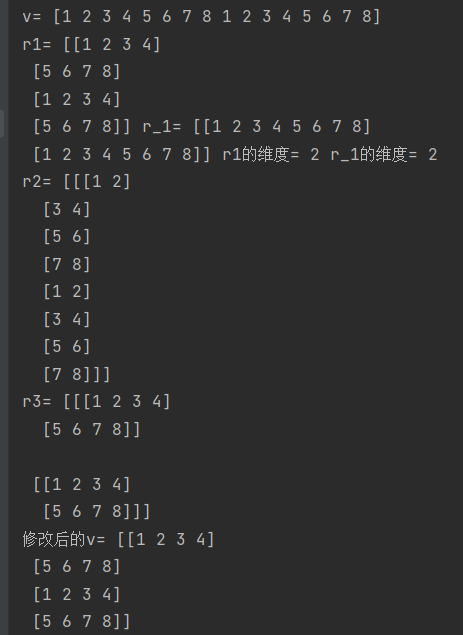
reshape是把列表塑成几行几列的数组,r1为四行四列,r_1是2行,-1的意思是系统会根据四行自动匹配列,所以为两行八列,且都是二维数据
2)一升三
r2为一个八行两列的三维矩阵
3)二升三
r3为两个二行四列的三维数据
4)resize改变原数据的维度
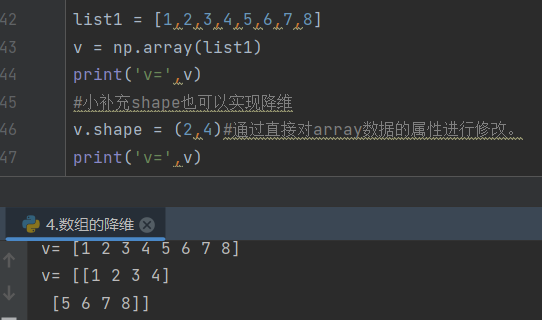
4.数组的降维
降维和升维没什么区别,还是用reshape
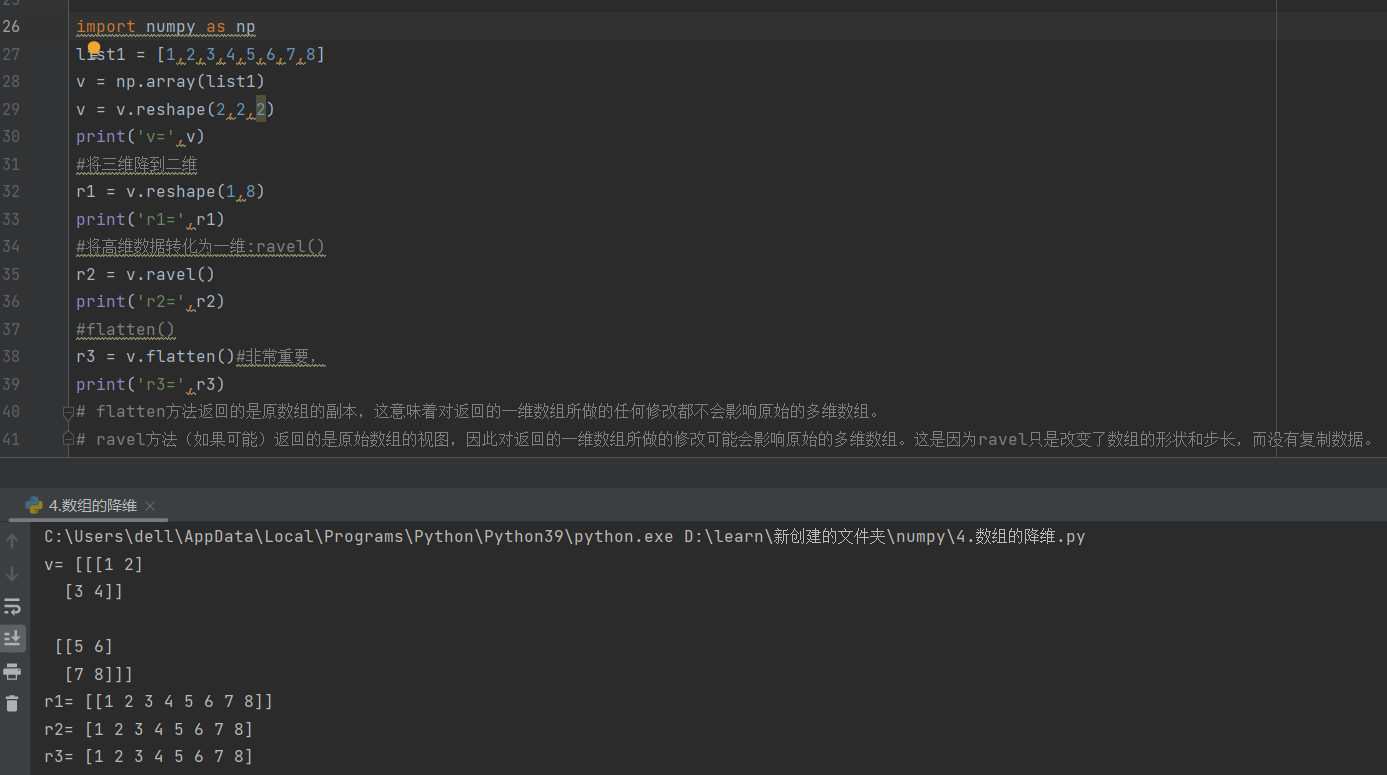
补充一点,shape其实也可以实现降维,是直接对array数据的属性进行修改
5.创建特殊的数组
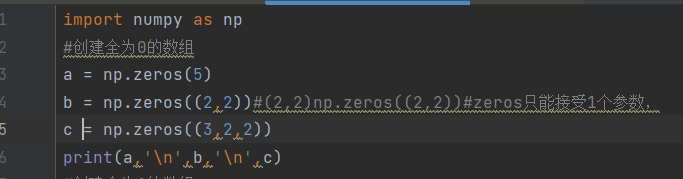
全为0,np.zeros()括号里只能接受一个参数,如果多数字要以元组的形式
一个数字为一维数组,俩数字为二维数组……
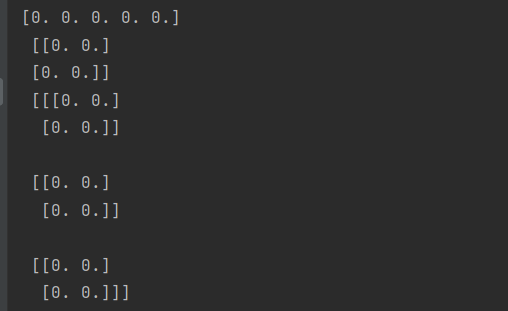
另外还有全1,这里也是只能填一个参数
d = np.ones(5)
e = np.ones((2,2))
f = np.ones((2,2,2))
print(d,'\n',e,'\n',f)还可以自定义
全为5的两个两行三列的三维矩阵full(参1,参2),参一是数组的形态,参二决定数据为多少
g = np.full((2,2,2), 5)
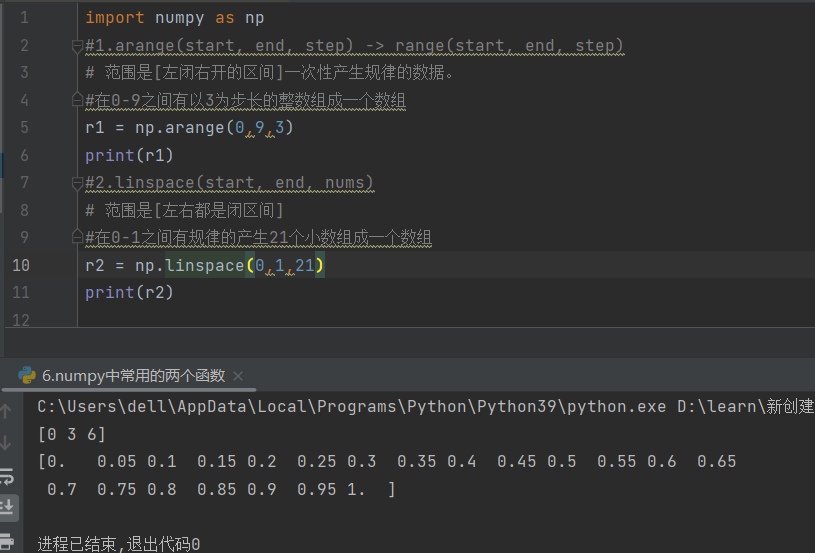
print(g)6.numpy中常用的两个函数
arange(参1,参2,参3):前俩数是取值范围,左闭右开,参3为步长
linspace(参1,参2,参3):前俩数为范围,左右闭区间,参3为产生的数字个数
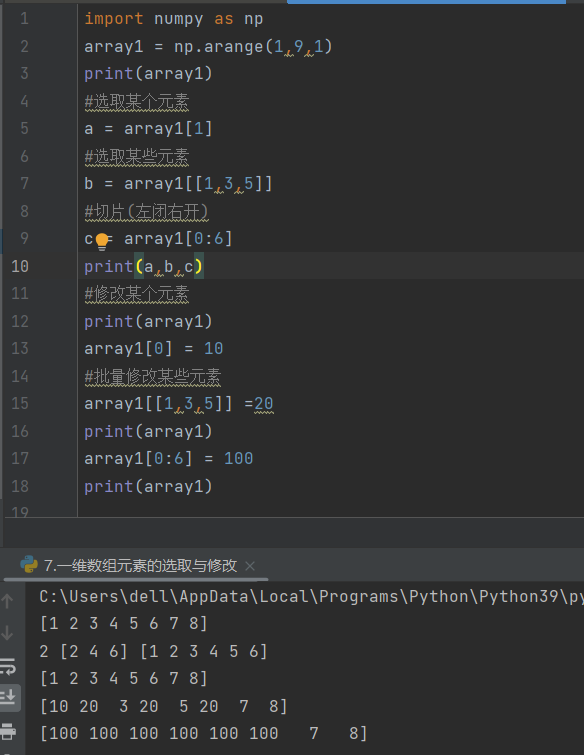
7.一维数组元素的选取与修改
逗号为和,例如这里的b变量,就是要取索引号为1和3和5的元素
冒号为范围,例如这里的c变量,取索引号0~6,不包含6的元素
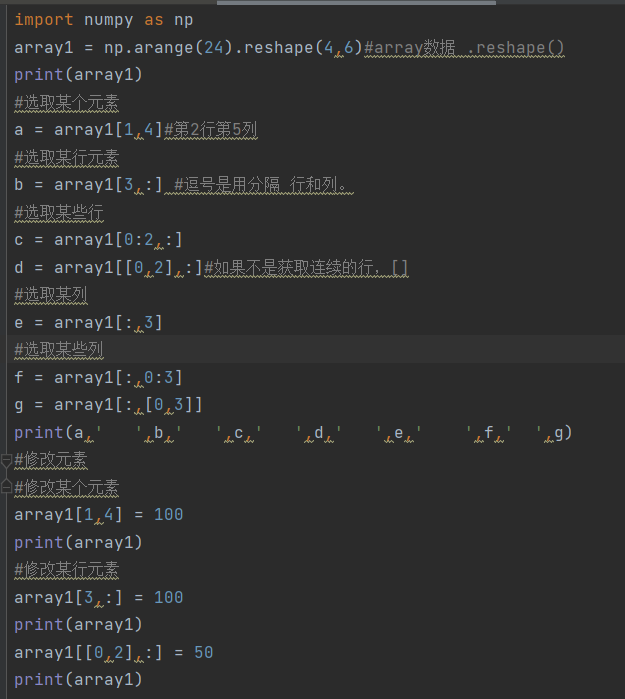
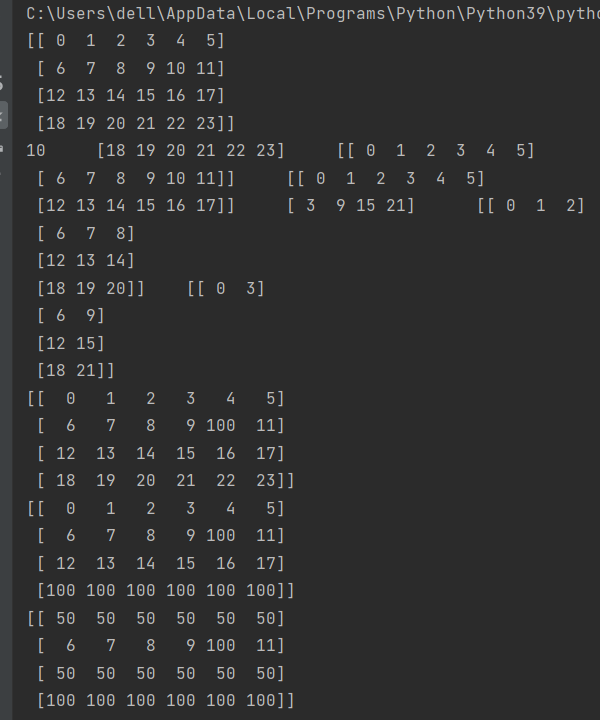
8.二维数组元素的选取与修改
这里的逗号有不一样的含义了,注意区分,效果可以在调试中看到
例如这里c变量,2和:之间的逗号意思就是分隔行和列的,整体意思就是选取0~2行不包含2,的全部列数据,这里的:如果不是数字是冒号就代表全部,再举一个例子,这里的e变量表示的就是全部行的第三列的数据
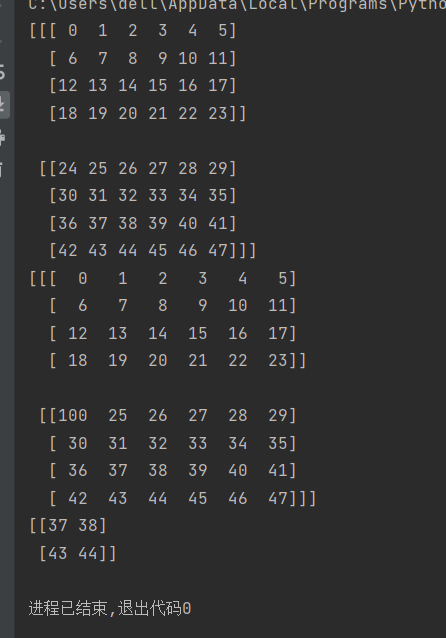
9.三维数组元素的选取与修改
和上面是一样的可以放在一起记忆
,
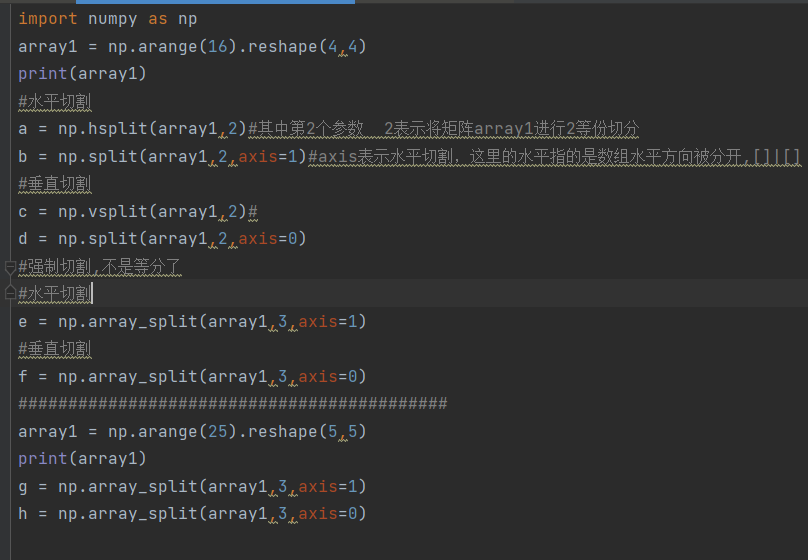
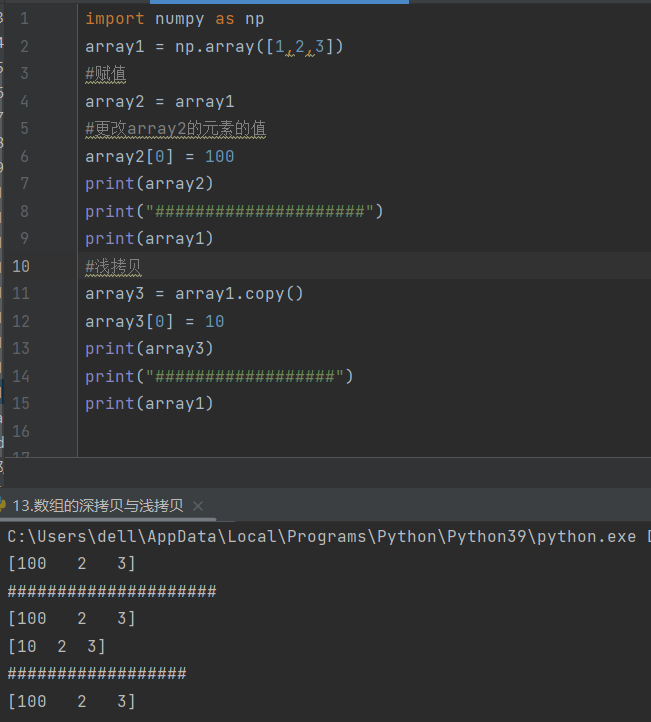
10.数组的组合
将数组组合,hstack()是水平组合,vstack()是垂直组合
concatente()中有一个参数axis,为1的时候和hstack功能一样,水平组合数组
为0的时候和vstack功能一样,垂直组合数组

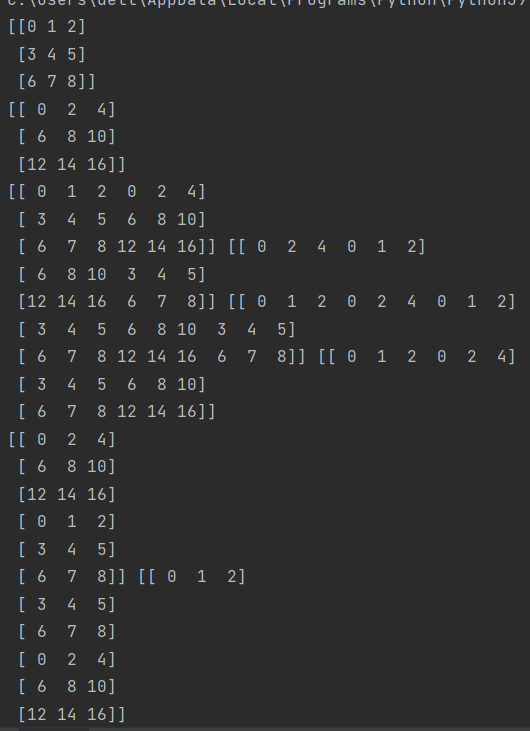
11.numpy内数组元素的切割
axis=1是水平切割,=0是垂直切割
这里的水平和垂直的含义需要注意
水平切割:
—— —— | —— —— 把数组掰开
| | | | |
| | | | |
| | | | |
—— —— | —— ——
垂直切割:
—— —— 把数组‘腰斩’
| |
| |
—— ——
————————————————————————————————
—— ——
| |
| |
—— ——
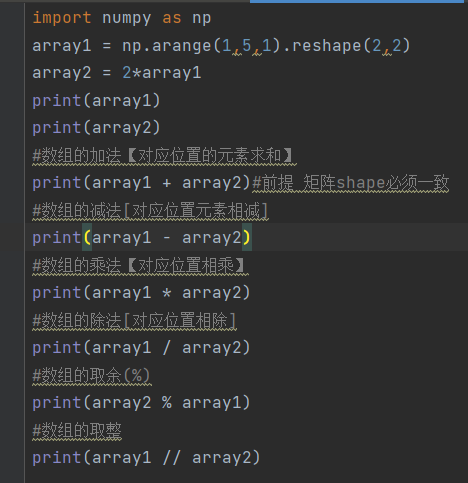
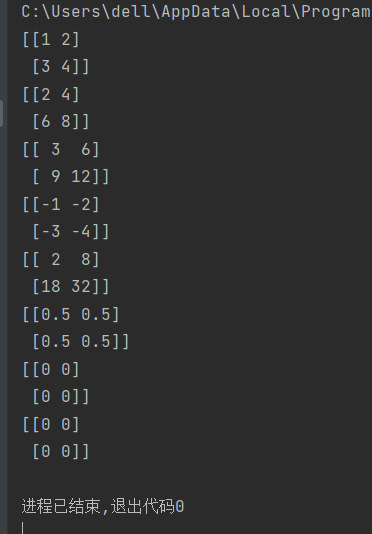
12.数组的算数运算
13.数组的拷贝
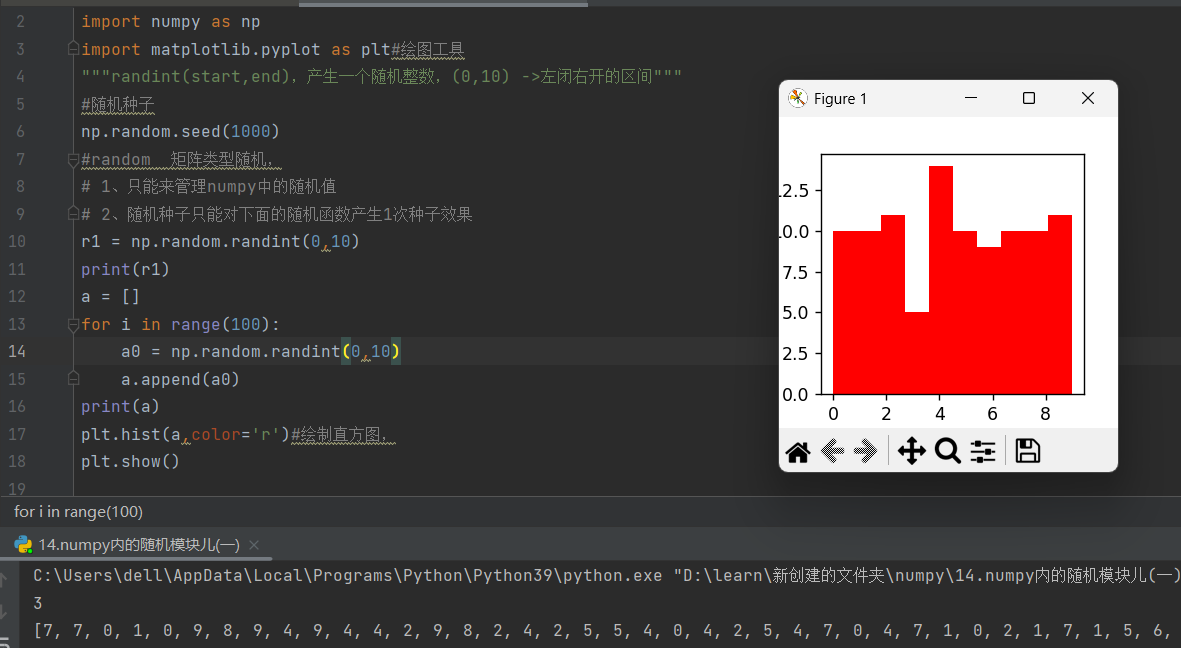
14.numpy内的随机模块
1)
2)
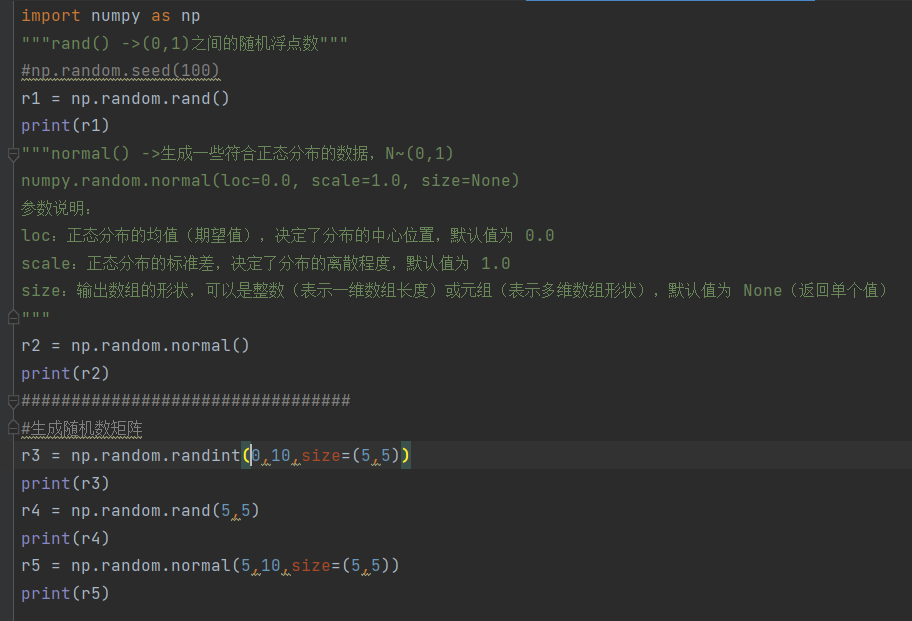
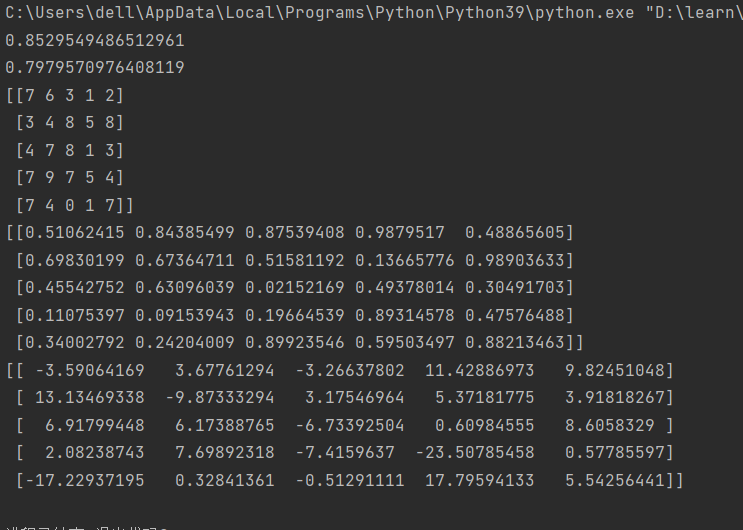
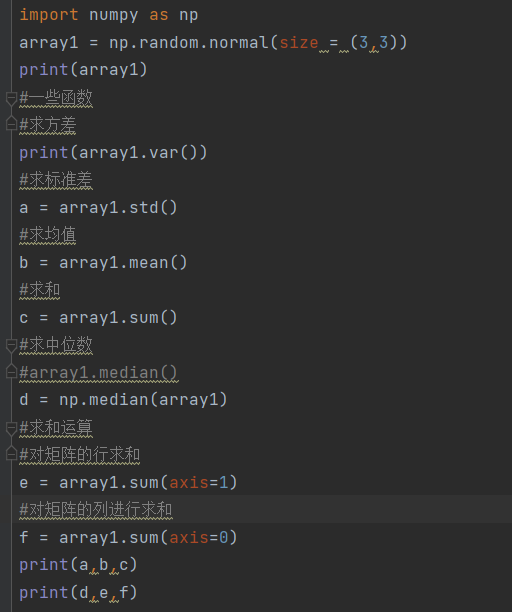
15.numpy内一些函数的使用
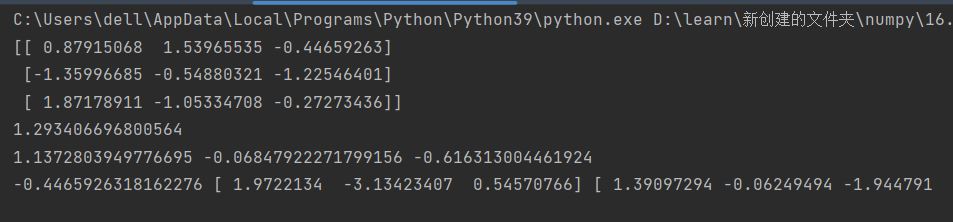
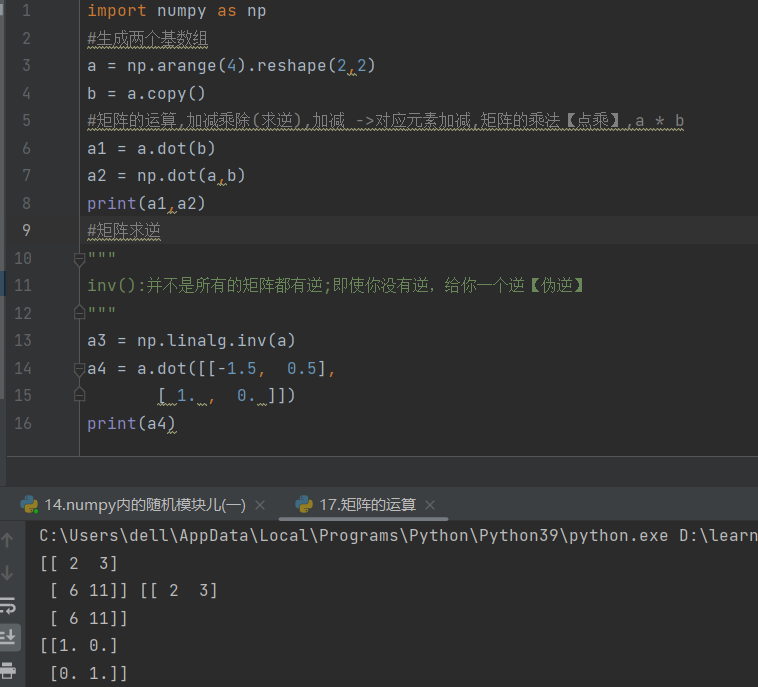
16.矩阵的运算
17.读取文件

二、pandas库
下载pandas库可以参考第三方库的下载:https://blog.csdn.net/2201_75573294/article/details/155455973?fromshare=blogdetail&sharetype=blogdetail&sharerId=155455973&sharerefer=PC&sharesource=2201_75573294&sharefrom=from_link
1.数据导入与导出
下面操作中所涉及到的代码:
"""
读取csv文件
"""
import pandas as pd
df_1 = pd.read_csv("data1.csv")
df_2 = pd.read_csv("data2.csv",encoding='utf8',header=None)
"""
读取excel文件
"""
df_3 = pd.read_excel("data3.xlsx")#需要装openpyxl库
"""
读取txt文件
"""
df_4 = pd.read_table("data4.txt",sep=',',header=None)
#sep=',':指定文件的分隔符为逗号(,)
"""
导出文件
"""
df_1.to_csv("导出.csv",index=True, header=True)
#index=True:表示导出时包含 DataFrame 的索引(行标签),默认值为 True;若设为 False,则不导出索引。
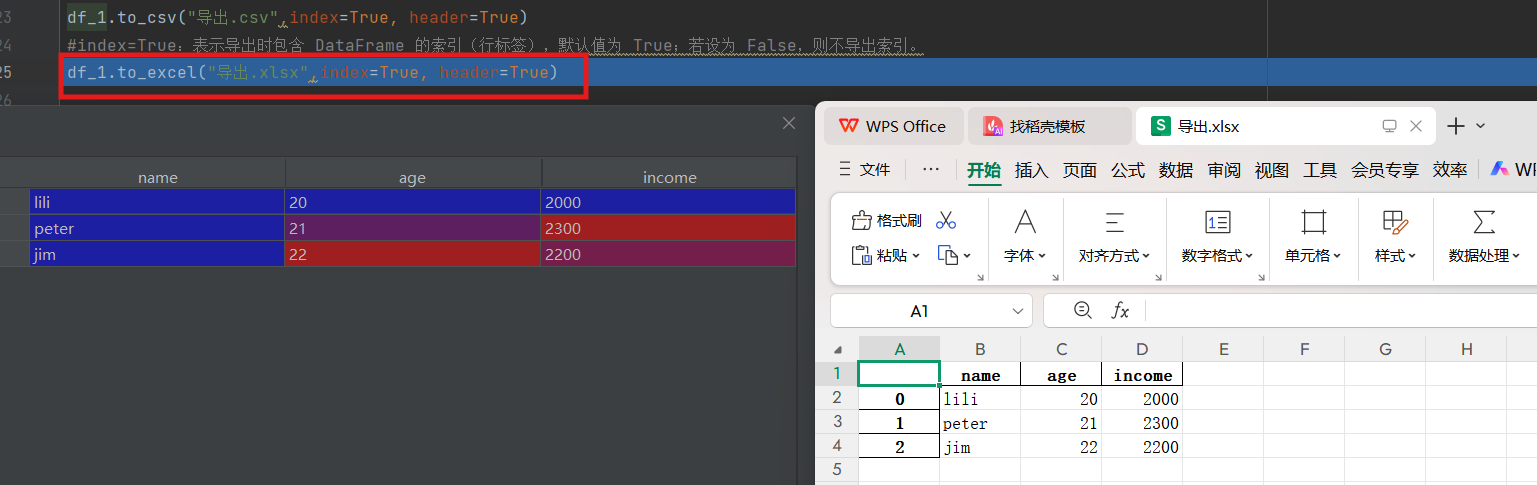
df_1.to_excel("导出.xlsx",index=True, header=True)1)读取csv文件
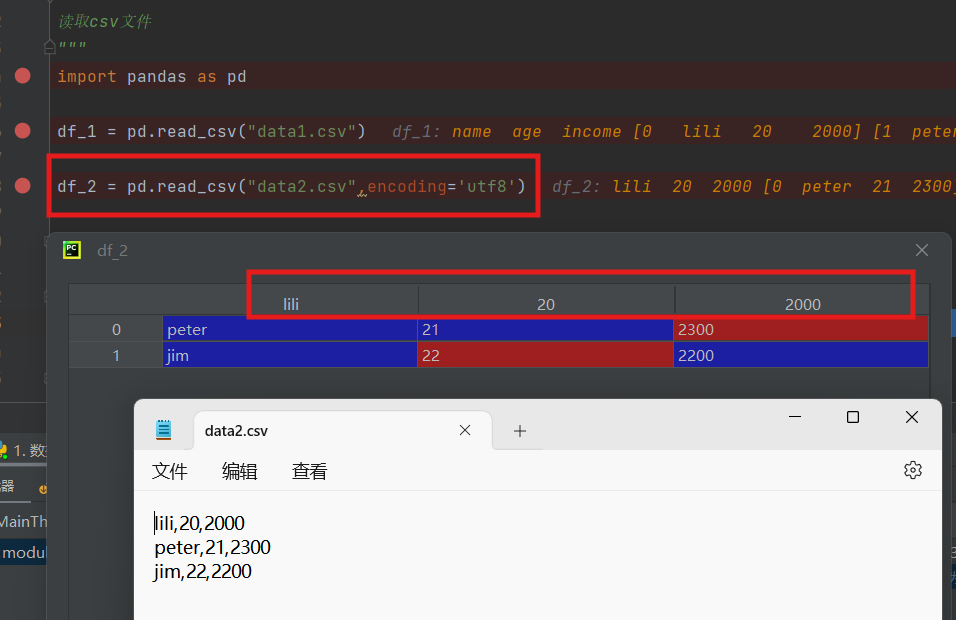
进行调试,下图中的df_1和df_2表格都是通过调试得来的,点击红框蓝色部分字体就可以打开

文件data1.csv,是有表头name,age,income,而文件data2.csv无表头name……
encoding是读取的方式,前面读取文件时open()函数有提到
header参数为none时用于原文件中无表头,也就是这里读取data2.csv

如果我们header=none删去,读取data2.csv,数据就会出现在表头,这个表就会被打乱
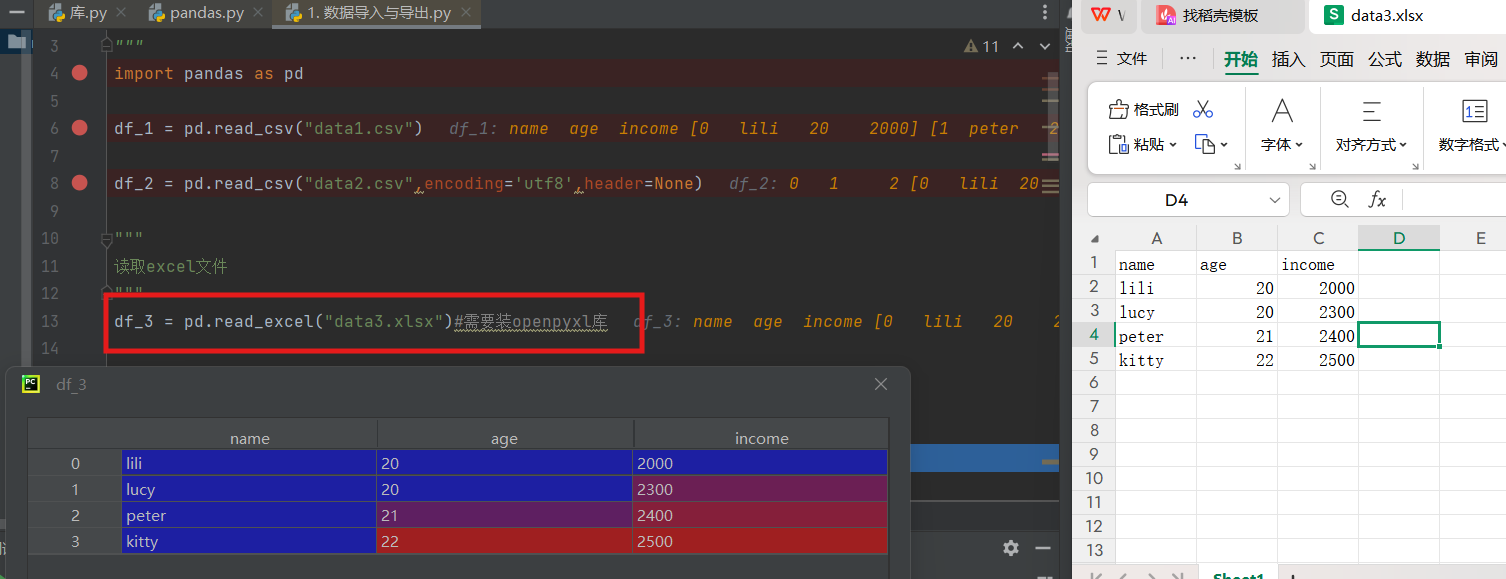
2)读取excel文件
继续运行读取data3文件(注意执行df_3这条命令前我们需要先下载openpyxl库)
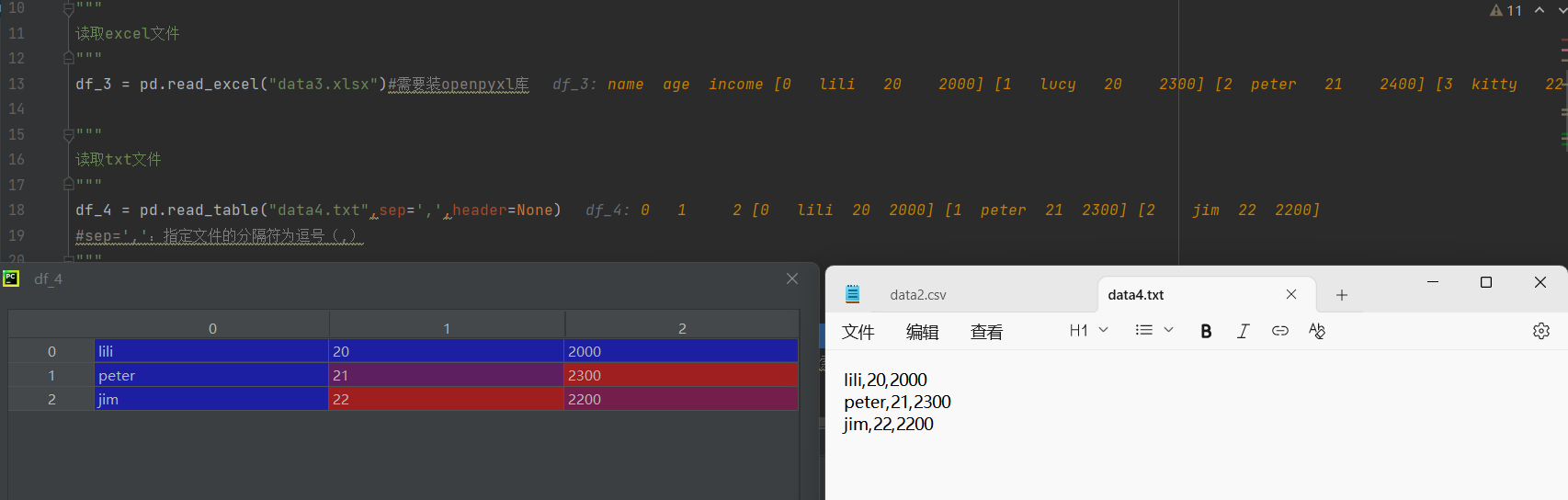
3)读取txt文件
这里的sep=','意思是以逗号分隔
4)导出
df_1导出为csv文件,index为true意思为行名也导出,header为true意思为表头也就是列名也导出,在文件管理器打开导出的文件
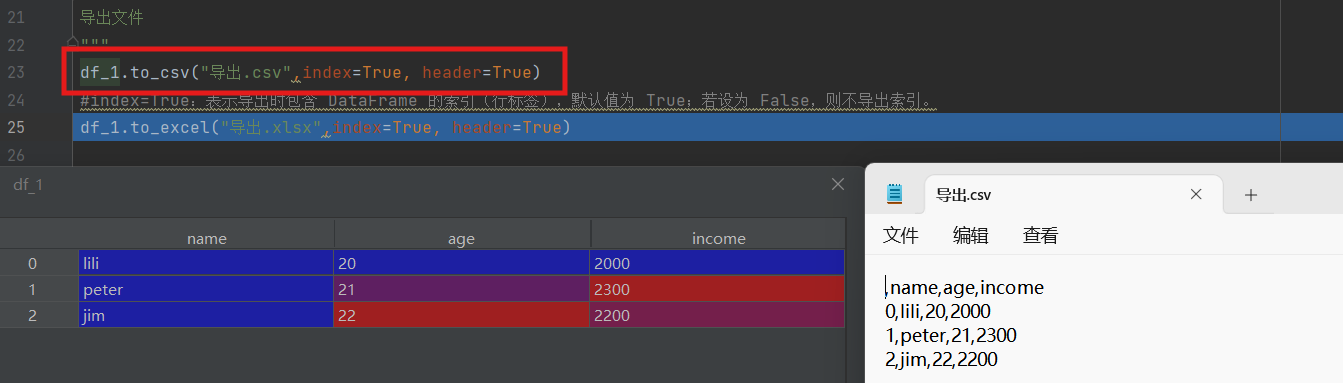
df_1导出为excel文件
2.缺失值处理
下列操作涉及到的代码:
import pandas as pd
"""
缺失值处理方式:
1.数据补齐 2.删除对应数据行 3.不处理
"""
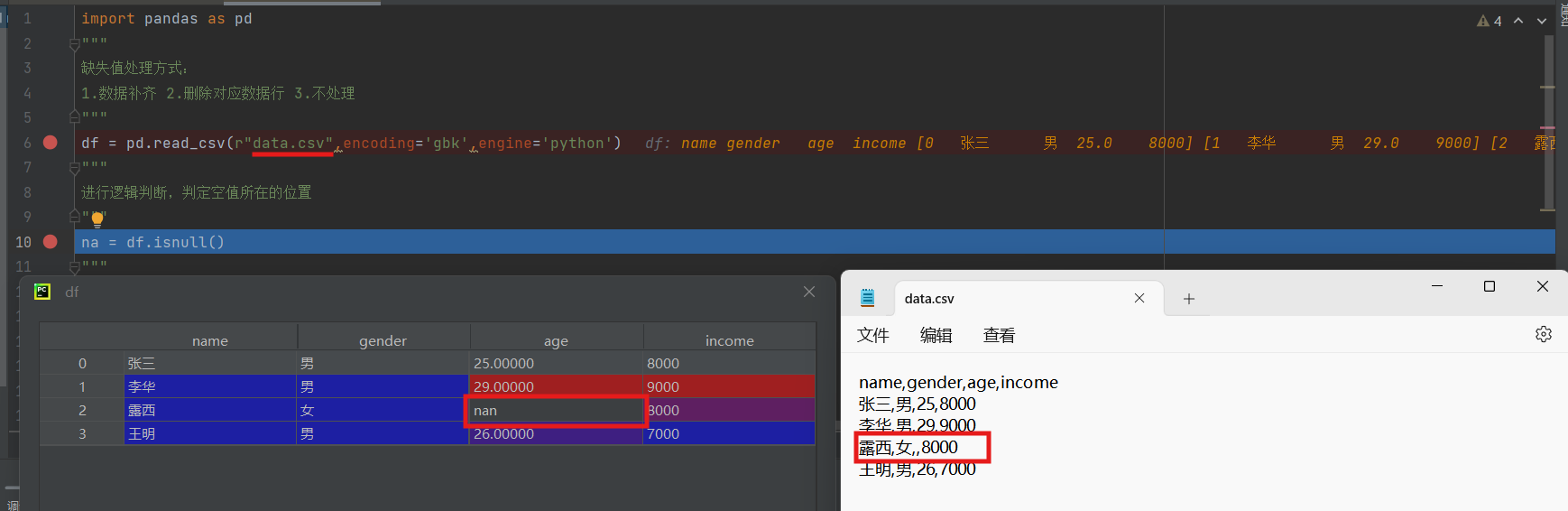
df = pd.read_csv(r"data.csv",encoding='gbk',engine='python')
"""
进行逻辑判断,判定空值所在的位置
"""
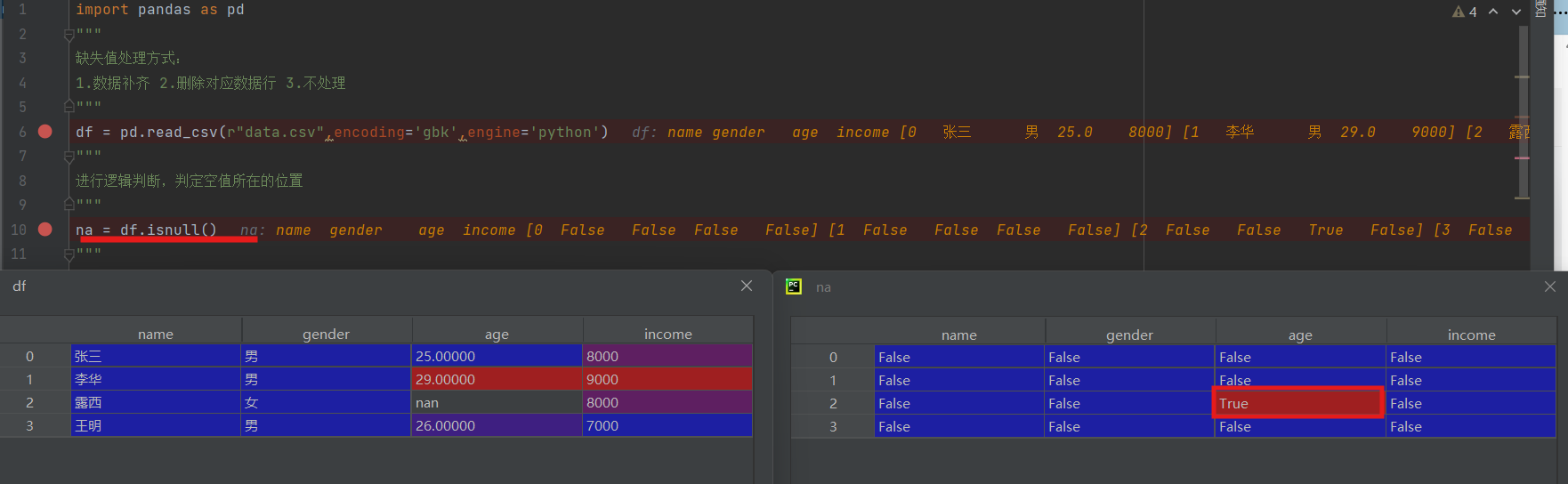
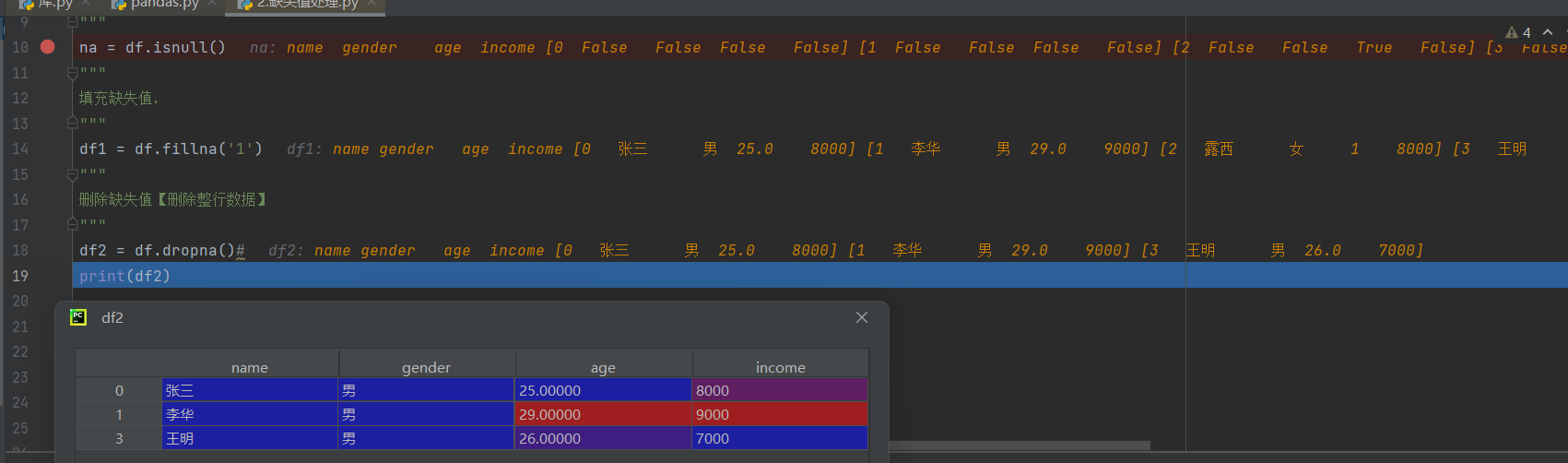
na = df.isnull()
"""
填充缺失值,
"""
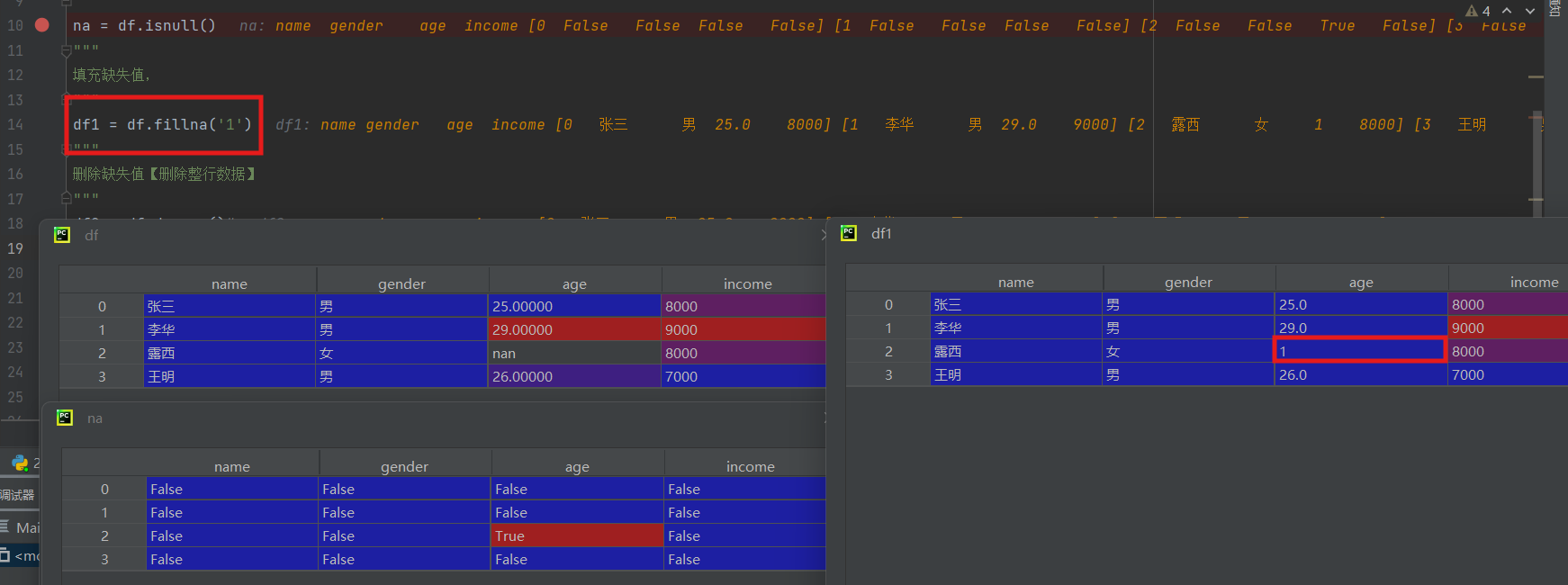
df1 = df.fillna('1')
"""
删除缺失值【删除整行数据】
"""
df2 = df.dropna()#
print(df2)
读取文件,在调试中打开df表格,原文件中第三行数据缺失一个数据,df表中缺失位置是none
下一步获取空值所在的位置,是空为true,不是空为false
在空值位置补上1(这里的填入数据如果要符合实际,我们是要用算法进行取值的,但是涉及到的算法比较复杂,这里只是简单的填入确定的值)
或者我们删除我们缺失信息的那一行(这里我们的数据只是缺少一个,很多时候实际问题中会出现缺失数据较多,用算法是算不出一个合理的值,一般就会删除信息)
3.重复值处理
import pandas as pd
df = pd.read_csv(r"data1.csv",encoding='gbk',engine='python')
print(df)
"""找出重复值的位置【逻辑判断】"""
result1 = df.duplicated()
"""根据列名来判断重复"""
#根据某个表头
result2 = df.duplicated('name')
print(result2)
#根据多个
result3 = df.duplicated(['gender', 'name'])
print(result3)
"""提取重复的行"""
a = df[result1]
b = df[result2]
c = df[result3]
'通过bool提取内容'
d = df[[True,False,False,True,True,False,False]]
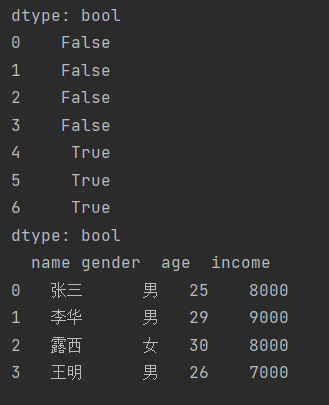
"""删除重复的行"""
new_df1 = df.drop_duplicates()
#部分重复【根据某列名来删除】
new_df2 = df.drop_duplicates(['name', 'gender'])
print(new_df2) 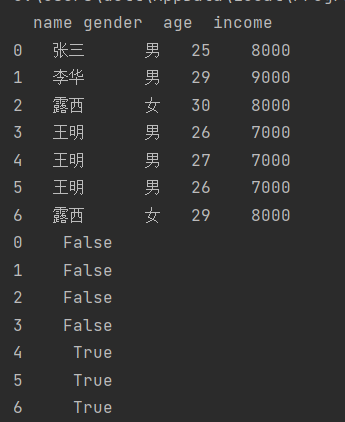
4.数据抽取
"""
根据一定条件,抽取数据
"""
import pandas as pd
df = pd.read_csv("data1.csv",encoding= 'gbk',engine='python')
"""
比较运算:包含大于、小于等运算
逻辑判断+取数
"""
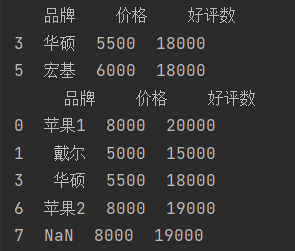
#抽取好评数大于17000的电脑
a = df['好评数'] > 17000
df_1 = df[df['好评数'] > 17000]
#抽取好评数在15000到17000之间的电脑
df_2 = df[df['好评数'].between(15000, 17000)]
print(df_1,'\n',df_2)
"""
字符匹配
"""
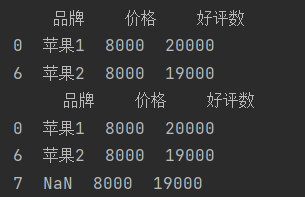
df_3 = df[df['品牌'].str.contains('苹果',na=False)]
df_4 = df[df['品牌'].str.contains('苹果',na=True)]
print(df_3,'\n',df_4)
#.str.contains('苹果'):对“品牌”列的每个元素进行字符串匹配,检查是否包含 “苹果” 子串,返回布尔值 ,True:包含,False:不包含)。
# na=False:指定对缺失值(NaN)的处理方式 —— 将缺失值视为 False(即不筛选包含缺失值的行)。
"""
逻辑运算: &(和)、|(或)
"""
#取出价格小于7000,好评大于16000的电脑
df_5 = df[(df['价格']<7000) & (df['好评数'] > 16000)]
df_6 = df[(df['价格']<6000) | (df['好评数']>18000)]
print(df_5,'\n',df_6) 
5.数据框的合并
"""
concat()函数:
使用方式:concat([df1,df2,df3...])
"""
import pandas as pd
import numpy as np
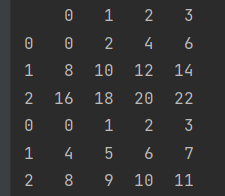
df_1 = pd.DataFrame(np.arange(12).reshape(3,4))
df_2 = 2*df_1
print(df_1,'\n',df_2)
#竖向合并
new_df1 = pd.concat([df_2, df_1])
#横向合并
new_df2 = pd.concat([df_1, df_2], axis=1)
print(new_df1,'\n',new_df2)
"""
join参数 inner:表示交集 outer:表示并集
"""
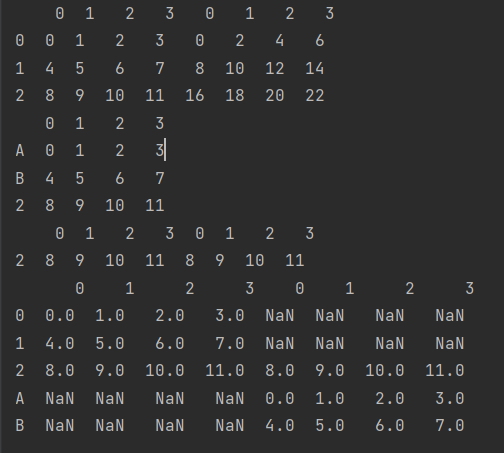
df_3 = pd.DataFrame(np.arange(12).reshape(3,4),
index=['A', 'B', 2])
new_df3 = pd.concat([df_1, df_3], axis=1, join='inner')
new_df4 = pd.concat([df_1, df_3], axis=1, join='outer')
print(df_3,'\n',new_df3,'\n',new_df4)


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









