







为什么说二分查找是很牛的算法?
一、二分查找是什么?
在学习数据结构的过程中我们会学很多数据结构,例如:二叉树、AVLTree、哈希表、B数,而今天我要给大家介绍在有序的情况下的一种排序——二分查找,接下来请看代码实现。
代码如下(示例):
int BinarySearch(int arr[], int k, int sz)
{
int left = 0;
int right = sz - 1;
while (left <= right)
{
int mid = (left + right) / 2;
if (arr[mid] < k)
{
left = mid + 1;
}
else if (arr[mid] > k)
{
right = mid - 1;
}
else
{
return mid;
}
}
if (left > right)
{
return -1;
}
}
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
int sz = sizeof(arr) / sizeof(arr[0]);
int k = 0;
scanf("%d", &k);
int ret = BinarySearch(arr, k, sz);
if (ret == -1)
{
printf("没找到\n");
}
else
{
printf("找到了,下标是%d\n", ret);
}
}
输出结果: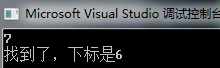

二、为什么说二分查找是很牛的算法
原因 如下(示例):
我们从时间复杂度的角度来看二分查找
很多看说这个二分查找的时间复杂度是O(N),这是错误的
最好:O(1),最坏:O(log2^n)那么我们是怎么算的呢?
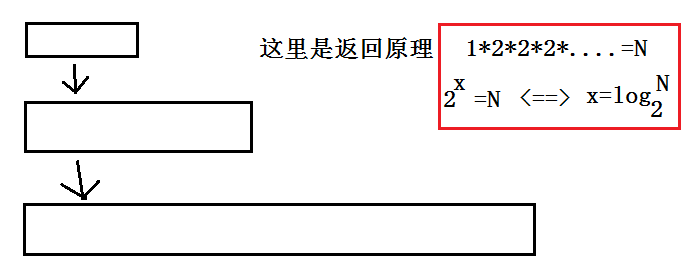
一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一

可能大家光看时间复杂度说明不了什么,可以参考一下下面的表格:
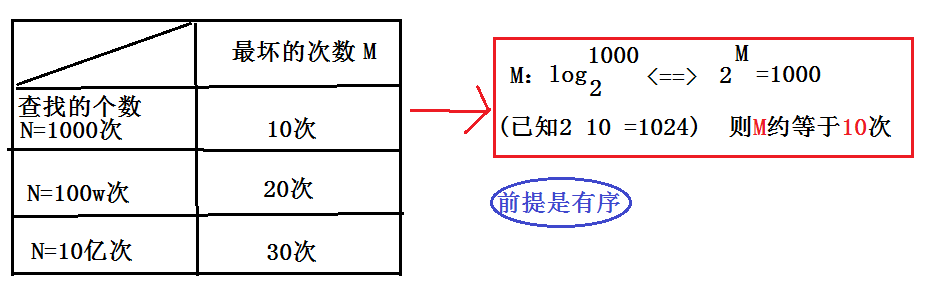
二分查找的优缺点
既然二分查找的效率这么快,我们为什么不只用二分查找呢?还要使用哈希表、二叉树呢?
二分查找的缺点:所查找的数组必须是有序的!!!
那么我们有没有不需要有序并且时间复杂度也是log2^N:AVLTree、RBTree(后期会详细介绍)
总结
以上就是今天要讲的内容,本文介绍了二分查找的使用和优缺点,已经为什么说二分查找是很牛的算法?
如果我的博客对你有所帮助记得三连支持一下,感谢大家的支持!

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









