






用户爱看什么?
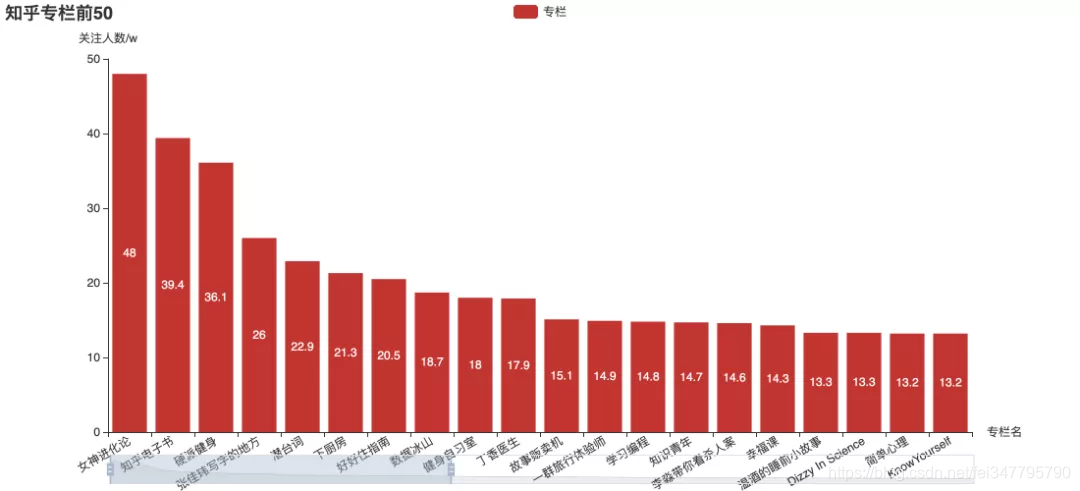
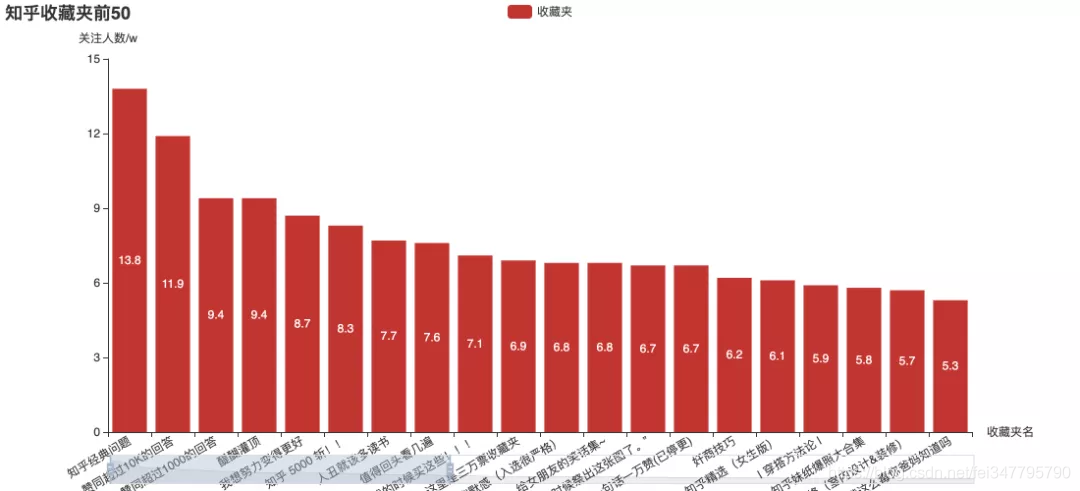
这些关注度最高专栏和收藏夹,里面有你关注的吗?
最后,这是一个以关注数超1万的用户的个人简介做出来的词云:

coding:utf8
抓取粉丝数过 1w 用户
import requests
import pymongo
import time
import pickle
def get_ready(ch=‘user_pd’,dbname=‘test’):
‘’‘数据库调用’‘’
global mycol, myclient,myhp
myclient = pymongo.MongoClient(“mongodb://localhost:27017/”)
mydb = myclient[dbname]
mycol = mydb[ch]
get_ready()
ss = mycol.find({})
se = {1,} # 去重集合
se2 = [‘GOUKI9999’,‘zhang-jia-wei’] # 爬取的列表
with open(r’C:\Users\yc\Desktop\used.txt’, ‘rb’) as f: # 读取
used = pickle.load(f)
used={1,}
sed = {}
for s in ss:
if s[‘follower_count’]>=10000: # 粉丝数大于10000
sed[s[‘user_id’]] = sed.get(s[‘user_id’],0) + 1
if sed[s[‘user_id’]] == 1:
se.add(s[‘user_id’])
se2.append(s[‘user_id’])
leng = len(se2)
print(leng)
proxies = {
“http”: “http://spiderbeg:pythonbe@106.52.85.210:8000”,
“https”: “http://spiderbeg:pythonbe@106.52.85.210:8000”,
}
headers = {
‘user-agent’:‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36’,
‘cookie’:‘your_cookie(用户主页面)’
}
for i,url_id in enumerate(se2): # 爬取
if i>=0:
print(i,’ ‘, end=’') # url个数
if url_id not in used: # 是否使用过
used.add(url_id)
nums = 500
off = 0
while True:
url2 = ‘https://www.zhihu.com/api/v4/members/’ + url_id + ‘/followees?include=data%5B*%5D.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F(type%3Dbest_answerer)%5D.topics&offset=’ + str(off) + ‘&limit=’ + str(nums)
r2 = requests.get(url2, headers=headers,proxies=proxies)
time.sleep(0.5)
c = 0
if ‘error’ in r2.json():
if r2.json()[‘error’][‘code’] in {310000, 310001}:
break
else:
raise NameError(‘页面错误’)
used.add(url_id) # 判断是否使用
for d in r2.json()[‘data’]:
z = {}
c+=1
z[‘user_id’] = d[‘url_token’]
z[‘name’] = d[‘name’]
z[‘headline’] = d[‘headline’]
z[‘follower_count’] = d[‘follower_count’]
z[‘answer_count’] = d[‘answer_count’]
z[‘articles_count’] = d[‘articles_count’] # if d[‘articles_count’] else 0
z[‘from’] = url_id # 谁的关注列表
if d[‘follower_count’]>=10000 and d[‘url_token’] not in se and d[‘url_token’] not in used: # 粉丝大于 1w,则爬取
se.add(d[‘url_token’])
se2.append(d[‘url_token’])
mycol.insert_one(z) # 插入数据
if r2.json()[“paging”][‘is_end’] == False:
nums+=500
off+=500
elif r2.json()[“paging”][‘is_end’] == True:
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









