






一、原题
给定一个字符串 s ,请你找出其中不含有重复字符的 最长 子串 的长度。
示例 1:
输入: s = "abcabcbb" 输出: 3 解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。
示例 2:
输入: s = "bbbbb" 输出: 1 解释: 因为无重复字符的最长子串是 "b",所以其长度为 1。
示例 3:
输入: s = "pwwkew" 输出: 3 解释: 因为无重复字符的最长子串是 "wke",所以其长度为 3。 请注意,你的答案必须是 子串 的长度,"pwke"是一个子序列,不是子串。
二、心得
我的第一反应就是使用哈希表(今天刚学会,学以致用)记录字符串字母和关键字,使用循环遍历字符串,找到第一次重复的字母,记录当前不重复的子串长度,最后肯定要选出最大的子串长度。非常正确的思路,经验+1!o(* ̄▽ ̄*)ブ
当然,我这次不怎么手废了,借鉴了一下(不,准确来说是学习了一下)char c = s.charAt(i);这个用法,提取字符串s中的第i位字母。还有我忘了 Java 中 max 的比较方法,嘿嘿,Math.max(),调用 Math 数据库里的 max() 方法。
结果如下:
class Solution {
public int lengthOfLongestSubstring(String s) {
Map<Character, Integer> map = new HashMap<Character, Integer>();
int max = 0, start = 0;
for(int i = 0; i < s.length(); i ++){
char c = s.charAt(i);
if(map.containsKey(c)){
start = Math.max(map.get(c) + 1, start);
}
max = Math.max(max, i - start + 1);
map.put(c, i);
}
return max;
}
}首先创建一个数据类型为 Character、关键字为整数的哈希表,在这里,我定义了两个量,一个是 max,指所求子串的最长值,一个是 start,指该子串最左端的对应的下角标。循环遍历字符串 s,提取下角标为 i 的字母。如果在哈希表中能够查下角标为 i 的字母的关键字,说明这个字母在之前已经存在于哈希表中了,即重复出现了,此时更新 start 的值,让子串的最左端从该重复的字母的后一位重新开始读取字符串,先暂停一下。
迷惑了吗?首先 if() 语句先于map.put(c, i);,则此时提取的字母还没有存入哈希表中,现在询问一下哈希表是否有过这个字母,如果有,则获取对应的关键字,只需要关键字加一,就能保证到重复字母的这段子串无一重复字母,哈哈哈,被我讲晕了吗?(((φ(◎ロ◎;)φ)))
这时候,取最大值的 start,为什么?如下图我的精美图画:
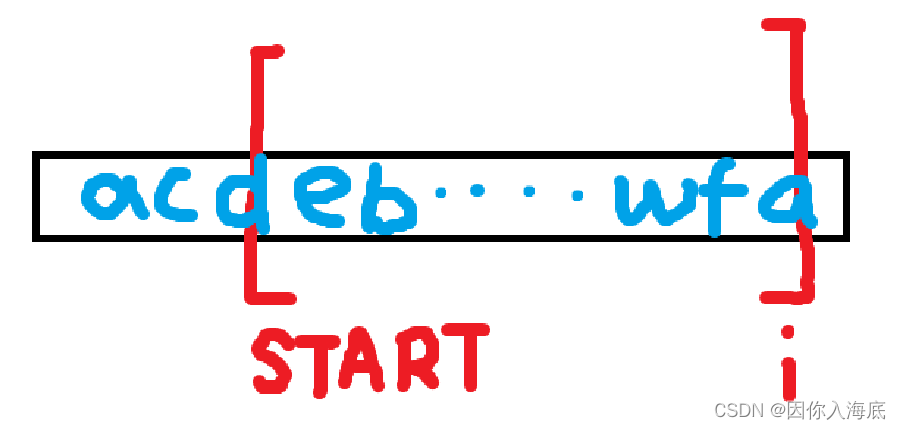
假设前一个遇到重复的字母为 c,则 start 取 d 对应的下角标,之后循环数次,直至 i 碰到了 a 字母,此时发现 a 字母在之前已经出现过了,即哈希表中已有 a 字母及其对应的关键字,若按照取下一位下角标的方法,start 应取字母 c 的下角标,但此时的 start 明显小于 d 的 start,此时只能取大的 start,为什么不取小的?——若取小,则在 deb····wfa 中必定有一个 c(想想你为什会取 d 的 start),会造成重复的 c。
至于 max 取大的值,毋庸置疑,因为你求的就是最长子串啊。(写完这篇,整个人都迷糊了(~﹃~)~zZ)















 141
141

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









