










博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2025年计算机专业毕业设计选题汇总(建议收藏)✅
1、项目介绍
技术栈:
Spark大数据、虚拟机、Hive、Hadoop、Python语言、Django框架、Echarts可视化、vue框架、HTML、selenium爬虫技术、锦江酒店网站数据、协同过滤推荐算法
基于Spark和Hive的酒店数据分析与推荐系统
本项目基于Spark和Hive的大数据处理平台,结合机器学习算法和推荐系统技术,设计并实现一个酒店数据分析和推荐系统。
系统将以北京酒店为例,通过处理和分析大量用户预订、评价和酒店数据,提供个性化推荐,并为酒店运营提供决策支持。
将酒店数据和用户行为数据从多个来源采集并存储到HDFS(Hadoop分布式文件系统)中。
使用Hive作为数据仓库,结构化存储采集到的多维度数据,支持SQL查询以便数据的聚合和统计。
使用Spark对采集到的原始数据进行清洗,去除重复、异常、缺失值等数据噪声,确保数据质量。
对文本类数据如用户评价进行文本清洗,去除无效信息并提取关键信息。基于用户的协同过滤(UserCF),根据用户的历史查看记录,生成个性化的酒店推荐列表。
使用ECharts等可视化工具,将用户行为分析、酒店特征分析以及推荐结果以图表的形式展示,提供可视化的分析报告。
2、项目界面
(1)酒店数据可视化分析大屏
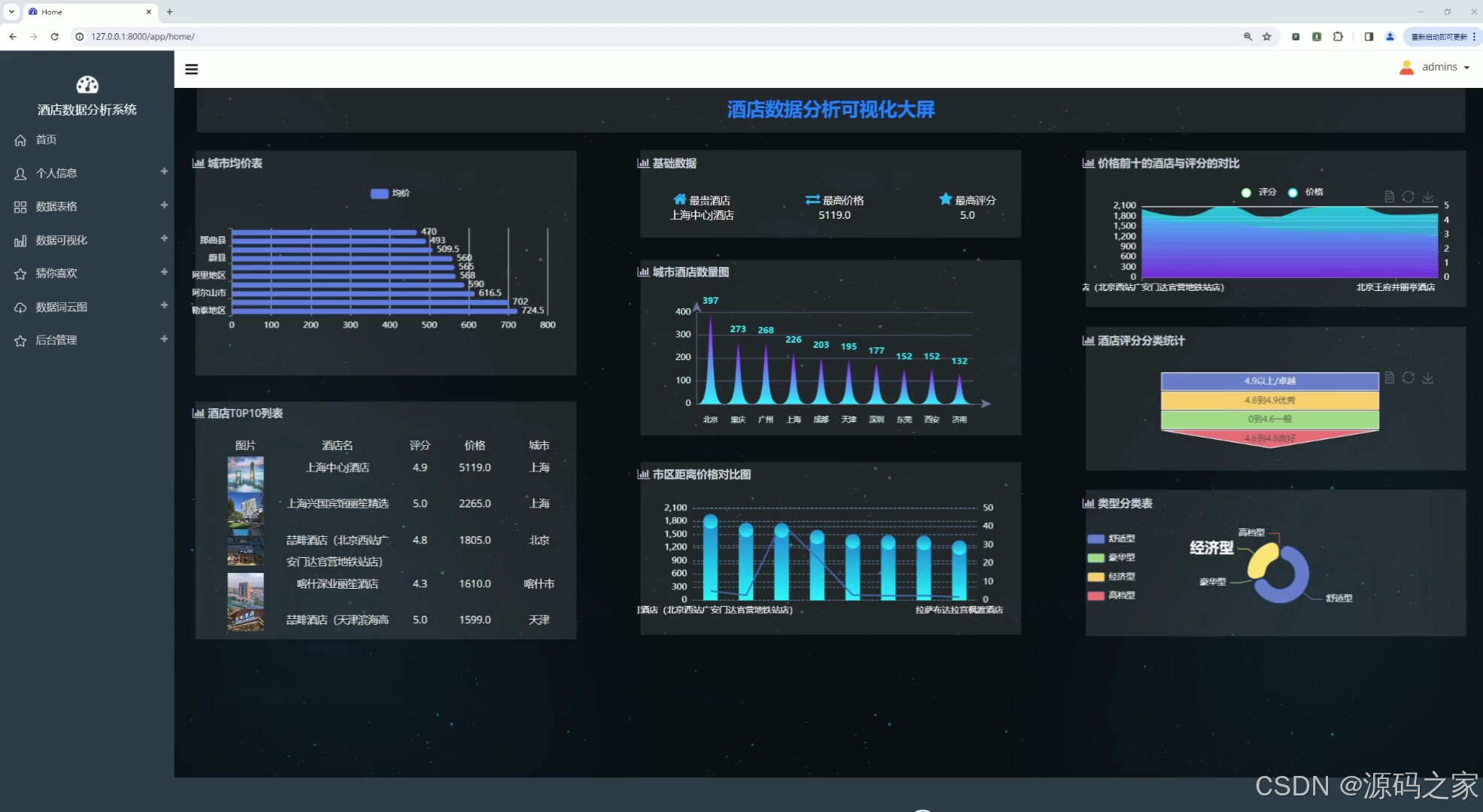
(2)酒店信息数据
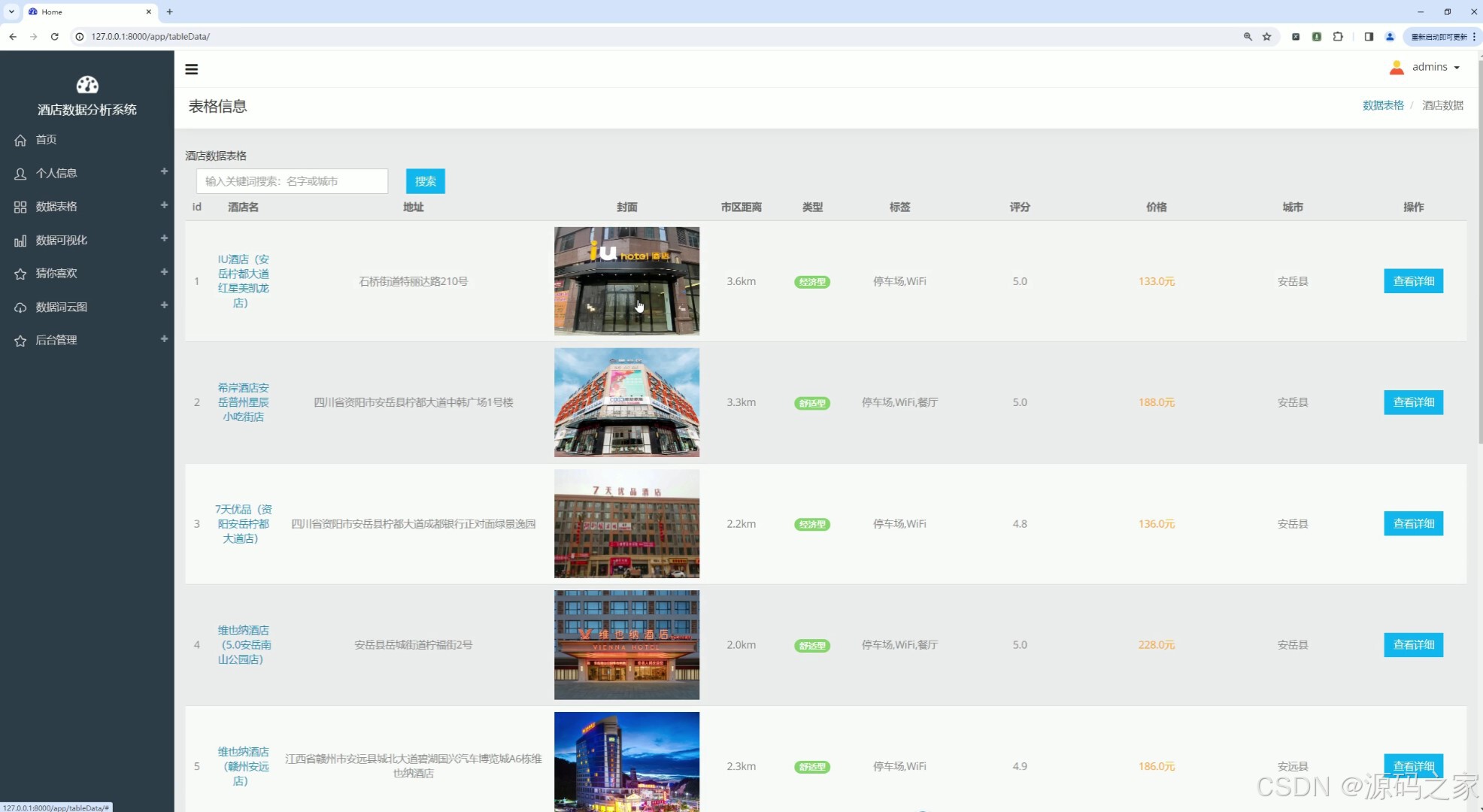
(3)酒店数据省市分布
(4)酒店价格区间柱状图分析和酒店类型饼图分析
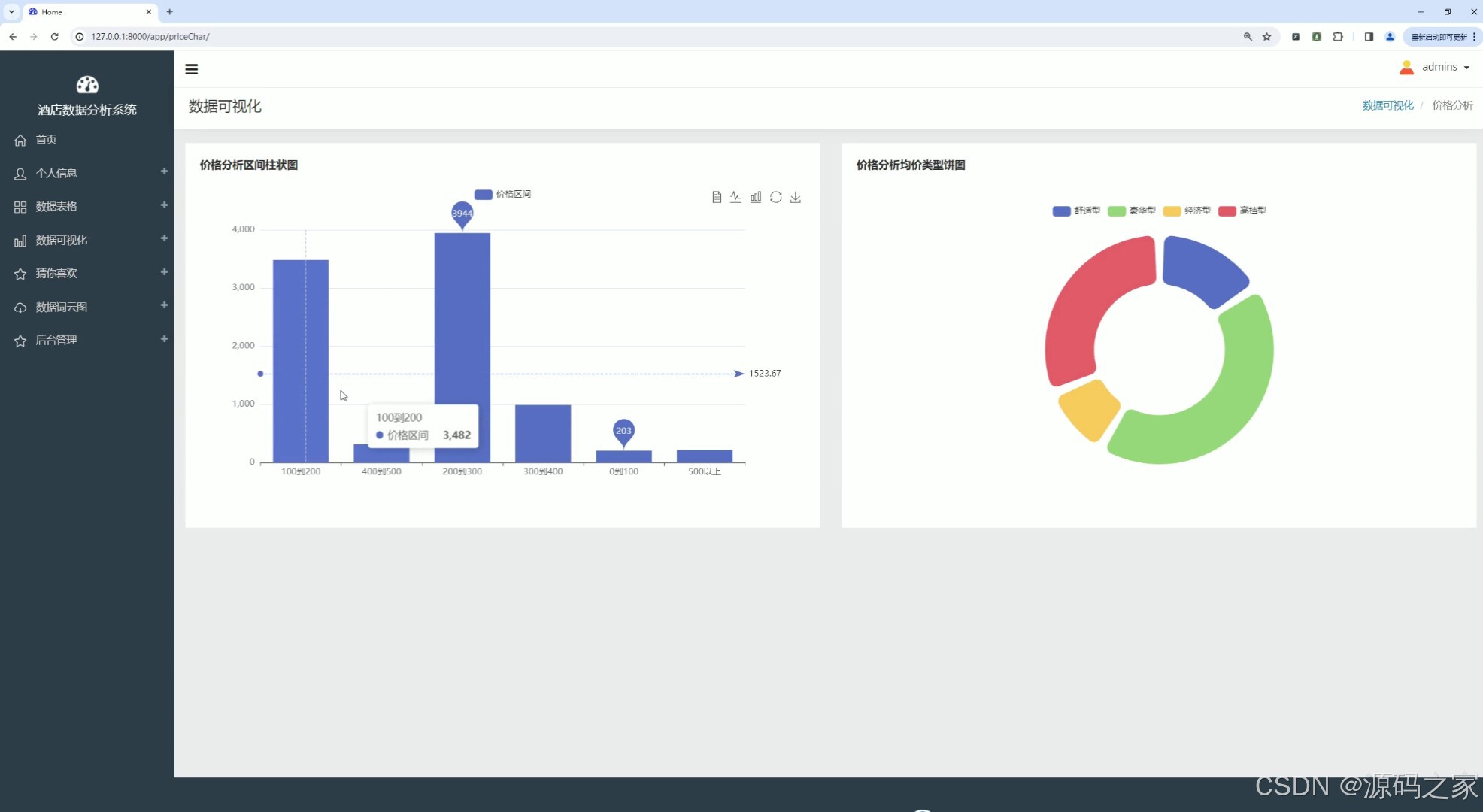
(5)酒店评分数量分布、酒店市区距离分布
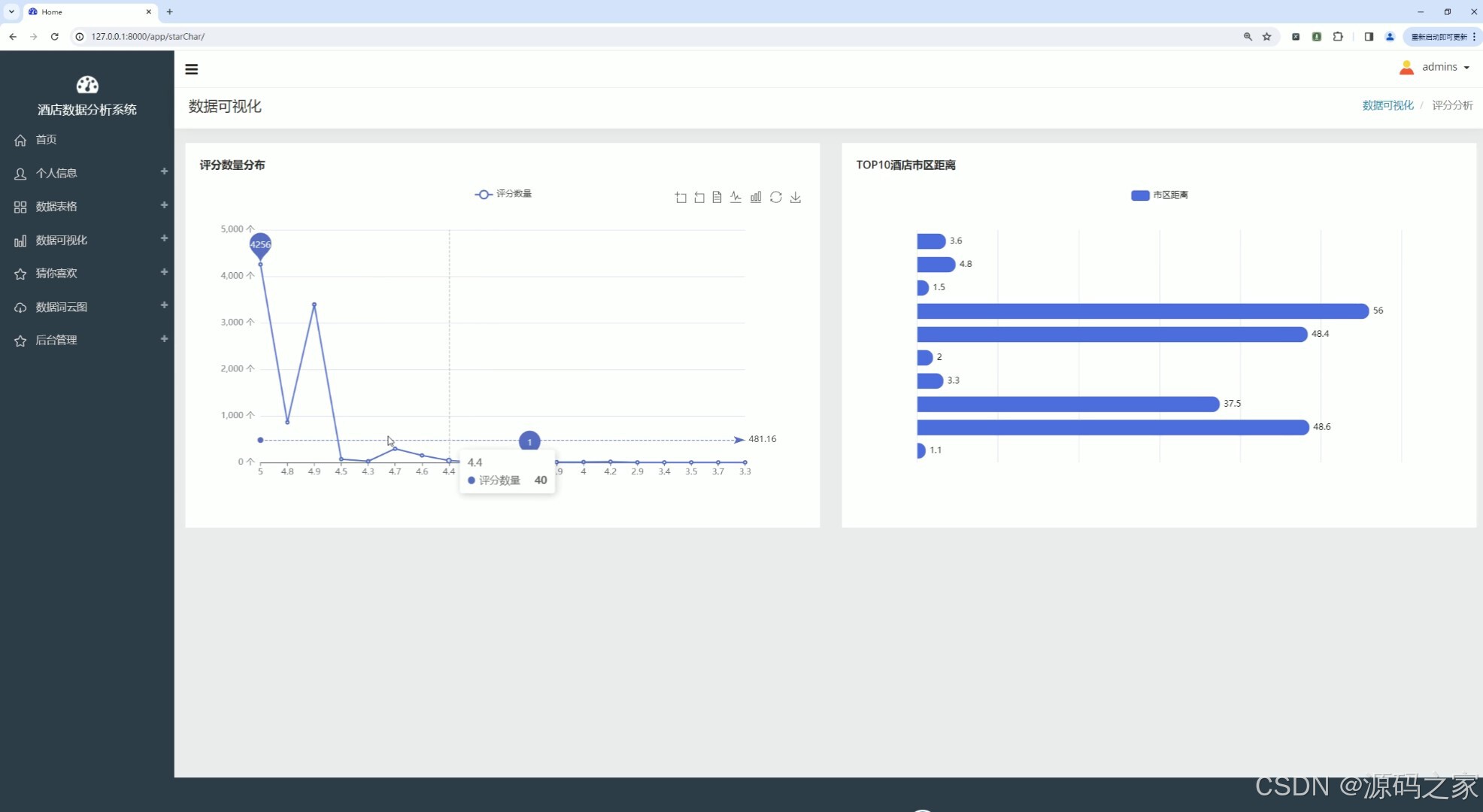
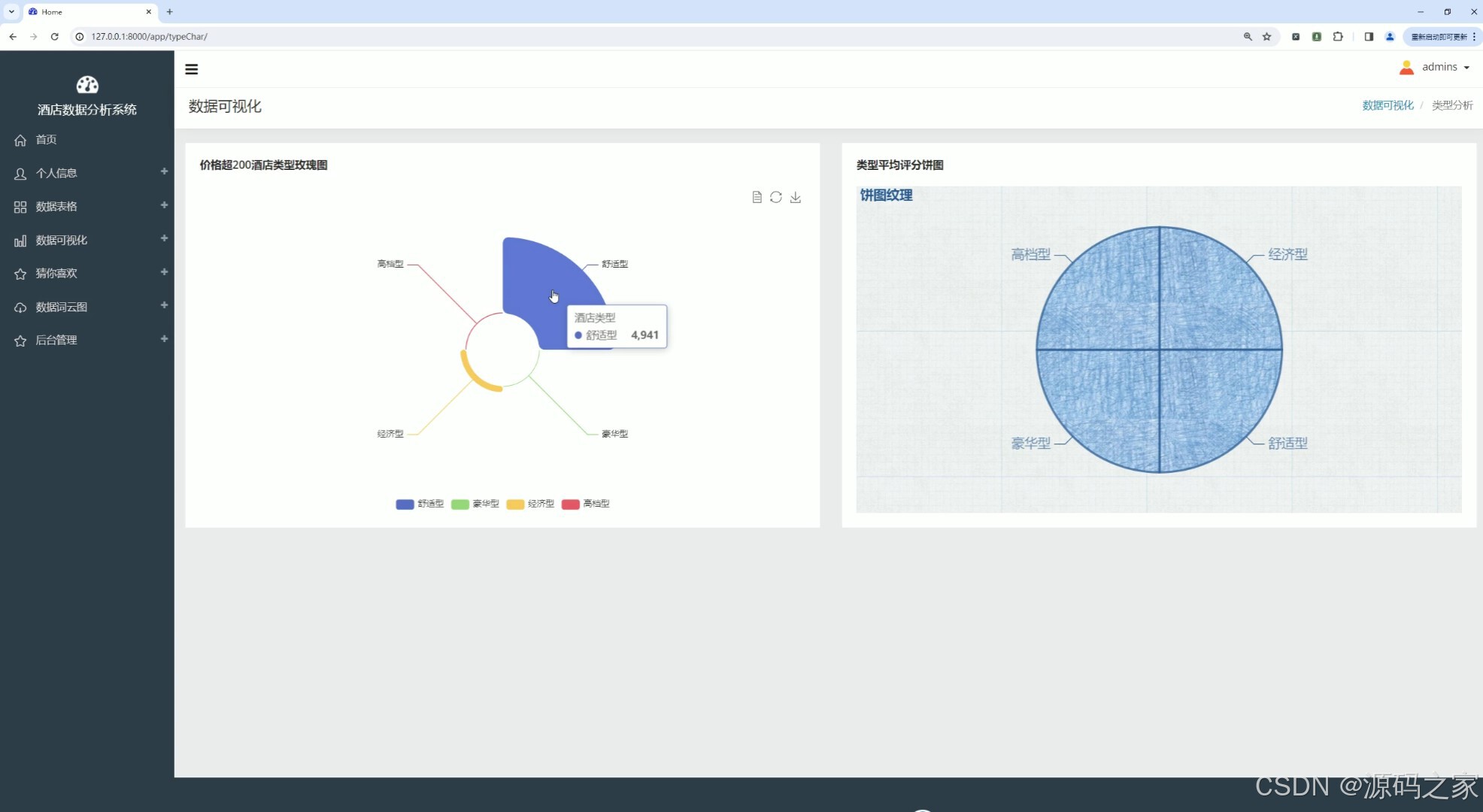
(6)价格超200酒店类型分析、酒店类型平均评分分析
(7)酒店名称词云图分析

(8)注册登录界面
(9)后台数据管理
(10)Spark大数据分析
3、项目说明
本文基于 Spark开发了一个酒店数据分析与推荐系统,目的在于通过对酒店历史数据的深入分析,帮助酒店行业理解市场趋势,并优化客户体验和营销策略。系统使用PySpark进行大规模数据处理,结合机器学习算法进行分析,并通过ECharts实现数据可视化。在数据处理阶段,系统对从锦江酒店网站抓取的酒店数据进行了清洗和预处理,分析了酒店的价格、评分、类型和城市等维度。探索性分析揭示了价格波动、评分分布、类型偏好和城市市场趋势,为后续决策提供了基础。系统采用协同过滤算法,基于用户历史行为和偏好进行个性化推荐,提升了用户体验。通过分析用户的评分和评论数据,系统能够识别出潜在的需求,并为不同客户群体提供推荐。ECharts可视化展示了酒店价格、评分和类型等分析结果,帮助用户直观了解市场表现。系统还生成了酒店词云图和地址词云图,展示了各酒店和地区的关键词及其受欢迎程度。此功能有助于分析酒店竞争力和客户关注热点。通过对推荐系统和数据分析模型的评估与验证,系统验证了分析结果的有效性。该系统提升了酒店数据分析的自动化和智能化水平,为酒店行业决策提供了数据支持,推动了行业的数字化转型。
关键词:Spark;酒店数据分析;协同过滤推荐算法;ECharts可视化
本研究通过基于大数据的酒店数据分析与推荐系统,展示了大数据技术在酒店行业中的广泛应用和潜力。随着旅游业和在线预订平台的快速发展,酒店行业面临着日益激烈的市场竞争和消费者需求的多样化。通过应用Spark强大的数据处理能力,本项目不仅成功地处理和分析了大量的酒店数据,还通过深入的聚类分析和推荐算法,揭示了酒店市场的复杂性以及消费者偏好的多样性。通过对酒店价格、评分、类型等关键特征的聚类分析,本研究为酒店管理者提供了有价值的市场细分结果,帮助他们识别不同消费群体,优化定价策略和服务设计。本研究还深入探讨了评分与销售量之间的关系,进一步分析了影响消费者选择的潜在因素,为提升酒店市场推广效果提供了数据支持。本研究的成果不仅有助于酒店行业更好地理解消费者需求,优化营销策略和服务质量,还为酒店行业在数字化转型过程中提供了新的思路。通过数据分析技术的应用,酒店能够更精准地预测市场趋势、提升运营效率、增强竞争力。本研究验证了大数据分析在酒店行业中的重要作用,并为未来酒店数据分析和智能推荐系统的研究和应用提供了宝贵的经验和启示。这为酒店行业适应数字化浪潮、提升服务质量和市场响应能力提供了有力支持。
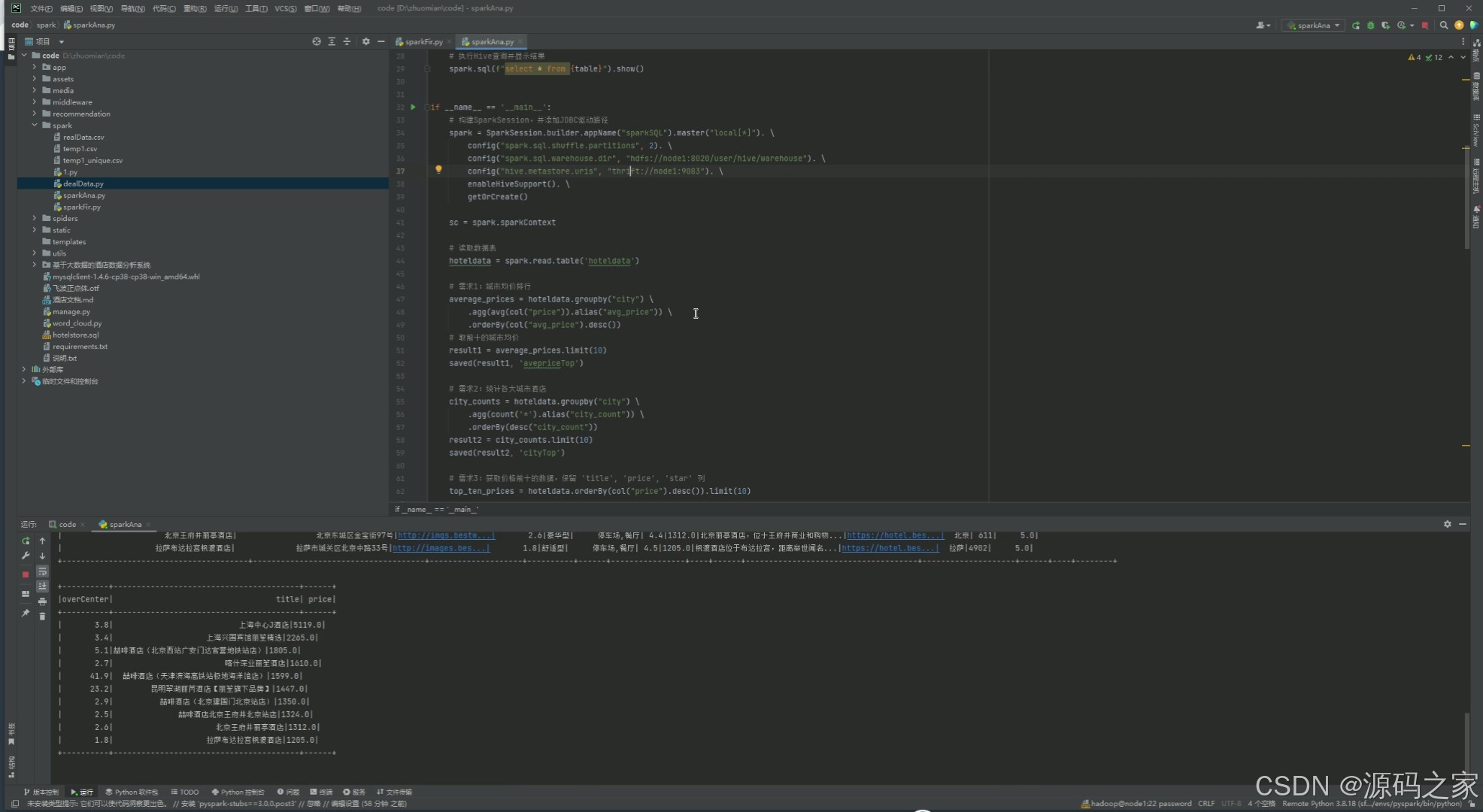
4、核心代码
# coding:utf8
# 导包
from pyspark.sql import SparkSession
from pyspark.sql.functions import count, avg, col, sum, when
from pyspark.sql.functions import desc, asc
from pyspark.sql.functions import max, lit
def saved(result, table):
# MySQL JDBC URL 和连接属性
jdbc_url = "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"
# 将 DataFrame 写入 MySQL 数据库
result.write.mode("overwrite") \
.format("jdbc") \
.option("url", jdbc_url) \
.option("dbtable", f"{table}") \
.option("user", "root") \
.option("password", "root") \
.option("encoding", "utf-8") \
.option("driver", "com.mysql.cj.jdbc.Driver") \
.save()
# 将 DataFrame 写入 Hive 表,使用 parquet 格式
result.write.mode("overwrite").format("parquet").saveAsTable(f"{table}")
# 执行Hive查询并显示结果
spark.sql(f"select * from {table}").show()
if __name__ == '__main__':
# 构建SparkSession,并添加JDBC驱动路径
spark = SparkSession.builder.appName("sparkSQL").master("local[*]"). \
config("spark.sql.shuffle.partitions", 2). \
config("spark.sql.warehouse.dir", "hdfs://node1:8020/user/hive/warehouse"). \
config("hive.metastore.uris", "thrift://node1:9083"). \
enableHiveSupport(). \
getOrCreate()
sc = spark.sparkContext
# 读取数据表
hoteldata = spark.read.table('hoteldata')
# 需求1:城市均价排行
average_prices = hoteldata.groupby("city") \
.agg(avg(col("price")).alias("avg_price")) \
.orderBy(col("avg_price").desc())
# 取前十的城市均价
result1 = average_prices.limit(10)
saved(result1, 'avepriceTop')
# 需求2:统计各大城市酒店
city_counts = hoteldata.groupby("city") \
.agg(count('*').alias("city_count")) \
.orderBy(desc("city_count"))
result2 = city_counts.limit(10)
saved(result2, 'cityTop')
# 需求3:获取价格前十的数据,保留 'title', 'price', 'star' 列
top_ten_prices = hoteldata.orderBy(col("price").desc()).limit(10)
# 查找 star 字段的最大值
max_star = hoteldata.agg(max(col("star"))).collect()[0][0]
# 将最大值转换为字符串,并截取保留一位小数
max_star_str = "{:.1f}".format(max_star) # 保留一位小数作为字符串
max_star_truncated = float(max_star_str) # 转回浮点数
# 将最大 star 值添加为一个新列到 top_ten_prices DataFrame
top_ten_with_max_star = top_ten_prices.withColumn("max_star", lit(max_star_truncated))
# 保存结果
saved(top_ten_with_max_star, 'priceTop')
# 需求4:酒店前十的价格与市区距离对比
result4 = top_ten_prices.select("overCenter", "title", "price").limit(10)
saved(result4, 'centerPriceTop')
# 需求4:酒店前十的价格与评分对比
result5 = top_ten_prices.select("star", "title", "price").limit(10)
saved(result5, 'starPriceTop')
# 需求6:评分分类
hoteldata_starclass = hoteldata.withColumn(
"star_category",
when(col("star").between(0, 4.6), "0到4.6一般")
.when(col("star").between(4.6, 4.8), "4.6到4.8良好")
.when(col("star").between(4.8, 4.9), "4.8到4.9优秀")
.when(col("star").between(4.9, float('inf')), "4.9以上/卓越")
.otherwise("未分类")
)
result6 = hoteldata_starclass.groupby("star_category").agg(count('*').alias("count"))
saved(result6, 'starcategory')
# 需求7:类型分析
result7 = hoteldata.groupby("type").agg(count('*').alias("count"))
saved(result7, 'typecategory')
# 需求8:价格区间分类
hoteldata_priceclass = hoteldata.withColumn(
"price_category",
when(col("price").between(0, 100), "0到100")
.when(col("price").between(100, 200), "100到200")
.when(col("price").between(200, 300), "200到300")
.when(col("price").between(300, 400), "300到400")
.when(col("price").between(400, 500), "400到500")
.when(col("price").between(500, float('inf')), "500以上")
.otherwise("未分类")
)
# 统计每个价格区间的酒店数量
result8 = hoteldata_priceclass.groupby("price_category").agg(count('*').alias("count"))
saved(result8, 'pricecategory')
# 需求9:各类型价格
result9 = hoteldata.groupby("type").agg(avg(col("price")).alias("avg_price"))
saved(result9, 'typeprice')
# 需求10:评分前十的酒店的标题和市区距离
top_start_values = hoteldata.orderBy(desc("star")).limit(10)
result10 = top_start_values.select("title", "overCenter")
saved(result10, 'starCenter')
# 需求11:按类型分组,计算每种类型中价格超过200的酒店数量
result11 = hoteldata.groupby("type").agg(
sum(when(col("price") > 200, 1).otherwise(0)).alias("price_over")
)
saved(result11, 'typeTwo')
# 需求12:计算每种类型的酒店的平均评分
type_avg_start = hoteldata.groupby("type").agg(avg("star").alias("avg_start"))
# 将结果按类型排序
result12 = type_avg_start.orderBy("type")
saved(result12, 'typeStar')
# 需求13:计算每个城市的酒店数量
result13 = hoteldata.groupby("city").count()
saved(result13, 'addresssum')
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 6138
6138

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









