






CODE:ICLR 2025
ABSTRACT
文本到图像生成模型的最新进展极大地增强了从文本提示生成逼真图像的能力,从而增加了对个性化文本到图像应用的兴趣,特别是在多主题场景中。然而,这些进展受到两个主要挑战的阻碍:首先,需要根据文本描述准确地保持每个引用主题的细节;其次,在不引入不一致性的情况下,在单个图像中实现多个主题的内聚表示的困难。为了解决这些问题,我们的研究引入了MS-Diffusion框架,用于布局引导的多主体零样本学习图像个性化。这种创新的方法将接地令牌与特征重采样器集成在一起,以保持主题之间的细节保真度。在布局引导下,MS-Diffusion进一步改善了交叉注意,以适应多主体输入,确保每个主体条件作用于特定区域。所提出的多主题交叉注意在保持文本控制的同时协调了和谐的主题间组合。综合定量和定性实验证实,该方法在图像和文本保真度方面都超越了现有模型,促进了个性化文本到图像生成的发展。
INTRODUCTION
多主题个性化方法在无微调的框架中经常导致显著的细节不准确,并且经常导致生成图像中的主题忽略、主题过度控制和主题-主题冲突问题。

本文首先引入了布局引导的多主体零样本学习图像个性化(MS-Diffusion)框架,该框架整合了对多主体的适应、零样本学习学习能力的整合、布局指导的提供、以及基本模型参数的保留。
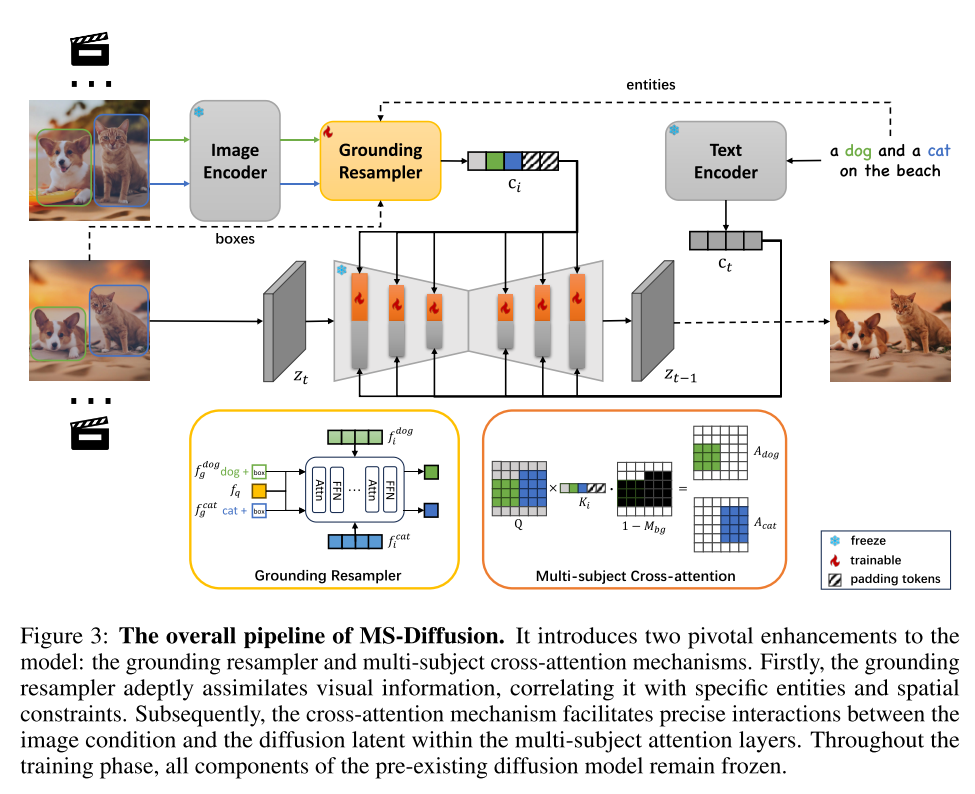
首先,设计了grounding resampler,提取目标的细节特征,并将其与包含实体和框的接地信息进行整合。该接地重采样器作为图像投影模块,通过添加语义先验和位置先验,提高了图像的保真度。
其次,提出了一种新的多物体交叉注意机制,该机制将被试限制在特定的领域。这种融合不仅有助于将多主题数据有效地注入模型中,而且还缓解了文本和图像主题控制条件之间的冲突。这种方法在对图像的多主题构图的精细粒度控制中达到顶峰。
总结了以前的P-T2I工作,并在表1中提供了总体比较。

贡献:
• 在扩散模型范式中引入了一个布局引导的零样本学习多主体图像个性化框架,称为“MS-Diffusion”。这一创新简化了保存详细主题参考资料的复杂过程。并且将多个主体无缝地融合成一个连贯和谐的个性化形象。
• “’Grounding Resampler”是一种先进的新型特征细化机制。该结构通过确定相关内容并将其与框嵌入融合,从而为每个主题划分预期的空间区域,从而丰富了图像的细节提取。此外,还引入了一个专门的多主体交叉注意机制,以面对和纠正多主体个性化中普遍存在的并发症,包括无意的主体忽视、不成比例的主体优势和相互之间的主体冲突。
• “MS-Diffusion”的能力通过其合成具有显著保真度的更广泛的图像光谱的能力得到经验证实。本文进一步描述了全面的消融研究,支持设计决策背后的基本原理,并肯定了提出的方法的有效性。
RELATED WORK
TEXT-TO-IMAGE GENERATION
为了更好地控制文本到图像的生成,一些扩散模型支持用户提供布局指导。
Layout Diffusion (2023)和GLIGEN (2023c)将边界框的位置和标签输入扩散模型,并训练扩散模型学习布局信息。DenseDiffusion (2023)开发了一种无需训练的方法,并在推理阶段调节注意图。Instance Diffusion(2024b)和MIGC (2024)将布局条件扩散扩展到实例级,使模型能够生成具有精确数量的多个对象。虽然布局引导扩散模型具有鲁棒的可控性,但它们不能引用特定的概念,这在个性化的文本到图像生成中得到了强调。
TEXT-TO-IMAGE PERSONALIZATION
单主体个性化方法:
Instruct-imagen 2024:通过强大的文本和图像提示参考能力引发关注。Instruct-imagen: Image generation with multi-modal instruction.
Textual Inversion(2023)与DreamBooth(2023):基于微调技术,利用文本标识符绑定视觉概念。
IP-Adapter(2023):零样本模型,将图像嵌入投影至交叉注意力层以实现个性化生成。
InstanceID(2024a):结合人脸编码器与ControlNet的面部关键点控制,优化身份个性化生成。
多模态输入统一:
Kosmos-G(2023)与λ-ECLIPSE(2024):通过文本-图像交错的多模态训练,缩小图像与文本提示间的差距。
SSR-Encoder(2024):设计查询网络,从多主体图像中提取单主体以实现个性化。
现存挑战:尽管上述研究提升了单主体个性化生成能力,但零样本多主体个性化模型的探索仍有限。现有方法在多主体生成时易产生冲突(如特征混淆、生成质量下降),导致效果不佳。
METHOD
PRELIMINARIES
Stable Diffusion with Image Prompt. 在IP-Adapter (2023)等零样本学习图像个性化架构中,图像也可以被视为扩散模型的一个条件。具体来说,通过图像编码器将主题图像编码为图像嵌入,然后投影到扩散模型的原始条件空间中,表示为ci。对于在固定范围内均匀采样的时间步长t,模型θ预测噪声ϵθ,并通过目标进行优化:
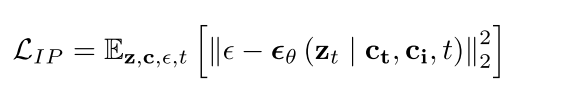
本文使用SDXL的损失函数作为预训练模型,该模型包含两个CLIP文本编码器和除c和t之外的附加条件输入。 Ci为额外文本提示,Ct为额外图像提示。
Cross-attention. 在IP-Adapter中,ci和ct都通过交叉注意层集成到U-Net骨干网中:
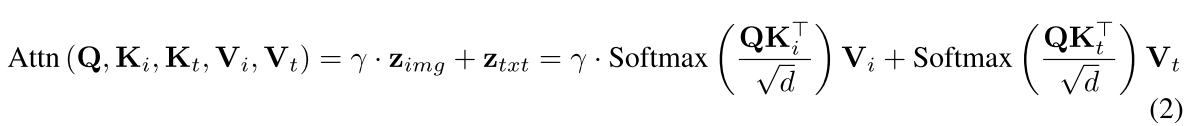
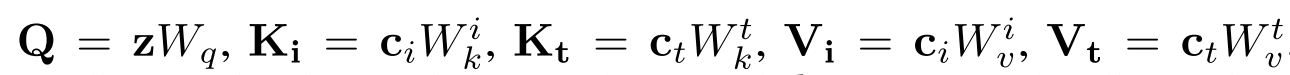
ci和ct的键和值矩阵是相互独立的,以解耦不同模态的条件。
注意图可以反映生成的图像与条件之间的归因关系,这意味着它们决定了条件控制的效果。
![]()
DISCUSSION ON MULTI-SUBJECT IMAGE PERSONALIZATION
大多数相关研究专注于缓解基础模型文本交叉关注中的视觉冲突。虽然修改文本交叉注意是有效的,但也存在一定的局限性。
首先,对文本交叉注意的调整可以直接影响对文本条件的控制。
其次,文本交叉注意并不直接决定图像条件的影响区域;相反,它通过塑造扩散模型生成的图像布局来间接影响图像条件。这种间接控制可能导致低性能和增加不确定性。
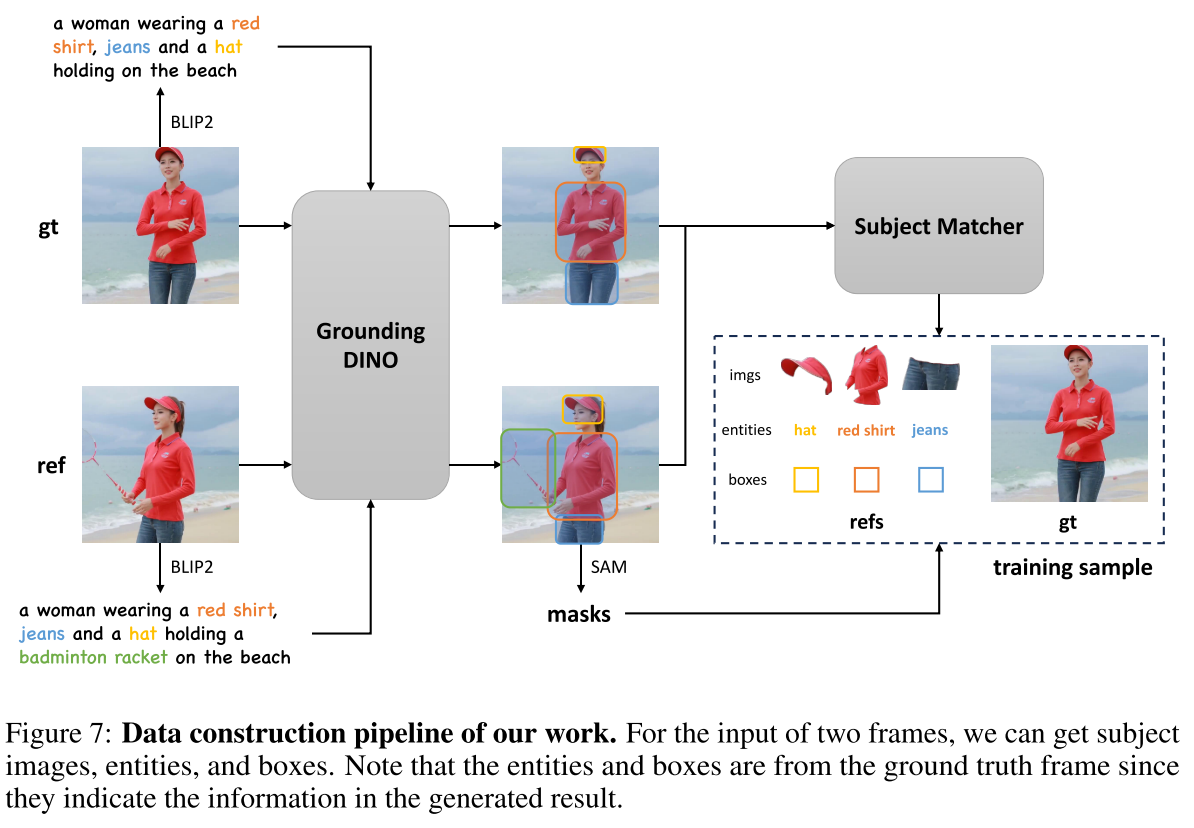
DATA CONSTRUCTION
本方法首先将命名实体识别(NER)协议应用于文本数据以提取相关实体。然后在检测框架中使用这些实体来定义相应的边界框。这一步生成包含一系列[主题,实体,空间布局]的训练样本。
GROUNDING RESAMPLER
图像嵌入特性:相比文本嵌入,图像嵌入信息更丰富且更稀疏,直接投影到条件空间困难。传统方法(如池化输出)易丢失细节。现有方法不足:Flamingo 和 IP-Adapter 等方法依赖图像编码器的全局特征,难以精准控制多主体生成。引入一组可学习的查询令牌(f_q),通过注意力机制从图像特征(f_i)中蒸馏关键信息。
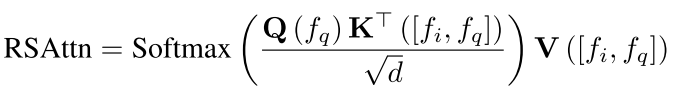
其中,[f_i, f_q] 是图像嵌入与查询令牌的拼接,d 为维度缩放因子,采用与 Vision Transformer 类似的全连接前馈网络(FFN)增强特征处理能力。
多主体初始化与训练策略
基于文本与位置的初始化:利用文本嵌入(实体语义)和位置框的傅里叶嵌入生成初始化查询令牌(f_p),引导模型关注特定区域和语义信息。
防过拟合策略:训练时随机将初始化令牌替换为原始可学习查询,避免模型对固定初始化过度依赖。
独立投影与拼接:多个主体的图像投影过程相互独立,最终将每个主体的查询令牌拼接为 c_i(总令牌数:N = n * n_t,n 为主体数,n_t 为单主体令牌数)。
MULTI-SUBJECT CROSS-ATTENTION
为了将每个主题的上下文限制在指定的空间域中,建议对传统的注意掩码进行增强,表示为m。这种调整涉及在查询和键矩阵中双边忽略令牌,具体应用于第j个主题如下:
掩码定义:对第j个主体,基于其边界框坐标Bj定义掩码Mj(x,y):
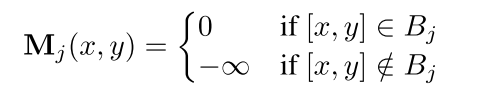
这里,Bj表示与第j个主题相关的边界框的坐标集。
全局掩码拼接:所有主体掩码拼接为M=Concat(M0,…,Mn),用于图像潜在表示z^imgz^img的计算:
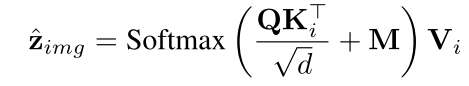
其中,M表示所有主题特定掩模的合并,Concat(M0,…),Mn)。这样,模型就保证了每个主题都在一定的区域表示,从而解决了图2中主题被忽略和冲突的问题。
虚拟令牌与背景控制
问题:当查询区域被所有主体掩码覆盖或完全未覆盖(如边界框重叠),掩码机制失效。
解决方案:引入随机初始化的虚拟令牌(dummy tokens),表征背景区域。文本条件可自由控制未被布局指导的区域,避免对主体的过度约束(见图2中的“overcontrol”问题)。
背景掩码Mbg:定义二进制掩码,边界框内为0,框外为1。最终图像潜在表示修正为:
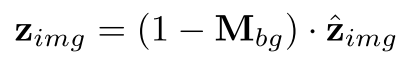
-
细粒度控制:通过掩码精准约束主体生成区域,减少冲突与忽略。
-
文本条件保留:虚拟令牌确保文本提示对背景区域的主导权,实验显示文本遵循能力提升。
-
对比实验:与基于注意力图优化的方法相比,本方法在多主体冲突处理中表现更优。
EXPERIMENTS
EXPERIMENT SETUP
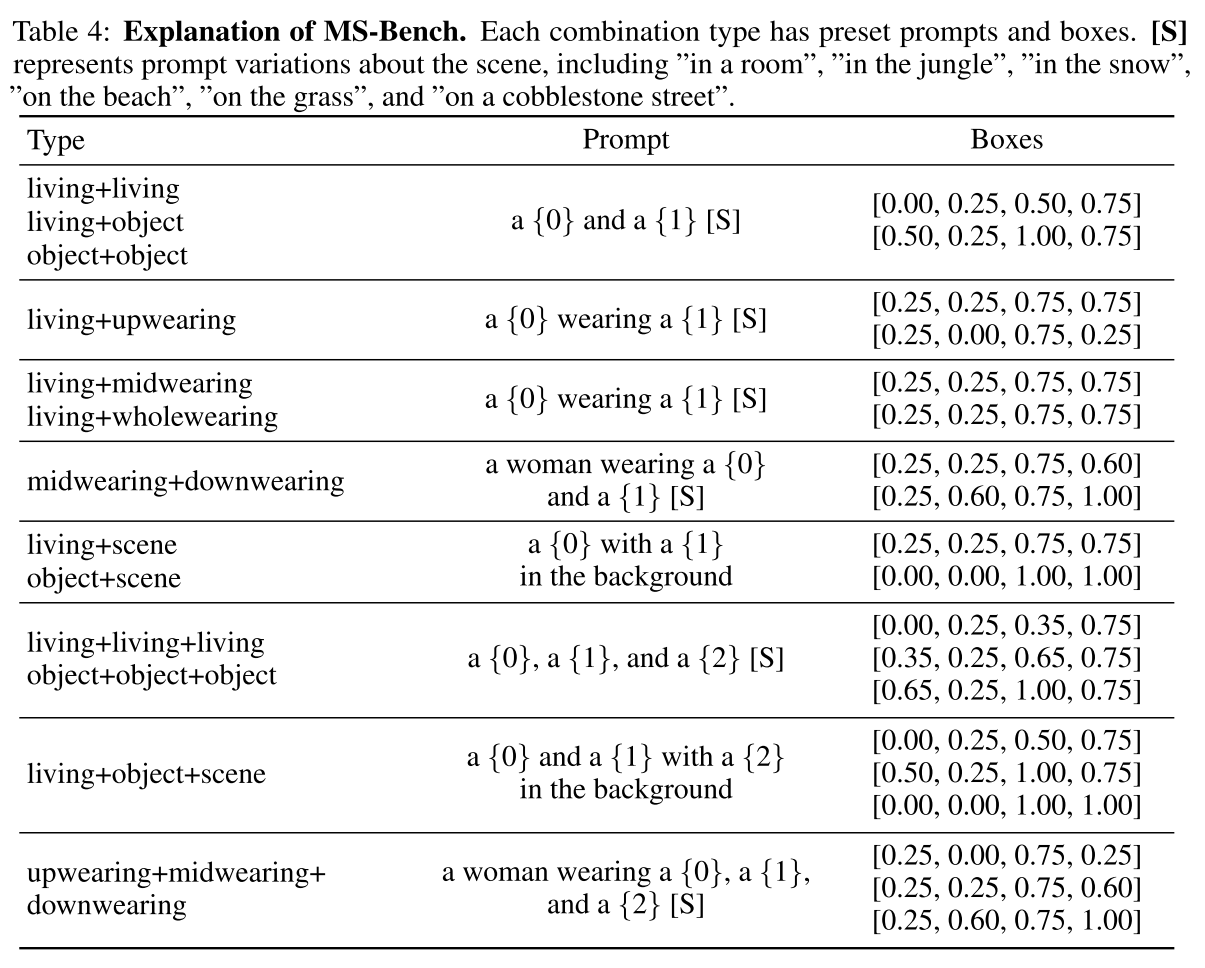
Datasets. 训练时,使用包含360万个视频剪辑的内部视频数据集。为了进行评估,分别在DreamBench (2023)和MS-Bench上测量了单受试者和多受试者的性能。DreamBench包括30个科目和25个提示,预设所有输入框为[0.25,0.25,0.75,0.75]。为了全面评估多受试者个性化的性能,建立了新的评估标准MS-Bench,该标准包括40个受试者和1148个组合,每个组合最多有6个提示,共计4488个不同的测试样本。数据集的详细信息见A节和B节。
Evaluation metrics.根据之前的工作,通过图像和文本保真度来衡量性能。为了评估图像保真度,在CLIP (2021)和DINO (2021)空间(分别称为CLIP- i和DINO)中使用生成图像和主题图像之间的余弦相似性度量。对于文本保真度,利用CLIP空间中生成的图像和文本提示之间的余弦相似度,表示为CLIP- t。在多主体个性化中,使用平均保真度来反映图像保真度是不够的,因为它不能揭示主体忽视的情况。进一步使用多主题DINO的乘积,记为M-DINO,来表示每个主题是否在结果中被重新创建。
Baselines. 对于单主题个性化,将模型与表1中提到的方法进行比较。Emu2 (2023)、Kosmos-G (2023)和λ-ECLIPSE (2024)都是基于mllm的方法,而λ-ECLIPSE据称性能更好。因此,选择SSR-Encoder (2024)和λ-ECLIPSE (2024)作为多主体个性化的基线。考虑到公平性,MS-Diffusion的定性结果是在没有任何基准微调的情况下生成的。MS-Diffusion和这些方法的实现细节在C部分。
SINGLE-SUBJECT COMPARISON
在单主题比较中,进行了详细的检查,利用定性和定量比较来衡量不同方法的性能。
在定性方面

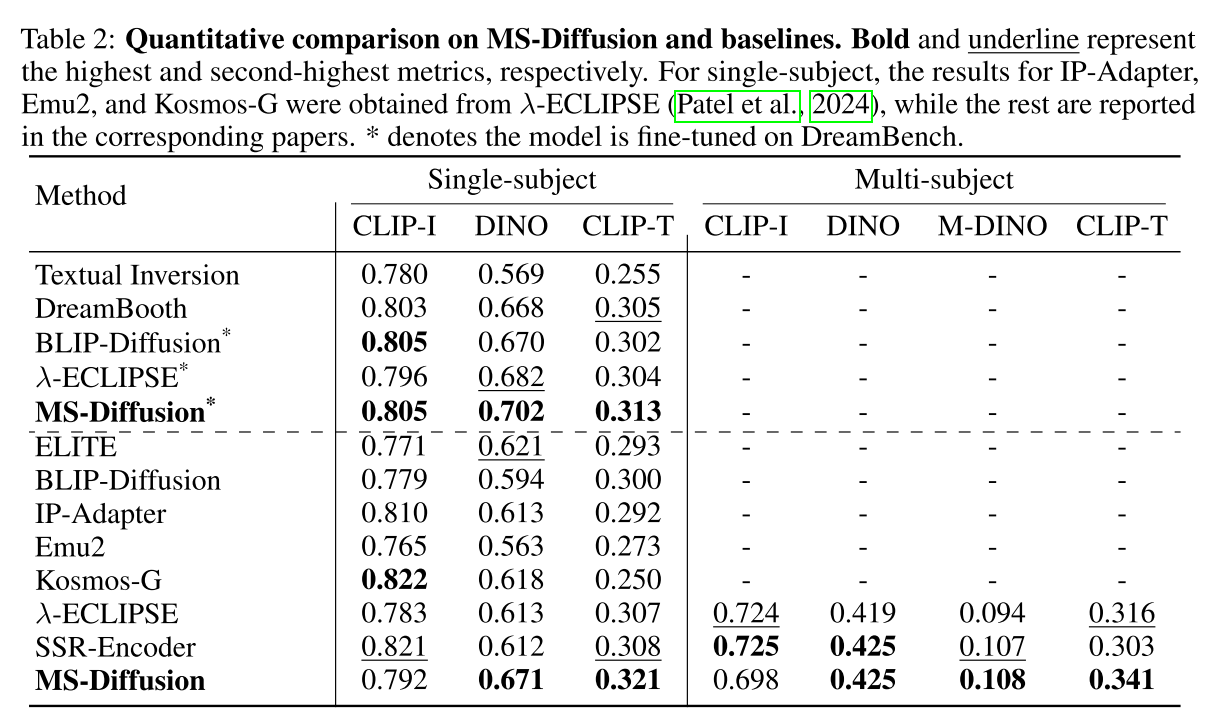
在表2提供的定量结果中
MULTI-SUBJECT COMPARISON
从图5的定性角度来看,MS-Diffusion设法在生成的图像中保持受试者之间的自然交互,同时确保每个受试者保持其独特性和可识别性。

定量,表2的结果显示了ms -扩散在DINO、M-DINO和CLIP-T中的强度。
与单主题个性化不同,MS-Diffusion与多主题个性化的基线在文本保真度上存在较大差距,这表明MS-Diffusion不仅有效地生成文本中概述的多个主题,而且很好地保留了SD固有的文本控制能力。此外,MS-Diffusion的图像保真度是相当的,突出了其保留细节的卓越能力,特别是在低文本保真度通常与过拟合相关时。
ABLATION STUDY
Module ablation. 对提出的两个模块,(GRS)和(MCA)进行了烧蚀实验,以验证它们的效果。
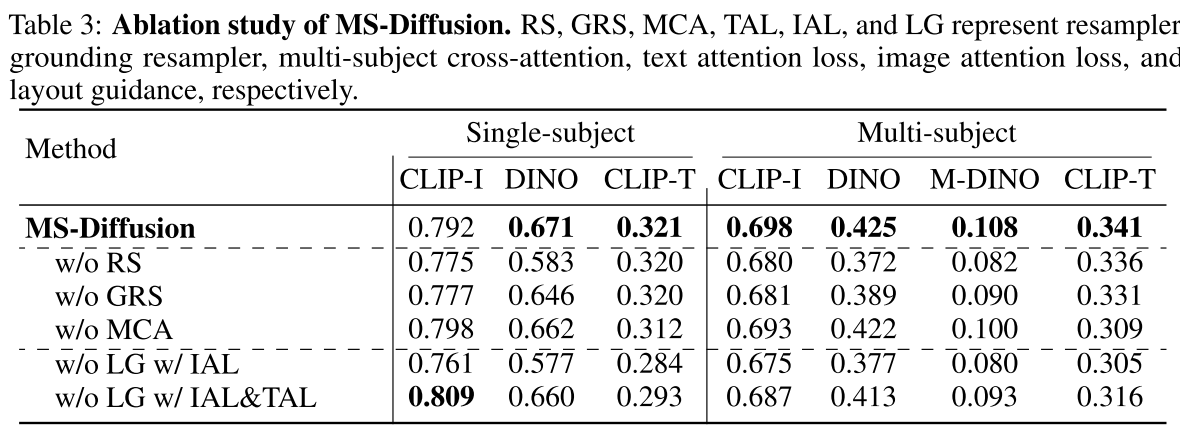
从表3的结果可以看出,类重采样器图像投影仪可以明显增强细节,DINO明显高于线性投影仪。此外,GRS对多目标图像保真度的大幅提高反映了接地令牌所携带的信息在多目标生成中的关键作用。作为解决冲突的关键模块,去除MCA会导致文本保真度的显著降低,特别是在多主题生成中。两个模块的结合使用确保MS-Diffusion同时保持高图像和文本保真度。
在图6中提供了关于模块消融的可视化结果。从定性的例子中可以清楚地看出,GRS增强了细节,而MCA处理了冲突。

Layout guidance. 如3.5节所述,已经探讨了显式布局指导(LG)不可或缺的作用,包括grounding tokens和MCA。隐含利用布局的一种直接方法包括在训练期间将注意力丢失纳入其中。除了图像注意力损失(IAL),还通过设置原始交叉注意层可训练,将文本注意力损失(TAL)引入到训练中。详细的损失定义见第g节。如表3所示,引导图像交叉注意的目标对个性化几乎没有帮助。TAL在一定程度上解决了冲突问题,但由于引入了额外的训练参数,其性能不如MS-Diffusion。我们认为包含LG是必要和合理的,不仅因为它提供了性能增强,还因为它有效地解决了图2中突出显示的各种多对象生成问题。
TRAINING DATASET CONSTRUCTION PIPELINE
DETAILS OF MS-BENCH
EXPERIMENT SETTINGS
Training and Inference.
MS-Diffusion中使用的预训练模型是Stable Diffusion XL (SDXL) 。由Pytorch 2.0.1和Diffusers 0.23.1实现,在16个A100 gpu上训练了120k步,批处理大小为8,学习率为1e-4。在IP-adapter 的训练之后,在交叉注意层中设置γ = 1.0,并使用相同的概率丢弃文本和图像条件。为了确保模型不依赖于接地令牌(第3.4节),还以0.1的概率随机丢弃它们。在推理过程中,我们为每个样本生成5张图像,无条件指导尺度和γ分别设置为7.5和0.6,以获得更好的结果。
LAYOUT GUIDANCE
对于单个跨注意层,第j个被试的注意损失计算公式为:
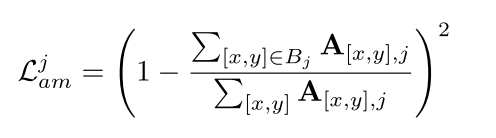
在各层和受试者之间平均Lj am,并在最终损失时将其权重设置为0.01。为了验证文本注意力损失,还在训练中优化了文本跨注意层,可学习参数增加了大约70%。
LIMITATIONS
MS-Diffusion有一定的局限性。基于方框的位置指示缺乏精度,当受试者之间的互动更强时,很难有效地工作。此外,该模型在推理过程中需要明确的布局输入,难以生成复杂的场景。MS-Diffusion虽然在单主体和多主体生成方面都优于SOTA个性化扩散方法,但仍然受到主体图像背景的影响。
我们探索了在推理过程中显式布局需求的解决方案。MS-Diffusion支持使用文本交叉注意图作为伪布局指南。具体来说,如图10所示,由于文本交叉注意映射可以反映每个文本标记的面积,因此我们可以在推理期间用它们替换先前的布局。在实践中,我们设置阈值从文本交叉注意图中提取掩码,并在T步去噪后应用它们。在T之前,我们尝试完全禁用布局指导或使用一个粗略的框作为布局先验。结果如图11所示。虽然禁用布局引导会导致主题一致性下降,但仍然表明在推理过程中显式布局引导是可以优化的。探索的一个方向是让模型在训练过程中学习布局。





















 1765
1765

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











