






我们曾经已经学过 C 语言里边有一些操作符,比如 + - * /,但是我们没有详细的去探究这些操作符,所以今天我们就把操作符这些内容探究一下,让我们对于操作符有更深刻的认识,让我们这些操作符有更好的一些使用
这个章的重点是要给大家去讲清楚各种操作符的一个使用,各种操作符的介绍,然后接下来是表达式求值,就是说有那么多操作符,我们要操作符如何进行表达式的求值呢?
30.1 算术操作符之除法与取模
操作符大概分为这么些类,第一类叫算术操作符,其实这些操作符我们是不是好像在第11章的时候,当时学过一遍,但是当时我们并没有把每一个操作符仔细的给大家去讲。所以,今天这个章节是把这些操作符详细给大家去讲,那么,我们首先来看算术操作符。操作符分类,首先是算术操作符,算术操作符都有哪些呢?就是 + - * / % 这样的操作符叫算术操作符;接下来叫移位操作符;还有叫位操作符(位操作符也叫位运算操作符);还有赋值操作符;还有单目操作符(我们之前学,什么叫单目呢?就是它只有一个操作数的这种操作符叫单目操作符);接下来还有关系操作符(就是比较大小的,比较它们之间关系的这种操作符叫关系操作符);然后就是逻辑操作符;条件操作符;还有逗号表达式;以及下标引用、函数调用和结构成员访问的相关操作符
在 C 语言里边有很多的操作符,都有哪些操作符呢?一共有10种操作符
1. 算术操作符:+ - * / %(取模、取余)
2. 移位操作符:>> <<
3. 位操作符:& | ^
4. 赋值操作符:= += -= *= /= &= |= ^= >>= <<=
5. 单目操作符:! - + & sizeof ~ -- ++ * (类型)
6. 关系操作符:> >= < <= == !=
7. 逻辑操作符:&& ||
8. 条件操作符:exp1 ?exp2 :exp3
9. 逗号表达式:exp1,exp2,exp3,...expN
10. 下标引用、函数调用和结构成员:[ ] ( ) . ->
这是我们这一块操作符的分类,当然我们知道这些分类之后,我们还得一个一个的操作符往下介绍,首先,我们就来看算术操作符,其实算术操作符,大概就这么几类:+ - * / %,其实这些操作符,你说难么?不难。你说简单吧,它还有一些细节要去用。就比如说:加号,就是计算加法的,它可以加2个整数;也可以加2个字符;也可以加2个浮点数。减号也一样,乘号也一样,对于除号来说,它有一些小小的讲法,举个例子
首先,我们写出我们的 main 函数,然后除号就是这么一个斜杠\,有人说那我们这个除号在数学里边是这样写的:÷。但是,在我们的 C 语言里边,这个除号使是用一个 \ 来表示的,有人说我们乘号好像在数学里边是这样的:×。但是,在我们的 C 语言里边是怎么表示的呢?C 语言里边表示的时候,用的是一颗星星*,如图所示:

那我们要做除法的话,我们怎么去做呢?比如:3/5,有人说3/5的话,不就是个0.6么?按照我们数学的一个想法是这样的,但是当我们去写的时候,int a = 3/5,我们打印一下 printf("%d\n", a),这个时候我们用了 printf 语句,所以我们得引个头文件,即:#include<stdio.h>
为什么是0呢?因为3/5的时候,左边和右边两个操作数,一个3一个5都是整数,那它除法的执行叫整数除法,3/5叫商0余3,就是不够除,商了个0,但不够除的话,余了个3,商0余3就这个道理。那这个时候3/5得到的其实是商,就是0,商了个0,如图所示:
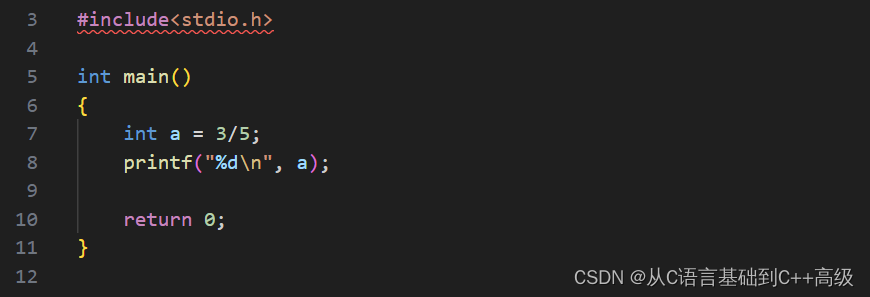

要是改成6呢?6/5呢?我们会发现:结果是1,而不是1.2,6/5是商1余了一个1,所以得到的结果就是一个整数,这叫整数除法,如图所示:
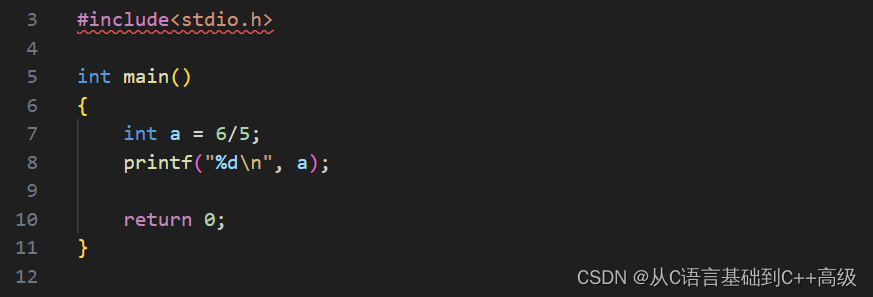

有人就说:我不想要这个东西,我要的是浮点数,是小数,为什么打印了个整数呢?我们想得到小数的时候,怎么弄呢?有人就说简单,6/5之后应该是个小数,要想得到小数,就把它放到小数里边去,然后把 int 改成 float,即:float a = 6/5,然我们打印一下
结果依然是1.0,好像不是1.2,其实最源头的问题,不是 a 里边能不能放得下一个小数的问题,而是6/5得到的结果,本来就是1了,1我们以浮点数的形式放到浮点型的变量里边去,打印出来还是个1,如图所示:


我们如果真的想得到一个小数的话,改怎么做呢?对于除号这个操作符来说,我们想得到小数,它的两端至少得有一个数是浮点数,比如6改成6.0,它就是浮点数了;或者我们把把5改成5.0,只要除号的两端有一个数是浮点数,它执行的就是浮点数的除法
而算出的如果是个浮点数,再放到浮点数里边,再用浮点数的形式打印,这才可以的,如图所示:


因此,如果对于除号来说,我们想得到的是小数,那应该保证除数和被除数里边,至少有一个数是浮点数,有人说那两个都是浮点数呢?那就应好了,肯定是浮点数的,如图所示:

注意:直接写出的这种数字,比如6.0 || 5.0,写出来之后,编译器会默认认为它是 double 类型的,它是 double 类型的时候,这两个计算除出来的结果,也是 double 类型,double 类型的双精度浮点数,双精度浮点数的值如果放到一个 float 类型的变量里边,单精度的变量里边去的话,可能会丢失精度
当然,如果我们不想看到这个警告,我们可以把6.0后边加个f,5.0后边加个f,那这个时候就变成一个 float 类型的变量,如图所示:


其实还有一种写法,就是如果我们这非要写6.0/5.0的话,我们把 float 改成 double,printf("%f\n", a)改成 printf("%lf\n", a)就可以了,这也是可以的
因此,我们可以得出结论:1. 除了 % 操作符之外,其他的几个操作符可以作用于整数和浮点数,2. 对于 \ 操作符,如果两个操作数都为整数,执行整数除法。而只要有浮点数执行的就是浮点数除法
对于取模也有讲法,对于取模操作符来说,%操作符的两个操作数必须为整数,返回的是整数之后的余数
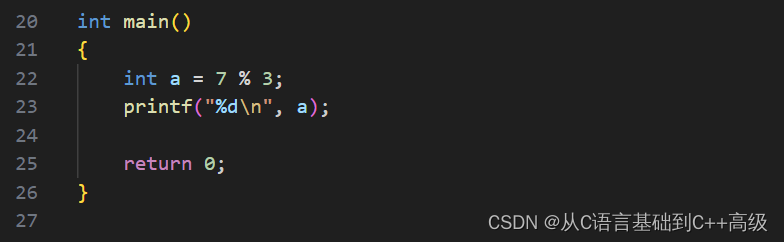
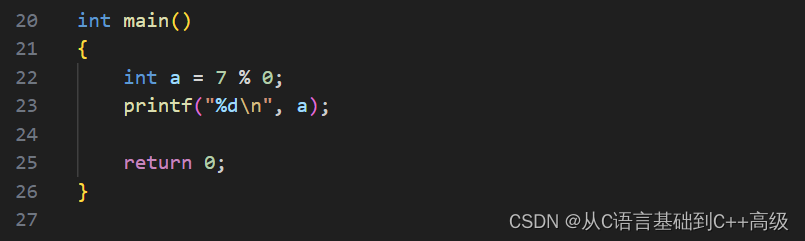
什么意思呢?举个例子,假设有一个 int a = 7%3,%到底算的是什么呢?%算的是除之后的余/数,7%3就是7/3之后的余数。7/3应该商了个2,商了个2之后余的是1,所以这个地方 a 应该是1,我们可以打印一下,即:printf("%d\n", a),如图所示:

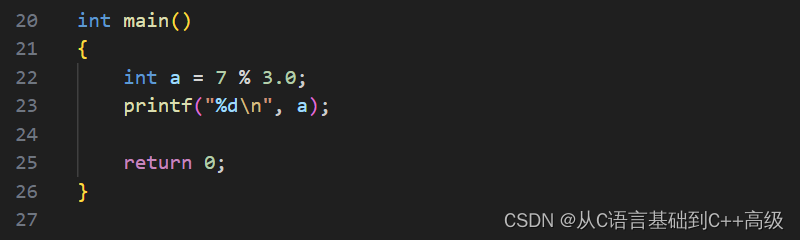
就看的是余数,如果看商的话,应该是个2,现在是余数,所以就明明白白的说出来了,那 % 这个操作符两端必须是整数,有人说7/3.0,这样行不行呢?当我们这样去写的时候,编译器会报错:% 这个取模操作符非法,右操作数包含 double 类型,所以,对于取模操作符来说,它的两端必须都是整数,模小数这个是不行的,如图所示:

当然,取模也不能模0或者模负数,你觉得有意义么?模0是你想干什么,模负数你想干什么,这些动作到底有没有意义呢?如果你觉得有意义,那你就可以测试一下,模0行不行。被零除或对零求模,这都是不行的,如图所示:

30.2 移位操作符之左右移
算数操作符一讲之后,接下来就是移位操作符,而移位操作符其实就2种:一种叫左移,一种是右移。对于移位操作符来说,有向左的两个箭头(<<),这叫左移操作符;向右的两个箭头(>>),叫右移操作符。那这样的操作符它到底有什么用呢?举个例子
假设有一个 int a = 2,然后把 a 向左向左移动1位,即:a << 1,就这么一个移法,就这么一个写法,把 a 这个变量里边值向左移动1位,然后我们把这个结果要放到 b 里边去,接下来用 printf("%d\n", b),如果我们要研究清楚这个代码,我们必须得知道这个向左移动到底是怎么移的,这个代码就是把 a 的二进制位向左移动1位,就是 a 向左移动1位的意思,如图所示:

首先,我们向左移动1位的时候,我们得写出 a 的二进制序列,a 是个什么呢?a 是个整数,2是个整数,放到 a 里边,a 又是个 int 变量,又因为 int 变量占4个 byte,4个 byte 就意味着32个 bit 位,32个 bit 位的话,把2放进去。也就是说,这个32 bit 位的空间放个2的话,它放进去应该是这样的,00000000000000000000000000000010,这就是2的二进制序列
我们把它放到 a 里边去之后,这就是 a 里边的一个值,a 内存里边放的这么一个信息,现在 a 的二进制序列是这样的(因为 a 是32个 bit 位,是个 int,所以我们要写够32个 bit 位),1其实代表的第二位,第二位的权重是2的1次方,2的1地方就是2,那这个地方1其实代表的是2,那后边是0的话,那整个这个数字是个二进制序列,代表的数字其实就是2。然后 a 向左移动1位,就是把 a 的二进制序列拿起来,向左移动了一位,如图所示:

当向左移动一位的时候,左边的0一定丢弃了,因为它溢出去了,当左边的0丢弃,右边少一位,所以会补0,补了0之后,这个结果变成了多少呢?这个1来到第三位了,第三位的权重是2²,2²是4,后边又是0,所以整个这个数字应该变成4,而当向左移动一位之后,放到 b 里边去的话,那 b 应该是4,如图所示:


结果是4,那就说明我们刚刚分析是对的。因此,其实我们总结一句话:左移操作符的移动规则:左边丢弃,右边补0;这就是左移操作符的特点。再来解释一下:移到左边的,移出去的,那就丢弃
右移又是怎么一回事呢?刚刚我们其实讲了左移的是移位,左移2位也是一样的道理,那我们就是左边溢出2位,右边补2个0就可以了。所以,左移它不仅可以移1位;可以移2位;可以移3位。那要是移100位呢?总共也就32个位,非要移100位,这是不是又是在吹毛求疵了,所以我们移的应该是正常的位,不敢移那种异常的位,移个100位,那我们如何移,没法移,所以要正确的思考这个问题
向右移动一位是怎么一个移法呢?箭头向右>>叫向右移动一位,这个时候移动也是把 a 的二进制位向右移动一个一位,a 的二进制向右移动一位,然后再赋给 b,那结果又是什么呢?a 的二进制序列是00000000000000000000000000001010,现在放到 a 里边去,然后向右移动一位,那就是把它的二进制序列拿起来向后移动一位,向右移动一位之后,右边一位肯定是丢了,因为它出范围了,那左边补什么呢?这个时候补的就有讲究了,我们知道:在内存里边,存一个 int 的二进制序列的时候,最高位如果放的是0,表示它是整数;如果最高位放1的话,表示它是负数,就是有符号的整数,如图所示:
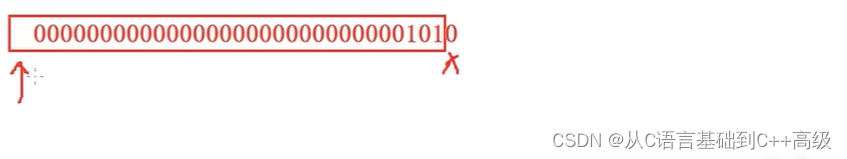
这个时候最左边一位里边存什么,放进去什么其实是非常关键的,所以我们到底最高位左边补什么呢?右边丢弃,它左边补什么呢?这个时候就形成了争论,但其实也没有关系,其实在右移操作符的时候,右移的时候我们其实分为2种,一种叫算数右移,一种叫逻辑右移
那我们首先来学算数右移,算数右移的规则是:右边舍弃,左边补原符号;逻辑右移的规则是:右边舍弃,左边补0(不管是正数还是负数,都要补0),通常采用的都是算数右移,这就是这么一个讲法,对于我们这个数字来说,这个数字是10,10是个正数,正数的话,它最高位本来就是0,现在向右移动一位,如果采用算数右移的话,左边补原来的符号位,左边补的其实就是0;而如果采用逻辑右移的话,不管是正数还是负数,统一补的都是0
因为10是个正数,不管是采用算数右移还是逻辑右移,现在高位都补0,当补0之后结果变成5了,如图所示:


有人就说,刚刚的这个例子,好像还不能测试我们当前到底是算术右移还是逻辑右移,反正这个右移存在2种:一种是算数右移,一种是逻辑右移,那到底是哪一种呢?我们当前编译器采用的哪一种右移的方式呢?这个地方如果你要测试的话,拿正数是测不出来的,因为正数不管是算数右移还是逻辑右移,高位都补0,所以我们换一种写法
那我们拿一个负数来测试一下,假设有一个 int a = -1,那这个-1现在如果我们要让它右移的话,怎么右移呢?首先,它是个负数,负数的-1现在要存到内存里边去,这个时候我们必须要给大家再交代一个知识点:整数的二进制表示形式有3种:原码、反码和补码。原码:直接根据数值写出的二进制序列,就是原码;反码:原码的符号位不变,其他位按位取反,就是反码;补码:反码+1,就是补码,如图所示:

接下来我们来一个一个的举例子:刚刚是个负数,-1现在要放到 a 里边去,我怎么放呢?我首先要写出它的原码,再写出它的反码,再写出它的补码,内存中存的是它的补码。也就是说,-1这个数字要存放到内存中的话,存放的是二进制的补码(对于正数的话,原码=反码=补码)
那这个地方补码怎么算出来的呢?首先,对于-1,它的原码是怎么写的呢?根据这个数值直接写出二进制序列就是原码,这个-1首先它怎么表示呢?我们说它是负数,所以最高位的二进制序列最高位是1,表示它是负数,那我们要写出 a 应该是32个 bit 位才能表示清楚,因为它是个 int,所以是10000000000000000000000000000001,最左边的1表示它是负数,而最后的1的话,表示它数值就是1,所以综合读一下就是-1的意思,只不过这是原码,这是-1的原码,我根据它的数值直接写出来的,后边表示是1,前边表示是负,如果把最左边的1改成0的话,就表示正1了,如图所示:

原码写出来之后,反码怎么写的呢?符号位不变,就是最左边的1不变,其他位按位取反,其他位如果是0,变成1,1变成0。那按位取反之后的结果就是11111111111111111111111111111110,如图所示:

然后得到反码之后,反码+1就是补码,那这个补码怎么算出来的?这个二进制序列如果+1的话,就是最低位+1,所以加完之后的结果全1了,也就是1111111111111111111111111111111,如图所示:

因此,-1在内存中存的时候,其实是存的全1,就是它的补码。所以我们就明白了:我们把 a 向右移动一位,其实就是把全1向右移动1位(全1这样一个二进制序列我们知道,它其实在内存里边放着的),a 里边假设放的是-1,就放了1111111111111111111111111111111这个二进制序列
现在我要把它拿起来,向右移动一位,移一位之后,右边的1肯定丢了,但是左边补什么呢?如果采用的是我们刚刚前边学的算数右移的话,因为原来-1是个负数,所以高位应该是补1的(补原来的符号位),如果采用的是逻辑,那高位应该是补0的,因为逻辑右移不管怎么移,它高位总是补0,如图所示:
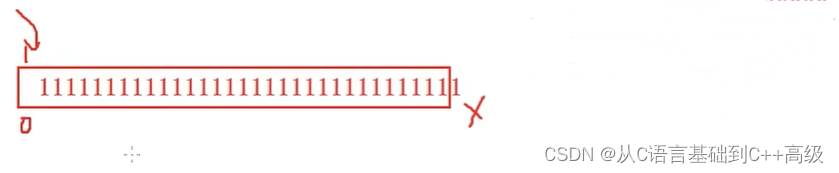
那我们到底是补了1还是补了0呢?我们仔细来看一下就知道了,如果补了1的话,原来右边丢了个1,左边补了个1,还是32个1,那说明右移之后,它的结果没变,还是个-1。但是如果我们补个0的话,它就变成个正的了,而且是个正的、比较大的数字了,因为0表示正数,后边这一堆1是非常大的数字,大概就这么一个情况,所以当向右移动之后,如果发现它还是个-1,当我们看到移位之后,还是个全1的时候,全1我们再反回去得到原码,才是我们真正肉眼看到的那个值,如图所示:


我们发现 b 还是个-1,b 如果是个-1,说明我们当前平台上采用的是算术右移,而如果是逻辑右移的话,那高位就是补了0,那会变成一个比较大的数字。因此:-1在内存中,存的是全1
但是,虽然我们刚刚画的时候,右移好像是把它的二进制序列拿起来,向右移动了一位(或者向左移动了一位),但实际上这个动作会不会改变 a 呢?把 a 向右移动一位,二进制序列往右挪之后,变成了个5,b 变成了5,就是移动之后,我们把这个结果放到 b 里边之后,b 是个5。但 a 是多少?我们可以对比一下,如图所示:


我们发现:a 还是原来的10,b 是5,就是 a 向右移动一位的时候,这个动作只不过是我们为了理解它,我给它拿起来之后向后移动了一位,产生了这么一个结果,但是 a 有没有发生变化呢?没有。只不过这个表达式的结果是 a 向右移动一位之后,产生的那个结果,最后放到 b 里边去了
相当于第43行代码 int b = a+1,这个表达式 a+1的结果11放到 b 里边去了,但 a 变成11了么?没有。一个道理,a 向右移动一位是不会改变 a 的,实这用到的就是一个向左移动的两个箭头实这用到的就是一个向左移动的两个箭头实这用到的就是一个向左移动的两个箭头实这用到的就是一个向左移动的两个箭头,如图所示:

总结:左移:左边丢弃,右边补0;右移分为2种:一种叫算数右移;一种叫逻辑右移。而我们通常采用的都是算术右移
当然,这个移位操作符,再不要把它用的,乱七八糟的,乌烟瘴气的,假设有一个 int a = 10,然后 a 向左移动 -5位赋给 b,即:int b = a << -5,这个时候又来了个负数,向左移动-5位这种写法就永远都不要写出来,移动-5位是什么意思?难道想表达的意思是:a 向右移动5位么?向左移动-5位是向右移动5位的意思么?那为什么不直接写成向右移动5位呢?
这种代码是标准未定义行为,就是说 C 语言都不知道怎么来帮你做这些题了,所以像这种代码写出来其实就是一些废代码、垃圾代码,编译器可能都不知道怎么来处理,如图所示:

30.3 位操作符之& | ^
所谓的位操作符都是些什么呢?位操作符其实有3种,一种是叫按位与(&);一种叫按位或(|);一种叫按位异或(^)。按位与是&这么一个操作符,按位或是一个竖杠,按位异或是一个向上的尖,我们来学一下它们是怎么用的
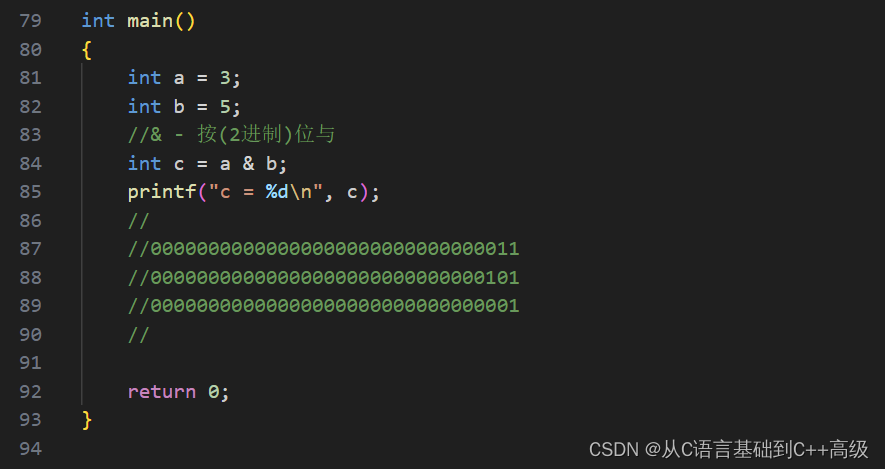
假设有一个 int a = 3,int b = 5,我们给了两个变量(一个 a,一个 b),然后 int c = a & b,这个操作符叫按(二进制)位与,这个与是怎么计算的呢,是想与;这个位是什么位呢,是二进制位。即:按(2进制)位与,所以我们就得写出 a 和 b 的二进制位,a 是3,3的二进制序列是11,但是不够,我们要写够它的32个 bit 位,所以 a 是00000000000000000000000000000011,b 是00000000000000000000000000000101,这就是我们看到的两个二进制序列
现在说 a 和 b 按位与,按位与的意思就是对应的二进制位按位与,对应的二进制位里边只要有0,按位与的结果就是0;对应的二进制位里边两个位都是1,才能够按位与出来一个1。所以前边与的结果肯定都是0了,所以到后边0和1里边只要有个0,按位与的结果就是0;同理1和0又是个0,然后1和1才按位与出来一个1。所以得出来结果就是00000000000000000000000000000001,这个结果它到底是多少呢?其实就是1(对于我们的整数的原反补表示有3种形式:这个算法是针对复数的;对于正整数来说,原码反码补码是相同的,我们写出原码之后,反码补码就写出来了),我们当看到这个数字的时候,它一定是个正数,因为最高位是0,所以它的原反补相同,那这个时候它其实就是个1了,那 c 到底算的是不是个1呢?我们打印来看一下,printf("c = %d\n", c),如图所示:

这就是我们所谓的按位与这个操作符的一个特点,它的一个计算方法,接下来还有一个操作符叫按位或操作符(|),这个位是什么位呢?还是我们刚刚学的二进制位,即:按(2进制)位或,假设有一个 int a = 3,int b = 5,int c = a | b,那它们的计算规则又是怎么计算的呢?所以,首先也得写出 a 和 b 的二进制序列
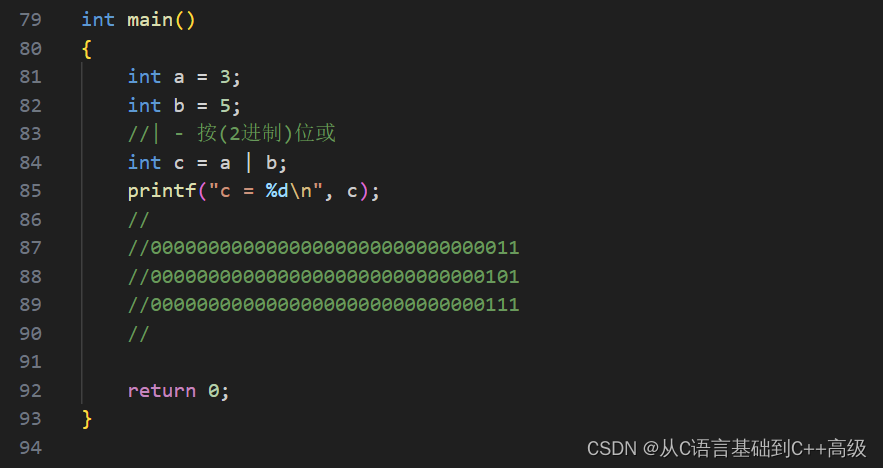
我们已经知道:a 和 b 的二进制序列已经是00000000000000000000000000000011和00000000000000000000000000000101,现在让我们来算,那我可怎么帮它来算出这个结果呢?按位或就是对应的二进制位如果有1,则为1;但是两个同时为0的时候,就为0,所以或的结果就是00000000000000000000000000000111,后边这个时候0和1里边出现了1了, 那或的结果就是1,就有真则为真,后边的1和0又有真了,两个为真的时候,当然也为真了,所以结果就是111,那这个111其实代表的就是7
二进制位里边,最低位这个权重是2的0次方,2的0次方就是1,所以最右边的1代表的就是1;中间的1它是第二位,它的权重是2的1次方,2的1次方就是2;最左边的1是第三位了,它的权重是2的2地方,因为权重最低为是2的0地方开始,然后2²其实就是4,4+2+1=7,那这个结果是不是7呢?我们用 printf("%d\n", c)打印一下,如图所示:

说明什么问题呢?说明我们确实按照刚刚所谓的按位或的方式来算的,而且我们也很好的学会了这个按位或的一个继承的方法,这是 | 这个按位或操作符的一个基本的使用,接下来还有一种写法就是 int c = a ^ b,当我们这样写的时候,这个向上的尖它到底是个什么鬼呢?这个向上的尖它叫按位异或,这个位又是什么位呢?位还是二进制位,即:按(2进制)位异或,那异或又是怎么算的呢?异或计算的特点是对应的二进制位异或,我们这个地方对应的二进制位怎么异或的呢?
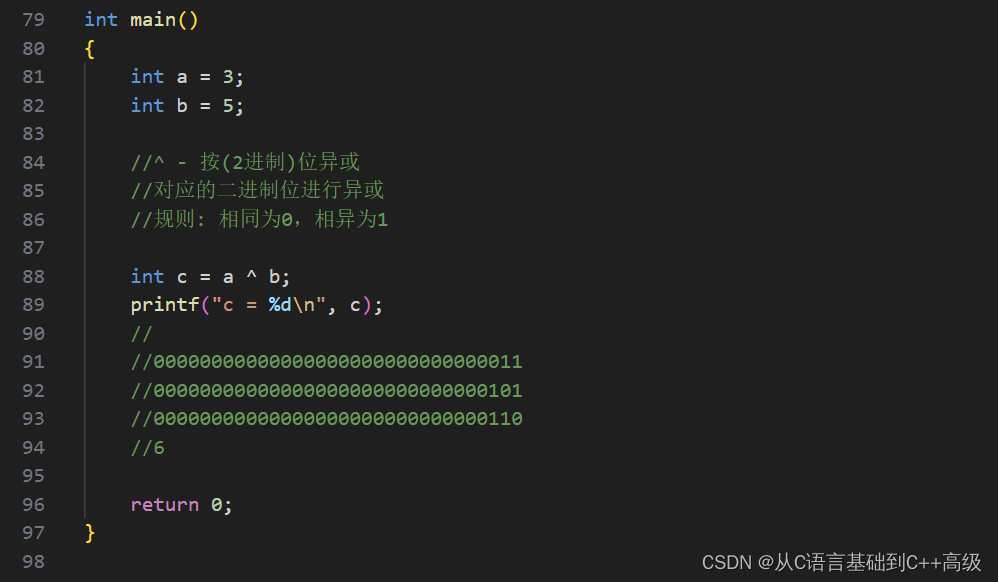
异或的计算规则是:相同为0,相异为1,就是对应的二进制位上,如果出现相同的两个数字,那异或的结果就是0;相异(一个1一个0的话就是相异),那结果就是1,a 和 b 的二进制序列当然是00000000000000000000000000000011和00000000000000000000000000000101这两个数字,异或就是对应的二进制位相同则为0,相异则为1。然后后边的0和1相异,所以为1,然后1和0相异为1,1和1相同为0,所以结果就是0110,0110是6,那 c 到底是不是6呢?我们用 printf("c = %d\n", c)打印一下,如图所示:

说明我们刚刚也算对了,所以在这3个小小的练习里边,我们就学会了三个操作符的一个基本的运算规则,值得注意的是:这三个操作符的操作数必须是整数,大家可以看我们刚刚举例子的时候,都是两个整数在与(或)(异或),能不能说3.0和5.0异或一下,不能,只能是整数。
接下来,对于这3个操作符的用途,我们可以举个例子,交换两个 int 变量的值,不能使用第三个变量,即:a = 3,b = 5,交换之后 a = 5,b = 3
这道题放在我们面前的时候,其实就是交换两个 int 类型变量的值,这个能有多难?假设 int a = 3,int b = 5,a 和 b 就是3和5,现在说把它俩交换一下,绝大部分的人能够想到的方式其实很简单:就是 a 和 b 交换,就相当于我们有一瓶醋,有一瓶酱油,醋和酱油进行交换,那这个时候我们得找一个空瓶,然后借助于那个空瓶把醋和酱油调换一下位置。即:醋倒到酱油瓶里,酱油倒到醋瓶里。所以我们必须有空瓶
现在我们 a 和 b 交换也一样的道理,我们创建一个 int c = 0,这是相当于我们那个空瓶,当 a 和 b 真的要交换的时候,我们得找空瓶:空瓶首先让它放 a 的值,就是把 c 里边先放上 a,即:a 的值放到 c 里边去,a 的值就空了,a 的值已经放到 c 里边去就备份起来了;然后 a 里边就可以放 b 的值了,而 b 的值一旦放到 a 里边去之后,相当于把 b 已经放到 a 里边去了,相当于交换的效果达到一部分了,然后 b 里边已经放了 a 的值了,b 里边要放原来 a 的值(a 的值刚刚备份到 c 里边去了),即 c 赋给 b
然后我们交换前打印一下,交换后打印一下,printf("a = %d b = %d\n", a, b),printf("a = %d b = %d\n", a, b),如图所示:


我们会发现:3和5变成了5和3,交换了没有?交换了,确实达到交换的效果了。但是,这种写法满足不满足题目的要求呢?不满足,题目的要求是说不能使用第三个变量。也就是说,不能使用 c,c 已经超过我们 a 和 b 两个变量了,我们只有两个变量,现在创建一个 c 不是有第三个变量了么?有人就说:不能使用 c,那我们就创建一个 d,d 和 c 的道理是一样的
多创建出来变量,那就不满足题目的要求了,所以现在问题就出现在 c 上,多创建了一个变量,已经不满足题目要求了,但是这个代码能不能解决问题呢?确实解决问题了,但是它不是我们题目要求的这种写法,那该怎么办呢?这个时候我们得想:不能使用第三个变量,我们该怎么办呢?不能使用第三个变量的时候,这个时候我们要交换两个变量该怎么算呢?
方法一:a = a+b,a+b 它能有一个合,这个合我们放到 a 里边去,a 和 b 加起来的合放到 a 里边去,所以 a 里边现在放的就是合了
合如果减去个 b 呢?这个 a 里边放的是合,即 a 和 b 的合,合减去一个 b,就能翻译出来原来的 a,就能得到原来的 a,即:合减去 b,就能得到原来的 a,原来的 a 想去哪里呢?想去 b 里边去,所以我们就放到 b 里边去,即:b = a-b
然后 b 里边已经得到 a 了,然后合再减去刚刚的 b,b 里边放的可是原来的 a,合减去原来的 a,得到的就是原来的 b,原来的 b 想去哪里呢?想去 a 里边,即:a = a-b,如图所示:

这也是一种比较常见的实现方法,但是当我们写出这样一种算法思想的时候,也想出了不同的解法,确实也没有用到第三个变量,只用了 a 和 b。但是,这种方法它其实有缺陷的,有什么缺陷呢?原因如下:a 和 b 都是 int,int 变量一定有自己的上限,它里边能存放的数字有它最大的值,而如果我们给 a 里边放了一个超大的数字,给 b 里边放了一个超大的数字,但是都没有超出 a 和 b 这样 int 能表示的最大值,a 和 b 里边放进去的值是合法的,但是一旦这两个数字加起来,加起来的那个合就超出了 int 能表示的最大值,数学上可算,但是 int 里边存不下
当我们把那个算出来能够超出 int 能表示最大值的那个值,放到 a 里边去的时候,那肯定放不下了,一旦放不下,就是二进制位丢掉了。丢掉了之后,放到 a 里边这个值还是合么?就不是了。而如果不是合,然后减去 b,还能翻译出来原来的 a 么?就翻译不出来了,所以当 a 和 b 太大的时候,就会产生溢出,而溢出就会导致 a 里边就不再是合,然后想翻译出来 a 和 b 的值,就翻译不出来了。因此,这种算法思想是存在问题的:数值太大会溢出,所以这种算法它只是针对部分数据是没问题的,小的数据是没问题的,但是,数据多了,就不行了
所以这个时候,我们就来学第三种写法,刚刚学到了异或这个操作符,我们就把异或用一下,a = a ^ b,b = a ^ b,a = a ^ b,如图所示:

我们发现:确实也达到了交换的效果,但这种算法它又是如何计算的呢?异或到底是怎么做的呢?这个东西其实不难分析:现在给出了 a 和 b 两个变量,现在我们用异或操作符,我们要写出它的二进制序列的,因为其实二进制序列高位的0,其实也没什么计算的作用,所以我们写的时候就写有效位就行了,为了能够简化过程,所以尽量不用写那么复杂
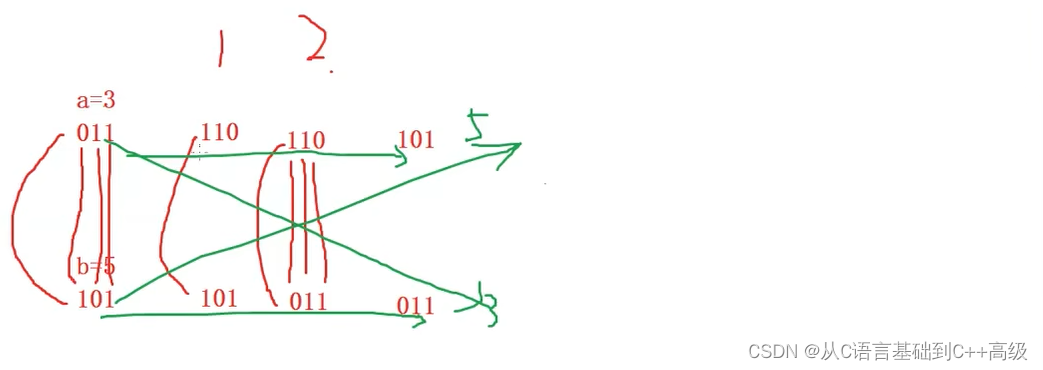
最开始 a = 3,b = 5,a 的二进制序列就是011,b 的二进制序列就是101,这是我们最开始的一个状态,现在 a 和 b 异或,即:011和101这两个二进制序列要异或一下,异或产生的结果放到 a 里边去,a 要发生变化了。a 和 b 异或,放到 a 里边去,异或的话对应的二进制位,最左边的0和1异或的结果是1(相异为1),然后中间的1和0相异为1,然后1和1相同为0。所以结果应该是110,110最后放到 a 里边去了,所以 a 的值就变成了110,b 的值没变,即:还是101,这是我们第一步完了之后的结果
第一步完了之后,我们说第二步,第二步又是 a 和 b 异或,而此时的 a 和 b 是这110和101两个二进制序列,它俩在进行异或的时候,最左边相同的二进制位为0,然后中间相异为1,然后相异为1,而异或的结果这个时候算出的就是011,011放到 b 里边去了,所以这一次完了之后,b 变成了011,a 应该是没变的,即:a 还是110,这一次是我们的第二步
第二步完了之后,我们马上要进行第三步了,第三步的时候,又是 a 和 b 异或,就是110和011这两个数字异或,对应的二进制位异或,结果是101,101放到 a 里边去了,所以 a 变成了101,b 还是我们的011
当我们看到这样一个结果的时候,我们的三步都已经算完了,算完了之后我们再来看一下:a 变成了5,b 变成了3。这就达到交换的效果了,这就是我们整个计算的一个过程,如图所示:
当我们看到这里的时候,我们确实把它交换了,而且这个地方有没有创建第三个变量呢?没有。那这个地方会不会存在第二种方法里边溢出的问题呢,也不会。为什么不会存在溢出?因为异或的时候,相同为0相异为1,不会产生进位,就不会溢出(没有进位,就没有溢出)。所以这个算法的过程种,再大的数字,它也不会溢出
这就是我们这种最终的一个解法,异或操作符非常神奇,a 和 b 异或之后,放到 a 里边去,我们可以把这个 a 里边得到的结果,也就是把 a 和 b 异或之后的结果想象成一个密码,这个密码密码如果和 b 异或,就能翻译出来原来的 a,原来的 a 翻译出来之后是011,其实就放到 b 里边去了,b 就是变成了011,然后它还是密码,这个密码如果跟我们原来的 a 进行异或,就能翻译出来原来的 b,原来的 b 放到 a 里边去了,异或传来的结果是非常有趣的
a 和 b 异或产生的结果,再次和 b 异或,就能翻译出来旧的 a,即:a ^ b ^ b 其实就能翻译出来 a 的值,为什么呢?其实还有一些细节,举个例子,假设有一个 int = 3,a ^ a 结果是多少?结果是0,那其实就是011 ^ 011,相同为0,对应的二进制位肯定相同,因为 a 和 a 相同,异或的结果就是000,所以我们可以得出一个结论:任何两个相同的数字异或一定是0,然后再来看:0 ^ a 结果是多少呢?结果是3,0的二进制序列就是000,a 就是011,异或的结果就是011,所以我们会发现:算出的结果还是这个 a。所以0和 a 异或的结果一定是 a,然后 a 和 a 异或的结果就是0。有了这样的理论基础,两个相同数字异或是0,0和任何一个数字异或还是它本身
a 和 b 异或产生的结果放到 a 里边,如果再次和 b 异或,就相当于写出的是 a ^ b ^ c,a ^ b 异或的结果就是 a,然后 b ^ b 异或结果是0,0和 a 异或结果就是 a,所以把 a 放到 b 里边去了,所以 & | ^ 这些操作符,所有它的应用场景首先我们必须先要理解这个操作符怎么用,然后掌握它运算的特点
练习题:编写代码实现:求一个整数存储在内存中的二进制中1的个数(按位与1)
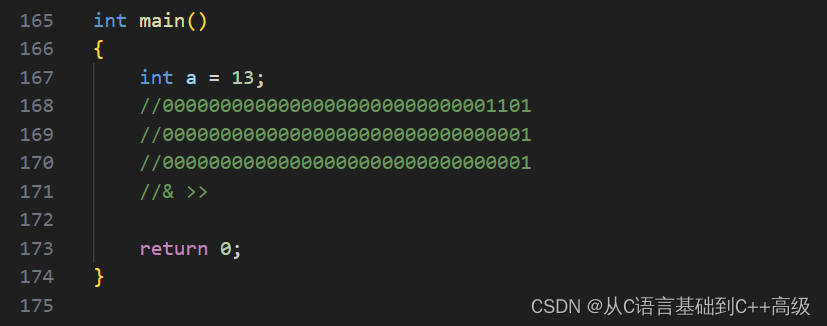
这个算法该怎么去算呢?一个整数存到内存中的二进制,其实就是补码,即:补码中有多少个1,其实很简单:假设有一个 int a = 13,13的二级制序列应该是00000000000000000000000000001101,现在我们看一下这个13里边多少个1,那我们怎么做呢?其实很简单,你要用我们这些操作符,现在我们想要知道最右边的一位是不是1,我们只要给00000000000000000000000000001101这个二进制序列按位与上00000000000000000000000000000001这么一个数字就可以了,这个数字其实就是1,我们给它按位与上个1,如果得到的结果,前面的因为我们这给的这一串都是0,所以你前边不管是什么,你按位与的结果都是0,但是最低位给的是1,当我们与1的时候,你是1,按位与1的结果才是1,如果本来是0,你按位与1的结果还是0
如果最低为是1,我给你按位与上一个1上去之后,得到一个1,就说明最低位是1;而如果最低位本来是0,我给你按位与个1之后,你得到的结果就是0,所以 a 这一位按位与上1之后,得到的结果是多少,就说明它的二进制最低位就是多少。我们给1,按位与的结果就是1,这个数字整体也是个1。有人说我们只知道最低位,那左边的一位怎么办?很简单,这个二进制序列如果最低位已经判断过的话,我们让它向右移动一位,最低位就等于丢了,然后倒数第二位来到最低位了;再向右移动一位,倒数第三位也来到最低位了;再向右移动一位,倒数第四位也来到最低位了
也就是说,我们让 a 的二进制序列在不断的向右移动一位,之后产生的结果按位与1,向右移动1位之后,产生的结果按位与1;或者说向右移动0位;向右移动1位;向右移动2位,向右移动3位,向右移动4位,那这个时候每一次算出的结果是多少,就说明它的第多少位就是多少,比如00000000000000000000000000001101这个二进制序列向右移动3位。向右移动0位1在最右边;向右移动1位,0来到最低位了;向右移动2位的时候,倒数第三位的1来到最低位了;向右移动3位的时候,倒数第四位的1来到最低位了,所以当我们移动3位的时候,第四位来到最低位的话按位与1,就能够求出第四位是多少。因此,最高位想来到最低位的话,只要向右移动31位就可以了,所以我们就可以通过循环的方式就可以让它所有的位想来到最低位就就来到最低位,然后按位与1的结果是多少,那说明最低位就是多少,我们现在要统计的什么?我们要统计它二进制序列里边有多少个1,我们发现只要得到的结果是1,那说明二进制位里边就有一个位是1,然后我们遇到一个1,count++就可以了,就能统计出来它的所有的位,这个时候我们用到了两个操作符,一个叫按位与(&),一个叫右移操作符(>>),如图所示:
再来一个例子,假设有一个 int a = 13,13的二进制序列应该是00001101这个二进制序列,如果我们要写32位的话,前边还要补24个0,即:00000000000000000000000000001101,13的二进制序列如果我们写出来之后,我们突然有个想法:把倒数第四位的1置成0,或者说把倒数第二位置成1,我就有这些想法,我想让你把某一位置成0或者1
假设我们把倒数第五位中的0置成1,就只改这一位,其他位不动,其他位还是原来的位,把倒数第五位改成1,其实很简单:我们让倒数第五位是1的话,我们只给它或上个1上去,它就变成1了,其他位或0。右边是1的,我们或0上去,它还是1;原来是0的,或0上去,还是0。所以我们或上00000000000000000000000000010000这么一个数字,只要我给它或上这样一个数字上去,或1,或者或上这个数字上去的时候,那这个数字最终就会变成00000000000000000000000000011101,这个数字相当于00000000000000000000000000001101来的时候,倒数第五位就变成了1,其他位不变
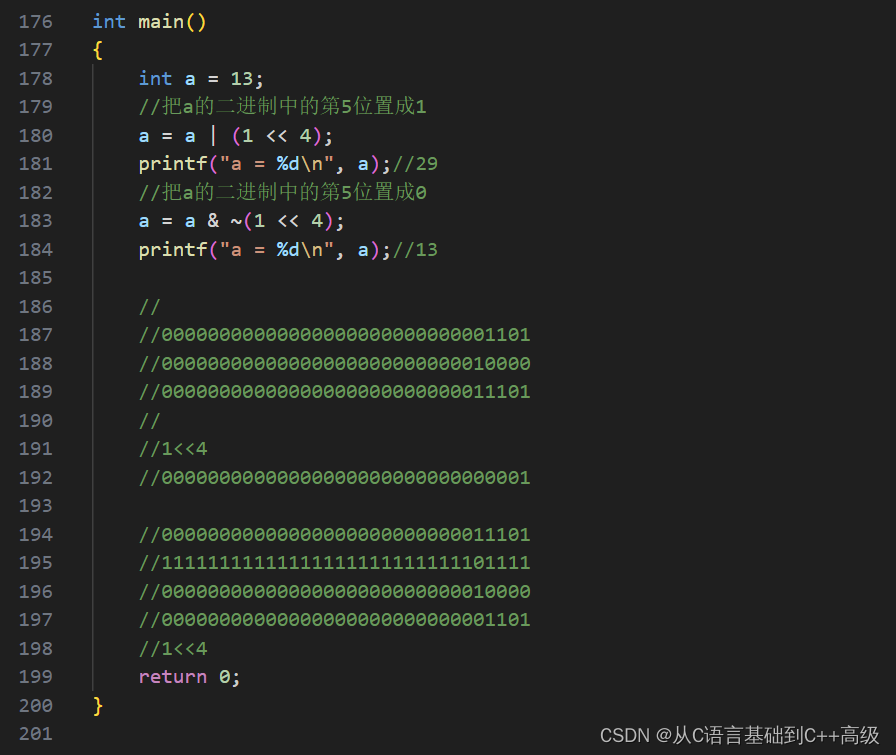
那或这一位我们知道了,但是这个数字怎么产生呢?这个数字其实要产生也很简单,其实就是把1向左移动上4位,1的二进制序列本来是00000000000000000000000000000001这样二进制序列,现在我让它左移一位在倒数第二位,左移两位在倒数第三位,左移三位在倒数第四位,左移四位就在倒数第五位,就得到00000000000000000000000000010000这个数字了,所以把1向左移动4位之后,给它按位或上去,就会变成00000000000000000000000000011101这个二进制序列,不信,我们来测试一下:a = a |(1<<4),应该是29,我们用 printf("a = %d\n", a)来打印一下,变成29的话,相当于把倒数第五位0改成1了,我们来测试一下,看是不是29,如图所示:


我们发现:改了没有?改了。当我们这改成1之后呢?我是你给我改回来,那这个地方该如何改呢?就是说倒数第五位已经改成1了,然后改成0,那改怎么改呢?现在我们已经掌握的操作符还是不够的,需要一个按位取反~操作符
我们刚刚说把 a 的二进制中的第5位置成1,而当我们把它置成1之后,现在把 a 的二进制中的第5位置成0(再改回来),这是我们现在想做的事情,刚刚我们好不容易把第5位或上一个1,所以第5位或上1之后,就会变成1,其他位或0就能其他位不变。所以我们怎么产生00000000000000000000000000010000这个二进制序列呢?1向左移动4位,然后按位或上 a,或到 a 上去,然后再赋给 a,而现在我们又把第5位这个1改成0,我们得到之后二进制序列应该是00000000000000000000000000011101
现在我们只是想把第5位置成0,其他位不变,那这一位怎么置成0呢?我们这个时候想让第4位为0的话,我们只要给第5位按位与上一个0,与0的时候,第5位就变成0了,就可以让它变成0,其他位要保持不变,其他的1我们如果还给它与0的话,与0就让它变成0了,所以我们给它与1,即:11111111111111111111111111101111,现在我们只是给第5位与上个0,其他位我们全部给与1,所以,我们只会改变第5位,其他位依然保持不变(第4位是个1,再与个1,还是1;第二位本来就是0,与个1,还是个0),所以我们与上11111111111111111111111111101111这么个数字就可以了,而这个数字怎么产生呢?这个数字要产生还是比较麻烦的,你要算,其实挺麻烦的,但是我们会发现:非常简单的一个东西是什么呢?就是说我们能得到00000000000000000000000000010000这样一个数字,我们给11111111111111111111111111101111这个数字按位取反,把它里边的0变成1;1变成0,就得到它了,而00000000000000000000000000010000这个数字又怎么得到呢?它就是1向左移动4位。所以其实就是:把1向左移动4位得到00000000000000000000000000010000,然后按位取反得到11111111111111111111111111101111这个数字,再给00000000000000000000000000011101这个数字就按位与上去可以了
所以,现在如果我们想把它改回来,其实很简单,我们有 a = a & ~(1 << 4),把1向左移动4位,就得到00000000000000000000000000010000这个数字,它按位取反得到11111111111111111111111111101111这个数字,再给 a 按位与上去得到这个结果,得到这个结果其实就是00000000000000000000000000001101,第5位改成0,1和0一与的结果就是0,然后其他位还能保持原来的位置,第5位就改成0了,那这个时候改成0的时候,又恢复到我们原来最开始的13,这个时候我们就把波浪号~这个操作符也用起来。因此,当我们在某些场景底下,我们想把它的二进制位全部都取反一下,我们就可以用波浪号~,如图所示:

30.4 赋值操作符之直接赋值与符合赋值
赋值操作符其实分为两类:一类就是直接一个等号=,叫赋值操作符;还有+=,-=,*=,/=,%=,<<=,>>=,这都是操作符,都叫赋值操作符,而 = 是直接赋值,而后边的叫复合赋值,其实赋值操作符是一个很棒的操作符,它可以让你得到一个你之前不满意的值,也就是你可以给自己重新赋值
比如说,举个例子,我体重150,我的体重怎么能150呢?我要改成130,这个地方的等号就是赋值操作符,即:当我们有一个变量的时候,你对它的值不满意,改它的时候,那这个时候就是赋值操作符;我们毕业之后我们说我们的薪资一天80,不满意,你把它改成200就完事了,salary =100,这个等号就是赋值操作符,如图所示:

赋值操作符除了这种等号的写法之后,还有这种连等的方式,比如 int a = 10,int x = 0,int y = 20,然后 a = x = y+1,这种连续仿赋值也是支持的,这种连续赋值怎么赋值的呢?它从右向左,y+1的值先赋给 x,x 的值再赋给 a,就这么一个赋值的方式 ,最终我们会发现:这个里边 x 和 a 的值都是 y+1的值,这种叫连续赋值。但是我们认为连续赋值这种代码其实是不够好的,这种代码理解起来比较麻烦一些,如图所示:

那我们如果不想用这种写法,该怎么办呢?我可以把它拆开写:y+1先赋给 x,写成一句话;然后 x 再赋给 a,写成两句话,这种写法其实就比较简洁大方了,因为你想观察它的时候其实很容易观察,比如 y+1赋给 x,这个 x 是怎么变化的?变成什么了?观察。然后 x 再赋给 a,a 又是怎么变化的?观察。每一个细节都能观察到,而上面一句代码的时候,一个 F10,这句话就彻底跳过去了,a 是怎么变的,x 是怎么变的,这个过程是没有观察到的,一瞬间就都过去了,所以这个连续赋值的方式,虽然语法支持,但是我们不建议这样去写,能拆开我们就拆开去写,这样更好一些,如图所示:

除了刚刚上面的这种赋值之外,我们还有复合赋值,复合赋值就是 += -= *= /= %= <<= >>= &= |= ^=,这都是可以复合赋值的,举个例子,我们对变量不满意的时候,我们随便改,这个是肯定可以的,假设有一个 int a = 10,这个时候我觉得 a 不是等于10,我想让 a 变成100,即:a = 100,那这种没有任何问题。还有一种赋值方式就是 a 如果你不是等于100,而是给它加上100,即:a = a+100,这种也在改变 a,把 a 加上100之后再赋给 a,给 a 加了个100,这种写法就可以简化一下,即:a +=100,第一种写法和第二种写法是完全等价的两种写法,第199行的+-就是我们所谓的复合赋值符
还有一种写法就是 a 向右移动3位之后赋给 a,即:a = a >> 3,这个时候就可以写成 a >>= 3,相同的道理,其他的都是复合赋值符,都可以这样去用,只要符合我们刚刚这种写法的一个逻辑,如果我们要讲一个注意的地方的话,其实就是:一个等号才叫赋值,两个等号叫判断相等,这是 C 语言里边的一个特点,如图所示:
30.5 单目操作符(重点)
单目操作符都有哪些呢?! - + & sizeof ~ -- ++ * (类型),这些操作符都叫单目操作符,我们来一个一个的再来解释

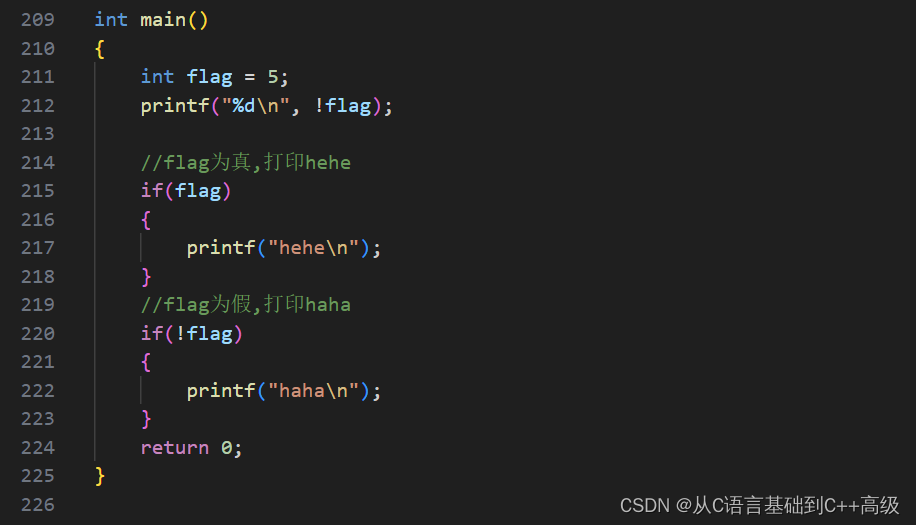
首先我们来看,第一个叫感叹号!,感叹号叫逻辑反操作,逻辑反操作是什么意思呢?假设有一个 int flag = 5,然后 flag 如果为真,我要做一件事情,即:比如说:flag 如果为真的话,我们就打印一个 hehe,即:if(flag){printf("hehe\n")},flag 里边现在放的5,5为非0,为真,所以第214行代码就能打印 hehe
而如果我们现在假设我们这说:flag 如果为假,我们要打印什么的话,那我们怎么写呢?我们应该这样写:if(!flag){},flag 为假就是 !flag,如果 flag 为0的时候,!flag,!就是逻辑反,取反,就是如果你是0,就是假。假的反面(!叫逻辑取反),假变成真,!flag 就是为真,这个时候我们可以打印 haha,这样去写的时候,如果 flag = 5,会不会打印 haha 呢?不会
flag 为5的时候,为真,然后 !flag 就是真变成假,这为假的时候,不打印 hehe,所以 flag 为假的时候,才打印 haha,第217行代码这种写法一般我们表示的是 flag 为真,我们要做什么事情,我们一般是这样的一种写法,这种风格的方式来写,有一个变量如果为假的时候,我们要做什么事情的时候,就是 if(!flag),因为 flag 为假的时候,!flag 就为真了,所以能进到 if 语句里边做事情,所以,感叹号!可以让假变成真,真变成假。因此,flag 如果为真的话,!flag 就为假了,如图所示:

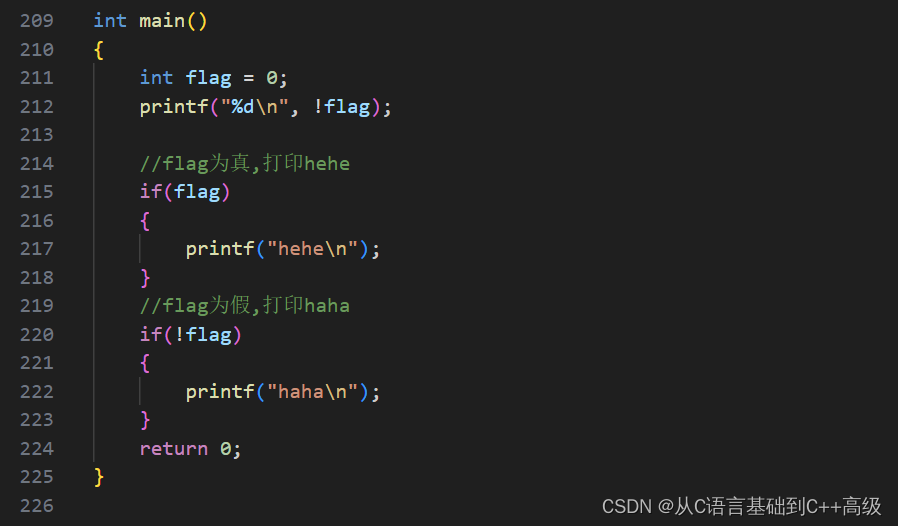
而如果这个 flag 如果我们给上个0,0为假,!flag 就是把假变成真,那第212行代码真用什么表示的呢?这只能给一个值:我们最终给的是1来表示真,即,当把假变成真的时候,这个表达式结果我们规定它是1,如图所示:

这就是感叹号!这个操作符的一个基本作用,感叹号!这个操作符左边只有一个操作数,所以它就是我们所谓的单目操作符,单目操作符是只有一个操作数的操作
30.5.1 负值
-是个负值,正负的意思,举个例子,假设有一个 int a = 10,然后 a = -a,那这个时候 a 就变成了-10了,我们可以用 printf("%d\n", a)打印出来看一下,如图所示:


为什么呢?因为负号-也是个操作符,-a 让 a 变成负的,当然还有一种写法,就是 a = +a,a = +a 这种写法其实这个正号+是没有什么用的,所以经常省略掉

30.5.2 sizeof
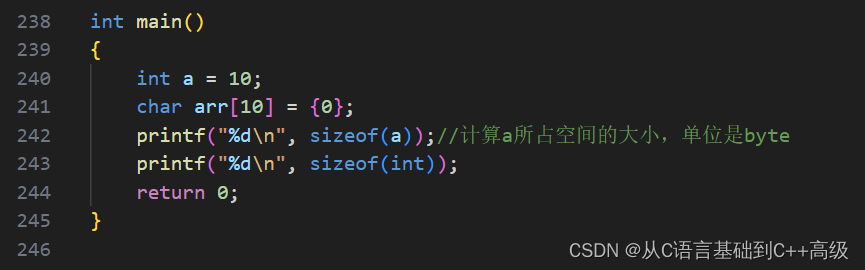
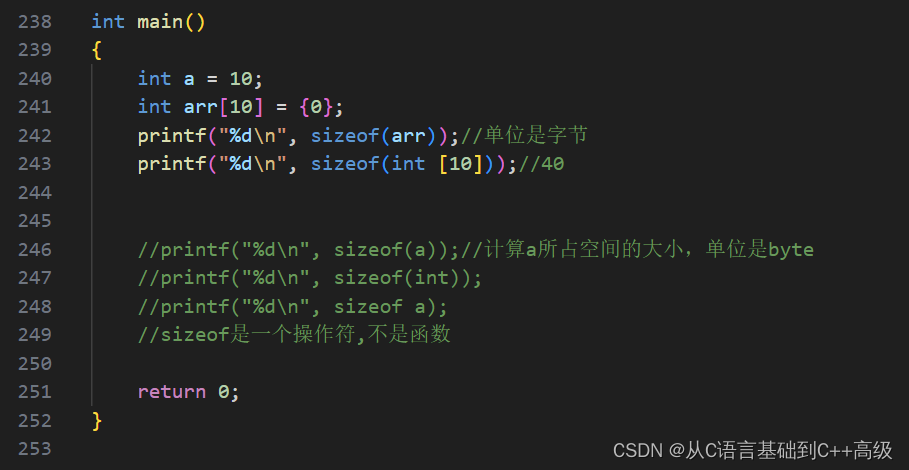
sizeof 这个操作符,其实是来计算操作数的类型长度的,计算和统计类型的长度,举个例子,到目前为止,我们现在学了这么些东西:我们如何创建一个变量,写个 int a = 10,创建一个变量,我们还可以创建一个数组,10个元素,全部是0,char arr[10] = {0}。然后 a 是 int 类型的,它占了多少个 byte 的空间呢?这个时候我们可以用 sizeof 来丈量:printf("%d\n", sizeof(a))就可以计算 a 所占空间的大小,单位是 byte,这里的 sizeof,其实就在计算 a 的大小,a 所占空间的大小
a 我们知道:向内存申请空间,它是个 int 类型,所以申请4个 byte,所以第242行代码应该就是4,如图所示:


这就是 sizeof 的特点,sizeof 计算方法,当然 sizeof 除了这种写法之外,还有没有其他的写法呢,sizeof 在计算 a 的时候,提供 a 的类型也行,a 我们知道它是 int 类型的,所以 a 换成 int 也是一样的效果,即:printf("%d\n", sizeof(int)),这计算的也是 int 类型的大小,int 所创建 a 的大小,如图所示:

所以,sizeof 我们就清楚了:就是计算 xxx 的大小,我们可以放变量,也可以放类型。当然,我们再写另外一种特殊的写法,我们也可以写成 printf("%d\n", sizeof a),把里边的圆括号去掉,即:sizeof 后边不写圆括号,直接写个 sizeof a,如图所示:

奥萨蒂
那我们把这个 int 后面的两个括号省略掉行不行?这个时候就不行了,这是语法不支持的,但我们 a 两端能够省略的话,说明其实 a 就不是函数了。因此,sizeof 用的是时候,对于求变量,两端的括号可以省略;但是求类型的时候,两端的括号不能省略。如图所示:


通常我们在使用的时候,它两端的这个括号我们都不会省略,我们只是讲一下这种语法是支持的
sizeof 当然除了这些功能之外,它还有一些其他的功能,刚刚我们说的是计算一个变量的大小,那它能不能计算一个数组的大小呢?当然也是可以的
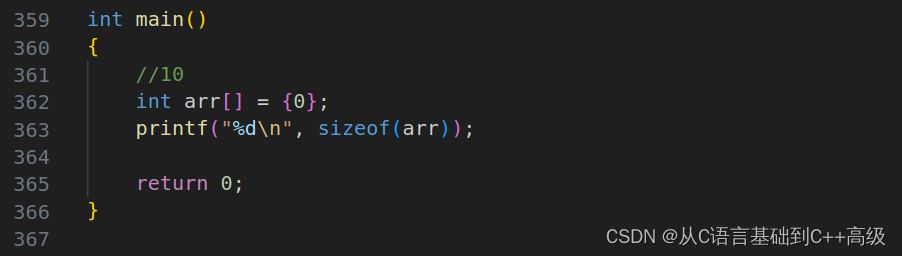
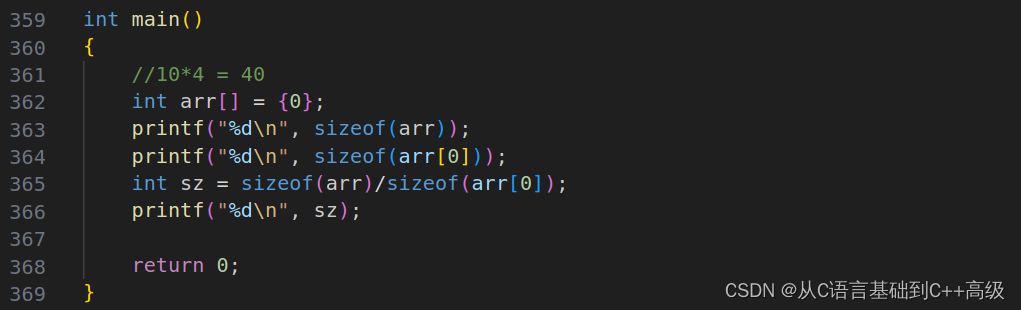
假设写上个 arr[10],这个数组我们暂时全放成0,这是10个元素,每个元素是一个 int,每个元素都是 int,那它总大小是多大?那我们就写一下 sizeof(arr),然后打印一下。值得注意的是:这个数组是用名字来表达的,不是 arr[10],这个数组不叫 arr[10],这个数组叫 arr。所以,当我们写的时候,我们就写 sizeof(arr)
那这个地方结果是多少呢?结果是40,为什么是40呢?因为我们是10个元素,每个元素是1个 int,一个 int 是4个字节,使用乘起来就是40个字节。所以第363行代码中 sizeof(arr) 计算的是数组的总大小,单位是字节。

假设再写一个 sizeof(arr[0]),arr[0]这是数组的第一个元素,那我们 sizeof 算出它的第一个元素大小又是多少呢?第一个元素大小是4,因为每个元素都是 int,它的第一个元素当然也是 int,如图所示:
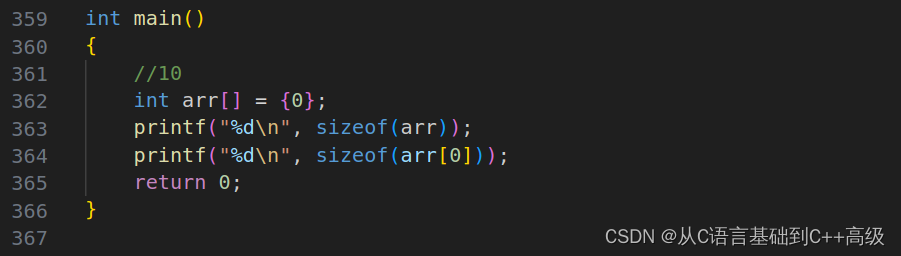

当我们这个地方要求这个数组元素个数的时候,是不是就可以这样写了?int sz = sizeof(arr) / sizeof(arr[0]),sizeof(arr)这是总大小,sizeof(arr[0]) 第一个元素大小,所以得到的就是我们的元素个数,我们打印出来结果是多少?是10!我们这个数组就是10个元素,所以 C 语言是如何计算数组元素个数?答案就是 int sz = sizeof(arr) / sizeof(arr[0]) ,如图所示:

sizeof a 的时候,计算一个变量大小的时候,可以把两端的圆括号省略掉,那我们能不能把 sizeof int,这个 int 两端的括号也省略掉呢?抱歉,这样就不行了,这是语法要求,如图所示:


所以 sizeof 计算变量大小的时候,对于变量名计算大小的时候,它是可以省略掉两端括号的,但是第246行代码不行,我们在看某些书的时候,它有这种写法。既然 sizeof 可以这样写,就证明 sizeof 是一个操作符,不是函数,如果 sizeof 是函数的话,后边这个括号是不能省略掉的。但是我们发现:sizeof 可以省略掉,所以就证明 sizeof 只是一个操作符而已,它不是函数
当然,除了 sizeof 去计算我们这种变量的大小,或者类型的大小之外,sizeof 也可以计算数组的大小,举个例子:printf("%d\n", sizeof(arr)),我们能不能计算一下这个数组大小呢?这个时候算的结果是多少呢?我们这个数组是10个元素,每个元素是 char 类型的,1个 char 是一个 byte,那10个元素就是10个 byte,如图所示:


当然,有人说10是不是有10个元素,所以答案才是10?不是。如果我们把第241行代码中的 char 换成 int,int 的话,这个数组的每个元素变成 int 类型了,一个 int 是4个 byte,10个 int 就是40个 byte,所以第242行代码应该是40,如图所示:


因此,sizeof 也可以计算一个数组大小,单位是 byte,有人就说 sizeof(arr)可以计算数组大小的话,那我们刚刚算一个变量大小的时候,sizeof(a)也可以有 sizeof(int),那请问:对于这个数组大小的时候,也能不能传它的类型呢?可以。对于 arr,它是数组名,那它的类型是什么呢?除了数组名,剩下的就是类型,即:int [10]
当我们这写上一个东西,sizeof(int [10])的时候,计算的大小是多少呢?依然是我们的40,如图所示:

数组有没有类型?有。int [10]就是这个 arr 的类型,即:int [10]是数组的类型,而不是单单的 int,我们可以写 sizeof(arr),也可以写 sizeof(int [10]),但是我们通常都是这样写的,计算一个数组大小的时候,因此,sizeof 它可以计算所占内存空间的大小
我们再来一个小小的题目,假设有一个 short s = 5,然后 int a = 10,接下来打印 printf("%d\n", sizeof(s = a+2))和 printf("%d\n", s),结果是2和5,如图所示:
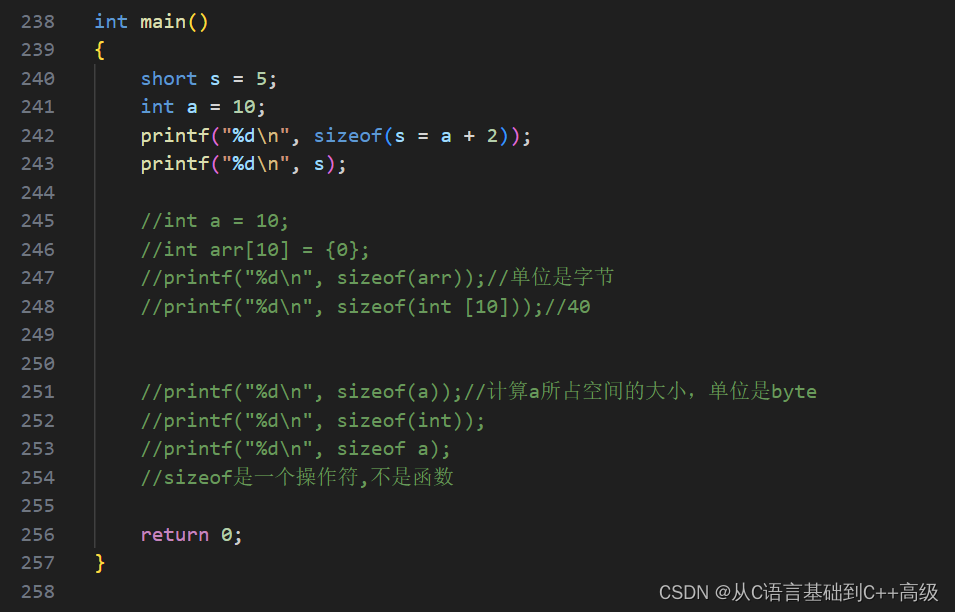
那这个地方我们就要想明白为什么是2和5呢?我们知道:short 是一定占2个 byte 的,我们放5进去,但是 s 只占2个 byte,是个短整型。a 是个 int 类型的,它占4个 byte,然后接下来 a+2,a 是个10,10+2就是12,12要放到 s 里边去,有人就说 s 就应该变成12,那 sizeof 计算的时候,应该计算的 s 所占空间的大小,不管结果有没有赋到 s 里边去
但是 sizeof 算大小的时候,因为 a+2的结果一定是放到 s 里边去了,所以 s = a+2这个表达式 s 说了算,s 的空间是多大,那这个 sizeof 算的就是多大。而 s 在这个计算的过程中,会因为你放了一个 int 类型的值,s 空间就变大么?不会。s 的两个 byte 它是提前就开辟好的,所以我们算的出 s 所占空间的大小是2个 byte。a 再大,是个 int,没关系,放到这里就得截断。一个大的变量,放到小的一个空间里边去的时候,放不下就得截断,把有些位就去掉,保留有些位就行了。因此,最终这个变量所占空间大小还是 s 说了算,就2个 byte
结果这个地方,在打印 s 的时候,s 是多少呢?s 还是5,为什么是5呢?好像10+2产生的12,好像并没有放到 s 里边去,而一旦放到 s 里边去的话,不就改成12了么?怎么 s 还是5呢?因为在 sizeof 括号中放的表达式是不参与运算的,为什么不参与运算呢?我们之前就给大家讲过:我们写的一个 test.c 这样的文件,而这个文件其实最终运行的应该是一个 test.exe 这样的文件,我们写出的这个 test.c 这样的 .c 文件,最后可能编译出来一个 test.exe 这样的文件运行起来
那这个 .c 文件被称为源文件,而这个 exe 文件被称为可执行程序,一个源文件变成一个可执行程序,它要经过什么样的步骤呢?首先是编译,然后是链接,然后这个可执行程序产生之后才能运行,而 s=a+2这样的表达式如果真的要运行,在什么阶段运行呢?它是在运行期间才能运行的,但是,sizeof 去计算 s 大小的时候,sizeof(s=a+2)的时候,在编译期间去计算的。也就是说,如果左边是个 sizeof 的话,s=a+2这个表达式其实并没有计算,而是直接在判断这个表达式的时候,这个表达式结果 s 说了算,所以 sizeof 就把 s 所占空间的大小中的2,就已经计算好了,那计算好了之后,这个表达式就已经处理完了,这个代码都已经处理完了,所以当我们真正最终跑到运行期间的时候,第242行代码 s=a+2这个代码就没有了,就相当于只有个2。打印2,是运行期间要去做的事情,s=a+2这个表达式已经处理过了,在编译期间就处理过了,所以在运行期间的时候,s=a+2这个表达式压根就没有计算,所以 s 的值没有发生变化,而在编译期间只是根据这个表达式说:a+2的结果放到 s 里边去了,然后 s 说了算,s 所占空间的大小是2,所以 sizeof 计算的结果是2,而并没有真的把 a+2的结果放到 s 里边去
因此,正因为我们处理 sizeof 是在编译期间处理的,所以它里边放的这种表达式是不会运算的,所以 sizeof 括号中的表达式是不参与运算的。当然,第一个答案也不会整型提升,因为 a+2的结果放到 s 里边去连算都没算,压根就没去算。因此,sizeof 是可以用来计算变量或者类型所占内存大小的操作符,如图所示:
30.5.3 ~
波浪号~ 是什么呢?这个波浪号~叫对一个数的二进制按位取反,举个例子,假设有一个 int a = -1,而我们知道:-1在内存里边,存的是补码,-1我们的原码应该是怎么写的?10000000000000000000000000000001,这是-1的二进制序列,这是它的原码
内存里边存的是补码,所以我们要想出它的补码,而波浪号~a 的时候,我们是在计算它的内存里边的那个值,对它进行按位取反,-1我们要写出它的补码,才能够算;然后符号位不变,其他位按位取反,即:11111111111111111111111111111110,得到的是反码;反码+1,+1之后其实就是最低为加了个1,就变成了全1了,即:11111111111111111111111111111111,这是补码,所以从这就简单的记住一个常识:-1的补码就是全1(简单的记一下,以后我们很容易就想到了,就不用一步一步算了)
然后 int b = ~a,我们对 a 给了个波浪号叫按位取反,即:原来位是1的,变成0;原来是0的,变成1,包括符合位,这个按位取反操作符压根就不认什么符号位不符号位,全部按位取反,其实对于-1来说,它在内存里边存的是11111111111111111111111111111111这样的一个全1,然后按位取反,包括符号位在内,全部变成0,就是全0了,原来是1的变成0,因为原来全是1,那就全部变成0,那变成0之后,得到结果是00000000000000000000000000000000,把这个结果放到 b 里边去,就是0,所以我们测试一下,如图所示:
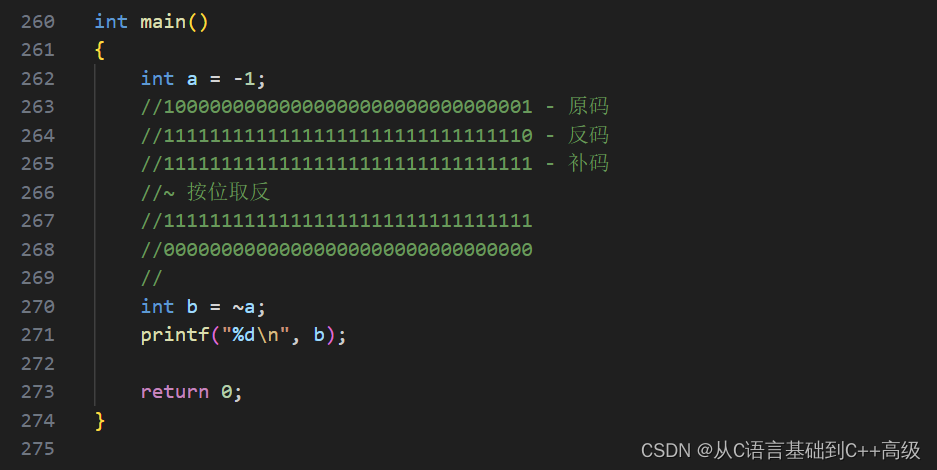
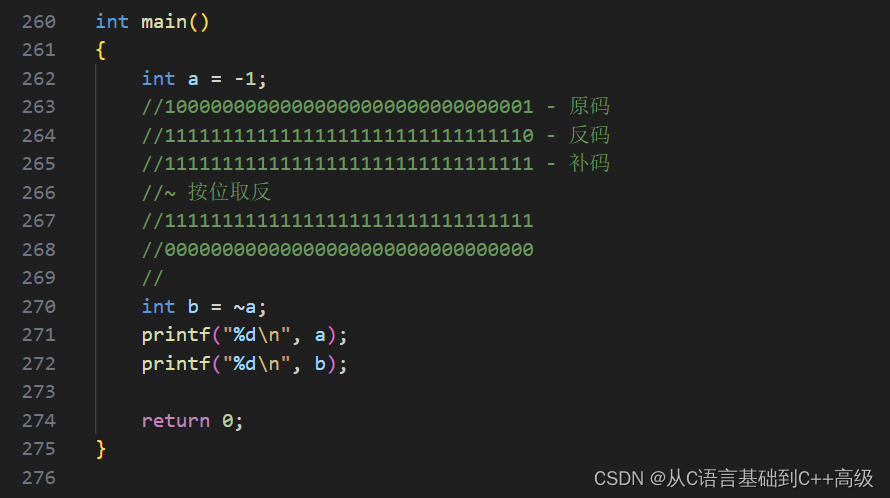
而如果我们还想测试一下 a,我们把 a 也打印出来看一下,a 有没有变呢?a 其实没变,a 还是我们的-1,因为波浪号~a 是对 a 的二进制序列按位取反,取反之后得到的结果就是00000000000000000000000000000000,b 是按位取反之后的一个结果,如图所示:

30.5.4 -- 和 ++
--这个操作符又分为前置--和后置--,++也分为前置++和后置++,这样的操作符,它又怎么回事呢?我们来一起看一下:其实,之前我们对++--这一块也就给大家讲过了,今天讲的也不会比原来深入,跟原来一样:假设有一个 int a = 10,然后 a++,++放到 a 的后边了,这叫后置++,如果我们把后置++的结果放到 b 变量里边去,即:int b = a++,那这个 b 到底是什么呢?printf("%d\n", a) 和 printf("%d\n", b)
后置++的意思就是,这个++是放到后边的,所以它的计算规则是先使用,后++,就是说把 a 里边的值,a 原来是10,先使用就赋给 b,这个是叫先使用,先使用它的值赋给 b,那 b 里边得到的就是10了,a再++,a 再自增,变成了11,所以当我们这看打印 a 的时候,我们这打印的是 a++之后的值,因为走到第293行的时候,这个++已经++过了,所以 a 变成了11,而 b 因为得到的是 a++之前的值,所以 b 应该是10
后置++是先使用,就是这个 a 的值,可以直接用,用完了之后,我们再把 a 的值加一下,叫先使用,再++,如图所示:


而反过来,如果我们换一下,假设有一个 int b = ++a,那这个时候叫前置++,前置++是先++,后使用,那这个地方怎么用的呢?其实就是 a 的值是10,先++一下,a 就变成了11,然后再赋给 b,是++之后的值,所以 a++之后变成11了,然后赋给 b 的时候,b 也是11,所以这个时候打印的两个应该都是11,这就是++的前置和后置的一个简单的讲法,如图所示:


假设有一个 int b = a--,这叫后置--,后置--一样的道理:先先用,后--,那请问这个地方的 a 和 b 打印出来是多少?先使用,那就是把 a 的值先使用赋给了 b,然后再自减,自减完之后 a 是9,变成9了,走到第295行的时候,a 已经减了。但是 b 得到的可是原来减之前的值,所以 b 是10,所以结果是9和10,如图所示:


如果我们换成前置的,假设有一个 int b = --a,那请问这个时候的 a 和 b 又是多少?这时应该就比较简单了,前置--是先--,a 就变成9了,然后再赋给 b,b 也是9,所以 a 也是9,b 也是 9,如图所示:


这就是++和--的一个简单的使用,再来一个例子:假设有一个 int a = 10,然后 printf("%d\n", a--),我们打印的结果是多少?然后再打印 a,即:printf("%d\n", a),这两个打印的是多少?a--,是先使用,再--,所以这个地方打印的时候,一定打印的是 a 原来的值,所以打印的结果,首先打印的是10。打印完之后,a--了,自减了,自减了之后,已经变成9了,所以第292行代码 a 打印的时候就应该是9,如图所示:


所以不一定是在表达式里边,打印其实也是一样的道理,++和--就了解到这,不要再过于深入,很多题目里边把这个代码真的是妖魔化了,然后这些代码真的是设计的非常的复杂,巨复杂。而且拿一些错误的代码来考试,所以这个时候不建议大家深入去挖掘这个++和--,没什么意义,反倒是浪费我们太多的时间,不值得
比如说,有人就喜欢用这样的代码:int a = 1,然后 int b = (++a)+(++a)+(++a),然后问 b 是多少?这种代码真的是没什么价值,有人就上当了,算了半天。实际上这个代码,是个有问题的代码,如图所示:


然而在 linux 平台上用 gcc 去编译代码 test.c,然后编译完之后,这个结果就生成了一个可执行程序叫 a.out,然后 ./a.out 去执行一下,这个时候跑出的结果是10,如图所示:

同样一段代码在 VS 底下跑出个12,而在 linux 环境底下居然跑出个10来,这就意味着同一个代码,可能产生不同的结果,数据一模一样的数据,代码一样的代码,那为什么结果就不一样了呢?说明这个代码是个垃圾代码,是个错误的代码,所以学校里边考这种题目,就很多的卷子里边考这种题目,就说明这个出卷子的人也不高明,所以这种垃圾题目,不做也罢
30.5.5 &和*
取地址操作符&和星号*是一对,这一对冤家其实经常会在一起用,假设有一个 int a = 10,我们知道:这个 a,它在内存中一定开辟空间的,开辟4个 byte,为什么有这4个 byte 呢?它里边要存放10,所以它内存中开辟空间,内存空间又划分成了一个一个小的内存单元,每个内存单元都有自己的编号,所以这个时候编号就被称为内存单元的地址,那 a 的地址是什么呢?我们就可以通过取地址&操作符来取出 a 的地址
a 的地址取出来之后,如果我们想打印,地址其实就是一个16进制的数字,其实应该是二进制的,只不过我们肉眼看到的时候,是以16进制展示的,然后我们以%p 的形式打印,打印地址,那我们直接可以打印,如图所示:


我们发现:a 确实有自己的地址,这个地址就是 a 所占这块空间的起始地址,起始内存单元的一个编号,这个地址不仅仅可以把它打印出来,我们可能需要把地址存起来,然后&a 假设是个地址的时候,我们要把它存起来,我就可以把它放到 pa 里边去,而 pa 是用来存放地址的,所以 pa 就是一个指针变量,指针变量是专门用来存放地址的,所以 pa 就是指针变量
那 pa 的类型怎么写呢?我们之前就学过:应该写成 int *,这颗星有讲法:* 其实说明 pa 是个指针变量,这颗星放到这,就告诉我们说 pa 是指针变量,那 pa 指向的那个对象是谁呢?是 a,a 的类型是 int,所以 int * 这也是 int,这个 int 说明 pa 是个指针变量,它指向的那个对象的类型是 int,所以未来 pa 的类型应该怎么写呢?首先我们得写颗星,说明 pa 是指针变量,然后前面是 int,因为 pa 里边放的是 a 的地址,a 的类型是什么,这就应该写成什么
这个指针变量 pa 里边,就放了一个 a 的地址,当有朝一日我们想通过 pa 来找到 a,怎么找呢?其实很简单:pa 这个变量的前边加上一颗星,这颗星被称为解引用操作符,或者叫间接访问操作符,这个 *pa 就是通过 pa 里边存的地址,找到它所指向的对象,pa 里边存的是 a 的地址,找到它所指向的对象就是 a,即:* pa 就是 a
如果 *pa = 20,这个时候一写,其实就是把上边的 a 改成了20,我们用 printf("%d\n", a)来打印一下,如图所示:


前边打印的是地址,后边打印的是20,a 的值不再是10,已经变成20了,这里边就用到了2个操作符:一个是取地址操作符 &,一个是解引用操作符 *,第324行这颗 * 和第323行这颗 * 是不一样的,上边的 * 告诉我们说 pa 是指针变量,下边的 * 是个操作符,是个解引用操作符。当然,& 叫取地址操作符,当然有人想问:这不是按位与么?确实,它也是按位与,按位与属于双目操作符,a&b,它有2个操作数的,而当它只有1个操作数的时候,它就是取地址操作符了,刚刚的 &a 是取出 a 的地址,只有一个操作数 a,所以它就是取地址操作符了
30.5.6 (类型)
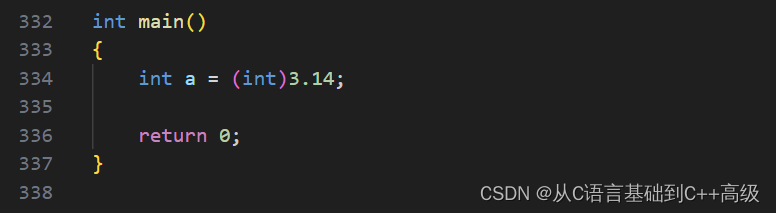
括号()里边放个类型,叫强制类型转换,举个例子,假设有一个 int a = 3.14,如果我们非要把这个3.14赋给 a,我们去编译代码的时候,这就报一个警告,warning:初始化,从 double 转换到 int 可能丢失数据,这个警告报的是很有道理的,3.14被认为是 double 类型,a 为 int,当赋过去的时候,类型不统一,有差异,所以就报警告,如图所示:


为了不看到这个警告,我们可以怎么办呢?强制类型转换。就在3.14的前边加上一个小圆括号,圆括号里边放一个 int,这个意思是:把3.14强制类型转换成 int 类型,括号括的是 int,括的是类型,而不是括给3.14的,这个时候我们在编译代码的时候,它就没错了,如图所示:

关于 sizeof 和数组,如果遇到这样的代码,又是怎么一回事呢?第331行给了一个 arr 数组,10个元素,每个元素是 int;ch 数组,10个元素,每个元素是 char,所以我们求一下 sizeof(arr),我们计算的应该是整个数组的大小,这个 arr 是10个元素,每个元素是 int,所以第331行应该是40
第332行 sizeof(ch)是数组,数组是10个元素,每个元素是 char,那这个时候计算一个数组大小应该是10,这是 sizeof 的特点
第321行是个 test1函数,test1函数把 arr 传过去了,arr 这个数组传给 test1函数上来的时候,然后打印 sizeof(arr),这个是多少呢?然后又把 ch 这个数组传参,传给了 test2,传参过去之后,传给了 test2函数,char ch 接收,然后 sizeof(ch) 又是多少呢?1的位置和3的位置是很容易理解的,因为我们直接算的是数组大小。但是,在第二个位置和第四个位置这个结果都是8(64位平台),为什么这么讲呢?
我们再一次提出来我们之前讲的一个东西,我们在学数组的时候,当然给大家讲了:数组传参,其实本质上传过去的是不是数组?不是。传过去的是数组首元素的地址,既然这传过去的是数组首元素的地址,是第一个元素的的地址,这个数组的每个元素都是 int,它的第一个元素当然也是 int 了,首元素的地址就是 int 的地址,int 的地址传过去,其实本质上应该是一个指针,因为首元素的地址传过来,地址应该放到指针变量里边去,所以第321行的 arr,应该是 int * arr,arr 是一个指针,所以第323行代码算的是一个指针变量的大小,那在32位平台下是4;64位平台下是8,所以是4或者8。那我们这个编译器,我们之前测试的指针大小是4个 byte,所以编译出来32位程序,所以是4
同样的道理,你不要看说我是一个 char 类型的数组,ch 传过去依然传的是首元素地址,传的是一个 char 类型的地址,即使我们传的是一个 char 类型的地址过去,第327行应该也是个指针,所以其实也是一个 char * 的指针,指针变量是用来存放地址的,ch 也是用来存放地址的,它的大小也是个指针变量的大小,它也是个4个或者8个 byte,如图所示:
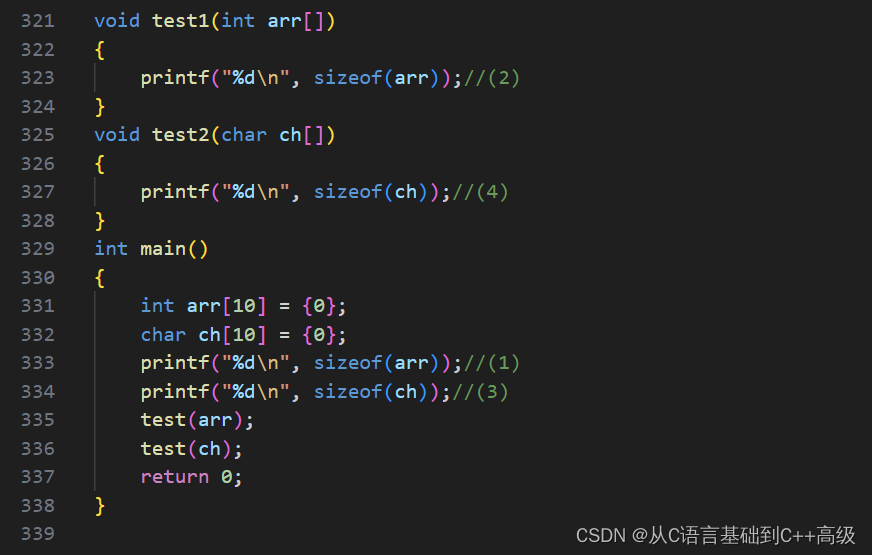
因此,结果就很明确了:有人就说不是一个 char 类型的指针么?它不应该是1么?指针大小不论类型,它们不管什么类型的指针变量,都是用来存放地址的,因为地址总是32个二进制序列或64个二进制序列,所以地址的大小是固定的,所以指针变量不管什么类型,它的大小都是那么大
(3)为什么是10,因为是个 char 类型的数组,10个元素,每个元素是 char
30.6 关系操作符
关系操作符这个很简单,就是判断大小,有>,>=,<,<=,!= 和==,就这么些操作符,就是说我们要判断两个数是不是相等的时候,假设要判断的是这个数不相等,我们要做什么事情,应该怎么写呢?假设有一个 int a = 3,int b = 5,然后 a 如果等于 b,我要做什么事情的话,我们就可以写成 if(a == b){},这叫相等的判断,两个等号叫判断相等,如图所示:

而如果我们要写,a 不等于 b,我要做什么事情的话,应该这样写:if(a != b){},如图所示:

如果我们说 a 大于 b,我要做什么事情的话,应该这样写:if(a > b){},如图所示:

当然我们也可以写成,a 小于 b 的时候,我要做什么事情,如图所示:

当然,我们也可以写成 a 小于等于 b,我们就可以写成 if(a <= b),如图所示:

所以,关系操作符就是比较大小的,但是我们非要强调一下的就是:一个等号=叫赋值,两个等号==叫判断相等。当然,还有一些情况下,是不能直接用等号==来判断相不相等,有些东西是不能直接用等号来判断相等的,比如说字符串比较 strcmp,比较两个字符串相等,不能使用等号=,数字比较大小,可以用等号=来比
30.7 逻辑操作符
30.7.1 并且&&
逻辑操作符是什么呢?就是逻辑与和逻辑或,就是表示并且或者或者的意思,两个与号叫逻辑与,即:&&,举个例子,逻辑与只看真假,,假设有一个 int a = 3,int b = 0,然后 a 并且 b,这个时候的意思就是:a 为真,b 为真的时候,这个时候里边才进去,但是现在 a 为3,为真,没问题;但是 b 现在是0,为假,那就不进去了
就是说这两个条件里边,但凡有一个为假,那结果就为假了,两个同时为真才为真,并且的关系,假如我想买蔡徐坤的篮球🏀并且背带裤,这是并且的意思,那这个时候只有篮球🏀和背带裤都要买,这才满足我刚刚说的那句话,如果篮球🏀买了,所以 a && b 的时候,这个条件要求是 a 和 b 同时满足的时候,这个条件才能满足,如图所示:

那现在的 a 并且 b,如果我们这打印 hehe,它会不会打印呢?它肯定不会打印的,为什么没有打印呢?因为 b 为假,只有一个满足条件了,如图所示:


如果把 b 改成5,a 为真,b 为真,如图所示:


如果两个都为假,那就更明确了,只要有一个为假,都已经为假了,如图所示:

30.7.2 或者||
如果我们写成两个||,即:if(a || b),这叫 a 或者 b,这个时候 a 改成3,b 改成0,这就是 a 或者 b 里边,只要有一个满足,那就满足,如图所示:

如果两个都为假,那这个时候才不打印,如图所示:

两个都为真,a 给个3,b 给个5,两个都买了,肯定开心,如图所示:

逻辑与和逻辑或的意思是什么?它们是判断真假的,我只关注真假,对于逻辑与来说,两个里边只要有一个为假,那就为假,两个同时为真,才为真;对于逻辑或来说,只要有一个为真,则为真,两个同时为假,才为假
同时一定要把按位与和逻辑与,按位或和逻辑或区分开,1个叫按位与,2个叫逻辑与
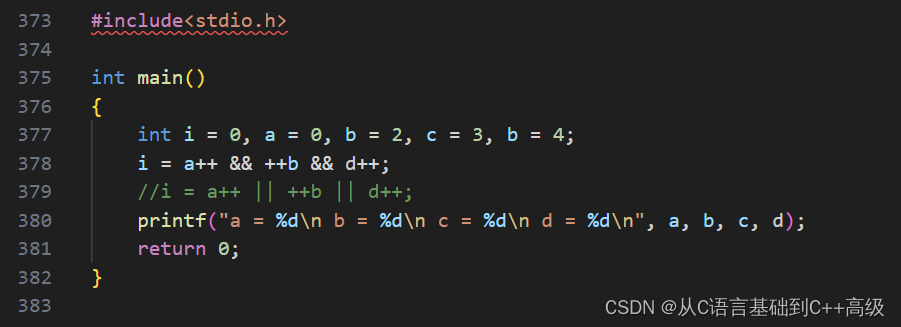
面试题:这道题说 i = 0,a = 0,b = 2,c = 3,d = 4,i = a++ && ++b && d++,计算 i,请问最终 a 等于多少,b 等于多少,c 等于多少,d 等于多少?是1,2,3,4
为什么这地方算的是1,2,3,4呢?如果 a && b 的时候,结果放到 c 里边去,即:int c = a && b,这个表达式,当我们发现 a 已经为假的时候,为0了,b 重不重要?b 其实不重要了,不管 b 是0还是3,我们会发现:这个表达式的结果都是0了,因为并且的话,只要有一个是0,那就为0了,所以 b 的值就根本不重要,所以这个并且这个操作符来说,左边如果确定为假的时候,右边就不用算了,这叫短路求值
所以我们根据这个结论,来看一下我们刚刚的代码:i 等于后边这个表达式的结果,我们得算这个表达式结果,这个表达式在算的时候,那我们怎么算呢?我们首先肯定是算 a++,a++后置++,后置++的意思就是:a 先使用再++,所以 a++这个表达式结果其实就是0,0为假,后边的要不要算了?
不用算了,因为 ++b 不管结果是多少,这个整体的并且算的结果肯定是0,++b 是0的话,第二个并且后边又不用算了,所以前边并且算的结果是0的话,后边也不用算了。因此,++b 没算,d++没算。所以 b 没变;c 就没涉及,没变;d 也没变,这个表达式结果是0,并且后边也是0,所以 i 被赋值成0,a 反正已经要运算了,它使用完之后也要++一下,a 变成了1,所以 a 是1,如图所示:

假设我们把 a 改成1,现在的结果又变成什么了?答案是2,3,3,5,是什么原因导致的呢?现在这个代码就又发生了变化,我们首先也是算a++,a是1,先使用,结果是1;1为真,所以后边要算的,b本来是2,所以 b 已经变成3了,a++完之后,也会变成2,d 本来就是4,4为真,所以整体 i 就变成1了,d 也要自增(后置++也要++一下),它也会变成5,所以最终结果是2,3,3,5,如图所示:


现在我们对于逻辑与会的话,我们再来换一下逻辑或:我们现在看一下我们的代码的结果是什么,现在变成了 a++ || ++b || d++,代码没变,a 还是1,答案是2,2,3,4
为什么是2,2,3,4呢?这个地方其实也是一样的道理,如果是 a || b 的这样一个逻辑,然后要把这个结果非要赋给 c,即:int c = a || b,对于这个表达式来说,如果我发现 a 已经为真了,比如说 a 为3,为真了,那后边重要不重要?不重要了。因为不管后边是真还是假,我们这个表达式结果都为真了。因此,对于逻辑或来说,左边为真,右边就不用算了。对于逻辑与来说,左边为假,右边就不用算了。
所以这个表达式 a++,因为 a 是1,a 后置++先使用,这个表达式结果是1,1为真,或后边就不用算了,所以后边的都没算,所以 a 是1,自增一下,后增也会增,变成了2,然后 bcd 都没变,就是2,2,3,4,最终 i 是1(就是真),如图所示:


如果 a 不是1了,恢复到0,那这个时候结果又发生变化了,因为现在的 a 是0了,a 一旦变成0的时候,我们的答案就又发生了一个简单的变化,=====如图所示:

30.8 条件操作符
什么叫条件操作符呢?也叫三目操作符,它是“问号”“冒号”的这样一种形式来表现的,exp 1 ?exp 2 :exp 3这样一个形式来呈现的。对于我们这个地方的“问号”和“冒号”这个操作符来说,它其实有3个操作数的,一个是表达式1,一个是表达式2,还有一个是表达式3。这三个东西就是3个操作数,所以它也叫三目操作符,如图所示:

那这个三目操作符具体是怎么描述的呢?其实是这样的:
exp1如果成立,exp 2计算,整个表达式的结果是 exp 2的结果
exp1如果不成立,exp 3计算,整个表达式的结果是 exp 3的结果
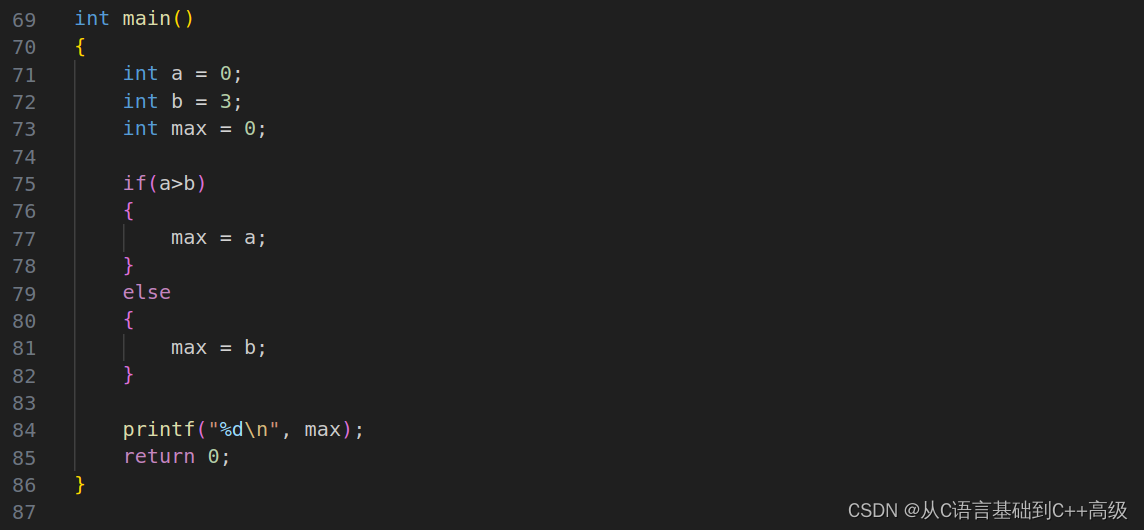
那我们具体举例子吧,在这讲一个代码,还是假设 int a = 0,int b = 3,int max = 0,我想求出 a 和 b 的较大值,我们怎么求呢?我说 if(a>b),那较大值就是 a,max 就被赋成了 a,else 的话,max 就被赋成了 b。这样的话 a 和 b 的较大值我们放到 max 里边去了, a 如果大于 b 的话,那我们 a 较大值就放到 max 里边去,否则 b 较大值就放到 max 里边去,然后打印 max 就行,如图所示:
但是,有的人肯定会说第75-82行代码有点多,如果我们要三目操作符能表达的话,怎么表达呢?也很简单, a 如果大于 b 这个表达式成立的话,问号,然后整个表达式的结果就是 a 的结果。冒号,否则就是 b 的结果。刚刚 if 语句写成的代码,我们用一句代码就搞定了,然后打印 max 就行,如图所示:
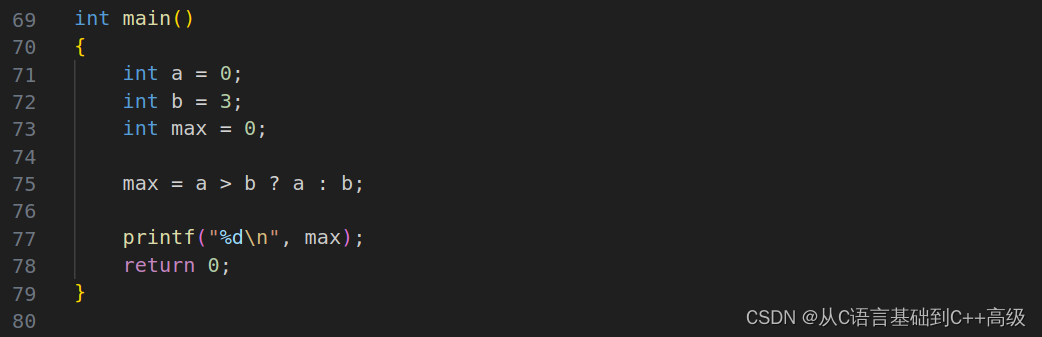

当我写出 max = a > b ? a : b 代码的时候,和 exp 1 ?exp 2 :exp 3代码就对应起来了,a > b 就是 exp1,表达式1如果成立,表达式2计算(a 计算),但是这个没什么可计算的,整个这个表达式的结果就是 a 的结果,a 赋给 max,否则 b 赋给 max,如图所示:

总结:未来有合适的场景,我们也可以用我们的三目操作符来表示这种逻辑,很简单,表达式1的结果如果为真,表达式2要计算,表达式2的结果是整个表达式的结果,否则就是表达式3的结果
30.9 逗号表达式
逗号表达式是逗号隔开的一串表达式,逗号表达式其实更简单一些
在这里简单的举个例子,括号里边写个 (2,4+5,6),这就是个逗号表达式,由逗号隔开的一串表达式,只不过这个表达式好像没产生什么效果。6就是6,4+5也就是4+5,但是它算不算逗号表达式呢?算,就是逗号表达式。如图所示:

当然我们也可以这么写,int a = 0,int b = 3,int c = 5,int d = (a = b + 2,c = a - 4,b = c + 2),这就是个逗号表达式,括号里边写的这个就是逗号表达式。
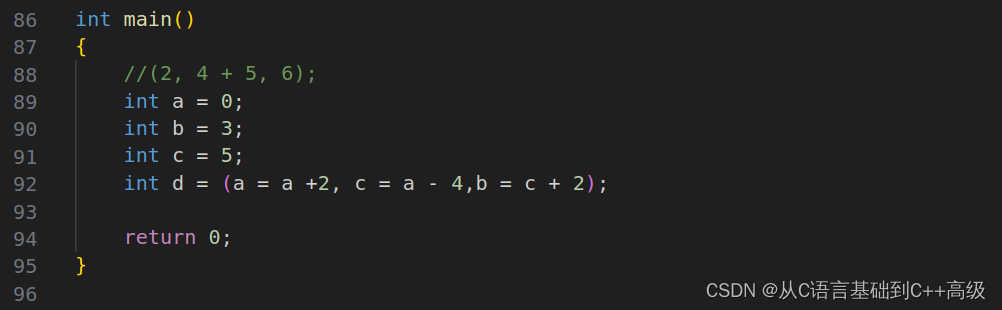
那这个逗号表达式它的特点是什么呢?逗号表达式是从左向右依次计算的,整个表达式的结果是最后一个表达式的结果
接下来,我们就打印一下 d,根据从左向右依次计算:首先 b+2赋给 a,这个表达式要算,b 是3,加2就是5了,a 变成了5了;也就是说,这一步完了之后,a 现在变成了5
然后再往后,c = a -4,a 是5,5-4=1,所以 c 就变成了1
然后 b = c +2,c 就是1,所以 b 就变成了3,
最后这个表达式的结果就是3,3赋给 b,这个表达式的结果就是3,如图所示:


所以,更加坚定的一点:逗号表达式一定要从左向右依次计算,它不可能凭空就算到后面去了,这是不可能的,整个表达式的结果是最后一个表达式的结果
30.10 下标引用、函数调用和结构成员
30.10.1 下标引用操作符
[ ] 这个操作符用于什么呢?举个例子,写个数组 int arr[10] = {1,2,3,4,5,6,7,8,9,10},假设我们把它里边的一个元素拿出来,我们要把它的第6个元素拿出来,第6个元素的下标是多少呢?是5。
所以我们写出 arr[5]的时候,就是我们的第6个元素,我们可以把它打印出来,我们说数组的下标是从0开始的,数组是由下标来访问的,如图所示:


我们可以看到:这个结果就出来了,确实打印出来了我们的6。那这个时候注意:第104行代码,使用的这个[ ]就是下标引用操作符,数组访问元素的时候,会用到一个[ ],这个[ ]下标引用操作符。
注意:第103行代码中使用的[ ]不是下标引用操作符,这是我们在定义数组的时候的一种语法
30.10.2 函数调用操作符
什么是函数调用操作符呢?举个例子,比如说我现在想在屏幕上打印一个 jiniitaimei ,那这个时候,调用这个 printf 函数的时候,后面这个地方有个圆括号,这个圆括号就是函数调用操作符。因此,调用函数的时候,函数名后边的()就是函数调用操作符,
也就是说,第114行代码这一对圆括号,就是函数调用操作符,它是个操作符,如图所示:

当然,我们还可以这样写:(%d, 100),我们打印个100,对于第114行代码这个圆括号来说,它这个操作符有几个操作数呢?在第114行代码传参,好像就传了一个字符串,感觉好像是1个参数。第115行代码传参,也可以传2个参数。如图所示:

因此,函数调用操作符可以传1个或多个参数,一个参数不传也行,它比较特殊一些。
30.10.3 结构成员操作符
请看第15章中的15.3.1 和15.3.3
补充:
1. * 是一颗星,就是说我们在 C 语言里边是敲不出乘号的,除非敲个x,那是x,是数学里的乘号,不是 C 语言里的乘号,C语言里的乘号用 * 号代表
2. 最后一位永远补0(如果左移的话),这是规定死的
3. %是取模、取余
4. >>(右移操作符) <<(左移操作符) { 右移左移主要是看箭头!}
5. 移位操作符移的是二进制位
6. 其实对于右移来说,也是一样的,就是把它的二进制位向右移动,但是具体细节,我们现在这里先不讲解
7. 整数在内存里边存储的是补码,一个整数有3种表示形式:原码、反码、补码。而 %d 打印出来的值是原码,实际上内存里边存的是补码。对于正整数来说,它的原码、反码、补码相同,当我们写出它的原码的时候,就是它的反码,就是它的补码。
8. 正数的原反补一样,这是规定,这个没有为什么(就比如说为什么有个正数和负数,这个没法解释)















 5983
5983











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









