






目录
一、数据采集的概述
1、数据的采集综述
数据采集:又称数据获取,搜集符合数据挖掘研究要求的原始数据。
数据采集是大数据分析的入口,所以是相当重要的一个环节。大数据采集与预处理是获取有效数据的重要途径,也是大数据应用的重要支撑。数据采集范围决定数据分析挖掘的维度深度。
数据采集一般包括三个部分分别为数据目标源、采集方式、数据形式。
数据目标源:数据的来源,是提供某种所需要数据的器件或原始媒体。
- 组织内部数据
- 互联网数据
- 物联网数据
- 政府公开数据
- 第三方数据
采集方式:用来采集互联网信息的网络爬虫。
数据采集形式:采集的形式多种多样,更具需求选择数据采集的形式。
2、互联网数据采集
网络爬虫的介绍,什么是网络爬虫?
爬虫请求网站并提供数据的自动化程序,又称网络蜘蛛,网络蚂蚁,网络机器人等,它可以不受人工干扰自动按照既定规则浏览互联网中的信息。我们把这些既定规则,称为爬虫算法。使用Python 语言可以方便的实现这些算法,编写爬虫程序,完成信息的自动获取。
常见的网络爬虫:百度公司的Baiduspider、360公司的360Spider、搜狐公司Sogouspider、微软公司的Bingbot等。
简单易用的爬虫采集器:八爬鱼采集器、后羿采集器。
3、爬虫的流程
网络爬虫实质上是一个能自动下载网络程序,它是搜索引擎中最核心的部分。
我们所谓的上网是由用户端计算机发送给目标计算机,将目标计算机的数据下载到本地的过程。而爬虫程序要做的就是 模拟浏览器发送请求—>下载网页代码—>只提取有用的数组—>存放于数据或者文件中。
4、反爬虫技术
反爬虫技术,通过反反爬虫破解反爬技术

总结
数据采集定义:又称数据采取,搜索符合数据挖掘研究要求的原始数据。
数据采集:为数据目标源、采集方式、数据采集形式。
爬虫技术:请求网站并提取数据的自动化程序。
反爬虫技术:headers字段、登录、IP、验证码。
二、数据采集流程—发送请求与获取内容
数据采集的四个流程:

一、发送请求
Http协议:产文本传输协议是浏览器和服务器之间的传输协议,他通常运行在传输控制协议之上。它指定了浏览器可能发送给服务器什么样的信息以及得到什么样的响应。
 URL:称为统一资源定位符,也称为网址。互联网上的每个页面,都对应一个URL。
URL:称为统一资源定位符,也称为网址。互联网上的每个页面,都对应一个URL。

二、requests库
Requests库是一个Python的第三方库, 可以通过调过来帮助我们实现自动爬取HTML网页页面以及模拟人类访问服务器自动提交网络请求。
| 方法 | 说明 |
| requests.request() | 构造一个请求,Requests库的核心方法。支撑以下各方法的基本方法 |
| requests.get() | 获取HTML网络的主要方法 |
| requests.head() | 获取HTML网页的头信息 |
| requests.post() | 向HTML网页提交追加资源的请求 |
| requests.put() | 向HTML网页提交覆盖资源的请求 |
| requests.patch() | 向HTML网页提交局部修改的请求 |
| requests.delete() | 向HTML网页提交删除的请求 |
1、requests.get():
构造一个向服务器请求资源的url对象。在这个对象Requests 库内部生成的。返回的是一个包含服务器资源的Response对象。包含从服务器返回的所有的相关资源。
import requests
r = requests.get("https://mp.csdn.net/mp_blog/creation/editor/139159154")
print(r.status_code)
print(r.text)
print(r.encoding)
print(r.apparent_encoding)
print(r.content)| 属性 | 说明 |
| r.status_code | HTTP请求的返回状态,200表示连接成功,其他表示失败 |
| r.text | HTTP响应内容的字符串形式,即url对应的页面内容 |
| r.encoding | 从HTTP header中猜测的响应内容编码方式 |
| r.apparent_encoding | 从内容中分析出的响应内容编码方式 |
| r.content | HTTP响应内容的二进制形式 |
2、获取内容
在爬取过程中通过上面表格中的内容来获取内容,可能在爬取过程中会遇到反爬,其中的一种是headers字段反爬:无论是浏览器还是爬虫程序,在向服务器发起网络请求的时候,都会发送一个headers文件。通过User-Agent字段来反爬。
对策:通过伪装user-agent,模拟成真实的浏览去取出内容。
应对的步骤:
打开开发者模式:点击网络、点击文档(Doc)、刷新页面、点击文档名称、在标头找到user-agent;
总结
①、requests库:发送网络请求、返回响应数据。
②、requests.get():构造一个向服务器请求资源的url对象。
③、数据获取流程:发送请求 > 获取响应内容 > 解析内容 > 保存数据
④、浏览器开发者模式:查找资源存放在哪个地方就需要用到浏览器开发者模式。
三、数据采集流程—解析内容与数据保存
一、解析内容
解析内容:我们看到的网页数据是经过渲染之后的,需要XPath、正则表达式等方式设定规则,查找目标位置,进行解析,引导采集工具执行采集作业。比较常用XPath进行解析。
XPath 即为XML路径语言(XML PathLanguage),是一门用来确定XML文档中某部分位置的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。
Chrom插件XPath Helper:是谷歌浏览器的开发者插件,安装后用该插件可以预览xpath所
提取的内容。就再也不需要通过搜索 html 源代码,定位一些 id 去找到对应的位置去解析网
页了。
Xpath插件的下载流程:
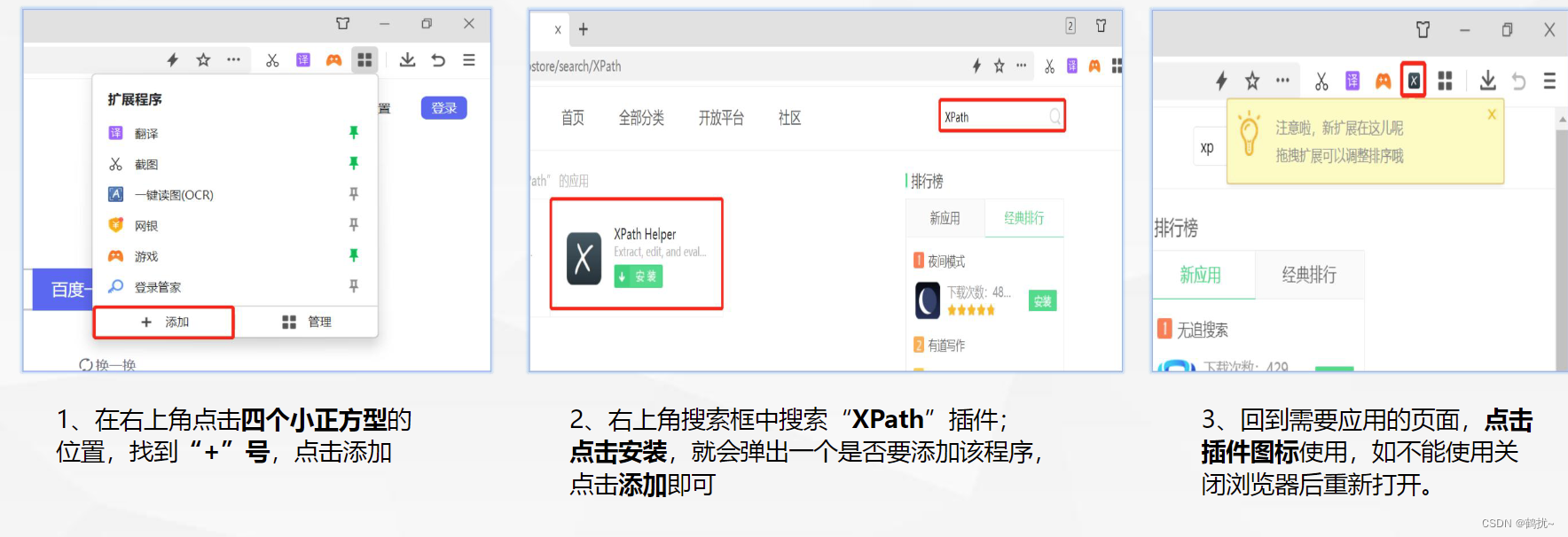
使用的方法:
1、打开浏览器开发者模式
2、单击方框小箭头
3、点击需要查看的页面元素
4、点击左侧的三个点-复制-复制XPath
5、粘贴到XPath Helper左侧框中
二、数据的保存
数据保存:解析后进行数据爬取,爬取数据后,需要将数据保存至本地,以便后续直接使用;保存文件类型:json格式、csv格式、二进制文件(图片、视频、Excel文件(xlsx/xls))等。
1、open()函数:用来创建文件
with.open('文件名称', '写入模式', '编码方式') as f:
格式:
open(file,mode='r',encoding=None) = open('文件名称','写入模式',编码方式)
参数“文件名称”必须填写
参数“写入模式”是可选的
Open中常用的参数
file:文件名称,打开并返回一个文件对象;
mode:文件写入的模式,默认为“r”只读方式;
r 只读方式打开文件,文件必须存在
w 重新写入,有文件,覆盖原内容,无文件,重新写入。
a 追加写入,有文件,追加写入,无文件,新写入
b 处理二进制文件,包含 rb、wb、ab。不需要指定编码方式
encoding:写入文件时使用的编码方式,一般设置为encoding='utf-8'。
2、write()函数:向文件中写入指定内容
write(data):
参数解释:
data:是指写入的数据,包括字符串类型、二进制类型
字符串与二进制类型转换:
• str通过encode方法转化为bytes。
• bytes通过decode方法转化为str。
常用文件类型总结:
r.text、json文件、csv文件等文本型文件r.content、Excel文件(xlsx/xls)、图片类文件(png/jpg)、视频类文件(mp4)等。
总结
①、解析内容:XPath查找目标位置,进行解析
②、数据保存:解析后进行数据爬取,爬取数据后,需要将
③、数据保存至本地
Open函数:用来打开和创建文件
write()函数:向文件中写入指定内容















 1667
1667











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









