







目录
一、左值引用和右值引用
传统的C++语法中就有引用的语法,而C++11中新增了的右值引用语法特性,所以从现在开始我们 之前学习的引用就叫做左值引用。无论左值引用还是右值引用,都是给对象取别名。
什么是左值?什么是左值引用?
左值是一个表示数据的表达式(如变量名或解引用的指针),我们可以获取它的地址+可以对它赋 值,左值可以出现赋值符号的左边,右值不能出现在赋值符号左边。定义时const修饰符后的左 值,不能给他赋值,但是可以取它的地址。左值引用就是给左值的引用,给左值取别名。
int main()
{
// 以下的p、b、c、*p都是左值
int* p = new int(0);
int b = 1;
const int c = 2;
// 以下几个是对上面左值的左值引用
int*& rp = p;
int& rb = b;
const int& rc = c;
int& pvalue = *p;
return 0;
}
什么是右值?什么是右值引用?
右值也是一个表示数据的表达式,如:字面常量、表达式返回值,函数返回值(这个不能是左值引 用返回)等等,右值可以出现在赋值符号的右边,但是不能出现出现在赋值符号的左边,右值不能 取地址。右值引用就是对右值的引用,给右值取别名。
int main()
{
double x = 1.1, y = 2.2;
// 以下几个都是常见的右值
10;
x + y;
fmin(x, y);
// 以下几个都是对右值的右值引用
int&& rr1 = 10;
double&& rr2 = x + y;
double&& rr3 = fmin(x, y);
// 这里编译会报错:error C2106: “=”: 左操作数必须为左值
10 = 1;
x + y = 1;
fmin(x, y) = 1;
return 0;
}
需要注意的是右值是不能取地址的,但是给右值取别名后,会导致右值被存储到特定位置,且可 以取到该位置的地址,也就是说例如:不能取字面量10的地址,但是rr1引用后,可以对rr1取地 址,也可以修改rr1。如果不想rr1被修改,可以用const int&& rr1 去引用,是不是感觉很神奇, 这个了解一下实际中右值引用的使用场景并不在于此,这个特性也不重要。
int main()
{
double x = 1.1, y = 2.2;
int&& rr1 = 10;
const double&& rr2 = x + y;
rr1 = 20;
rr2 = 5.5; // 报错
return 0;
}二、左值引用与右值引用比较
左值引用总结:
1. 左值引用只能引用左值,不能引用右值。
2. 但是const左值引用既可引用左值,也可引用右值。
int main()
{
// 左值引用只能引用左值,不能引用右值。
int a = 10;
int& ra1 = a; // ra为a的别名
//int& ra2 = 10; // 编译失败,因为10是右值
// const左值引用既可引用左值,也可引用右值。
const int& ra3 = 10;
const int& ra4 = a;
return 0;
}右值引用总结:
1. 右值引用只能右值,不能引用左值。
2. 但是右值引用可以move以后的左值(move可以将左值变为右值),注意:move只是类似于强转,并不会影响变量本身的属性。不要轻易的对左值进行move,move传值后可能会被掠夺资源。
int main()
{
// 右值引用只能右值,不能引用左值。
int&& r1 = 10;
// error C2440: “初始化”: 无法从“int”转换为“int &&”
// message : 无法将左值绑定到右值引用
int a = 10;
int&& r2 = a;
// 右值引用可以引用move以后的左值
int&& r3 = std::move(a);
return 0;
}
三、右值引用使用场景和意义
前面我们可以看到左值引用既可以引用左值和又可以引用右值,那为什么C++11还要提出右值引 用呢?是不是化蛇添足呢?下面我们来看看左值引用的短板,右值引用是如何补齐这个短板的!
首先要理解右值引用的意义和优点,就先要知道左值引用的缺点和其不能完成的场景,既然const左值引用左右值都可以引用,那为什么还需要右值引用呢?
首先左值引用可以解决以下问题:
1、解决传参拷贝的问题。
2、解决部分返回对象拷贝的问题。(如果出了作用域,返回对象依然存在没有销毁,就可以使用左值引用减少一次拷贝构造)
通过上述分析我们可以得出,在返回值时,如果变量是一个局部变量,出了函数作用域生命周期就结束了,在此情况下左值引用返回就失去了它的意义和用途,此时只能传值返回,就会发生拷贝,如果是浅拷贝还好,如果是类似于红黑树、堆、哈希桶或者vector<vector<int>>等结构。将会产生非常大的消耗。
左值引用场景
void func1(string s)
{}
void func2(const string& s)
{}
int main()
{
string s1("hello world");
// func1和func2的调用我们可以看到左值引用做参数减少了拷贝,提高效率的使用场景和价值
func1(s1);
func2(s1);
// string operator+=(char ch) 传值返回存在深拷贝
// string& operator+=(char ch) 传左值引用没有拷贝提高了效率
s1 += '!';
return 0;
}左值引用的短板

就好比上图的情景,正常来走是两次拷贝构造,编译器经过优化后可以变成一次拷贝构造,在generate函数结束之前把vv对象拷贝给ret。即使已经大大提升了效率,但是对C++这样极致追求效率的语言来说还可以提高。
此时就出现了一种全新的语法:右值引用。
3.1右值引用的使用场景
拿string来进行举例:
以下是从博主模拟实现的string中截取出来的一部分
namespace gaz
{
gaz::string to_string(int value)
{
bool flag = true;
if (value < 0)
{
flag = false;
value = 0 - value;
}
gaz::string str;
while (value > 0)
{
int x = value % 10;
value /= 10;
str += ('0' + x);
}
if (flag == false)
{
str += '-';
}
std::reverse(str.begin(), str.end());
return str;
}
}
int main()
{
// 在gaz::string to_string(int value)函数中可以看到,这里
// 只能使用传值返回,传值返回会导致至少1次拷贝构造(如果是一些旧一点的编译器可能是两次拷贝构造)。
gaz::string ret1 = gaz::to_string(1234);
gaz::string ret2 = gaz::to_string(-1234);
return 0;
}如果只存在左值引用的情况下,我们使用模拟实现的to_string进行字符串转化时,返回已经转化完成的string时就只能返回一个string类型,因为此处如果使用右值引用的话出了to_string的作用域,这个对象就会销毁,此时无法将转换出的string传出。而此时to_string传出的值要赋给ret,此时的str虽然是一个左值,但在传给ret时,编译器会将其拷贝构造为一个右值,然后赋给ret。
C++11对右值概念的解释细分为:
1、纯右值:(内置类型的右值)如:1 2 3 4 5
2、将亡值:(自定义类型的右值)如:匿名对象、传值返回函数。如:匿名对象、传值返回函数。

而返回作为左值str中间转换产生的右值就被称为将亡值。而这里编译器还会再进行一次优化。

注意:那为什么不在这里显示的写move(str)而是由编译器去move呢?因为我们要考虑存量的问题,因为C++要兼容C语言,而在语言刚诞生的时候还不支持右值引用。所以这里编译器将str隐式的move了。
3.2移动构造、移动赋值
根据上面的场景,既然str作为左值要变成右值返回给ret,而且它又作为一个即将销毁的将亡值,而在return时右需要对其进行深拷贝,而深拷贝是一种及其的资源浪费,那能不能直接不销毁它直接将其资源进行转移呢?
答案时肯定的,这时就可以重载出一个移动构造,配合move对其资源进行转移。
// 拷贝构造 -- 左值
string(const string& s)
:_str(nullptr)
{
cout << "string(const string& s) -- 深拷贝" << endl;
_str = new char[s._capacity + 1];
strcpy(_str, s._str);
_size = s._size;
_capacity = s._capacity;
}
// 移动构造 -- 右值(将亡值)
string(string&& s)
{
cout << "string(string&& s) -- 移动拷贝" << endl;
swap(s);
}如果只重载了一个拷贝构造,那不管是将亡值还是一个普通对象都会走左值的拷贝构造,而重载了右值拷贝构造后,如果碰到了拷贝的对象时右值,就会调用右值的拷贝构造。而此处的swap就运用的非常巧妙,将需要拷贝的值与当前值所指向的空间进行交换,就在不开辟新空间的情况下完成了拷贝,而传值时传过来的string &s在经过swap后指向了原本this所指向的空间,出函数栈帧的时候还顺便把原本this指向的空间一并释放了。
当然,此情况也只限于深拷贝的情况下可以提高效率,浅拷贝情况下,移动构造就没有太大意义,比如之前模拟的日期类。
总结一下:
浅拷贝的类不需要移动构造。
深拷贝的类才不需要移动构造。
// 拷贝赋值
// s2 = tmp
string& operator=(const string& s)
{
cout << "string& operator=(const string& s) -- 深拷贝" << endl;
string tmp(s);
swap(tmp);
return *this;
}
// 移动赋值
string& operator=(string&& s)
{
cout << "string& operator=(string&& s) -- 移动拷贝" << endl;
swap(s);
return *this;
}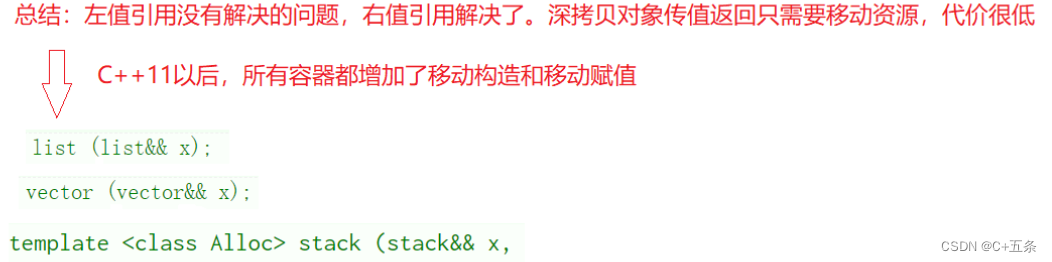
3.3右值引用引用左值及其一些更深入的使用场景分析
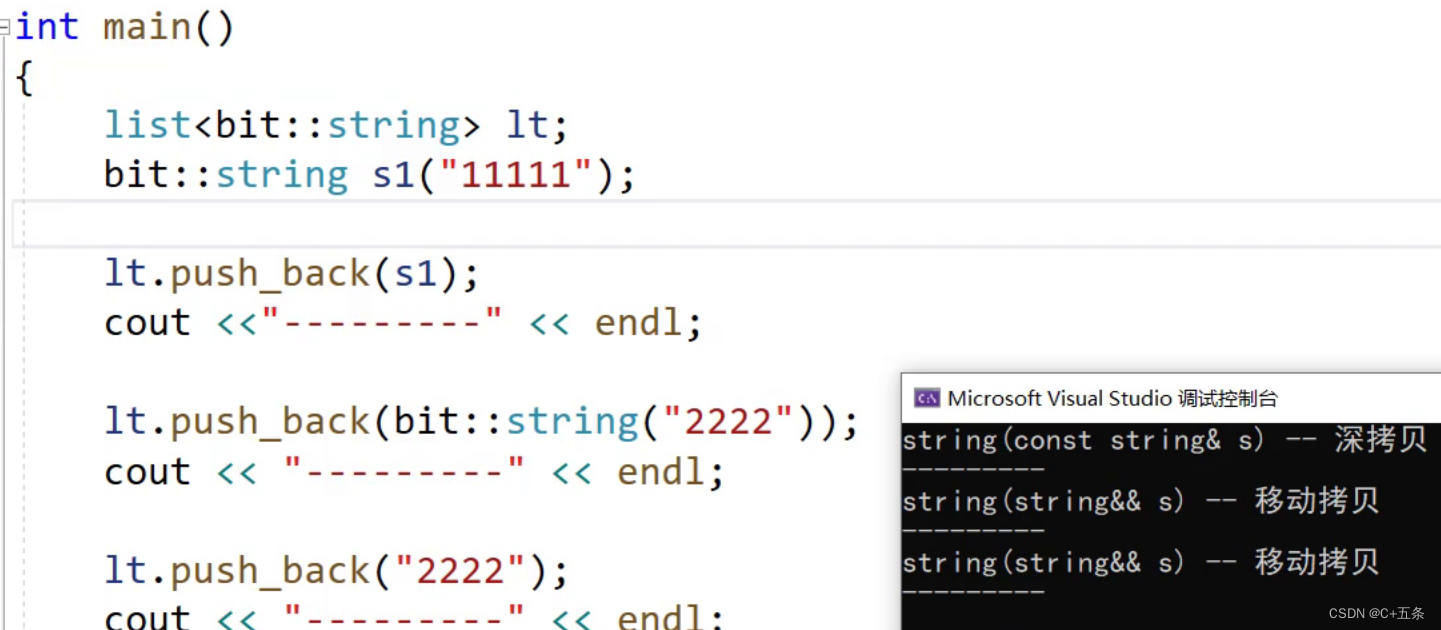
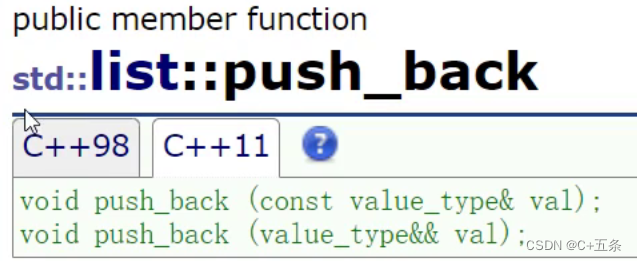
可以看到list的push_back提供了两个版本,一个左值引用一个右值引用。而list的构造是在节点中构造string时调用的。
在我们之前模拟实现的list中,我们也可以重载右值引用的版本:
template<class T>
struct ListNode
{
ListNode<T>* _next;
ListNode<T>* _prev;
T _data;
ListNode(const T& x = T())
:_next(nullptr)
, _prev(nullptr)
, _data(x)
{}
ListNode(T&& x)
:_next(nullptr)
, _prev(nullptr)
, _data(move(x))
{}
};同时insert,构造也要提供右值。
iterator insert(iterator pos, const T& x)
{
Node* cur = pos._node;
Node* prev = cur->_prev;
Node* newnode = new Node(x);
// prev newnode cur
prev->_next = newnode;
newnode->_prev = prev;
newnode->_next = cur;
cur->_prev = newnode;
//return iterator(newnode);
return newnode;
}
iterator insert(iterator pos, T&& x)
{
Node* cur = pos._node;
Node* prev = cur->_prev;
Node* newnode = new Node(move(x));
prev->_next = newnode;
newnode->_prev = prev;
newnode->_next = cur;
cur->_prev = newnode;
//return iterator(newnode);
return newnode;
}push_back也要重载右值引用版本
void push_back(const T& x)
{
insert(end(), x);
}
void push_back(T&& x)
{
insert(end(), move(x));
}这里每次传参都会进行move操作,既然push_back已经构造了右值引用版本,x接收以后为什么不能直接传参而是要再次进行move呢?
因为右值引用被引用后,右值引用的变量x属性是左值。
验证如下:


右值引用底层是指针,右值引用开辟了一个空间来指向10,r就是那个地址的空间。为什么右值被右值引用后,r的属性却是左值呢?
因为右值引用本质上就是为了提高交换资源的效率,10作为右值是不能被改变或者改变的,swap都无法实现,所以右值被右值引用后的属性是左值,这样才能被改变。
















 7239
7239











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











