






前面文章中介绍了LNN工具链的流程,在模型部署之前,检查了模型的合约性,通过修改模型使其满足灵感和性格对算子和模型大小的要求。之后通过约束训练、量化训练、构图打包以及推理执行4个步骤,成功实现了模型的部署。在流程中对模型只是进行了简单的裁剪演示。
本篇重点讲如何进行合理的模型裁剪,并为您展示真实输入数据下最终推理执行的结果。
模型裁剪
对模型进行打包,会收到类似如下所示的报错提醒,错误中提到模型的参数和中间变量所占用的内存超过了预设的8MB的上限。
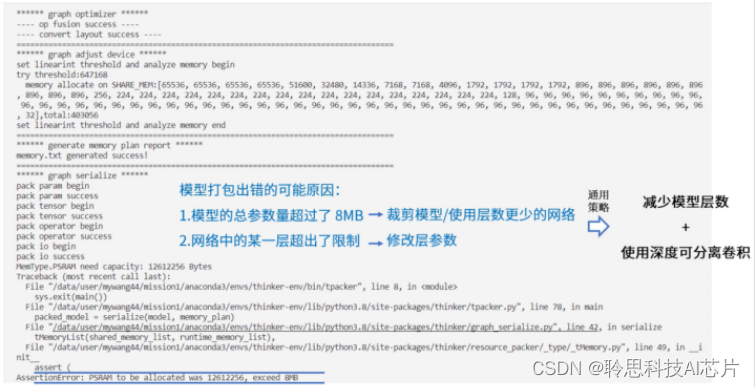
可能是这两种情况:
- 模型的总参数量超过了8MB的上限。这时需要对模型整体进行裁剪,使用层数更少的网络,比如resnet18或resnet34。
- 模型的总体大小满足8MB的上限,只是网络中的某一层超出了限制,需要定位到对应的层去修改参数。但是由于目前thinker无法返回具体是哪一层超出了限制,因此可以采取一种比较通用的裁剪策略:减少模型的层数,并修改模型使用深度可分离卷积。
深度可分离卷积的效果
对不同的resnet模型进行了深度可分离全新的改进,以降低模型的参数的数量和内存的要求。通过采用深度可分离卷积,在保持模型的性能的同时,显著减少了模型的参数的数量。以下是原始模型参数的大小和在线后参数大小的对比。
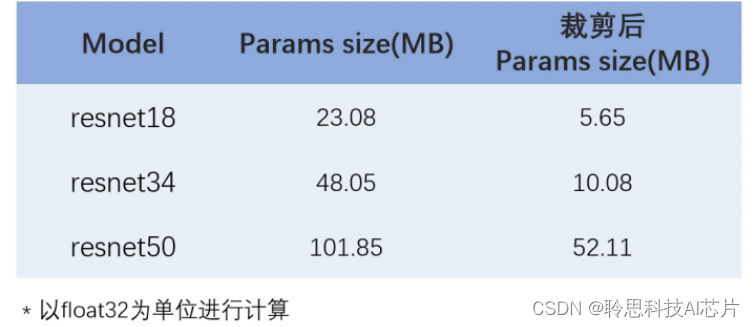
经过实验,经过查检的resnet18和resnet34,在量化训练之后都是可以满足tpacker 8M的约束条件的。
在的示例中,resident34和resident18的精度差别只有0.4%,因此最终选择了resnet18进行训练和部署。裁减后的residence18和原始网络的精度基本保持相同,在73%左右。
深度可分离卷积的原理
先举一个简单的例子,假如之间相遇时的三通道的5×5像素的图像,直接送入kernelsize=4的1个常规的卷积层,输出得到4个featuremap。来计算一下最基层的参数数量,输入的通道数是3,得到了featuremap的数量14,卷积核的长和宽均为3,那么总的参数的数量为3×3×3×4=108。
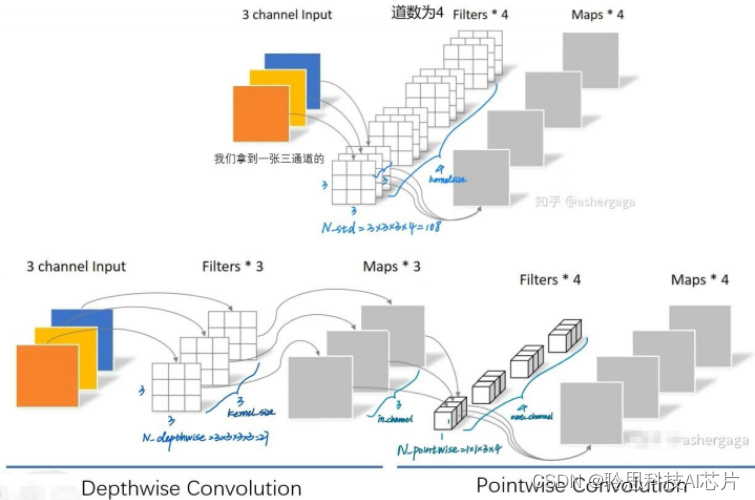
接下来将一个完整的卷积分解为两步进行,进一步进行depthwise convolution,与常规的卷积不同,不再对图像的每个通道使用多个卷积核而是采取一种更高效的方法。这一个通道只被一个卷积核卷积,这意味着每一个卷积核对应图像的一个通道,生成一个featuremap。
在本例中对图像的3个通道,将分别生成3张featuremap,然而这种模式存在特征融合不足和表达能力受限的缺陷。为了弥补这一点,接下来使用pointwise convolution进行特征融合,pointwise convolution的运算与常规的卷积非常相似,他的卷积核的尺寸是1×1×M,M为上一层的通道数,所以这里的卷积运算会将上一步的featuremap在深度方向进行加权组合,有几个卷积核就会输出几个featuremap。
最后来计算一下使用深度可分离卷积时的参数数量。深度可分离卷积的参数有两部分相加得到。第一部分是deepwest convolution.它的输入的图像的通道数为3,输出的featuremap的数量也为3,卷积核的长和宽均为3,因此这一部分的参数数量为3×3×3×3=27。第二部分是pointwise convolution,它的输入通道数为3,输出的featuremap数量为4,卷集核的长和宽均为1,因此这一部分的参数的数量为1×1×3×4为12,总共的深度可分离卷积的参数数量为27+12=39,对于相同的收入同样是得到4张featuremapp,深度可分离卷积的参数数量是常规卷积的1/3。
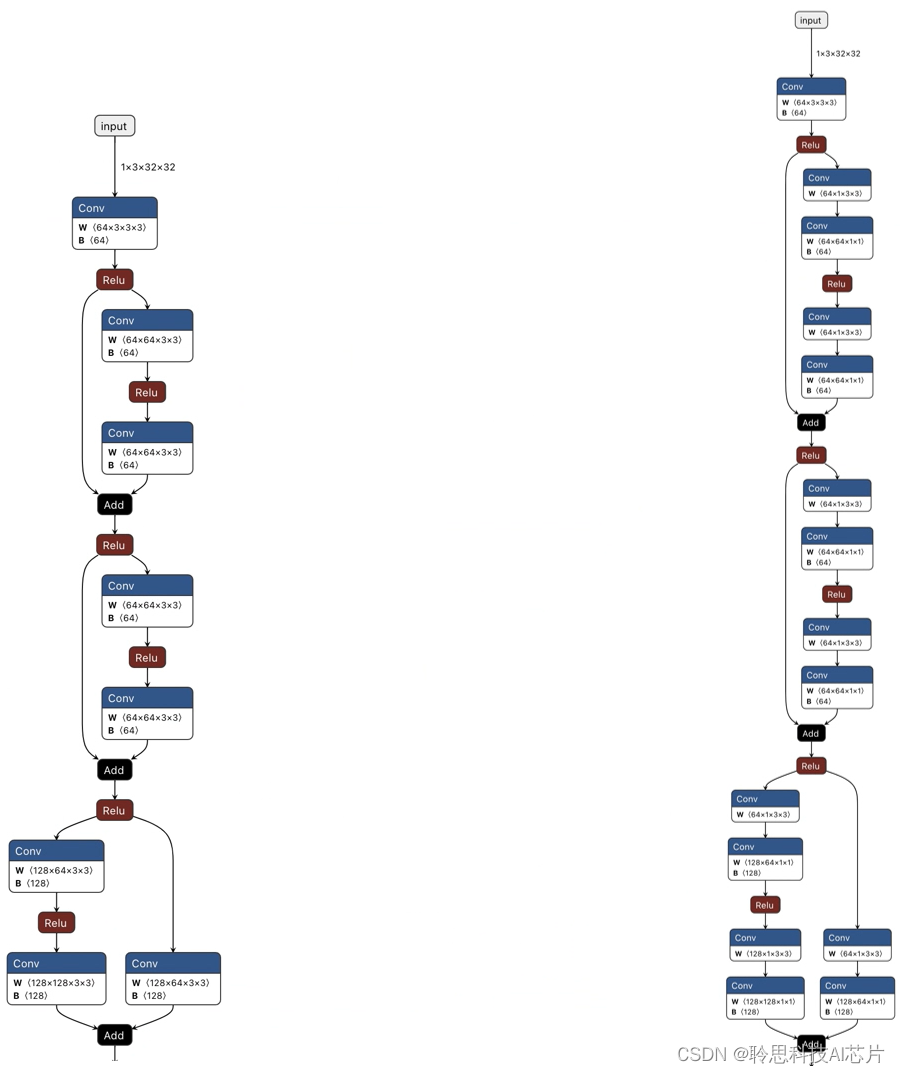
具体深度可分离卷积是如何使用在的模型中?
可以通过ONNX图进行对比着看一下,截取resnet18的stage1部分,可以看到只需要在主路和shortcut部分将原始常规的卷积块替换成depthwise convolution,加上pointwise conclusion就可以。
在vscode实现步骤:
1、首先定义一个名为DepthwiseSeparableConv2d的新类,用于实现深度可分离卷积。
在构造函数中定义了两个子卷积层,depthwise卷积层和pointwise卷积层是一个nn.Conv2d层,其中groups参数设置为in_channels,这样可以确保每个输入通道都有一个独立的卷积核的核心实现逐通道卷积。(pointwise卷积层是另一个nn.Conv2d层,它的核心是使用1×1的卷积核将depthwise卷积层的输出通道,融合为out_channel通道,forward函数接收一个输入张量X,首先将其传递给depthwise卷积层,然后将其传递给pointwise卷积层最后返回输出张量。)
2、接下来修改BasicBlock和BottleNeck类,将其中的标准卷积替换为DepthwiseSeparableConv2d。(例如在BasicBlock中,将原始的卷积替换为如下所示的深度可分离卷积,类似的在shortcut的部分,将标准卷积也替换为深度各分离卷积,在BottleNeck中也进行同样的操作。)
通过这些修改,resnet模型的各个卷积都被替换为是深度可分离卷积。在保持输出特征相同的情况下,这种改变明显的减少了模型的参数量和计算量。
结果展示
步骤就和上一篇中的一样进行约束训练,量化训练之后,会得到一个最佳的权重文件,将其转化成onnx图之后,用tpacker进行打包,得到一个model.bin文件用于推理执行。
示例步骤:
1、选择一张真实的图片按照pytorch-cifar100的预处理方法,首先对拿到的任意一张JPG图像调整图像的尺寸为32×32像素,使用该数据系的均值和标准差,对图像进行归一化处理,将预处理后的图像转化为int8格式,最后保存为二进制文件。
2、运行图片预处理脚本,得到一个input.bin文件
3、接下来调用示例工程test_thinker,输入刚刚处理好的图片,生成的二进制文件input.bin和模型二进制文件model.bin。
运行命令可以看到最终test_thinker给得出的推理结果。
视频讲解
AI模型裁剪教程 :以resent结构为例,裁剪出适合运行在CSK6芯片上的模型
【AI模型裁剪教程 :以resent结构为例,裁剪出适合运行在CSK6芯片上的模型】
关于聆思
聆思科技是一家专注提供智能终端系统级(SoC)芯片的高科技企业,目前推出的CSK6系AI芯片已适配Zephyr RTOS。
希望了解更多有关CSK6 AI芯片信息的伙伴也可以+V:listenai-csk
欢迎各位同学与我们进行技术相关的探讨,大家一起进步吧!

















 992
992

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









